Extrair texto e informações de imagens usando enriquecimento de IA
Por meio do enriquecimento de IA, a IA do Azure Search oferece várias opções para criar e extrair texto pesquisável de imagens, incluindo:
- OCR reconhecimento óptico de caracteres de texto e dígitos
- Análise de imagem que descreve imagens por meio de recursos visuais
- Habilidades personalizadas para invocar qualquer processamento de imagem externo que você deseje fornecer
Usando o OCR, você pode extrair textos de fotos ou imagens, como a palavra PARE em uma placa de trânsito. Por meio da análise de imagem, você pode gerar uma representação de texto de uma imagem, como um dente-de-leão para uma foto de um dente-de-leão ou a cor amarelo. Você também pode extrair metadados sobre a imagem, como seu tamanho.
Este artigo aborda os princípios para trabalhar com imagens e também descreve vários cenários comuns, como trabalhar com imagens incorporadas, habilidades personalizadas e visualizações de sobreposição em imagens originais.
Para trabalhar com o conteúdo da imagem em um conjunto de habilidades, você precisará de:
- Arquivos de origem que incluem imagens
- Um indexador de pesquisa, configurado para ações de imagem
- Um conjunto de habilidades com habilidades personalizadas ou internas que invocam o OCR ou a análise de imagem
- Um índice de pesquisa com campos para receber a saída de texto analisada, além de mapeamentos de campo de saída no indexador que estabelece a associação
Opcionalmente, você pode definir projeções para aceitar a saída analisada por imagem em um repositório de conhecimento para cenários de mineração de dados.
Configurar arquivos de origem
O processamento de imagem é orientado por indexador, o que significa que as entradas brutas devem estar em uma fonte de dados compatível.
- A análise de imagem dá suporte a JPEG, PNG, GIF e BMP
- O OCR dá suporte a JPEG, PNG, BMP e TIF
As imagens são arquivos binários autônomos ou inseridos em documentos, como arquivos de aplicativo PDF, RTF ou Microsoft. Um máximo de 1.000 imagens pode ser extraído de um determinado documento. Se houver mais de 1.000 imagens em um documento, as primeiras 1.000 serão extraídas e, em seguida, será gerado um aviso.
O Armazenamento de Blobs do Azure é o armazenamento usado com mais frequência para processamento de imagem na IA do Azure Search. Há três tarefas principais relacionadas à recuperação de imagens de um contêiner de blobs:
Habilite o acesso ao conteúdo no contêiner. Se você estiver usando um cadeia de conexão de acesso completo que inclua uma chave, a chave dará a você permissão para o conteúdo. Opcionalmente, é possível autenticar usando o Microsoft Entra ID ou conectar-se como um serviço confiável.
Crie uma fonte de dados do tipo azureblob que se conecta ao contêiner de blob que armazena seus arquivos.
Examine os limites da camada de serviço para verificar se os dados de origem estão abaixo dos limites máximos de tamanho e quantidade para indexadores e enriquecimento.
Configurar indexadores para processamento de imagem
Após a configuração dos arquivos de origem, habilite a normalização da imagem definindo o parâmetro imageAction na configuração do indexador. A normalização de imagem ajuda a tornar as imagens mais uniformes para o processamento posterior. A normalização de imagem inclui as seguintes operações:
- Imagens grandes são redimensionadas para uma altura e largura máximas para uniformizá-las.
- Para imagens que têm metadados que especificam orientação, a rotação de imagem é ajustada para carregamento vertical.
Ajustes de metadados são capturados em um tipo complexo criado para cada imagem. Você não pode optar por sair da exigência de normalização de imagem. As habilidades que iteram em imagens, como OCR e análise de imagem, esperam imagens normalizadas.
Crie ou atualize um indexador para definir as propriedades de configuração:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Defina
dataToExtractcomocontentAndMetadata(obrigatório).Verifique se o
parsingModeestá definido como padrão (obrigatório).Esse parâmetro determina a granularidade dos documentos de pesquisa criados no índice. O modo padrão configura uma correspondência um-para-um para que um blob resulte em um documento de pesquisa. Se os documentos forem grandes ou se as habilidades exigirem partes menores de texto, você poderá adicionar a habilidade de Divisão de Texto que subdivide um documento na paginação para fins de processamento. Mas, para cenários de pesquisa, um blob por documento será necessário se o enriquecimento incluir processamento de imagem.
