Tutorial: Use o designer para implantar um modelo de machine learning
Em parte um deste tutorial, você treinou um modelo de regressão linear que prevê preços de carros. Nesta segunda parte, você usará o designer do Azure Machine Learning para implantar o modelo, de modo que outros possam utilizá-lo.
Observação
O designer dá suporte a dois tipos de componentes: componentes predefinidos clássicos (v1) e componentes personalizados (v2). Esses dois tipos de componentes NÃO são compatíveis.
Componentes predefinidos clássicos fornecem componentes predefinidos, principalmente para processamento de dados e tarefas tradicionais de aprendizado de máquina, como regressão e classificação. Esse tipo de componente continua a ter suporte, mas novos componentes não serão adicionados.
Componentes personalizados permitem que você encapsule seu próprio código como um componente. Eles suportam o compartilhamento de componentes entre workspaces e a criação contínua entre o Estúdio do Machine Learning, CLI v2 e interfaces SDK v2.
Para novos projetos, aconselhamos que você use componentes personalizados, que são compatíveis com o Azure Machine Learning v2 e continuarão recebendo novas atualizações.
Este artigo se aplica aos componentes predefinidos clássicos e não é compatível com CLI v2 e SDK v2.
Neste tutorial, você:
- Criará um pipeline de inferência em tempo real.
- Criará um cluster de inferência.
- Implantará o ponto de extremidade em tempo real.
- Testará o ponto de extremidade em tempo real.
Pré-requisitos
Conclua a parte um do tutorial para aprender a treinar e pontuar um modelo de machine learning na interface visual.
Importante
Se você não vir elementos gráficos mencionados neste documento, como botões no estúdio ou designer, pode ser que você não tenha o nível certo de permissões no workspace. Entre em contato com seu administrador de assinatura do Azure para verificar se você recebeu o nível de acesso correto. Para obter mais informações, confira Gerenciar usuários e funções.
Criar um pipeline de inferência em tempo real
Para implantar o pipeline, primeiro, converta o pipeline de treinamento em um pipeline de inferência em tempo real. Esse processo remove componentes de treinamento e adiciona entradas e saídas do serviço Web para processar as solicitações.
Observação
O recurso Criar pipeline de inferência dá suporte a pipelines de treinamento que contêm apenas componentes integrados do designer e que têm um componente como Treinar Modelo, que gera o modelo treinado.
Criar um pipeline de inferência em tempo real
Selecione Pipelines no painel de navegação lateral, em seguida, abra o trabalho de pipeline que você criou. Na página de detalhes, acima da tela do pipeline, selecione os três pontos ..., depois escolha Criar pipeline de inferência>Pipeline de inferência em tempo real.
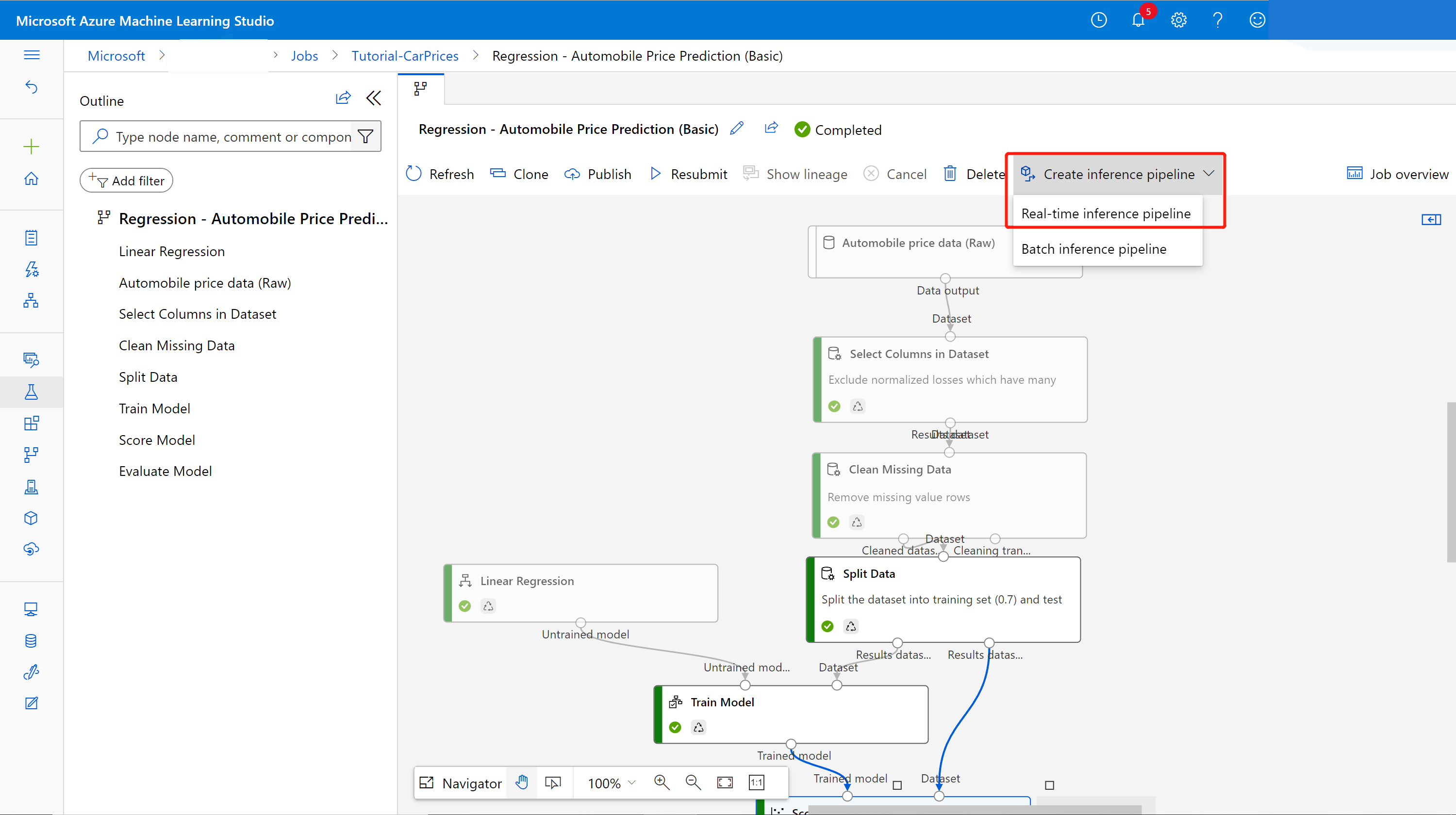
Seu novo pipeline agora se parecerá com isto:
Quando você seleciona Criar pipeline de inferência, várias coisas acontecem:
- O modelo treinado é armazenado como um componente de Conjunto de dados na paleta de componentes. Você pode encontrá-lo em Meus conjuntos de dados.
