Visão geral da continuidade dos negócios com o Banco de Dados do Azure para PostgreSQL – servidor flexível
APLICA-SE A:  Banco de dados do Azure para PostgreSQL – Servidor Flexível
Banco de dados do Azure para PostgreSQL – Servidor Flexível
A continuidade dos negócios no servidor flexível do Banco de Dados do Azure para PostgreSQL refere-se aos mecanismos, políticas e procedimentos que permitem que sua empresa continue operando quando ocorrem interrupções, especialmente em sua infraestrutura de computação. Na maioria dos casos, o servidor flexível do Banco de Dados do Azure para PostgreSQL lida com eventos disruptivos que podem acontecer no ambiente de nuvem e mantêm seus aplicativos e processos empresariais em execução. No entanto, há alguns eventos que não podem ser tratados automaticamente, como os seguintes:
- O usuário exclui ou atualiza acidentalmente uma linha em uma tabela.
- O terremoto causa falta de energia e desativa temporariamente uma zona de disponibilidade ou uma região.
- Aplicação de patch de banco de dados necessária para corrigir um problema de segurança ou bug.
O servidor flexível do Banco de Dados do Azure para PostgreSQL fornece recursos que protegem dados e atenuam o tempo de inatividade para seus bancos de dados de missão crítica durante eventos de tempo de inatividade planejados e não planejados. Criado com base na infraestrutura do Azure que oferece resiliência e disponibilidade robustas, o servidor flexível do Banco de Dados do Azure para PostgreSQL tem recursos de continuidade de negócios que fornecem outra proteção contra falhas, atendem a requisitos de tempo de recuperação e reduzem a exposição à perda de dados. Ao arquitetar seus aplicativos, você deve considerar a tolerância ao tempo de inatividade, que é o RTO (objetivo de tempo de recuperação) e a exposição à perda de dados, que é o RPO (objetivo de ponto de recuperação). Por exemplo, um banco de dados comercialmente crítico requer requisitos de tempo de atividade mais rígidos que um banco de dados de teste.
A tabela a seguir ilustra os recursos que o servidor flexível do Banco de Dados do Azure para PostgreSQL oferece.
| Recurso | Descrição | Considerações |
|---|---|---|
| Backups automáticos | O servidor flexível do Banco de Dados do Azure para PostgreSQL executa automaticamente backups diários de seus arquivos de banco de dados e faz backup contínuo dos logs de transações. Os backups podem ser mantidos de sete dias até 35 dias. É possível restaurar o servidor de banco de dados para qualquer ponto no tempo dentro do período de retenção do backup. O RTO depende do tamanho dos dados a serem restaurados + o tempo para executar a recuperação de log. Pode ser de alguns minutos até 12 horas. Para obter mais detalhes, confira Conceitos – backup e restauração. | Os dados de backup permanecem dentro da região. |
| Alta disponibilidade com redundância de zona | O servidor flexível do Banco de Dados do Azure para PostgreSQL pode ser implantado com a configuração de alta disponibilidade (HA) com redundância de zona, em que os servidores primários e em espera são implantados em duas zonas de disponibilidade diferentes dentro de uma região. Essa configuração de HA protege seus bancos de dados contra falhas no nível da zona e também ajuda a reduzir o tempo de inatividade do aplicativo durante eventos de tempo de inatividade planejado e não planejado. Os dados do servidor primário são replicados para a réplica em espera no modo síncrono. No caso de qualquer interrupção no servidor primário, o servidor passará por failover automaticamente na réplica em espera. O RTO na maioria dos casos deve ser menor que 120s. O RPO deve ser zero (sem perda de dados). Para obter mais informações, confira a [documentação de conceitos de alta disponibilidade]/azure/reliability/reliability-postgresql-flexible-server. | Com suporte nas camadas de computação de uso geral e otimizado para memória. Disponível apenas em regiões em que há várias zonas disponíveis. |