Defina
imageActionpara habilitar o nónormalized_imagesem uma árvore de enriquecimento (obrigatório):generateNormalizedImagespara gerar uma matriz de imagens normalizadas como parte da quebra de documento.generateNormalizedImagePerPage(aplica-se somente a PDF) para gerar uma matriz de imagens normalizadas em que cada página no PDF é renderizada em uma imagem de saída. Para arquivos não PDF, o comportamento desse parâmetro é semelhante a se você tivesse definidogenerateNormalizedImages. No entanto, a configuraçãogenerateNormalizedImagePerPagepode tornar a operação de indexação menos eficiente por design (especialmente para documentos grandes), pois várias imagens teriam que ser geradas.
Opcionalmente, ajuste a largura ou a altura das imagens normalizadas geradas:
normalizedImageMaxWidthem pixels. O padrão é 2.000. O valor máximo é 10.000.normalizedImageMaxHeightem pixels. O padrão é 2.000. O valor máximo é 10.000.
O padrão de 2.000 pixels para a largura e a altura máximas de imagens normalizadas baseia-se nos tamanhos máximos suportados pela habilidade OCR e a habilidade de análise de imagem. A habilidade OCR dá suporte a largura e altura máximas de 4.200 para idiomas não ingleses e 10.000 para inglês. Caso aumente os limites máximos, poderá haver uma falha no processamento de imagens maiores, de acordo com a definição do conjunto de habilidades e do idioma dos documentos.
Opcionalmente, defina critérios de tipo de arquivo se a carga de trabalho tiver como destino um tipo de arquivo específico. A configuração do indexador de blobs inclui configurações de inclusão e exclusão de arquivos. Você pode filtrar arquivos que não deseja.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Obter imagens normalizadas
Quando imageAction é definido como um valor diferente de nenhum, o novo campo normalized_images contém uma matriz de imagens. Cada imagem é um tipo complexo que tem os seguintes membros:
| Membro de imagem | Descrição |
|---|---|
| data | Cadeia codificada em Base64 da imagem normalizada no formato JPEG. |
| width | Largura da imagem normalizada em pixels. |
| altura | Altura da imagem normalizada em pixels. |
| originalWidth | A largura original da imagem antes da normalização. |
| originalHeight | A altura original da imagem antes da normalização. |
| rotationFromOriginal | Rotação no sentido anti-horário em graus para criar a imagem normalizada. Um valor entre 0 graus e 360 graus. Esta etapa lê os metadados da imagem gerada por uma câmera ou scanner. Geralmente, é um múltiplo de 90 graus. |
| contentOffset | O deslocamento de caractere dentro do campo de conteúdo do qual a imagem foi extraída. Este campo só é aplicável a arquivos com imagens incorporadas. O contentOffset para imagens extraídas de documentos PDF está sempre no final do texto na página da qual foi extraído no documento. Isso significa que as imagens aparecem após todo o texto da página, independentemente da localização original da imagem na página. |
| pageNumber | Caso a imagem tenha sido extraída de um arquivo PDF ou renderizada nele, este campo vai conter o número da página da qual a imagem foi extraída ou na qual a imagem foi renderizada, começando pela página 1. Se a imagem não for de um PDF, esse campo será 0. |
Valor de exemplo de normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Definir conjuntos de habilidades para processamento de imagem
Esta seção complementa os artigos de referência de habilidades fornecendo contexto para trabalhar com entradas, saídas e padrões de habilidades, relacionadas ao processamento de imagem.
Criar ou atualizar um conjunto de habilidades para adicionar habilidades.
Adicione modelos para OCR e análise de imagens no portal do Azure ou copie as definições na documentação de referência de habilidades. Insira-os na matriz de habilidades da definição do conjunto de habilidades.
Se necessário, incluir uma chave de vários serviços na propriedade de serviços de IA do Azure do conjunto de habilidades. A IA do Azure Search faz chamadas para um recurso de serviços de IA do Azure faturável para OCR e análise de imagem de transações que excedem o limite gratuito (20 por indexador/dia). Os serviços de IA do Azure devem estar na mesma região que o serviço de pesquisa.
Se as imagens originais estiverem inseridas em PDF ou em arquivos de aplicativos, como PPTX ou DOCX, será necessário adicionar uma habilidade de Mesclagem de Texto se quiser que a imagem e o texto saiam juntos. Trabalhar com imagens inseridas é um assunto discutido mais adiante neste artigo.
Depois que a estrutura básica do conjunto de habilidades for criada e os serviços de IA do Azure estiverem configurados, será possível se concentrar em cada habilidade de imagem individual, definindo entradas e contexto de origem e mapeando saídas para campos em um índice ou repositório de conhecimento.