- Os componentes de treinamento como Treinar Modelo e Dividir Dados são removidos.
- O modelo treinado salvo é adicionado de volta ao pipeline.
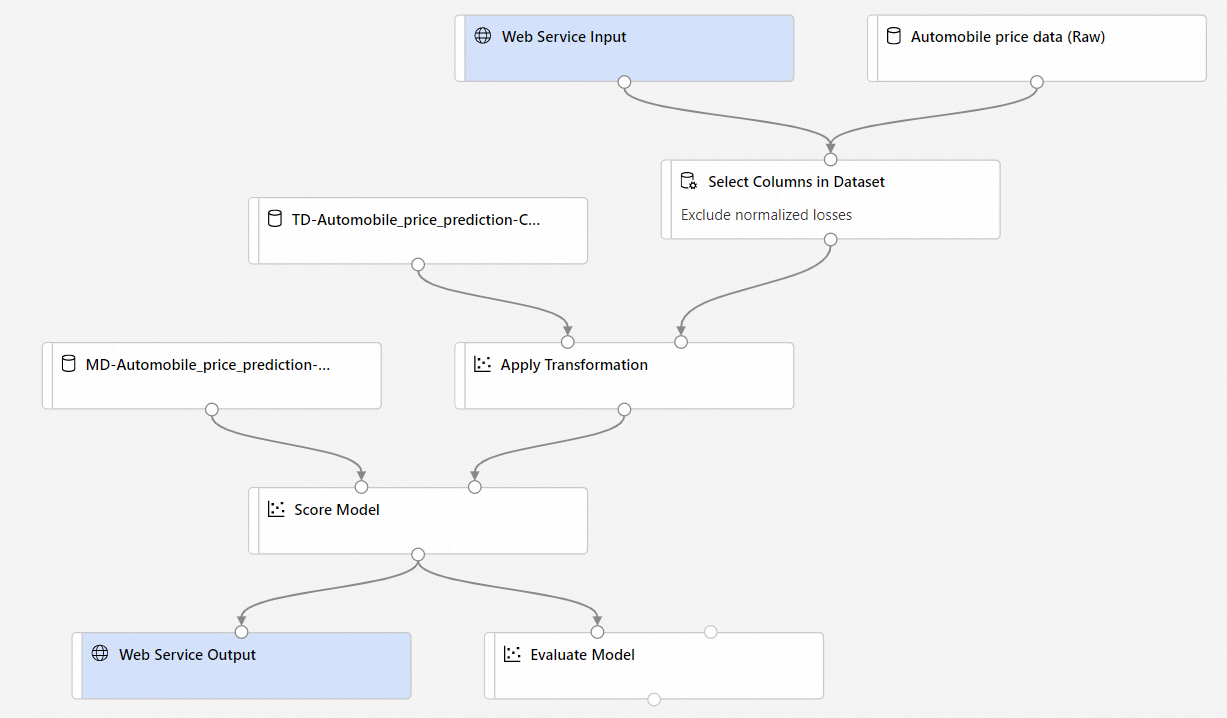
- Os componentes Entrada de Serviço Web e Saída de Serviço Web são adicionados. Esses componentes mostram o local em que os dados do usuário entram no pipeline e o local em que são retornados.
Observação
Por padrão, a Entrada do Serviço Web espera o mesmo esquema de dados que o componente de saída de dados que se conecta à mesma porta downstream. Neste exemplo, Entrada do Serviço Web e Dados (Brutos) de preço de automóveis se conectam ao mesmo componente downstream, então a Entrada do Serviço Web espera o mesmo esquema de dados que os Dados (Brutos) de preço de automóveis, e a coluna da variável alvo
priceestá incluída no esquema. No entanto, ao pontuar os dados, você não saberá os valores da variável do alvo. Nesse caso, você pode remover a coluna da variável do alvo no pipeline de inferência usando o componente Selecionar Colunas no Conjunto de Dados. Ao remover a coluna de variável de destino, verifique se a saída de Selecionar Colunas no Conjunto de Dados está conectada à mesma porta que a saída do componente Entrada do Serviço Web.Selecione Configurar e Enviar e use o mesmo destino de computação e experimento que você usou na parte um.