| Alta disponibilidade na mesma zona | O servidor flexível do Banco de Dados do Azure para PostgreSQL pode ser implantado com a mesma configuração de alta disponibilidade (HA) de zona em que os servidores primários e em espera são implantados na mesma zona de disponibilidade em uma região. Essa configuração de HA protege seus bancos de dados contra falhas no nível de nó e também ajuda a reduzir o tempo de inatividade do aplicativo durante eventos de tempo de inatividade planejado e não planejado. Os dados do servidor primário são replicados para a réplica em espera no modo síncrono. No caso de qualquer interrupção no servidor primário, o servidor passará por failover automaticamente na réplica em espera. O RTO na maioria dos casos deve ser menor que 120s. O RPO deve ser zero (sem perda de dados). Para obter mais informações, confira a [documentação de conceitos de alta disponibilidade]/azure/reliability/reliability-postgresql-flexible-server. | Com suporte nas camadas de computação de uso geral e otimizado para memória. |
| Discos gerenciados Premium | Os arquivos de banco de dados são armazenados em um armazenamento gerenciado Premium altamente durável e confiável. Isso fornece redundância de dados com três cópias de réplicas armazenadas em uma zona de disponibilidade com recursos de recuperação automática de dados. Para obter mais informações, confira a documentação de discos gerenciados. | Dados armazenados em uma zona de disponibilidade. |
| Backup com redundância de zona | Os backups de servidor flexível do Banco de Dados do Azure para PostgreSQL são armazenados automaticamente e com segurança em um armazenamento com redundância de zona em uma região, se a região der suporte a zonas de disponibilidade. Durante uma falha no nível da zona em que o servidor é provisionado, se o servidor não estiver configurado com redundância de zona, ainda será possível restaurar o banco de dados usando o ponto de restauração mais recente em uma zona diferente. Para obter mais informações, confira Conceitos – backup e restauração. | Aplicável somente em regiões em que várias zonas estão disponíveis. |
| Backup de redundância geográfica | Os backups de servidor flexível do Banco de Dados do Azure para PostgreSQL são copiados para uma região remota. que ajuda na situação de recuperação de desastre caso a região do servidor primário esteja inoperante. | Este recurso está habilitado no momento nas regiões selecionadas. Ele usa um RTO mais longo e um RPO maior, dependendo do tamanho dos dados a serem restaurados e da quantidade de recuperação a ser executada. |
| Réplica de leitura | Réplicas de leitura entre regiões podem ser implantadas para proteger seus bancos de dados contra falhas no nível da região. As réplicas de leitura são atualizadas assincronamente usando a tecnologia de replicação física do PostgreSQL e podem atrasar o primário. Para obter mais informações, confira Conceitos – Réplicas de leitura. | Com suporte nas camadas de computação de uso geral e otimizado para memória. |
A tabela a seguir compara RTO e OPR em um cenário típico de carga de trabalho:
| Recurso | Com capacidade de intermitência | Uso Geral | Otimizado para memória |
|---|---|---|---|
| Recuperação Pontual do backup | Qualquer ponto de restauração dentro do período de retenção RTO – Varia RPO < 5 min |
Qualquer ponto de restauração dentro do período de retenção RTO – Varia RPO < 5 min |
Qualquer ponto de restauração dentro do período de retenção RTO – Varia RPO < 5 min |
| Restauração geográfica de backups replicados geograficamente | RTO – Varia RPO < 1 h |
RTO – Varia RPO < 1 h |
RTO – Varia RPO < 1 h |
| Réplicas de leitura | RTO – Minutos* RPO < 5 min* |
RTO – Minutos* RPO < 5 min* |
RTO – Minutos* RPO < 5 min* |
*Em alguns casos, o RTO e o OPR podem ser muito maiores, dependendo de vários fatores, incluindo a latência entre sites, a quantidade de dados a serem transmitidos e, principalmente, a carga de trabalho de gravação do banco de dados primário.
Eventos de tempo de inatividade planejado
Abaixo estão alguns cenários de manutenção planejada. Normalmente, esses eventos geram até alguns minutos de inatividade e sem perda de dados.
