Indexar dados de arquivos e atalhos do OneLake
Neste artigo, saiba como configurar um indexador de arquivos do OneLake para extrair dados pesquisáveis e dados de metadados de um lakehouse no OneLake.
Para configurar e executar o indexador, você pode usar:
- API REST 2024-05-01-preview ou uma API REST de versão prévia mais recente.
- Um pacote beta do SDK do Azure que fornece o recurso.
- Assistente de importação de dados no portal do Azure.
- Assistente de Importação e vetorização de dados no portal do Azure.
Esse artigo usa as APIs REST para ilustrar cada etapa.
Pré-requisitos
Um workspace do Fabric. Siga esse tutorial para criar um workspace do Fabric.
Um lakehouse em um workspace do Fabric. Siga esse tutorial para criar um lakehouse.
Dados textuais. Se você tiver dados binários, poderá usar a análise de imagem de enriquecimento de IA para extrair texto ou gerar descrições de imagens. O conteúdo do arquivo não pode exceder os limites do indexador para sua camada de serviço de pesquisa.
Conteúdo no local Arquivos do seu lakehouse. Você pode adicionar dados da seguinte maneira:
- Carregue diretamente em um lakehouse
- Use pipelines de dados a partir do Microsoft Fabric
- Adicione atalhos de fontes de dados externas como Amazon S3 ou Google Cloud Storage.
Um serviço de Pesquisa de IA configurado para uma identidade gerenciada pelo sistema ou uma identidade gerenciada atribuída pelo usuário. O serviço de Pesquisa de IA deve residir no mesmo locatário que o workspace do Microsoft Fabric.
Uma atribuição de função de Colaborador no workspace do Microsoft Fabric onde o lakehouse está localizado. As etapas estão descritas na seção Conceder permissões desse artigo.
Um cliente REST para formular chamadas REST semelhantes às mostradas nesse artigo.
Tarefas com suporte
Você pode usar esse indexador para as seguintes tarefas:
- Indexação de dados e indexação incremental: o indexador pode indexar arquivos e metadados associados de caminhos de dados em um lakehouse. Ele detecta arquivos e metadados novos e atualizados por meio da detecção de alterações interna. Você pode configurar a atualização de dados através de um agendamento ou sob demanda.
- Detecção de exclusão: o indexador pode detectar exclusões por meio de metadados personalizados para a maioria dos arquivos e atalhos. Isso requer a adição de metadados aos arquivos para indicar que foram "excluídos temporariamente", permitindo sua remoção do índice de pesquisa. No momento, não é possível detectar exclusões em arquivos de atalho do Google Cloud Storage ou do Amazon S3 porque os metadados personalizados não são compatíveis com essas fontes de dados.
- IA aplicada por meio de conjuntos de habilidades: os Conjunto de habilidades são totalmente compatíveis com o indexador de arquivos do OneLake. Isso inclui recursos importantes como vetorização integrada que adiciona etapas de fragmentação e inserção de dados.
- Modos de análise: o indexador dá suporte a modos de análise JSON se você quiser analisar matrizes ou linhas JSON em documentos de pesquisa individuais. Ele também dá suporte ao modo de análise Markdown.
- Compatibilidade com outros recursos: o indexador do OneLake foi projetado para funcionar perfeitamente com outros recursos do indexador, como sessões de depuração, cache do indexador para enriquecimentos incrementais e repositório de conhecimento.
Formatos de documento com suporte
O indexador de arquivos do OneLake pode extrair texto dos seguintes formatos de documento:
- CSV (consulte Indexando BLOBs CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (consulte Como indexar blobs JSON)
- KML (XML para representações geográficas)
- Formatos do Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (emails do Outlook) e XML (WORD XML 2003 e 2006)
- Abrir formatos de documento: ODT, ODS, ODP
- Arquivos de texto sem formatação (consulte também Como indexar texto sem formatação)
- RTF
- XML
- ZIP
Atalhos com suporte
Os seguintes atalhos do OneLake são compatíveis com o indexador de arquivos do OneLake:
Atalho do OneLake (um atalho para outra instância do OneLake)
Limitações nessa versão prévia
Atualmente, não há suporte para os tipos de arquivo Parquet (incluindo delta parquet).
Não há suporte para exclusão de arquivo de atalhos do Amazon S3 e do Google Cloud Storage.
Esse indexador não dá suporte ao conteúdo do local da tabela do workspace do OneLake.
Este indexador não dá suporte a consultas SQL, mas a consulta usada na configuração da fonte de dados é exclusivamente para adicionar opcionalmente a pasta ou atalho de acesso.
Não há suporte para ingerir arquivos do workspace Meu Workspace no OneLake, pois esse é um repositório pessoal por usuário.
Preparar dados para indexação
Antes de configurar a indexação, revise os dados de origem para determinar se alguma alteração deve ser feita com antecedência. Um indexador pode indexar o conteúdo de um contêiner por vez. Por padrão, todos os arquivos no contêiner são processados. Você tem várias opções para um processamento mais seletivo:
Coloque os arquivos em uma pasta virtual. Uma definição de fonte de dados do indexador inclui um parâmetro de "consulta" que pode ser uma subpasta ou um atalho do lakehouse. Se esse valor for especificado, somente os arquivos na subpasta ou o atalho no lakehouse serão indexados.
Inclua ou exclua arquivos por tipo de arquivo. A lista de formatos de documentos com suporte pode ajudar você a determinar quais arquivos excluir. Por exemplo, é útil excluir arquivos de imagem ou de áudio que não fornecem um texto pesquisável. Essa funcionalidade é controlada por meio de definições de configuração no indexador.