Se este for o primeiro trabalho, pode levar até 20 minutos para que seu pipeline termine de ser executado. As configurações de computação padrão têm um tamanho de nó mínimo de 0, o que significa que o designer precisa alocar recursos depois de ficar ocioso. Trabalhos de pipeline repetidos levam menos tempo, pois os recursos de computação já estão alocados. Além disso, o designer usa resultados armazenados em cache para cada componente para melhorar ainda mais a eficiência.
Vá para os detalhes do trabalho do pipeline de inferência em tempo real selecionando Detalhes do trabalho no painel esquerdo.
Selecione Implantar na página de detalhes do trabalho.
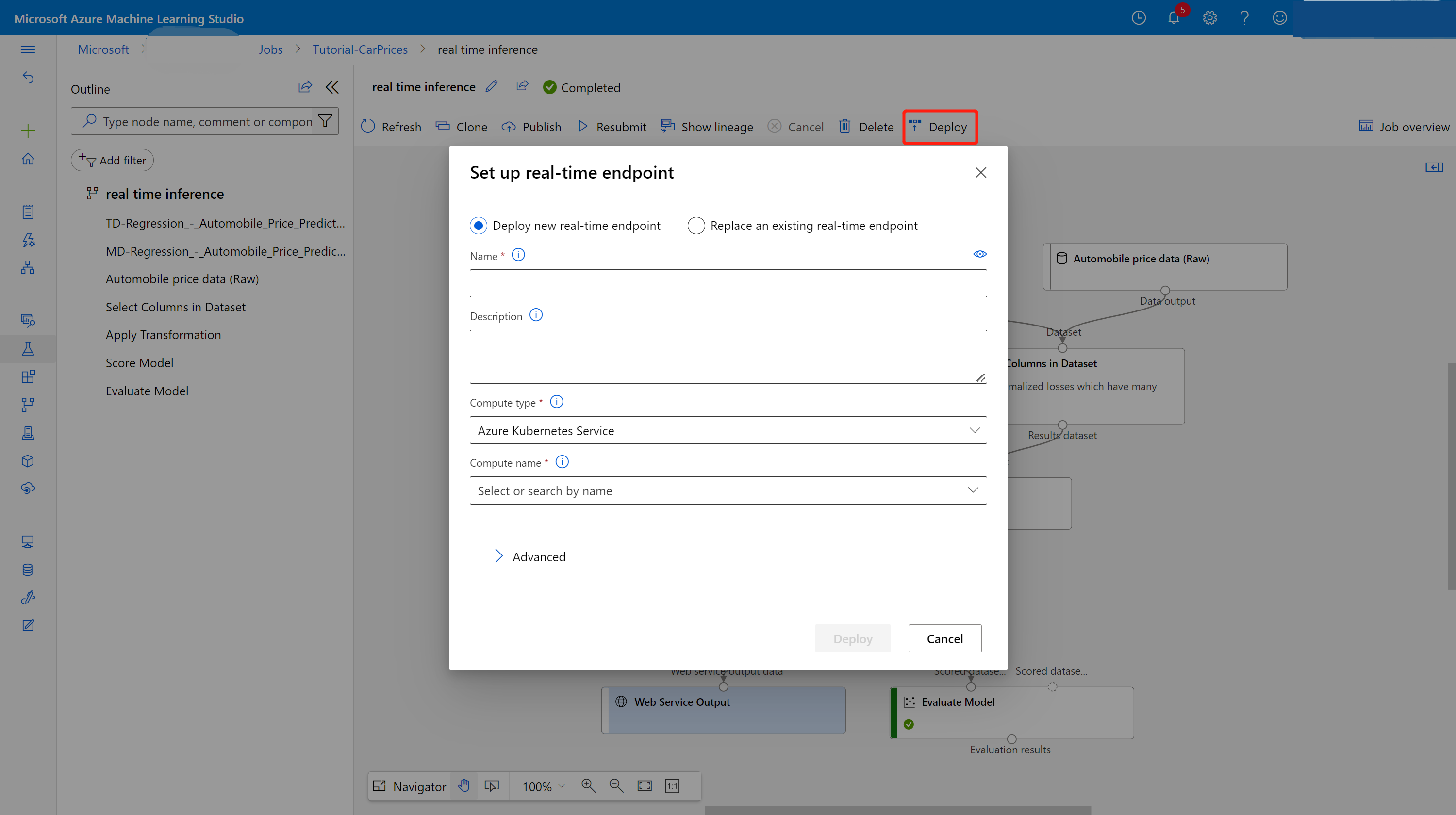


Cria um cluster inferência
Na caixa de diálogo exibida, selecione uma opção entre os clusters existentes do AKS (Serviço de Kubernetes do Azure) no qual o modelo será implantado. Se não tiver um cluster do AKS, use as etapas a seguir para criar um.
Vá para a página Computação selecionando Computação na caixa de diálogo.
Na faixa de navegação, selecione Clusters do Kubernetes>+ Novo.
