O que são os conceitos de continuidade de negócios, alta disponibilidade e recuperação de desastres?
Este artigo define e descreve a continuidade de negócios e explica como planejá-la com relação ao gerenciamento de riscos por meio do design de alta disponibilidade e recuperação de desastres. Embora não sejam fornecidas diretrizes explícitas sobre como atender a necessidades de continuidade de negócios, é possível entender os conceitos usados nas diretrizes de confiabilidade da Microsoft.
A continuidade de negócios descreve o estado em que uma empresa pode continuar suas operações durante falhas, interrupções ou desastres. Ela requer planejamento proativo, preparação e a implementação de sistemas e processos resilientes.
Para planejar-se para a continuidade de negócios, é preciso identificar, compreender, classificar e gerenciar riscos. Com base nos riscos e nas respectivas probabilidades, elabore um plano que leve em consideração a HA (alta disponibilidade) e a DR (recuperação de desastre).
Alta disponibilidade significa desenvolver uma solução que seja resiliente aos problemas cotidianos e que atenda às necessidades de disponibilidade de negócios.
Recuperação de desastres consiste em planejar-se para lidar com riscos incomuns e possíveis interrupções catastróficas.
Continuidade de negócios
Em geral, as soluções de nuvem estão diretamente vinculadas a operações de negócios. Sempre que uma solução de nuvem fica indisponível ou apresenta um problema sério, o impacto nas operações de negócios pode ser grave. Esse tipo de impacto pode interromper a continuidade de negócios.
Os impactos graves na continuidade de negócios podem incluir:
- Perda de renda empresarial.
- Incapacidade de fornecer um serviço importante aos usuários.
- Violação de um compromisso assumido com um cliente ou outra parte.
É importante entender e comunicar as expectativas de negócios e as consequências de falhas às principais partes interessadas, incluindo aquelas que projetam, implementam e operam as cargas de trabalho. Assim, essas partes interessadas podem colaborar compartilhando os custos envolvidos no cumprimento desse planejamento. Em geral, há um processo de negociação e revisão dessa visão com base no orçamento e em outras restrições.
Planejamento de continuidade de negócios
Para controlar ou evitar completamente um impacto negativo na continuidade de negócios, é importante criar proativamente um plano de continuidade dos negócios. Esse tipo de plano é baseado na avaliação dos riscos e no desenvolvimento de métodos para controlá-los por meio de diversas abordagens. Os riscos específicos e as abordagens para mitigá-los variam para cada organização e carga de trabalho.
Um plano de continuidade de negócios não leva em consideração somente os recursos de resiliência da plataforma de nuvem em si, mas também os recursos do aplicativo. Um plano de continuidade de negócios avançado também incorpora todos os aspectos de suporte nos negócios, incluindo pessoas, processos manuais ou automatizados relacionados aos negócios e outras tecnologias.
O planejamento da continuidade de negócios deve incluir as seguintes etapas sequenciais:
Identificação de riscos. Identificar riscos à disponibilidade ou funcionalidade de uma carga de trabalho. Possíveis riscos podem incluir problemas de rede, falhas de hardware, erros humanos, indisponibilidade regional etc. Entenda o impacto de cada risco.
Classificação de risco. Classifique cada risco como comum ou incomum. Riscos comuns devem ser considerados nos planos de HA e riscos incomuns devem fazer parte do planejamento de DR.
Mitigação de riscos. Crie estratégias de mitigação para HA ou DR a fim de minimizar ou mitigar os riscos, por exemplo, por meio do uso de redundância, replicação, failover e backups. Considere também mitigações e controles não técnicos e baseados em processos.
O planejamento da continuidade de negócios é um processo, não um evento único. É importante revisar e atualizar regularmente qualquer plano de continuidade de negócios criado, a fim de garantir a relevância e a eficácia e atender às necessidades atuais dos negócios.