Incluir ou excluir arquivos arbitrários. Se você quiser ignorar um arquivo específico por qualquer motivo, poderá adicionar propriedades e valores de metadados aos arquivos em seu lakehouse do OneLake. Quando um indexador encontra essa propriedade, ele ignora o arquivo ou seu conteúdo na execução de indexação.
A inclusão e exclusão de arquivos são abordadas na etapa de configuração do indexador. Se você não definir os critérios, o indexador reportará um arquivo inelegível como um erro e seguirá em frente. Se ocorrerem erros suficientes, o processamento poderá ser interrompido. Você pode especificar a tolerância a erros nas definições de configuração do indexador.
Um indexador normalmente cria um documento de pesquisa por arquivo, onde o conteúdo do texto e os metadados são capturados como campos pesquisáveis em um índice. Se os arquivos forem arquivos inteiros, você poderá analisá-los em vários documentos de pesquisa. Por exemplo, você pode analisar linhas em um arquivo CSV para criar um documento de pesquisa por linha. Se você precisar dividir um único documento em trechos menores para vetorizar dados, considere usar a vetorização integrada.
Indexando metadados de arquivo
Os metadados do arquivo também podem ser indexados, e isso é útil se você achar que alguma das propriedades de metadados padrão ou personalizadas é útil em filtros e consultas.
As propriedades de metadados especificadas pelo usuário são extraídas literalmente. Para receber os valores, é necessário definir o campo no índice de pesquisa do tipo Edm.String, com o mesmo nome que a chave de metadados do blob. Por exemplo, se um blob tiver uma chave de metadados de Priority com valor High, deverá ser definido um campo chamado Priority no índice de pesquisa e ele será preenchido com o valor High.
As propriedades de metadados do arquivo padrão podem ser extraídas em campos com nomes e tipos semelhantes, conforme listado abaixo. O indexador de arquivos do OneLake cria automaticamente mapeamentos de campos internos para essas propriedades de metadados, convertendo o nome hifenizado original ("metadata-storage-name") em um nome equivalente sublinhado ("metadata_storage_name").
Você ainda precisa adicionar os campos sublinhados à definição do índice, mas pode omitir os mapeamentos de campos do indexador porque o indexador faz a associação automaticamente.