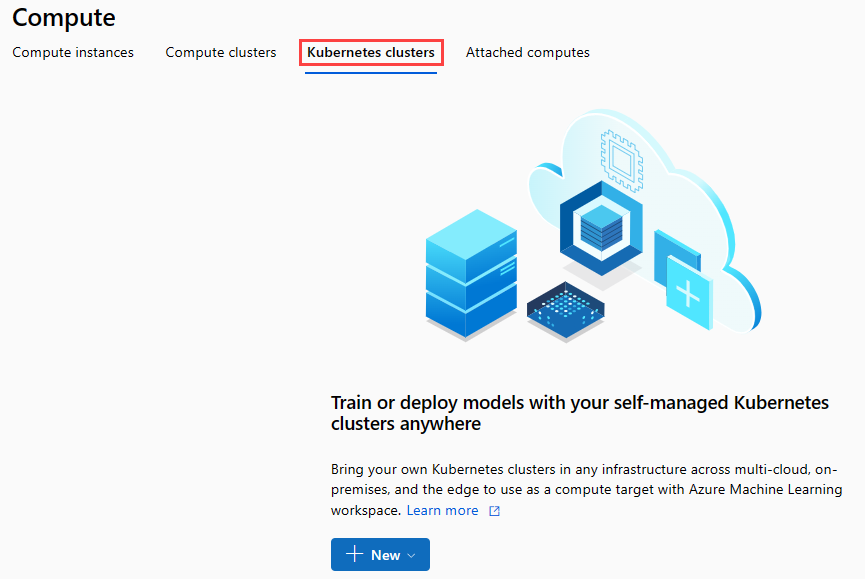
No painel do cluster de inferência, configure um novo Serviço de Kubernetes.
Insira aks-compute para o Nome de computação.
Selecione uma região próxima que esteja disponível para a Região.
Selecione Criar.
Observação
Leva aproximadamente 15 minutos para criar um novo serviço do AKS. Verifique o estado de provisionamento na página Clusters de Inferência.
Implantar o ponto de extremidade em tempo real
Após o término do provisionamento do seu serviço AKS, retorne ao pipeline de inferência em tempo real para concluir a implantação.
Selecione Implantar acima da tela.
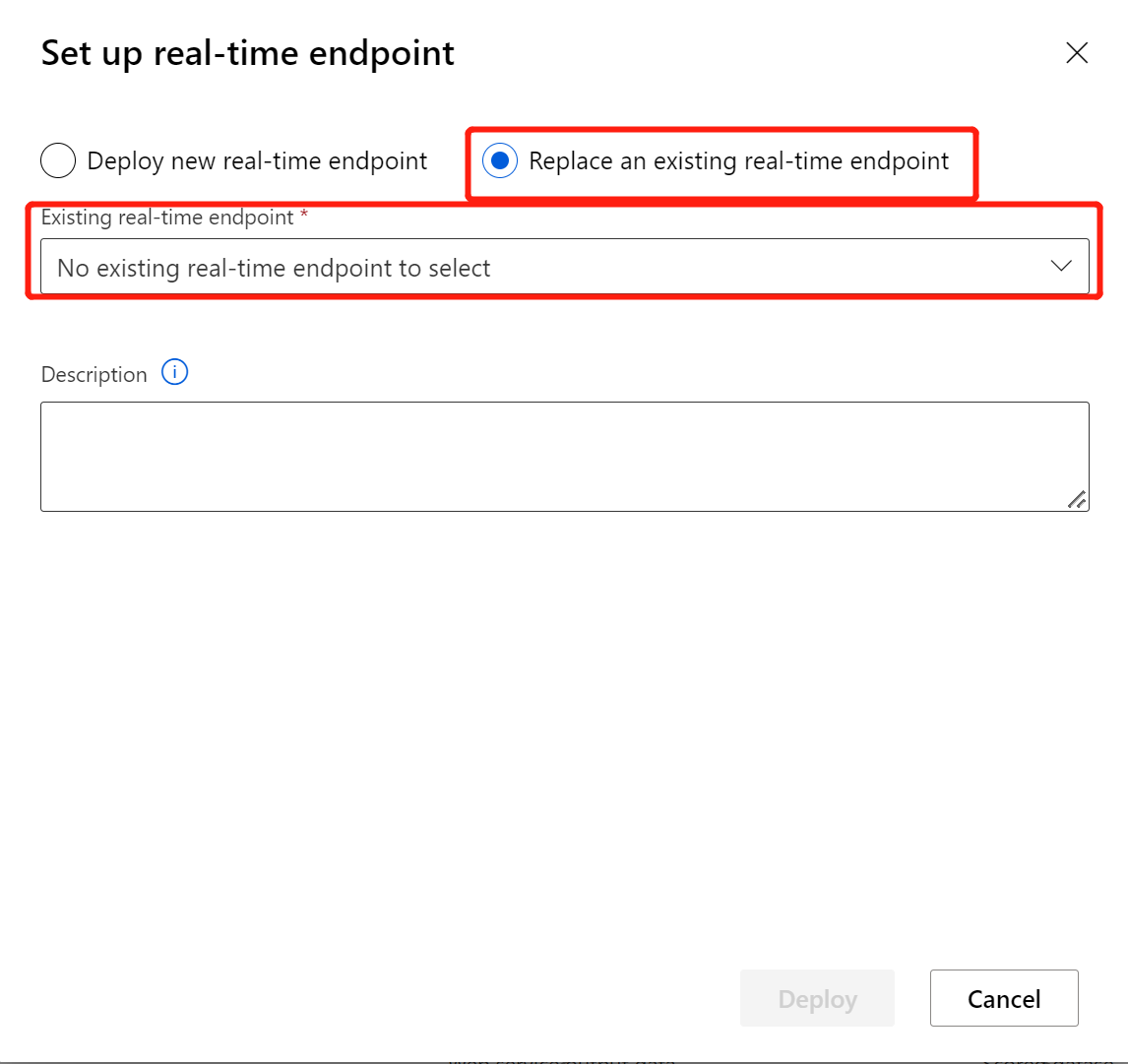
Selecione Implantar novo ponto de extremidade em tempo real.