| Cenário | Processo |
|---|---|
| Escala de computação (iniciada pelo usuário) | Durante a operação de dimensionamento de computação, pontos de verificação ativos podem ser concluídos, as conexões de cliente são descarregadas, todas as transações não confirmadas são canceladas, o armazenamento é desanexado e depois desligado. Uma nova instância de servidor flexível do Banco de Dados do Azure para PostgreSQL com o mesmo nome de servidor de banco de dados é provisionada com a configuração de computação dimensionada. Em seguida, o armazenamento é anexado ao novo servidor e o banco de dados é iniciado, o que executa a recuperação, se necessário, antes de aceitar conexões de clientes. |
| Expansão do armazenamento (iniciado pelo usuário) | Quando a expansão de uma operação de armazenamento é iniciada, os pontos de verificação ativos têm permissão para serem concluídos, as conexões de cliente são descarregadas e todas as transações não confirmadas são canceladas. Depois disso, o servidor é desligado. O armazenamento é dimensionado para o tamanho desejado e então anexado ao novo servidor. Uma recuperação é executada, se necessário, antes de aceitar conexões de cliente. Observe que não há suporte para a redução vertical do tamanho do armazenamento. |
| Nova implantação de software (iniciada pelo Azure) | Novos recursos de distribuição ou correções de bugs ocorrem automaticamente como parte da manutenção planejada do serviço, e você pode agendar quando essas atividades ocorrerem. Para obter mais informações, verifique o portal. |
| Atualizações de versão secundárias (iniciadas pelo Azure) | O Banco de Dados do Azure para PostgreSQL corrige automaticamente os servidores de banco de dados para a versão secundária determinada pelo Azure. Isso acontece como parte da manutenção planejada do serviço. O servidor de banco de dados é reiniciado automaticamente com a nova versão secundária. Para obter mais informações, consulte a documentação. Você também pode verificar seu portal. |
Quando a instância do servidor flexível do Banco de Dados do Azure para PostgreSQL é configurada com alta disponibilidade, o serviço executa primeiro o dimensionamento e as operações de manutenção no servidor em espera. Para obter mais informações, confira a [documentação de conceitos de alta disponibilidade]/azure/reliability/reliability-postgresql-flexible-server.
Mitigação de tempo de inatividade não planejada
Os tempos de inatividade não planejados podem ocorrer como resultado de interrupções imprevisíveis, como falha de hardware subjacente, problemas de rede e bugs de software. Se o servidor de banco de dados configurado com alta disponibilidade falhar inesperadamente, a réplica em espera será ativada e os clientes poderão retomar as operações. Se não estiver configurado com alta disponibilidade (HA), se a tentativa de reinicialização falhar, um novo servidor de banco de dados será provisionado automaticamente. Embora um tempo de inatividade não planejado não possa ser evitado, o servidor flexível do Banco de Dados do Azure para PostgreSQL ajuda a reduzir o tempo de inatividade executando automaticamente operações de recuperação sem a necessidade de intervenção humana.