Identificação de riscos
A fase inicial no planejamento de continuidade de negócios envolve a identificação de riscos à disponibilidade ou à funcionalidade de uma carga de trabalho. É preciso analisar cada risco para entender a probabilidade e a gravidade associadas. A gravidade precisa incluir qualquer tempo de inatividade ou perda de dados possível, além de indicar se algum aspecto do restante do design da solução pode compensar os efeitos negativos.
A seguinte tabela é uma lista resumida de riscos, ordenados de maneira decrescente por probabilidade:
| Exemplo de risco | Descrição | Regularidade (probabilidade) |
|---|---|---|
| Problema temporário de rede | Uma falha temporária em um componente da pilha de rede, que pode ser recuperada após um curto período (em geral, alguns segundos ou menos). | Regular |
| Reinicialização de máquina virtual | Uma reinicialização de máquina virtual usada por você ou um serviço dependente. Reinicializações podem ocorrer porque a máquina virtual trava ou porque é preciso aplicar um patch. | Regular |
| Falha de hardware | Uma falha de componente em um data center, como um nó de hardware, rack ou cluster. | Ocasional |
| Interrupção de data center | Uma interrupção que afeta a maior parte ou todo o data center, como uma falha de energia, um problema de conectividade de rede ou problemas de aquecimento e resfriamento. | Incomum |
| Interrupção regional | Uma interrupção que afeta toda uma área metropolitana ou um perímetro maior, como um grande desastre natural. | Muito incomum |
O planejamento de continuidade de negócios não envolve somente a plataforma e a infraestrutura de nuvem. É importante considerar o risco de erros humanos. Além disso, alguns riscos que normalmente são considerados de segurança, desempenho ou operação também devem ser considerados como de confiabilidade porque afetam a disponibilidade da solução.
Estes são alguns exemplos:
| Exemplo de risco | Descrição |
|---|---|
| Perda ou corrupção de dados | Dados foram excluídos, substituídos ou corrompidos de alguma forma por um acidente ou uma violação de segurança, como um ataque de ransomware. |
| Bug de software | Uma implantação de um código novo ou atualizado introduz um bug que afeta a disponibilidade ou a integridade, deixando a carga de trabalho em um estado de mau funcionamento. |
| Implantações com falha | A implantação de um novo componente ou versão que falhou, deixando a solução em um estado inconsistente. |
| Ataques de negação de serviço | O sistema foi atacado com o objetivo de impedir o uso legítimo da solução. |
| Administradores desonestos | Um usuário com privilégios administrativos executou intencionalmente uma ação prejudicial ao sistema. |
| Entrada inesperada de tráfego em um aplicativo | Um pico de tráfego sobrecarregou os recursos do sistema. |
Na FMA (análise de modo de falha), são identificadas possíveis falhas que podem ocorrer em uma carga de trabalho ou nos componentes associados a ela e o comportamento que a solução teria nessas situações. Para saber mais, confira Recomendações para realizar a análise de modo de falha.
Classificação de risco
Os planos de continuidade de negócios devem abordar riscos comuns e incomuns.
Riscos comuns são planejados e esperados. Por exemplo, em um ambiente de nuvem, é comum que haja falhas temporárias, incluindo breves interrupções de rede, reinicializações de equipamentos devido a patches, tempos limite quando um serviço está ocupado etc. Como esses eventos acontecem regularmente, as cargas de trabalho precisam ser resilientes a eles.
Uma estratégia de alta disponibilidade deve considerar e controlar cada um desses riscos.
Riscos incomuns são geralmente o resultado de um evento imprevisível, como um desastre natural ou um grande ataque à rede, que pode levar a uma interrupção catastrófica.
Os processos de recuperação de desastres lidam com esses riscos raros.
Como a alta disponibilidade e a recuperação de desastres são correlacionadas, é importante planejar estratégias para ambas.