Selecione o cluster do AKS que você criou.
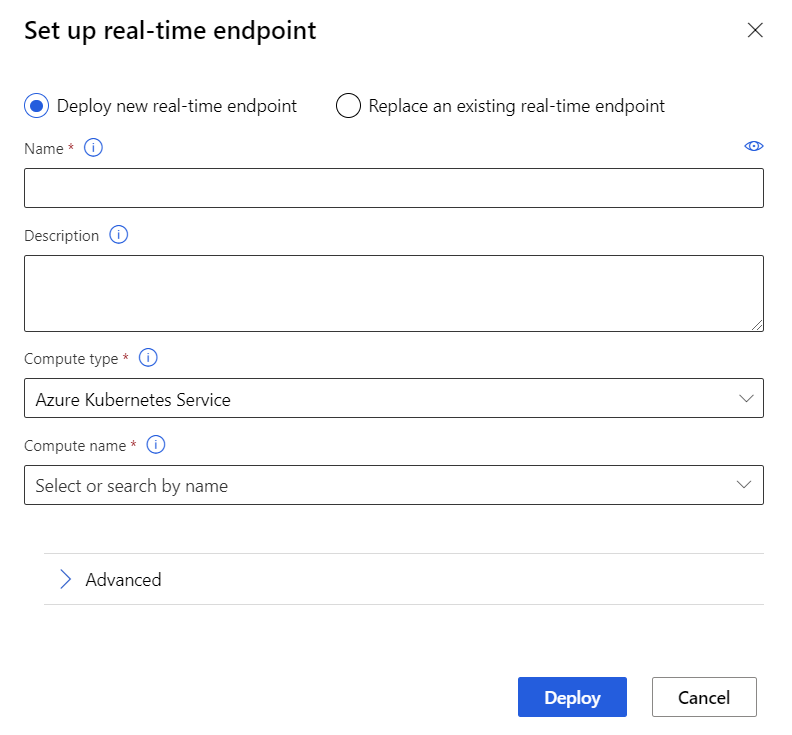
Você também pode alterar a configuração Avançado para seu ponto de extremidade em tempo real.
Configuração avançada Descrição Habilitar o diagnóstico e a coleta de dados do Application Insights Permite que o Azure Application Insights colete dados dos pontos de extremidade implantados.
Por padrão: falso.Tempo limite de pontuação Um tempo limite em milissegundos para impor as chamadas de pontuação ao serviço Web.
Por padrão: 60000.Dimensionamento automático habilitado Permite dimensionamento automático para o serviço Web.
Por padrão: verdadeiro.Número mínimo de réplicas O número mínimo de contêineres a serem usados no dimensionamento automático desse serviço Web.
Por padrão: 1.Número máximo de réplicas O número máximo de contêineres a serem usados no dimensionamento automático desse serviço Web.
Por padrão: 10.Utilização de destino A utilização de alvo (em percentual) que o dimensionador automático deve tentar manter para este serviço Web.
Por padrão: 70.Período de atualização A frequência (em segundos) com que o dimensionamento automático tenta escalar esse serviço Web.