Embora nos esforcemos continuamente para fornecer alta disponibilidade, há momentos em que o servidor flexível do Banco de Dados do Azure para PostgreSQL sofre interrupções, causando indisponibilidade dos bancos de dados e, portanto, afetando o seu aplicativo. Quando nosso monitoramento de serviço detecta problemas que causam erros generalizados de conectividade, falhas ou problemas de desempenho, o serviço declara automaticamente uma interrupção para mantê-lo informado.
Interrupção do serviço
No caso de interrupção do servidor flexível do Banco de Dados do Azure para PostgreSQL, você poderá ver mais detalhes relacionados à interrupção nos seguintes locais:
- Banner do portal do Azure Se sua assinatura for identificada como afetada, haverá um alerta de interrupção de um problema de Serviço nas Notificações do portal do seu Azure.
- Ajuda + suporte ou Suporte + solução de problemas: quando você criar um tíquete de suporte em Ajuda + suporte ou em Suporte + solução de problemas, haverá informações sobre os problemas que possam afetar seus recursos. Selecione Exibir os detalhes da interrupção para obter mais informações e um resumo do impacto. Também haverá um alerta na página Nova solicitação de suporte.
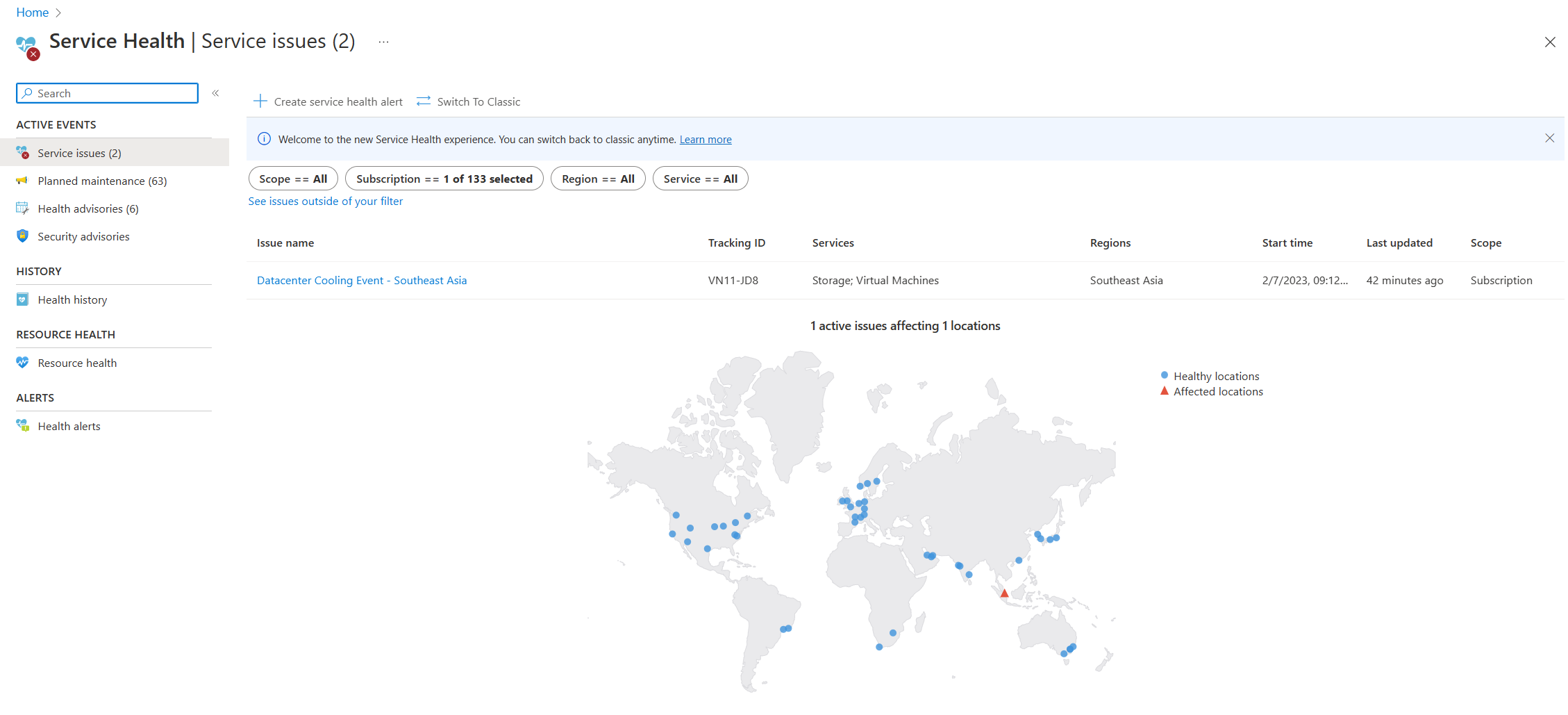
- Ajuda do Serviço: a página Integridade do Serviço no portal do Azure contém informações sobre o status do datacenter do Azure globalmente. Pesquise "integridade do serviço" na barra de pesquisa no portal do Azure e exiba Problemas de serviço na categoria Eventos ativos. Você também pode exibir a integridade de recursos individuais na página Integridade do recurso de qualquer recurso no menu Ajuda. Confira a seguir uma captura de tela de exemplo da página Integridade do Serviço, com informações sobre um problema de serviço ativo no Sudeste da Ásia.
- Notificação por email: se você tiver configurado alertas, uma notificação por email chegará quando uma interrupção de serviço afetar sua assinatura e seus recursos. Os emails chegam de "azure-noreply@microsoft.com". O corpo do email começaria com "O alerta do log de atividades... foi disparado por um problema de serviço para a assinatura do Azure...". Para obter mais informações sobre alertas de integridade do serviço, confira Receber alertas do log de atividades em notificações de serviço do Azure usando o portal do Azure.
Importante
Como o nome implica, os espaços de tabela temporária no PostgreSQL são usados para objetos temporários, bem como outras operações internas de banco de dados, como classificação. Portanto, não recomendamos a criação de objetos de esquema de usuário em um espaço de tabela temporária, pois não garantimos a durabilidade desses objetos após reinicializações do servidor, failovers de HA etc.
Tempo de inatividade não planejado: cenários de falha e recuperação de serviço
Abaixo estão alguns cenários de falha não planejados e o processo de recuperação.