Além disso, é importante entender que a classificação de risco depende da arquitetura da carga de trabalho e dos requisitos de negócios. Alguns riscos podem ser classificados como HA para uma carga de trabalho e como DR para outra. Por exemplo, uma indisponibilidade total de uma região do Azure geralmente é considerada um risco de DR para as cargas de trabalho nessa região. No entanto, para as cargas de trabalho que usam diversas regiões do Azure em uma configuração ativa-ativa com replicação completa, redundância e failover automático de região, uma interrupção de região é classificada como um risco de HA.
Mitigação de risco
A mitigação de riscos consiste no desenvolvimento de estratégias de HA ou DR para minimizar ou mitigar riscos à continuidade de negócios. A mitigação de riscos pode ser baseada em tecnologias ou pessoas.
Mitigação de riscos baseada em tecnologia
A mitigação de riscos baseada em tecnologia usa controles de risco baseados na implementação e na configuração da carga de trabalho, como:
- Redundância
- Replicação de dados
- Failover
- Backups
Os controles de risco baseados em tecnologia devem ser considerados no contexto do plano de continuidade de negócios.
Por exemplo:
Requisitos de baixo tempo de inatividade. Alguns planos de continuidade de negócios não podem tolerar nenhum tipo de risco de tempo de inatividade devido a rigorosos requisitos de alta disponibilidade. Alguns controles baseados em tecnologia podem demorar para notificar as pessoas a fim de que elas respondam. Os controles de risco baseados em tecnologia que incluem processos manuais lentos provavelmente não são adequados para inclusão em uma estratégia de mitigação de riscos.
Tolerância a falhas parciais. Alguns planos de continuidade de negócios são capazes de tolerar a execução de fluxos de trabalho em um estado degradado. Quando uma solução opera em um estado degradado, alguns componentes podem ser desabilitados ou se tornar não funcionais, mas as principais operações de negócios continuam a ser realizadas. Para saber mais, confira Recomendações para self-healing e autopreservação.
Mitigação de riscos baseada em pessoas
A mitigação de riscos baseada em pessoas usa controles de risco baseados em processos de negócios, como os seguintes:
- Disparar um guia estratégico de resposta.
- Fazer fallback para operações manuais.
- Treinamento e mudanças culturais.
Importante
Pessoas que projetam, implementam, operam e desenvolvem a carga de trabalho devem ser competentes, encorajados a relatar suas preocupações e responsáveis pelo sistema.
Como os controles de risco baseados em pessoas costumam ser mais lentos do que os baseados em tecnologia e mais propensos a erros humanos, um bom plano de continuidade de negócios deve incluir um processo formal de controle de mudanças para qualquer coisa que altere o estado do sistema em execução. Por exemplo, considere implementar os seguintes processos:
- Teste rigorosamente suas cargas de trabalho, começando pelas mais críticas. Para evitar problemas relacionados a alterações, teste todas as alterações feitas na carga de trabalho.
- Introduza portas de qualidade estratégicas como parte das práticas de implantação segura de cargas de trabalho. Para saber mais, confira Recomendações para práticas de implantação segura.
- Formalize procedimentos para acesso de produção sob demanda e manipulação de dados. Essas atividades, independentemente de quão secundárias, podem apresentar um alto risco e causar incidentes de confiabilidade. Os procedimentos podem incluir o alinhamento com outro engenheiro, o uso de listas de verificação e a realização de avaliações por pares antes da execução de scripts ou da aplicação de alterações.
Alta disponibilidade
Alta disponibilidade é o estado em que uma carga de trabalho específica pode manter seu nível necessário de tempo de atividade no dia a dia, mesmo durante falhas temporárias e intermitentes. Como esses eventos acontecem regularmente, é importante que cada carga de trabalho seja projetada e configurada para alta disponibilidade, de acordo com os requisitos do aplicativo específico e as expectativas do cliente. A HA de cada carga de trabalho contribui para seu plano de continuidade de negócios.