Por padrão: 1.Capacidade reserva de CPU O número de núcleos de CPU a serem alocados para esse serviço Web.
Por padrão: 0,1.Capacidade reserva de memória A quantidade de memória (em GB) a ser alocada para esse serviço Web.
Por padrão: 0,5.Selecione Implantar.
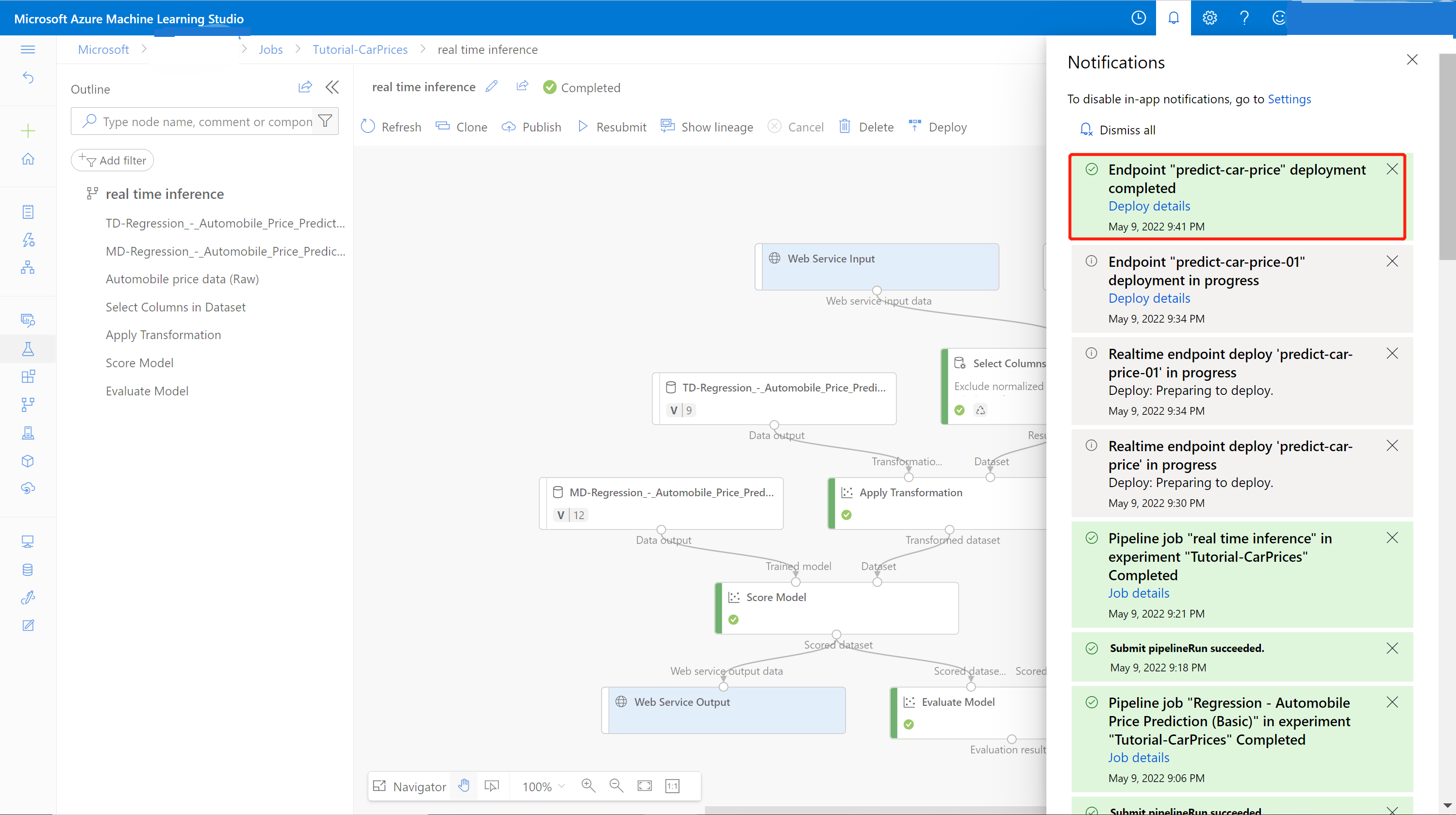
Uma notificação de êxito da centro de notificações é exibida após a conclusão da implantação. Isso pode levar alguns minutos.

Dica
Você também pode implantar no Azure Container Instance se selecionar Azure Container Instance para Tipo de Computação na caixa de configurações do ponto de extremidade em tempo real. A Instância de Contêiner do Azure é usada para teste ou desenvolvimento. Use o Azure Container Instance para cargas de trabalho baseadas em CPU de baixa escala que exigem menos de 48 GB de RAM.
Testar o ponto de extremidade em tempo real
Após a conclusão da implantação, veja o ponto de extremidade em tempo real acessando a página Pontos de extremidade.
Na página Pontos de extremidade, selecione o ponto de extremidade implantado.
Na guia Detalhes, você pode ver mais informações, como o URI REST, a definição do Swagger, o status e as marcas.
Na guia Consumir, você pode encontrar um código de consumo de exemplos, chaves de segurança e definir métodos de autenticação.