metadata_storage_name (
Edm.String) – o nome do arquivo. Por exemplo, se você tiver um arquivo /mydatalake/my-folder/subfolder/resume.pdf, o valor desse campo seráresume.pdf.metadata_storage_path (
Edm.String) – o URI completo do blob, incluindo a conta de armazenamento. Por exemplo,https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) – o tipo de conteúdo, conforme especificado pelo código usado para carregar o blob. Por exemplo,application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) – carimbo de data/hora da última modificação do blob. A IA do Azure Search usa esse carimbo de data/hora para identificar os blobs alterados, a fim de evitar a reindexação total após a indexação inicial.metadata_storage_size (
Edm.Int64) – tamanho do blob em bytes.metadata_storage_content_md5 (
Edm.String) – hash MD5 do conteúdo do blob, se estiver disponível.
Por fim, todas as propriedades de metadados específicas ao formato de documento dos arquivos que você está indexando também podem ser representadas no esquema de índice. Para obter mais informações sobre metadados específicos de conteúdo, consulte Propriedades de metadados de conteúdo.
É importante observar que não é necessário definir os campos para todas as propriedades acima no índice de pesquisa – basta capturar as propriedades necessárias para seu aplicativo.
Conceder permissões
O indexador do OneLake usa autenticação de token e acesso baseado em função para conexões com o OneLake. As permissões são atribuídas no OneLake. Não há requisitos de permissão nos armazenamentos de dados físicos que fazem backup dos atalhos. Por exemplo, se você estiver indexando da AWS, não precisará conceder permissões de serviço de pesquisa na AWS.
A atribuição de função mínima para a identidade do serviço de pesquisa é de Colaborador.
Configure um sistema ou uma identidade gerenciada pelo usuário para seu serviço de Pesquisa de IA.
A captura de tela a seguir mostra uma identidade gerenciada pelo sistema para um serviço de pesquisa denominado "onelake-demo".
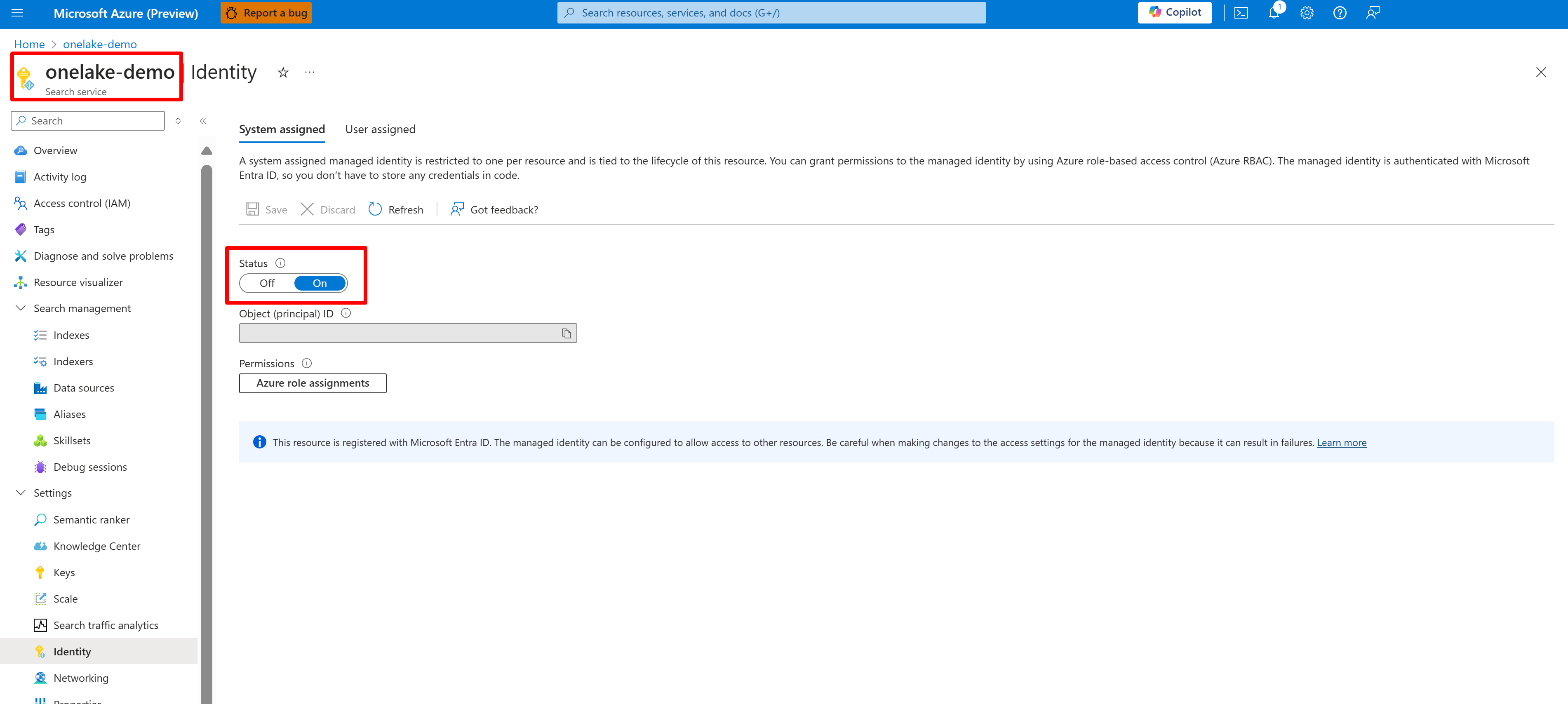
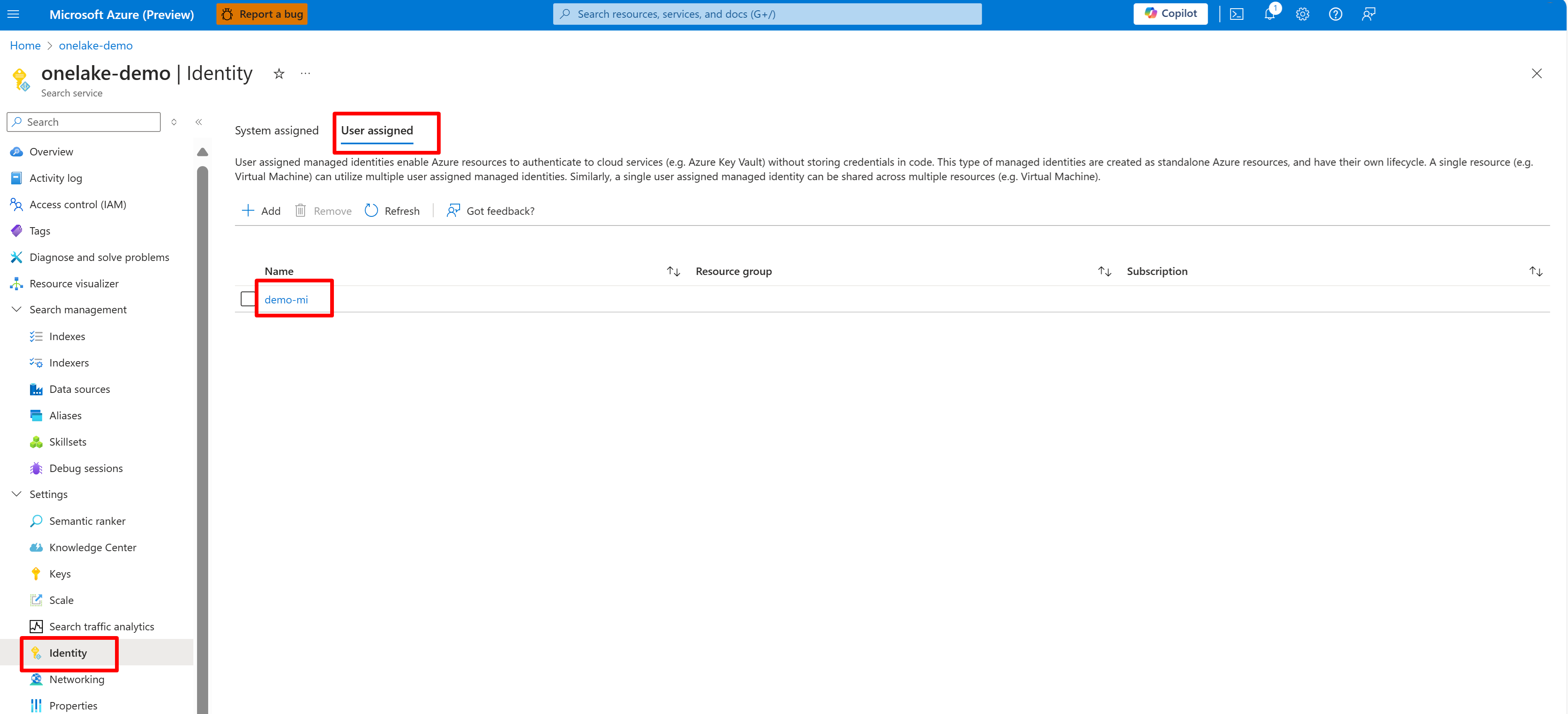
Essa captura de tela mostra uma identidade gerenciada pelo usuário para o mesmo serviço de pesquisa.