Como a HA pode variar em cada carga de trabalho, é importante entender os requisitos e as expectativas do cliente ao determiná-la. Por exemplo, um aplicativo que é usado por sua organização para solicitar suprimentos de escritório pode exigir um nível de tempo de atividade relativamente baixo, enquanto um aplicativo financeiro crítico pode exigir um tempo de atividade muito maior. Mesmo em uma única carga de trabalho, fluxos diferentes podem ter requisitos diferentes. Por exemplo, em um aplicativo de comércio eletrônico, os fluxos que dão suporte à navegação dos clientes e à realização de pedidos podem ser mais importantes do que os fluxos de atendimento de pedidos e processamento de operações administrativas. Para saber mais sobre fluxos, confira Recomendações para identificar e classificar fluxos.
Normalmente, o tempo de atividade é medido com base no número de "noves" na porcentagem. Essa porcentagem está relacionada à quantidade de tempo de inatividade que você pode ter em um determinado período. Estes são alguns exemplos:
- Um requisito de tempo de atividade de 99,9% (três noves) permite aproximadamente 43 minutos de tempo de inatividade em um mês.
- Um requisito de tempo de atividade de 99,95% (três noves e meio) permite aproximadamente 21 minutos de inatividade em um mês.
Quanto maior o requisito de tempo de atividade, menor será a tolerância a interrupções e mais trabalho será necessário para atingir esse nível de disponibilidade. O tempo de atividade não é medido por um único componente, como um nó, mas pela disponibilidade geral de toda a carga de trabalho.
Importante
Não projete sua solução para atingir níveis de confiabilidade mais altos do que o necessário. Use os requisitos de negócios para orientar suas decisões.
Elementos de design de alta disponibilidade
Para atingir os requisitos de HA, uma carga de trabalho pode incluir diversos elementos de design. Alguns dos elementos comuns são listados e descritos abaixo nesta seção.
Observação
Algumas cargas de trabalho são críticas, o que significa que qualquer tempo de inatividade pode resultar em consequências graves à vida e à segurança das pessoas ou em grandes perdas financeiras. Para projetar uma carga de trabalho crítica, é importante ter algumas coisas em mente ao elaborar a solução e gerenciar a continuidade de negócios. Para saber mais, confira Azure Well-Architected Framework: cargas de trabalho críticas.
Serviços e camadas do Azure compatíveis com alta disponibilidade
Muitos serviços do Azure são projetados para oferecer alta disponibilidade e podem ser usados para criar cargas de trabalho altamente disponíveis. Estes são alguns exemplos:
- Os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure fornecem alta disponibilidade para VMs (máquinas virtuais), criando e gerenciando automaticamente instâncias de VM e as distribuindo para reduzir o impacto de falhas na infraestrutura.
- O Serviço de Aplicativo do Azure fornece alta disponibilidade por meio de uma variedade de abordagens, incluindo a movimentação automática de workers de um nó não íntegro para um íntegro e o fornecimento de recursos para self-healing de muitos tipos de falhas comuns.
Use cada guia de confiabilidade de serviço para entender os recursos do serviço, decidir quais camadas usar e determinar quais recursos incluir na estratégia de alta disponibilidade.
Confira os SLAs (acordos de nível de serviço) de cada serviço para entender os níveis esperados de disponibilidade e as condições a serem atendidas. Pode ser necessário selecionar ou evitar camadas específicas de serviços para atingir determinados níveis de disponibilidade. Alguns serviços da Microsoft são oferecidos sem SLA, como camadas de desenvolvimento ou básicas, ou com a condição de que o recurso pode ser recuperado do sistema em execução, como ofertas baseadas em spot. Além disso, algumas camadas adicionaram recursos de confiabilidade, como suporte para zonas de disponibilidade.