Na guia Logs de implantação, encontre os logs de implantação detalhados do ponto de extremidade em tempo real.
Para testar o seu ponto de extremidade, acesse a guia Testar. Nela, você pode inserir os dados de teste e selecionar Testar para verificar a saída do seu ponto de extremidade.
Atualizar o ponto de extremidade em tempo real
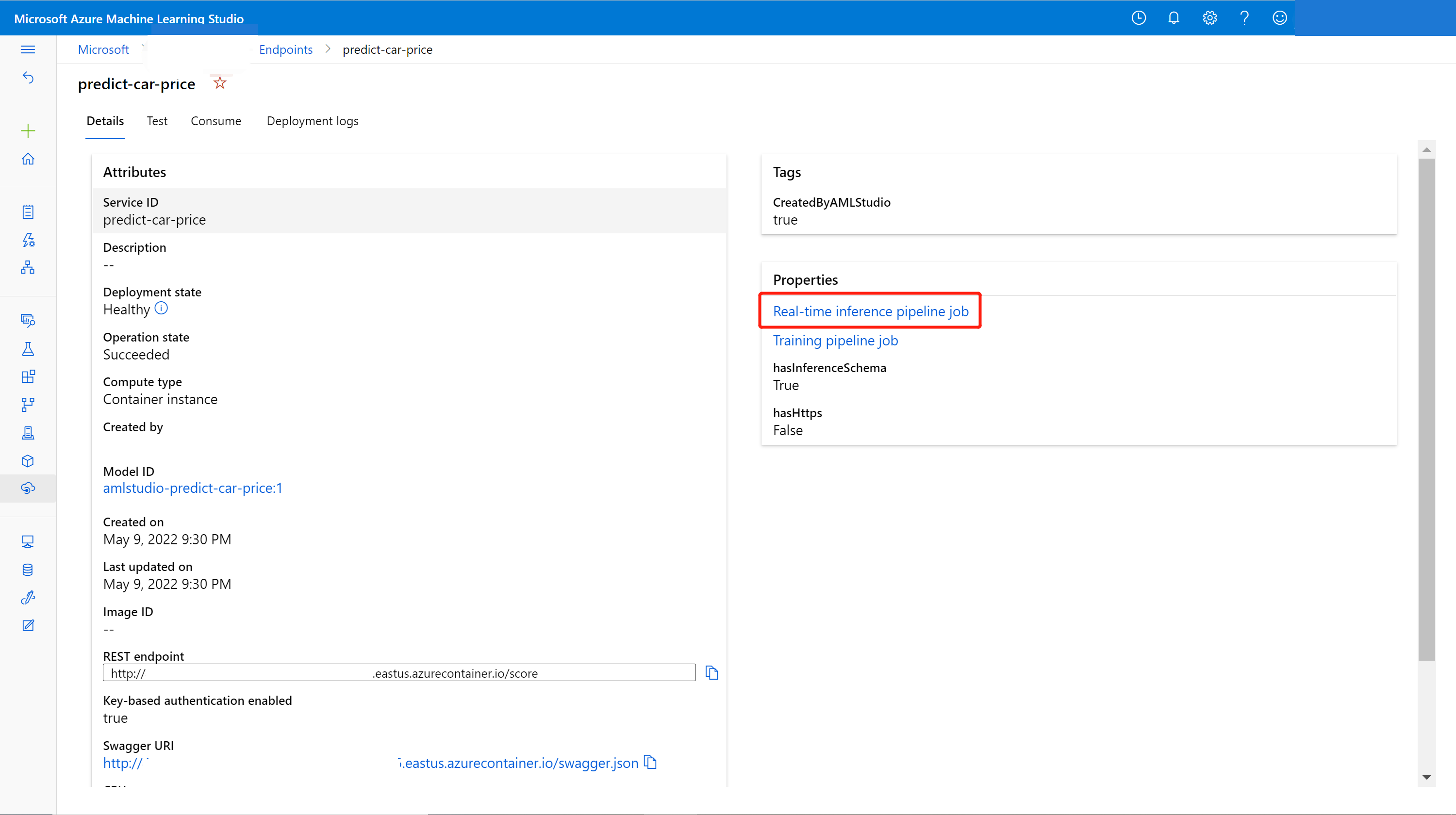
Você pode atualizar o ponto de extremidade online com o novo modelo treinado no designer. Na página de detalhes do ponto de extremidade online, localize o trabalho anterior do pipeline de treinamento e o trabalho de pipeline de inferência.
Você pode encontrar e modificar seu rascunho de pipeline de treinamento na página inicial do designer.
Outra alternativa é abrir o link de trabalho do pipeline de treinamento e cloná-lo para um novo rascunho de pipeline para continuar a edição.
Depois de enviar o pipeline de treinamento modificado, vá para a página de detalhes do trabalho.
Quando o trabalho for concluído, clique com o botão direito do mouse em Treinar Modelo e selecione Registrar dados.
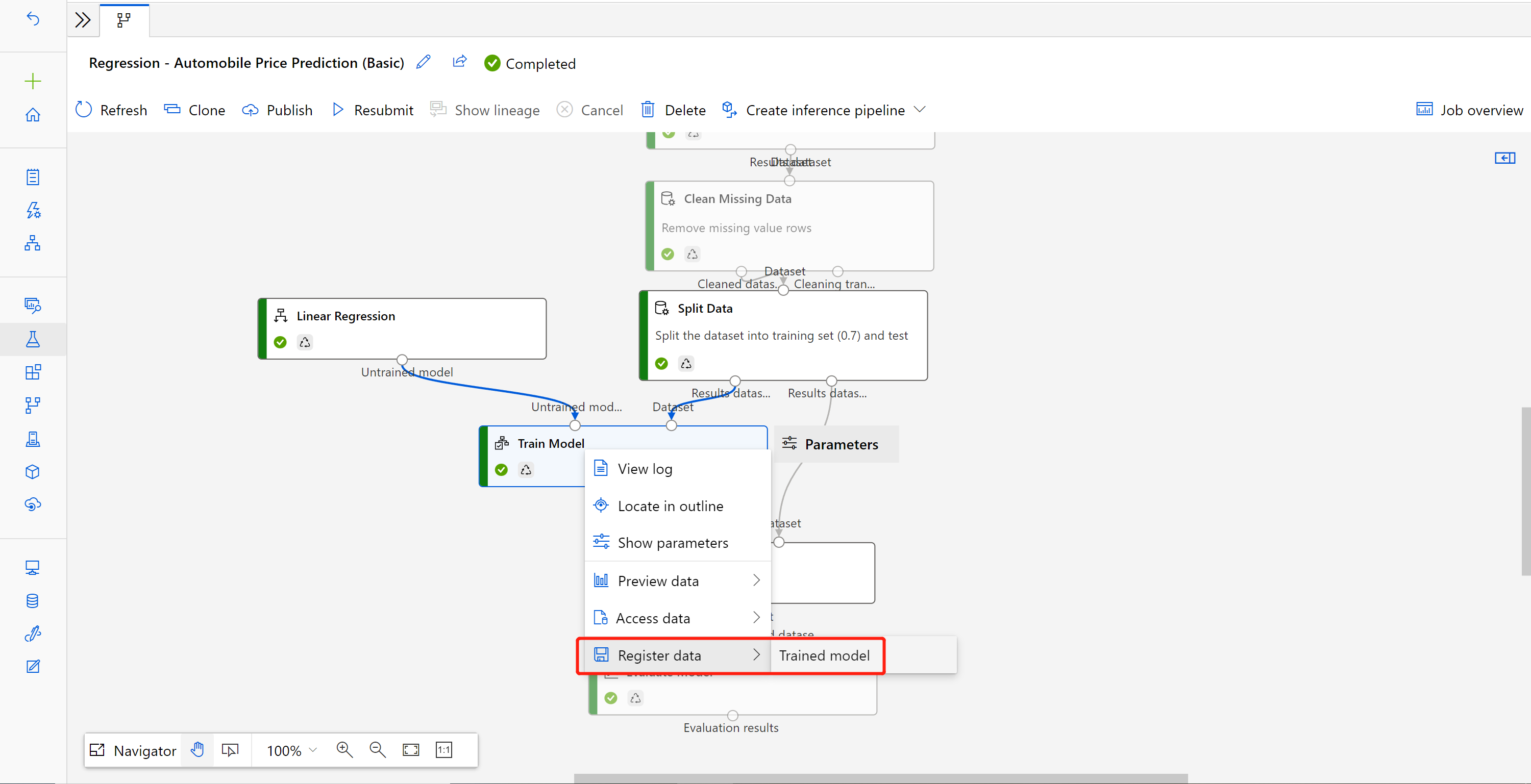
Insira o nome e selecione o tipo de Arquivo.