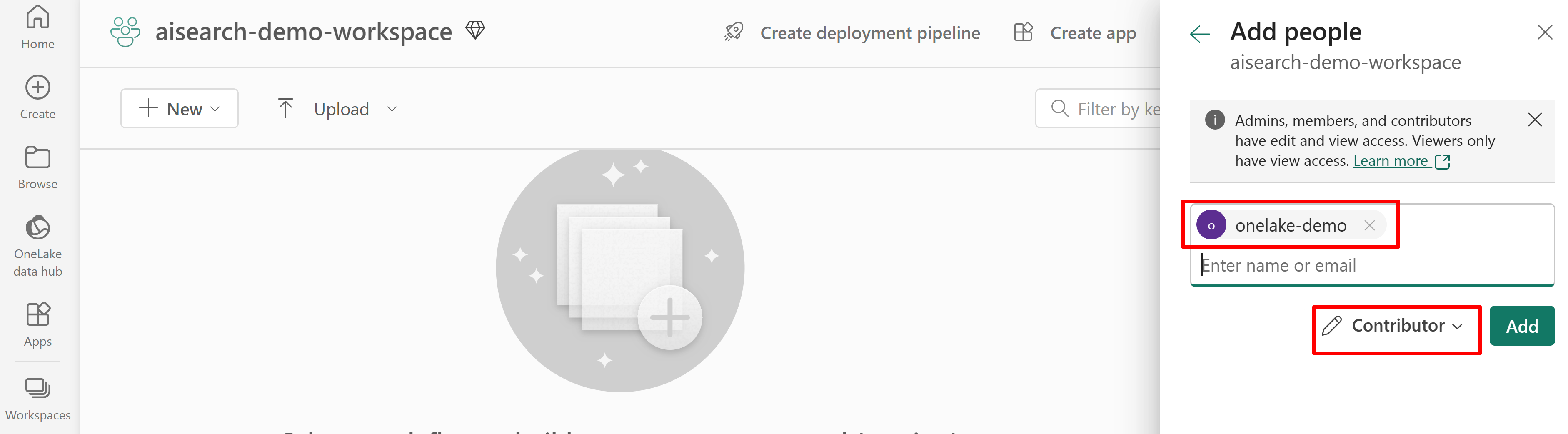
Conceda permissão para acesso do serviço de pesquisa ao workspace do Fabric. O serviço de pesquisa faz a conexão em nome do indexador.
Se você usar uma identidade gerenciada atribuída pelo sistema, pesquise o nome do serviço de Pesquisa de IA. Para obter uma identidade gerenciada atribuída pelo usuário, pesquise o nome do recurso de identidade.
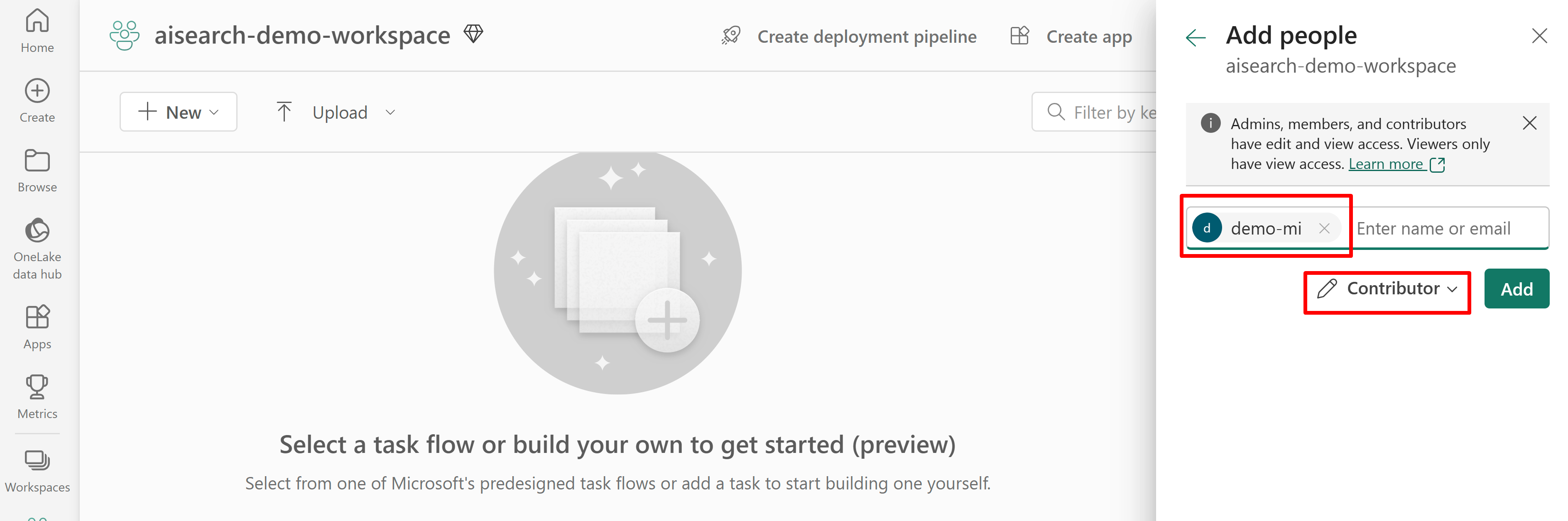
A captura de tela a seguir mostra uma atribuição de função de Colaborador usando uma identidade gerenciada pelo sistema.
Essa captura de tela mostra uma atribuição de função de Colaborador usando uma identidade gerenciada pelo sistema:




Definir a fonte de dados
Uma fonte de dados é definida como um recurso independente para que possa ser usada por vários indexadores. Você deve usar a API REST 2024-05-01-preview para criar a fonte de dados.
Use a API REST Criar ou atualizar uma fonte de dados para configurar sua definição. Estas são as etapas mais significativas da definição.