Observação
Para obter um exemplo de conjunto de habilidades que combine o processamento de imagens com o processamento de linguagem natural downstream, consulte Tutorial REST: Usar REST e IA para gerar conteúdo pesquisável de blobs do Azure. Ele mostra como alimentar a saída de imagens de habilidades em reconhecimento de entidade e extração de frases-chave.
Entradas para processamento de imagem
Conforme observado, as imagens são extraídas durante a quebra de documento e, em seguida, normalizadas como uma etapa preliminar. As imagens normalizadas são as entradas para qualquer habilidade de processamento de imagem e são sempre representadas em uma árvore de documentos enriquecida de uma entre duas maneiras:
/document/normalized_images/*é para documentos processados inteiros./document/normalized_images/*/pagesé para documentos processados em partes (páginas).
Se você estiver usando o OCR e a análise de imagem da mesma maneira, as entradas terão praticamente a mesma construção:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Mapear saídas para campos de pesquisa
Em um conjunto de habilidades, a saída da habilidade de Análise de Imagem e OCR é sempre texto. O texto de saída é representado como nós em uma árvore de documento enriquecido interna, e cada nó deve ser mapeado para campos em um índice de pesquisa ou para projeções em um repositório de conhecimento, para que o conteúdo fique disponível no seu aplicativo.
No conjunto de habilidades, examine a seção
outputsde cada habilidade para determinar quais nós existem no documento enriquecido:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Crie ou atualize um índice de pesquisa para adicionar campos para aceitar as saídas de habilidades.
No exemplo da coleção de campos a seguir, conteúdo é o conteúdo do blob. Metadata_storage_name contém o nome do arquivo (defina
retrievablecomo verdadeiro). Metadata_storage_path é o caminho exclusivo do blob e é a chave de documento padrão. Merged_content é saída da Mesclagem de Texto (útil quando as imagens são inseridas).Texto e layoutText são saídas de habilidade de OCR e devem ser uma coleção de cadeias de caracteres para capturar toda a saída gerada por OCR para todo o documento.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Atualize o indexador para mapear a saída do conjunto de habilidades (nós em uma árvore de enriquecimento) para os campos de índice.
Os documentos enriquecidos são internos. Para externalizar os nós em uma árvore de documento enriquecida, configure um mapeamento de campo de saída que especifique qual campo do índice recebe o conteúdo do nó. Os dados enriquecidos são acessados pelo seu aplicativo por meio de um campo de índice. O exemplo a seguir mostra um nó de texto (saída OCR) em um documento enriquecido mapeado para um campo de texto em um índice de pesquisa.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Execute o indexador para invocar recuperação de documento de origem, processamento de imagem e indexação.
Verificar os resultados
Execute uma consulta no índice para verificar os resultados do processamento de imagem. Use o Gerenciador de pesquisa como um cliente de pesquisa ou qualquer ferramenta que envie solicitações HTTP. A consulta a seguir seleciona os campos que contêm a saída do processamento de imagem.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
O OCR reconhece texto em arquivos de imagem. Isso significa que os campos OCR (texto e layoutText) estarão vazios se os documentos de origem forem texto puro ou imagens puras. Da mesma forma, os campos de análise de imagem (imageCaption e imageTags) estarão vazios se as entradas do documento de origem forem estritamente texto. A execução do indexador emite avisos se as entradas de imagem estiverem vazias. Esses avisos devem ser esperados quando os nós não estão populados no documento enriquecido. Lembre-se de que a indexação de blobs permite incluir ou excluir tipos de arquivo se você quiser trabalhar com tipos de conteúdo isoladamente. Você pode usar essas configurações para reduzir o ruído durante as execuções do indexador.
Uma consulta alternativa para verificar os resultados pode incluir os campos conteúdo e merged_content. Observe que esses campos incluem conteúdo para qualquer arquivo de blob, mesmo aqueles em que o processamento de imagens não foi realizado.