Tolerância a falhas
Tolerância a falhas é a habilidade que um sistema tem de continuar em operação, em alguma capacidade definida, no caso de uma falha. Por exemplo, um aplicativo Web pode ser projetado para continuar em operação mesmo quando um único servidor Web falha. A tolerância a falhas pode ser alcançada por meio de redundância, failover, particionamento, degradação gradual e outras técnicas.
A tolerância a falhas também exige que os aplicativos lidem com falhas temporárias. Ao criar seu próprio código, talvez seja necessário habilitar a manipulação de falhas temporárias. Alguns serviços do Azure fornecem manipulação integrada de falhas temporárias em algumas situações. Por exemplo, por padrão, os Aplicativos Lógicos do Azure repetem automaticamente solicitações com falha feitas a outros serviços. Para saber mais, confira Recomendações para lidar com falhas temporárias.
Redundância
Redundância é a prática de duplicar instâncias ou dados para aumentar a confiabilidade da carga de trabalho.
É possível atingir a redundância distribuindo réplicas ou instâncias redundantes de uma ou mais das seguintes maneiras:
- Em um data center (redundância local)
- Entre zonas de disponibilidade em uma região (redundância de zona)
- Em todas as regiões (redundância geográfica).
Confira exemplos de como alguns serviços do Azure fornecem opções de redundância:
- O Serviço de Aplicativo do Azure permite que você execute diversas instâncias de um aplicativo para garantir que ele permaneça disponível mesmo se uma delas falhar. Se você habilitar a redundância de zona, essas instâncias serão distribuídas em diversas zonas de disponibilidade na região do Azure que você usa.
- O Armazenamento do Azure fornece alta disponibilidade replicando dados automaticamente pelo menos três vezes. Você pode distribuir essas réplicas entre zonas de disponibilidade habilitando o ZRS (armazenamento com redundância de zona) e, em muitas regiões, também é possível replicar seus dados de armazenamento entre regiões usando o GRS (armazenamento com redundância geográfica).
- O Banco de Dados SQL do Azure tem diversas réplicas para garantir que os dados permaneçam disponíveis mesmo se uma delas falhar.
Para saber mais sobre redundância, confira Recomendações de design para redundância e Recomendações para usar regiões e zonas de disponibilidade.
Escalabilidade e elasticidade
Escalabilidade e elasticidade são as habilidades de um sistema de lidar com o aumento de carga por meio da adição e remoção de recursos (escalabilidade) e da agilidade na resposta de acordo com as mudanças de necessidades (elasticidade). Escalabilidade e elasticidade podem ajudar um sistema a manter a disponibilidade durante picos de carga.
Muitos serviços do Azure são compatíveis com a escalabilidade. Estes são alguns exemplos:
- Os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure, o Gerenciamento de API do Azure e diversos outros serviços são compatíveis com o dimensionamento automático do Azure Monitor. Com o dimensionamento automático do Azure Monitor, é possível especificar políticas como "quando minha CPU ultrapassar consistentemente 80%, adicionar outra instância".
- O Azure Functions pode provisionar instâncias dinamicamente para atender às suas solicitações.
- O Azure Cosmos DB é compatível com a taxa de transferência de dimensionamento automático, em que o serviço pode gerenciar automaticamente os recursos atribuídos aos bancos de dados com base nas políticas especificadas.
A escalabilidade é um fator essencial a ser considerado durante um mau funcionamento parcial ou completo. Quando uma réplica ou instância de computação não está disponível, os componentes restantes podem precisar dar suporte a mais carga para lidar com o que estava sendo tratado anteriormente pelo nó com falha. Considere o superprovisionamento se o seu sistema não puder ser dimensionado com rapidez suficiente para lidar com as mudanças esperadas na carga.
Para saber como projetar um sistema escalonável e elástico, confira Recomendações para elaborar uma estratégia de dimensionamento confiável.