Defina
"type"como"onelake"(obrigatório).Obtenha o GUID do workspace do Microsoft Fabric e o GUID do lakehouse:
Vá para o lakehouse do qual você gostaria de importar dados de seu URL. Ele deve ser semelhante a este exemplo: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Copie os seguintes valores usados na definição da fonte de dados:
Copie o GUID do workspace, que chamaremos de
{FabricWorkspaceGuid}, que é listado logo após "grupos" no URL. Nesse exemplo, seria 000000000-0000-0000-0000-0000-000000000000000.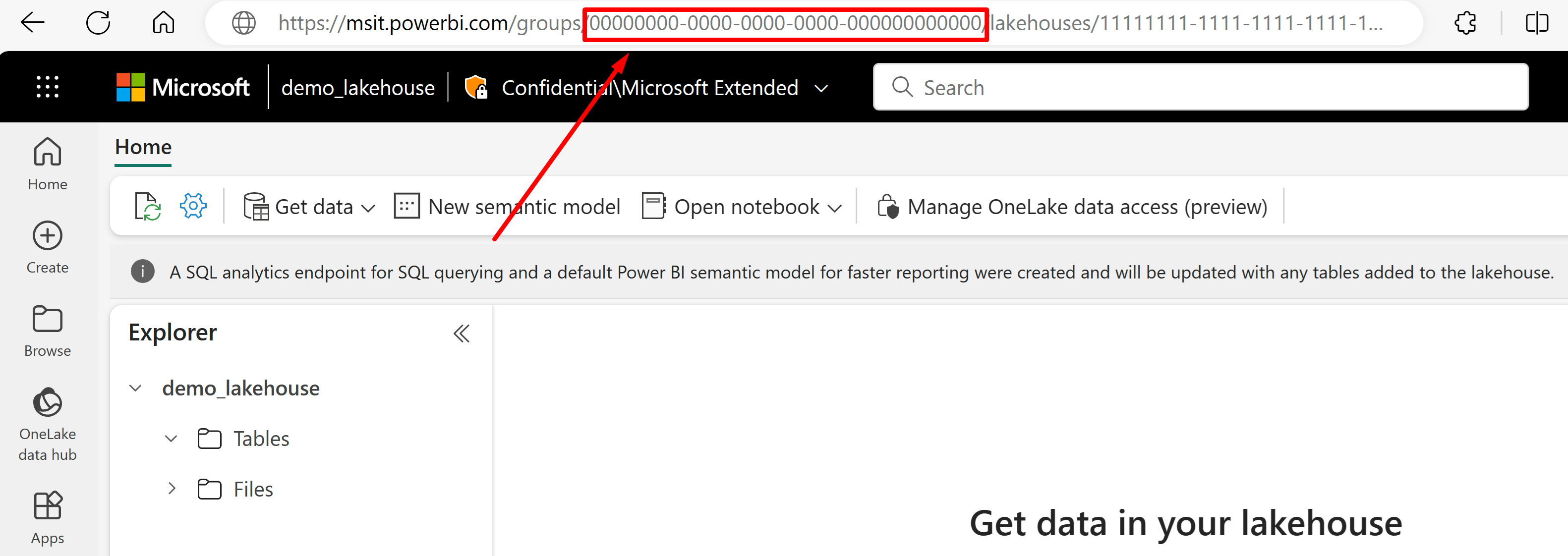
Copie o GUID do lakehouse que chamaremos de
{lakehouseGuid}, que é listado logo após "lakehouses" no URL. Neste exemplo, seria 11111111-1111-1111-1111-1111-1111111111111.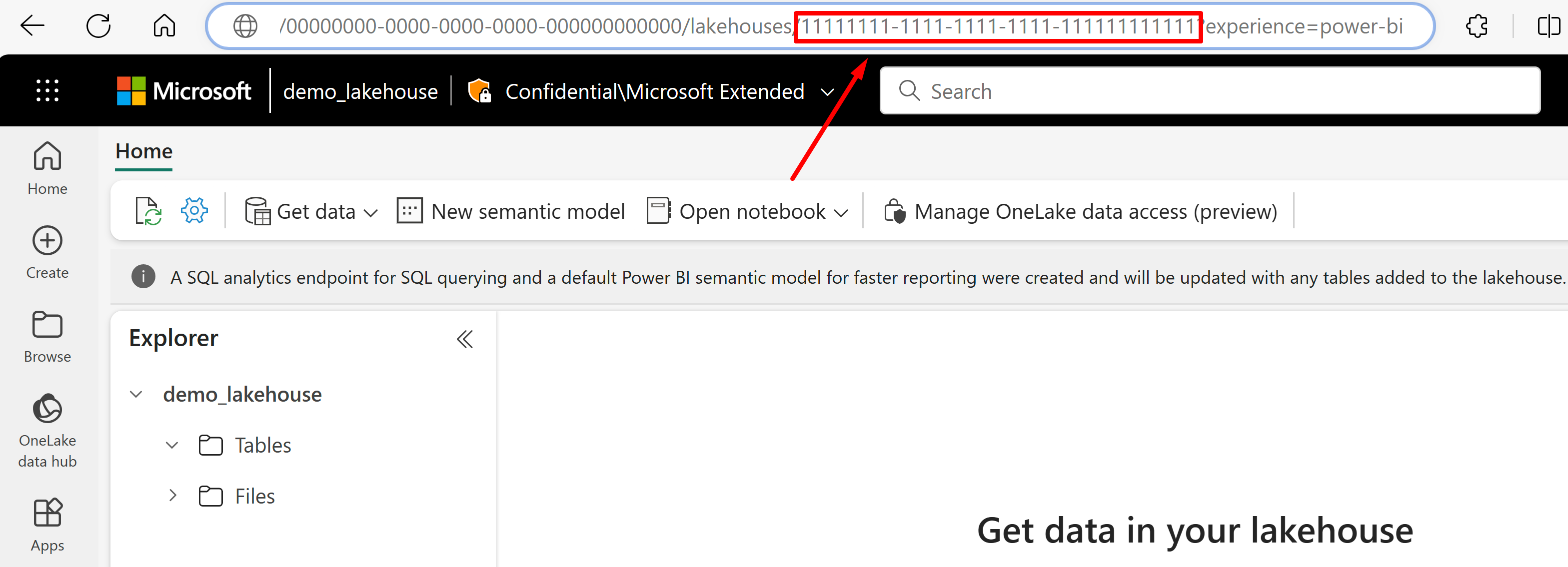
Defina
"credentials"para o GUID do workspace do Microsoft Fabric substituindo{FabricWorkspaceGuid}pelo valor copiado na etapa anterior. Esse é o OneLake para acessar com a identidade gerenciada que você configurará posteriormente nesse guia."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Defina
"container.name"para o GUID do lakehouse, substituindo{lakehouseGuid}pelo valor copiado na etapa anterior. Use"query"para especificar opcionalmente uma subpasta ou atalho do lakehouse."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Defina o método de autenticação usando a identidade gerenciada atribuída pelo usuário ou vá para o próximo passo da identidade gerenciada pelo sistema.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }O valor
userAssignedIdentitypode ser encontrado acessando o recurso{userAssignedManagedIdentity}, em Propriedades e é chamadoId.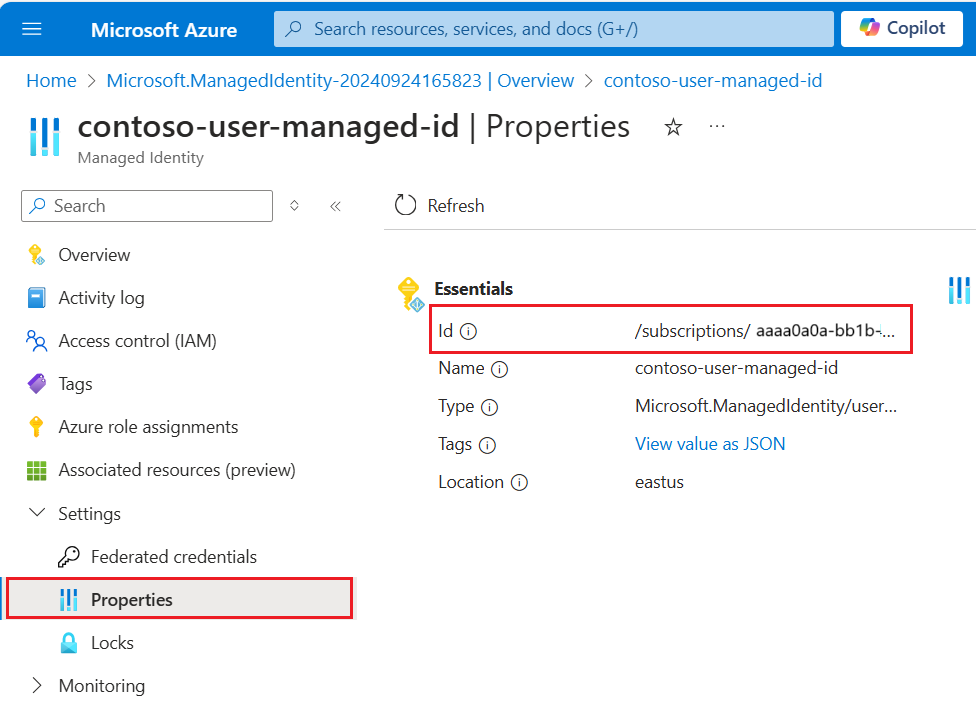