Sobre saídas de habilidades
As saídas de habilidade incluem text (OCR), layoutText (OCR), merged_content, captions (análise de imagem), tags (análise de imagem):
textarmazena a saída gerada pelo OCR. Esse nó deve ser mapeado para o campo do tipoCollection(Edm.String). Há um campotextpor documento de pesquisa que consiste em cadeias de caracteres delimitadas por vírgulas para documentos que contêm várias imagens. A ilustração a seguir mostra a saída do OCR para três documentos. O primeiro é um documento que contém um arquivo sem imagens. Em segundo lugar está um documento (arquivo de imagem) que contém uma palavra, Microsoft. O terceiro é um documento que contém várias imagens, algumas sem nenhum texto ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextarmazena informações geradas por OCR sobre o local do texto na página, descritas em termos de caixas delimitadoras e coordenadas da imagem normalizada. Esse nó deve ser mapeado para o campo do tipoCollection(Edm.String). Há um campolayoutTextpor documento de pesquisa que consiste em cadeias de caracteres delimitadas por vírgula.merged_contentarmazena a saída de uma habilidade de Mesclagem de Texto e deve ser um campo grande de tipoEdm.Stringque contém texto bruto do documento de origem, comtextinseridas no lugar de uma imagem. Se os arquivos forem somente texto, o OCR e a análise de imagem não terão nada a fazer emerged_contentserá igual aocontent(uma propriedade de blob que contém o conteúdo do blob).imageCaptioncaptura uma descrição de uma imagem como marcas individuais e uma descrição de texto mais longa.imageTagsarmazena marcas sobre uma imagem como uma coleção de palavras-chave, uma coleção para todas as imagens no documento de origem.
A captura de tela a seguir é uma ilustração de um PDF que inclui texto e imagens incorporadas. A quebra de documentos detectou três imagens incorporadas: bando de gaivotas, mapa, águia. Outros textos no exemplo (incluindo títulos, cabeçalhos e corpo de texto) foram extraídos como texto e excluídos do processamento de imagens.
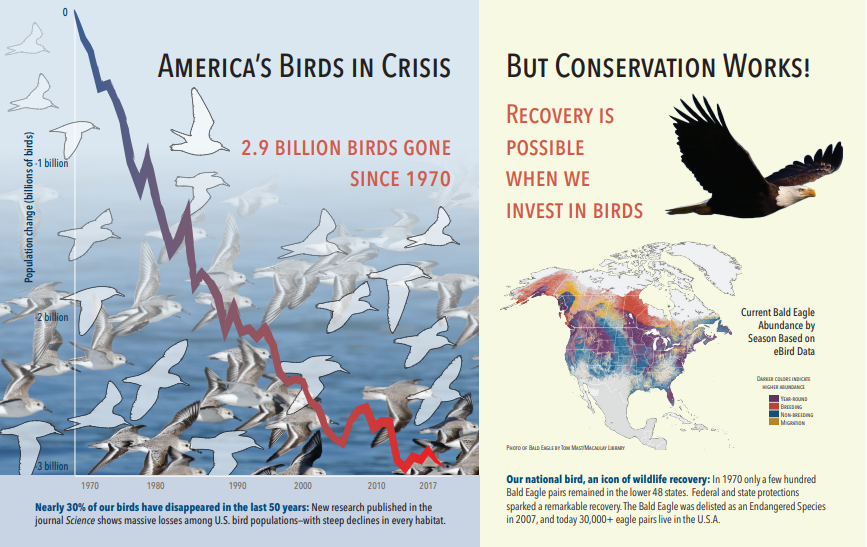
A saída da análise de imagem é ilustrada no JSON a seguir (resultado da pesquisa). A definição de habilidade permite especificar quais recursos visuais são interessantes. Para este exemplo, foram produzidas marcas e descrições, mas há mais saídas para escolher.
A saída
imageCaptioné uma matriz de descrições, uma por imagem, indicada portagsque consistem em palavras simples e frases mais longas que descrevem a imagem. Observe que as marcas que consistem em um bando de gaivotas nadando na água ou um close de um pássaro.A saída
imageTagsé uma matriz de marcas simples, listadas na ordem de criação. Observe que as marcas se repetem. Não há agregação ou agrupamento.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Cenário: imagens incorporadas em PDFs
Quando as imagens que você deseja processar são inseridas em outros arquivos, como PDF ou DOCX, o pipeline de enriquecimento extrai apenas as imagens e as passa para o OCR ou para a análise de imagem para processamento. A extração de imagens ocorre durante a fase de decodificação do documento e, uma vez que as imagens são separadas, elas permanecem separadas, a menos que você mescle explicitamente a saída processada de volta no texto de origem.
A mesclagem de texto é usada para colocar a saída do processamento de imagem de volta no documento. Embora a mesclagem de texto não seja um requisito obrigatório, ela é frequentemente invocada para que a saída de imagem (texto de OCR, layout de OCR, texto, marcas de imagem, legendas de imagem) possa ser reintroduzida no documento. Dependendo da habilidade, a saída de imagem substitui uma imagem binária inserida por um equivalente de texto in-loco. A saída da Análise de Imagem pode ser mesclada no local da imagem. A saída de OCR sempre é exibida no final de cada página.
O fluxo de trabalho a seguir descreve o processo de extração, análise e mesclagem de imagem e como estender o pipeline para enviar a saída processada por imagem por push para outras habilidades baseadas em texto, como reconhecimento de entidade ou tradução de texto.