Técnicas de implantação sem tempo de inatividade
Implantações e outras alterações no sistema apresentam um risco significativo de tempo de inatividade. Como o risco de tempo de inatividade é um desafio para os requisitos de alta disponibilidade, é importante usar práticas de implantação sem tempo de inatividade para fazer atualizações e alterações de configuração sem inatividade.
As técnicas de implantação sem tempo de inatividade podem incluir:
- Atualizar um subconjunto dos recursos por vez.
- Controlar a quantidade de tráfego que chega à nova implantação.
- Monitorar qualquer impacto aos usuários ou ao sistema.
- Corrigir problemas rapidamente, como reverter para uma implantação anterior conhecida como válida.
Para saber mais sobre as técnicas de implantação sem tempo de inatividade, confira Práticas de implantação segura.
O Azure usa abordagens de implantação sem tempo de inatividade para nossos próprios serviços. Ao criar seus aplicativos, você pode adotar implantações sem tempo de inatividade por meio de uma variedade de abordagens, como as seguintes:
- Os Aplicativos de Contêiner do Azure fornecem diversas avaliações do aplicativo, que podem ser usadas para realizar implantações sem tempo de inatividade.
- O AKS (Serviço de Kubernetes do Azure) é compatível com uma variedade de técnicas de implantação sem tempo de inatividade.
Embora as implantações sem tempo de inatividade sejam frequentemente associadas a implantações de aplicativos, elas também devem ser usadas para alterações de configuração. Confira algumas maneiras de aplicar alterações de configuração com segurança:
- O Armazenamento do Azure permite que você altere as chaves de acesso da conta de armazenamento em diversos estágios, o que evita o tempo de inatividade durante operações de rotação de chaves.
- A Configuração de Aplicativos do Azure fornece sinalizadores de recursos, instantâneos e outros recursos para ajudar você a controlar como as alterações de configuração são aplicadas.
Se você optar por não realizar implantações sem tempo de inatividade, será necessário definir janelas de manutenção para fazer alterações no sistema em momentos esperados pelos usuários.
Teste automatizado
É importante testar a capacidade da solução de acomodar interrupções e falhas que você considera estarem no escopo da HA. Muitas dessas falhas podem ser simuladas em ambientes de teste. Testar a capacidade da solução de tolerar ou se recuperar automaticamente de uma variedade de tipos de falhas é um processo chamado de engenharia do caos. A engenharia do caos é essencial para organizações maduras com padrões rigorosos de HA. O Azure Chaos Studio é uma ferramenta de engenharia do caos que pode simular alguns tipos de falhas comuns.
Para saber mais, confira Recomendações para elaborar uma estratégia de teste de confiabilidade.
Monitoramento e alertas
Com o monitoramento, é possível saber sobre a integridade do sistema, mesmo em caso de mitigações automatizadas. Ele é essencial para entender como a solução está se comportando e observar sinais antecipados de falhas, como o aumento nas taxas de erro ou o alto consumo de recursos. Com alertas, é possível receber notificações proativas de mudanças importantes no ambiente.
O Azure fornece uma variedade de recursos de monitoramento e alerta, incluindo os seguintes:
- O Azure Monitor coleta logs e métricas de recursos e aplicativos do Azure e pode enviar alertas e exibir dados em painéis.
- O Application Insights do Azure Monitor fornece monitoramento detalhado de aplicativos.
- Os serviços Integridade do Serviço do Azure e Azure Resource Health monitoram a integridade da plataforma Azure e seus recursos.
- Os Eventos Agendados informam quando há uma manutenção planejada para máquinas virtuais.
Para saber mais, confira Recomendações para projetar uma estratégia confiável de monitoramento e alerta.
Recuperação de desastre
Um desastre é um evento distinto, incomum e importante com um impacto maior e mais duradouro do que um aplicativo pode mitigar por meio do aspecto de alta disponibilidade do design. Exemplos de desastres incluem:
- Desastres naturais, como furacões, terremotos, inundações ou incêndios.