Exemplo:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Opcionalmente, use uma identidade gerenciada atribuída pelo sistema. A "identidade" será removida da definição se estiver usando a identidade gerenciada atribuída pelo sistema.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Exemplo:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Detectar exclusões por meio de metadados personalizados
A definição da fonte de dados do indexador de arquivos do OneLake pode incluir uma política de exclusão temporária se você quiser que o indexador exclua um documento de pesquisa quando o documento de origem for sinalizado para exclusão.
Para habilitar a exclusão automática de arquivos, use metadados personalizados para indicar se um documento de pesquisa deve ser removido do índice.
O fluxo de trabalho requer três ações separadas:
- "Exclusão temporária" do arquivo no OneLake
- O indexador exclui o documento de pesquisa no índice
- "Exclusão irreversível" do arquivo no OneLake.
A "Exclusão temporária" informa ao indexador o que fazer (excluir o documento de pesquisa). Se você excluir o arquivo físico no OneLake primeiro, não haverá nada para o indexador ler e o documento de pesquisa correspondente no índice ficará órfão.
Há etapas a seguir no OneLake e na Pesquisa de IA do Azure, mas não há outras dependências de recursos.
No arquivo do lakehouse, adicione um par chave-valor de metadados personalizados ao arquivo para indicar que o arquivo está sinalizado para exclusão. Por exemplo, você pode nomear a propriedade "IsDeleted", definida como false. Quando você quiser excluir o arquivo, altere-o para true.