Depois de se conectar à fonte de dados, o indexador carrega e quebra documentos de origem, extraindo imagens e texto e enfileirando cada tipo de conteúdo para processamento. É criado um documento enriquecido que consiste apenas em um nó raiz (documento).
As imagens na fila são normalizadas e passadas para documentos enriquecidos como um nó documento/normalized_images.
Os enriquecimentos de imagem são executados usando
"/document/normalized_images"como entrada.As saídas de imagem são passadas para a árvore de documentos enriquecida, com cada saída como um nó separado. As saídas variam de acordo com a habilidade (texto e layoutText para o OCR; marcas e legendas para análise de imagem).
Opcional, mas recomendado se você quiser que os documentos de pesquisa incluam texto e texto de origem da imagem juntos, a mesclagem de texto é executada, combinando a representação de texto dessas imagens com o texto bruto extraído do arquivo. As partes de texto são consolidadas em uma única cadeia de caracteres grande, em que o texto é inserido primeiro na cadeia de caracteres e, em seguida, as saídas de texto OCR ou marcas e legendas de imagem.
Agora a saída da mesclagem de texto é o texto definitivo a ser analisado quanto a quaisquer habilidades downstream que executam o processamento de texto. Por exemplo, se o seu conjunto de habilidades incluir o OCR e o reconhecimento de entidade, a entrada para o reconhecimento de entidade deverá ser
"document/merged_text"(o targetName da saída da habilidade de mesclagem de texto).Depois que todas as habilidades foram executadas, o documento enriquecido é concluído. Na última etapa, os indexadores se referem a mapeamentos de campo de saída para enviar conteúdo enriquecido para campos individuais no índice de pesquisa.
O exemplo de conjunto de habilidades a seguir cria um campo merged_text que contém o texto original do documento com texto OCRed incorporado no lugar de imagens incorporadas. Ele também inclui uma habilidade de reconhecimento de entidade que usa merged_text como entrada.
Sintaxe de corpo da solicitação
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Agora que você tem um campo merged_text, você pode mapeá-lo como um campo pesquisável na definição do indexador. Todo o conteúdo dos arquivos, incluindo o texto das imagens, serão pesquisáveis.
Cenário: Visualizar caixas delimitadoras
Outro cenário comum é visualizar informações de layout dos resultados de pesquisa. Por exemplo, talvez você queira realçar o local em que um trecho de texto foi encontrado em uma imagem como parte dos resultados da pesquisa.
Como a etapa de OCR é realizada nas imagens normalizadas, as coordenadas de layout estão no espaço da imagem normalizada, mas se você precisar exibir a imagem original, converta os pontos de coordenada no layout para o sistema de coordenadas da imagem original.
O algoritmo a seguir ilustra o padrão:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Cenário: Habilidades personalizadas de imagem
As imagens também podem ser transmitidas e retornadas das habilidades personalizadas. Um conjunto de habilidades codifica em Base64 a imagem que está sendo transmitida para a habilidade personalizada. Para usar a imagem dentro da habilidade personalizada, defina "/document/normalized_images/*/data" como a entrada para a habilidade personalizada. No código da habilidade personalizado, decodifique a cadeia de caracteres em Base64 antes de convertê-la em uma imagem. Para retornar uma imagem para o conjunto de habilidades, codifique a imagem em Base64 antes de retorná-la para o conjunto de habilidades.
A imagem é retornada como um objeto com as propriedades a seguir.
{
"$type": "file",
"data": "base64String"
}
O repositório de exemplos do Python do Azure Search traz um exemplo completo implementado no Python de uma habilidade personalizada que enriquece imagens.
Como enviar imagens às habilidades personalizadas
Nos cenários em que você precisa usar uma habilidade personalizada para trabalhar com imagens, será possível enviar imagens a uma habilidade personalizada de modo que ela retorne textos ou imagens. O conjunto de habilidades a seguir foi extraído do exemplo.
O conjunto de habilidades abaixo usa a imagem normalizada (obtida durante a quebra de documento) e gera fatias dela.
Conjunto de habilidades de exemplo
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Exemplo de habilidade personalizada
Uma habilidade personalizada será criada fora do conjunto de habilidades. Neste caso, é um código Python que primeiro percorre o lote de registros de solicitação no formato de habilidade personalizada, depois converte a cadeia de caracteres codificada em base64 em uma imagem.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Da mesma forma, para retornar uma imagem, retorne uma cadeia de caracteres codificada em base64 em um objeto JSON com uma propriedade $type de arquivo.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}