- Erros humanos que resultam em grande impacto, como exclusão acidental de dados de produção ou um firewall mal configurado que expõe dados confidenciais.
- Grandes incidentes de segurança, como negação de serviço ou ataques de ransomware, que levam à corrupção de dados, à perda de dados ou a interrupções de serviço.
A recuperação de desastres envolve planejar como você responde a esses tipos de situações.
Observação
Você deve seguir as práticas recomendadas na solução para minimizar a probabilidade desses eventos. No entanto, mesmo com um planejamento proativo e atento, é prudente planejar como você responderia a essas situações, caso elas aconteçam.
Requisitos de recuperação de desastres
Devido à raridade e à gravidade dos eventos de desastres, o planejamento de DR traz expectativas diferentes para sua resposta. Muitas organizações podem lidar com o fato de que, em um cenário de desastre, algum nível de inatividade ou perda de dados é inevitável. Um plano de DR completo deve especificar os seguintes requisitos de negócios críticos para cada fluxo:
O RPO (objetivo de ponto de recuperação) é a duração máxima de perda de dados aceitável em caso de desastres. Ele é medido em unidades de tempo, como "30 minutos de dados" ou "quatro horas de dados".
O RTO (objetivo de tempo de recuperação) é a duração máxima de tempo de inatividade aceitável no caso de um desastre, em que o "tempo de inatividade" é definido por sua especificação. Ele também é medido em unidades de tempo, como "oito horas de tempo de inatividade".
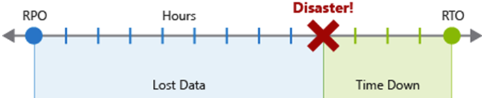
Cada componente ou fluxo na carga de trabalho pode ter valores individuais de RPO e RTO. Avalie os riscos do cenário de desastre e as possíveis estratégias de recuperação ao decidir os requisitos. O processo de especificação do RPO e do RTO cria efetivamente requisitos de DR para a carga de trabalho como resultado de preocupações comerciais específicas (custos, impacto, perda de dados etc.).
Observação
Embora seja tentador optar por zero RTO e zero RPO (sem tempo de inatividade e sem perda de dados em caso de desastre), isso é difícil e caro de implementar na prática. É importante que as partes interessadas técnicas e comerciais discutam esses requisitos em conjunto e decidam requisitos realistas. Para saber mais, confira Recomendações para definir destinos de confiabilidade.
Planos de Recuperação de Desastres
Independentemente da causa do desastre, é importante que você crie um plano de DR bem definido e testável. Esse plano será usado como parte da infraestrutura e do design do aplicativo para dar suporte ativo a ele. Você pode criar diversos planos de DR para diferentes tipos de situações. Em geral, os planos de DR dependem de controles de processo e intervenção manual.
A DR não é um recurso automático do Azure. No entanto, muitos serviços oferecem recursos e funcionalidades que você pode usar para dar suporte às suas estratégias de DR. Avalie os guias de confiabilidade de cada serviço do Azure para entender como ele e os respectivos recursos funcionam. Assim, é possível mapear esses recursos para o plano de DR.
As seções a seguir listam alguns elementos comuns de um plano de recuperação de desastres e descrevem como o Azure pode ajudar você a alcançá-los.
Failover e failback
Alguns planos de recuperação de desastres envolvem o provisionamento de uma implantação secundária em outro local. Se um desastre afetar a implantação primária da solução, o tráfego poderá fazer failover para o outro site. O failover requer planejamento e implementação atentos. O Azure fornece uma variedade de serviços para auxiliar no failover, como os seguintes:
- O Azure Site Recovery fornece failover automatizado para ambientes locais e soluções hospedadas em máquinas virtuais no Azure.
- O Azure Front Door e o Gerenciador de Tráfego do Azure oferecem suporte ao failover automatizado do tráfego de entrada entre diferentes implantações da solução, como em diferentes regiões.