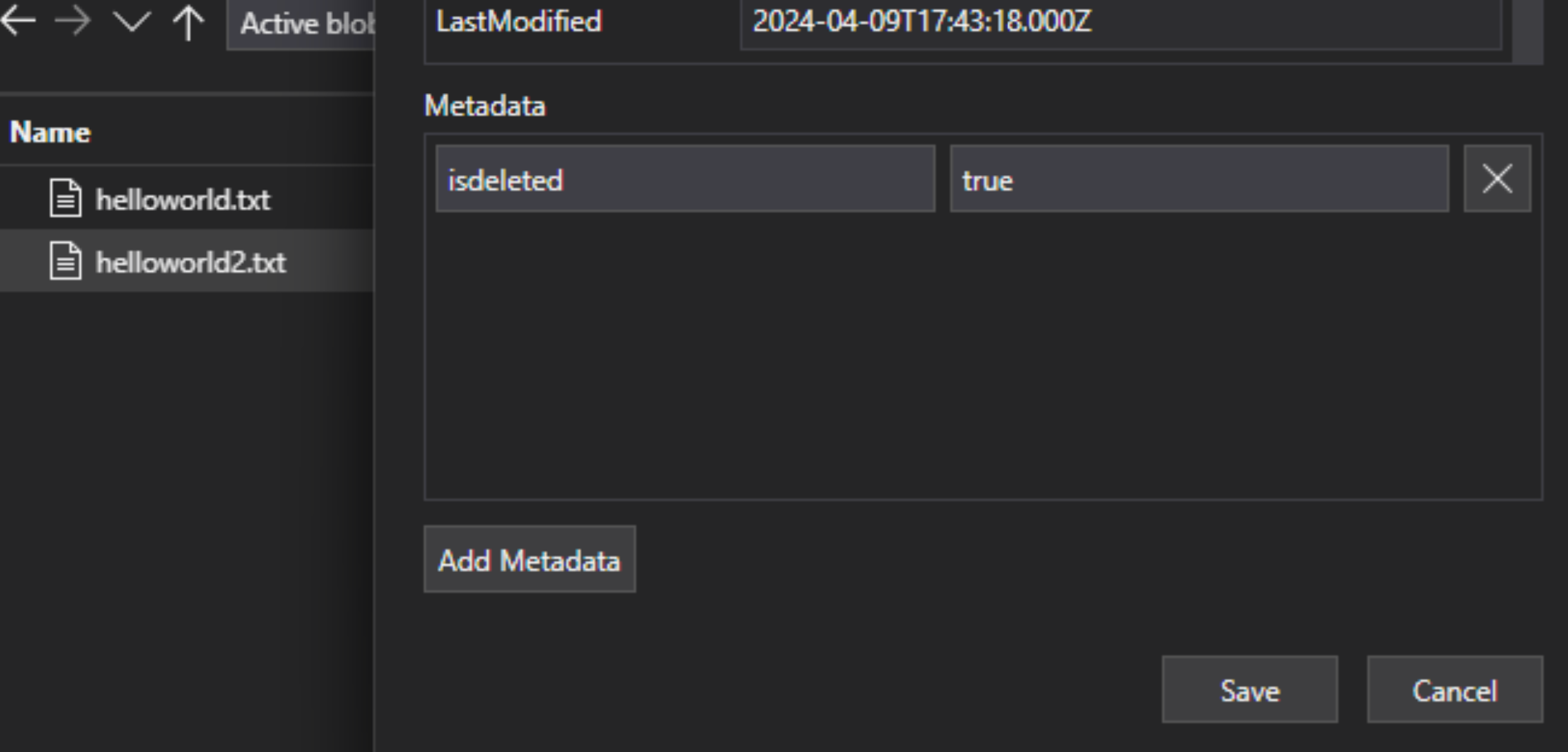
Na Pesquisa de IA do Azure, edite a definição da fonte de dados para incluir uma propriedade "dataDeletionDetectionPolicy". Por exemplo, a política a seguir considera um arquivo excluído se ele tiver uma propriedade de metadados "IsDeleted" com o valor verdadeiro:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Depois que o indexador for executado e excluir o documento do índice de pesquisa, você poderá excluir o arquivo físico no data lake.
Alguns pontos-chave incluem:
Agendar uma execução do indexador ajuda a automatizar esse processo. Recomendamos agendamentos para todos os cenários de indexação incremental.
Se a política de detecção de exclusão não tiver sido definida na primeira execução do indexador, você deverá redefinir o indexador para que ele leia a configuração atualizada.
Lembre-se de que a detecção de exclusão não é compatível com os atalhos do Amazon S3 e do Google Cloud Storage devido à dependência de metadados personalizados.
Adicionar campos de pesquisa a um índice
Em um índice de pesquisa, adicione campos para aceitar o conteúdo e os metadados dos arquivos do data lake do OneLake.
Criar ou atualizar um índice para definir os campos de pesquisa que armazenam o conteúdo e os metadados do arquivo:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Crie um campo de chave do documento ("key": true). Para o conteúdo do arquivo, os melhores candidatos são as propriedades de metadados.
metadata_storage_path(padrão) caminho completo para o objeto ou o arquivo. O campo-chave ("ID" neste exemplo) é preenchido com valores de metadata_storage_path porque é o padrão.metadata_storage_name, utilizável somente se os nomes forem exclusivos. Caso deseje ter esse campo como a chave, mova"key": truepara essa definição de campo.Uma propriedade de metadados personalizada que você adiciona aos seus arquivos. Essa opção requer que o seu processo de carregamento de arquivo adicione essa propriedade de metadados a todos os blobs. Como a chave é uma propriedade necessária, todos os arquivos que não têm um valor não são indexados. Se você usar uma propriedade de metadados personalizada como uma chave, evite fazer alterações nessa propriedade. Os indexadores adicionarão documentos duplicados para o mesmo arquivo se a propriedade de chave for alterada.
As propriedades de metadados geralmente incluem caracteres, como
/e-, que são inválidas para chaves de documento. Como o indexador tem uma propriedade "base64EncodeKeys" (true por padrão), ele codifica automaticamente a propriedade metadata, sem a necessidade de configuração ou de mapeamento de campo.Adicione um campo "conteúdo" para armazenar o texto extraído de cada arquivo por meio da propriedade "conteúdo" do arquivo. Não é necessário usar esse nome, mas, usá-lo permite aproveitar os mapeamentos de campo implícitos.