| Cenário | Processo de recuperação [Servidores configurados sem HA com redundância de zona] |
Processo de recuperação [Servidores configurados com HA com redundância de zona] |
|---|---|---|
| Falha no servidor de banco de dados | Se o servidor de banco de dados estiver inoperante, o Azure tentará reiniciar o servidor de banco de dados. Se isso falhar, o servidor de banco de dados será reiniciado em outro nó físico. O tempo de recuperação (RTO) depende de vários fatores, incluindo a atividade no momento da falha, como transação grande e o volume de recuperação a ser executado durante o processo de inicialização do servidor de banco de dados. Os aplicativos que usam os bancos de dados do PostgreSQL precisam ser criados para detectar e repetir as conexões e transações que falharam. |
Se a falha do servidor de banco de dados for detectada, o servidor passará por failover para o servidor em espera, reduzindo o tempo de inatividade. Para obter mais informações, consulte [página conceitos de HA]/azure/reliability/reliability-postgresql-flexible-server. O RTO deve estar entre 60 e 120s, com perda de dados zero. |
| Falha de armazenamento | Os aplicativos não detectam impactos relacionados aos problemas de armazenamento, como uma falha de disco ou uma corrupção do bloco físico. À medida que os dados são armazenados em três cópias, a cópia dos dados é atendida pelo armazenamento sobrevivente. O bloco de dados corrompido é automaticamente reparado e uma nova cópia dos dados é criada também de modo automático. | Para erros raros e irrecuperáveis, como aqueles em que o armazenamento inteiro fica inacessível, a instância do servidor flexível do Banco de Dados do Azure para PostgreSQL faz failover para a réplica em espera para reduzir o tempo de inatividade. Para obter mais informações, consulte [página conceitos de HA]/azure/reliability/reliability-postgresql-flexible-server. |
| Erros de usuário/lógicos | Para se recuperar de erros do usuário, como tabelas descartadas por engano ou dados atualizados de modo incorreto, você precisa executar uma PITR (recuperação pontual). Ao executar a operação de restauração, você especifica o ponto de restauração personalizado, que é a hora certa antes do erro. Se você quiser restaurar apenas um subconjunto de bancos de dados ou tabelas específicas, em vez de todos os bancos de dados no servidor de banco de dados, poderá restaurar o servidor de banco de dados em uma nova instância, exportar as tabelas por meio de pg_dump e usar pg_restore para restaurar essas tabelas em seu banco de dados. |
Esses erros de usuário não são protegidos com alta disponibilidade, pois todas as alterações são replicadas para a réplica em espera de maneira síncrona. Você precisa executar a restauração pontual para se recuperar desses erros. |
| Falha na zona de disponibilidade | Para se recuperar de uma falha no nível de zona, você pode executar uma restauração pontual usando o backup e escolhendo um ponto de restauração personalizado com a hora mais recente para restaurar os dados mais recentes. Uma nova instância do servidor flexível do Banco de Dados do Azure para PostgreSQL é implantada em outra zona não afetada. O tempo necessário para a restauração depende do backup anterior e do volume de logs de transações a serem recuperados. | O servidor flexível do Banco de Dados do Azure para PostgreSQL faz failover automaticamente para o servidor em espera em 60 a 120 segundos e sem perda de dados. Para obter mais informações, consulte [página conceitos de HA]/azure/reliability/reliability-postgresql-flexible-server. |
| Falha de região | Se o servidor estiver configurado com o backup com redundância geográfica, você poderá executar a restauração geográfica na região emparelhada. Um novo servidor será provisionado e recuperado para os últimos dados disponíveis que foram copiados para essa região. Você também pode usar réplicas de leitura entre regiões. Em caso de falha na região, você pode executar a operação de recuperação de desastre promovendo sua réplica de leitura para ser um servidor autônomo de leitura gravável. Espera-se que o RPO seja de até 5 minutos (perda de dados possível), exceto no caso de falha regional grave quando o RPO pode estar próximo do retardo de replicação no momento da falha. |
Mesmo processo. |
Configurar seu banco de dados após a recuperação de uma falha regional
- Se estiver usando a restauração geográfica ou a replicação geográfica para se recuperar de uma interrupção, você deverá se certificar de que a conectividade com o novo banco de dados esteja configurada corretamente para que o funcionamento normal do aplicativo possa ser retomado. Você pode seguir as Tarefas de pós-restauração.
- Se você já definiu uma configuração de diagnóstico no servidor original, faça o mesmo no servidor de destino, se necessário, conforme explicado em Configurar e acessar logs no Banco de Dados do Azure para PostgreSQL – Servidor Flexível.
- Configurar alertas de telemetria. Você precisa certificar-se de que as configurações de regra de alerta existentes estejam atualizadas para mapear para o novo servidor. Para obter mais informações sobre regras de alerta, consulte Usar o portal do Azure para configurar alertas em métricas para o Banco de Dados do Azure para PostgreSQL – Servidor Flexível.
Importante
Servidores excluídos podem ser restaurados. Se você excluir o servidor, poderá seguir nossas diretrizes para Restaurar um banco de dados do Azure removido – Banco de Dados do Azure para PostgreSQL – Servidor flexível para recuperá-lo. Use o bloqueio de recursos do Azure para ajudar a evitar a exclusão acidental do seu servidor.