Em geral, leva algum tempo para que um processo de failover detecte que a instância primária falhou e alterne para a secundária. Verifique se o RTO da carga de trabalho está alinhado com o tempo de failover.
Também é importante considerar o failback, que é o processo de restaurar operações na região primária após a recuperação dela. O failback pode ser complexo de planejar e implementar. Por exemplo, os dados na região primária podem ter sido gravados após o início do failover. Você precisará tomar decisões de negócios cuidadosas sobre como lidar com esses dados.
Backups
Os backups consistem em uma cópia dos dados e no armazenamento seguro deles por um período de tempo definido. Com eles, você pode recuperar-se de desastres quando o failover automático para outra réplica não é possível ou quando ocorre corrupção de dados.
Ao usar backups como parte de um plano de recuperação de desastres, é importante levar em consideração o seguinte:
Local de armazenamento. Ao usar backups como parte de um plano de recuperação de desastres, eles devem ser armazenados separadamente dos dados principais. Normalmente, os backups são armazenados em outra região do Azure.
Perda de dados. Em geral, como os backups são feitos com pouca frequência, a restauração de backups normalmente envolve perda de dados. Por esse motivo, a recuperação de backup deve ser usada como último recurso e um plano de recuperação de desastres deve especificar a sequência de etapas e tentativas de recuperação que devem ocorrer antes da restauração de um backup. É importante garantir que o RPO da carga de trabalho esteja alinhado com o intervalo de backup.
Tempo de recuperação. Como a restauração de backup geralmente leva tempo, é fundamental testar os backups e processos de restauração para verificar a integridade e entender quanto tempo o processo de restauração leva. Verifique se o RTO da carga de trabalho leva em conta o tempo necessário para restaurar o backup.
Muitos serviços de dados e armazenamento do Azure são compatíveis com backups, como os seguintes:
- O Backup do Azure fornece backups automatizados para discos de máquinas virtuais, contas de armazenamento, AKS e uma variedade de outras fontes.
- Muitos serviços de banco de dados do Azure, incluindo o Banco de Dados SQL do Azure e o Azure Cosmos DB, têm um recurso de backup automatizado para seus bancos de dados.
- O Azure Key Vault fornece recursos para fazer backup de seus segredos, certificados e chaves.
Implantações automatizadas
Para implantar e configurar rapidamente os recursos necessários em caso de desastre, use ativos de IaC (infraestrutura como código), como arquivos Bicep, modelos do ARM ou arquivos de configuração do Terraform. O uso da IaC reduz o tempo de recuperação e a probabilidade de erro, em comparação à implantação e à configuração manual de recursos.
Testes e exercícios
É essencial validar e testar com frequência os planos de DR, bem como a estratégia de confiabilidade mais ampla. Inclua todos os processos humanos nos exercícios e não se concentre somente nos processos técnicos.
Se você não testar os processos de recuperação em uma simulação de desastre, a chance será maior de enfrentar grandes problemas ao usá-los em um desastre real. Além disso, ao testar os planos de DR e os processos necessários, você pode validar a viabilidade do RTO.
Para saber mais, confira Recomendações para elaborar uma estratégia de teste de confiabilidade.
Conteúdo relacionado
- Use os guias de confiabilidade do serviço do Azure para entender como cada serviço do Azure dá suporte à confiabilidade no design e para aprender sobre os recursos que você pode incorporar aos planos de HA e DR.
- Use o Azure Well-Architected Framework: confiabilidade para saber como projetar uma carga de trabalho confiável no Azure.
- Use a perspectiva do Well-Architected Framework sobre os serviços do Azure para saber como configurar cada serviço do Azure a fim de atender aos seus requisitos de confiabilidade e aos outros pilares da Well-Architected Framework.
- Para saber mais sobre o planejamento de recuperação de desastres, confira Recomendações para projetar uma estratégia de recuperação de desastres.