Adicione campos para propriedades de metadados padrão. O indexador pode ler propriedades de metadados personalizadas, de metadados padrão e de metadados específicas do conteúdo.
Configurar e executar o indexador de arquivos do OneLake
Depois que o índice e a fonte de dados forem criados, você estará pronto para criar o indexador. A configuração do indexador especifica as entradas, os parâmetros e as propriedades que controlam os comportamentos de tempo de execução. Você também pode especificar as partes de um blob que serão indexadas.
Crie ou atualize um indexador dando um nome a ele e referenciando a fonte de dados e o índice de destino:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Defina "batchSize" se o padrão (dez documentos) estiver subutilizando ou sobrecarregando os recursos disponíveis. Os tamanhos de lote padrão são específicos da fonte de dados. A indexação de arquivos define o tamanho do lote em 10 documentos ao reconhecer ao tamanho médio maior do documento.
Em "configuração", controle quais arquivos são indexados com base no tipo de arquivo ou deixe sem especificar para recuperar todos os arquivos.
Em
"indexedFileNameExtensions", forneça uma lista separada por vírgula de extensões de arquivos (com um ponto à esquerda). Faça o mesmo em"excludedFileNameExtensions"para indicar as extensões que devem ser ignoradas. Se a mesma extensão estiver nas duas listas, ela será excluída da indexação.Em "configuração", defina "dataToExtract" para controlar quais partes dos arquivos são indexadas:
"contentAndMetadata" é o padrão. Especifica que todos os metadados e conteúdo textual extraídos do arquivo sejam indexados.
"storageMetadata" especifica que apenas as propriedades de arquivo padrão e os metadados especificados pelo usuário são indexados. Embora as propriedades estejam documentadas para blobs do Azure, as propriedades do arquivo são as mesmas para o OneLake, exceto para os metadados relacionados à SAS.
"allMetadata" especifica que as propriedades padrão do arquivo e todos os metadados dos tipos de conteúdo encontrados são extraídos do conteúdo do arquivo e indexados.
Em "configuração", defina "parsingMode" se os arquivos devem ser mapeados para vários documentos de pesquisa ou se consistem em texto sem formatação, documentos JSON ou arquivos CSV.
Especifique mapeamentos de campo se houver diferenças no nome ou tipo de campo, ou se você precisar de várias versões de um campo de origem no índice de pesquisa.
Na indexação de arquivos, muitas vezes você pode omitir os mapeamentos de campo porque o indexador tem suporte interno para mapear as propriedades de metadados e "content" para campos com nomes semelhantes e campos com tipo em um índice. Para as propriedades de metadados, o indexador substitui automaticamente os hifens
-por sublinhados no índice de pesquisa.
Para obter mais informações sobre outras propriedades, Crie um indexador. Para obter a lista completa da descrições de parâmetro, confira Criar o Indexador (REST) na API REST. Os parâmetros são os mesmos para o OneLake.
Por padrão, um indexador é executado automaticamente quando você o cria. Você pode alterar esse comportamento definindo "desabilitado" como verdadeiro. Para controlar a execução do indexador, execute um indexador sob demanda ou coloque-o em um agendamento.
Checar o status do indexador
Conheça várias abordagens para monitorar o status do indexador e o histórico de execução aqui.
Tratar erros
Os erros que normalmente ocorrem durante a indexação incluem os tipos de conteúdo sem suporte, conteúdo ausente ou arquivos grandes. Por padrão, o indexador de arquivos do OneLake é interrompido assim que encontra um arquivo com um tipo de conteúdo sem suporte. No entanto, talvez você queira que a indexação prossiga mesmo que ocorram erros e, depois, depure documentos individuais.
Erros transitórios são comuns para soluções que envolvem várias plataformas e produtos. No entanto, se você mantiver o indexador em um agendamento (por exemplo, a cada 5 minutos), o indexador deverá ser capaz de se recuperar desses erros na execução seguinte.
Há cinco propriedades do indexador que controlam a resposta do indexador quando ocorrem erros.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parâmetro | Valores válidos | Descrição |
|---|---|---|
| "maxFailedItems" | -1, null ou 0, inteiro positivo | Continuar a indexação se ocorrem erros a qualquer momento do processamento, ao analisar blobs ou ao adicionar documentos a um índice. Definir as propriedades com o número de falhas aceitáveis. Um valor de -1 permite o processamento, independentemente de quantos erros ocorram. Caso contrário, o valor será um inteiro positivo. |
| "maxFailedItemsPerBatch" | -1, null ou 0, inteiro positivo | O mesmo que acima, mas usado para indexação do lote. |
| "failOnUnsupportedContentType" | true ou false | Se o indexador não puder determinar o tipo de conteúdo, especifique se deseja continuar ou falhar o trabalho. |
| "failOnUnprocessableDocument" | true ou false | Se o indexador não puder processar um documento de um tipo de conteúdo que em outros contextos tem suporte, especifique se deseja continuar ou falhar o trabalho. |
| "indexStorageMetadataOnlyForOversizedDocuments" | true ou false | Por padrão, os blobs superdimensionados são tratados como erros. Se você definir esse parâmetro como verdadeiro, o indexador tentará indexar seus metadados mesmo que o conteúdo não possa ser indexado. Para obter os limites do tamanho do blob, consulte Limites de serviço. |
Próximas etapas
Analise como o Assistente de importação e vetorização de dados funciona e experimente-o para esse indexador. Você pode usar a vetorização integrada para agrupar e criar inserções para pesquisa vetorial ou híbrida usando um esquema padrão.