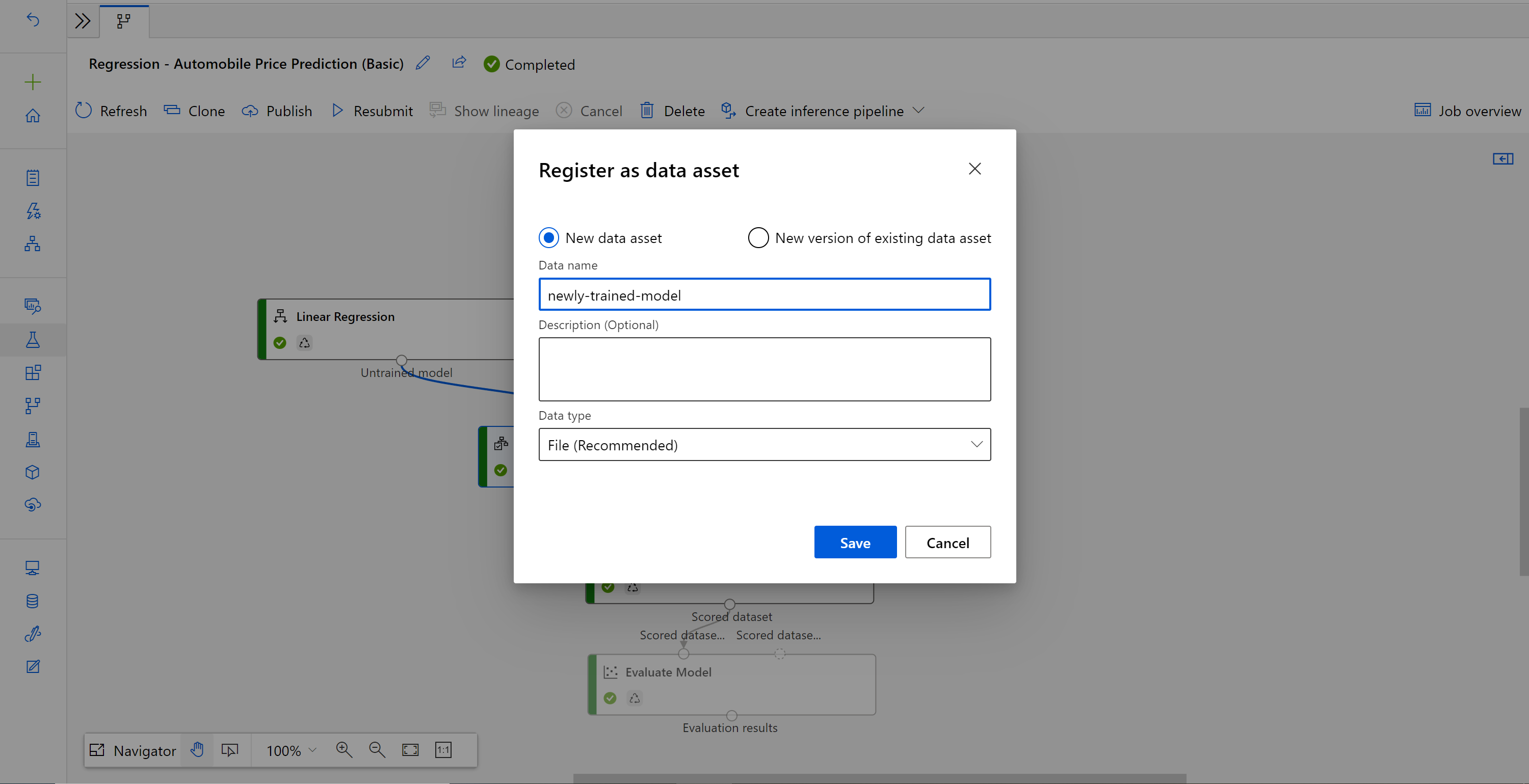
Depois que o conjunto de dados for registrado com êxito, abra o rascunho do pipeline de inferência ou clone o trabalho de pipeline de inferência anterior para um novo rascunho. No rascunho do pipeline de inferência, substitua o modelo treinado anterior mostrado como nó MD-XXXX conectado ao componente Modelo de Pontuação com o conjunto de dados que acaba de ser registrado.
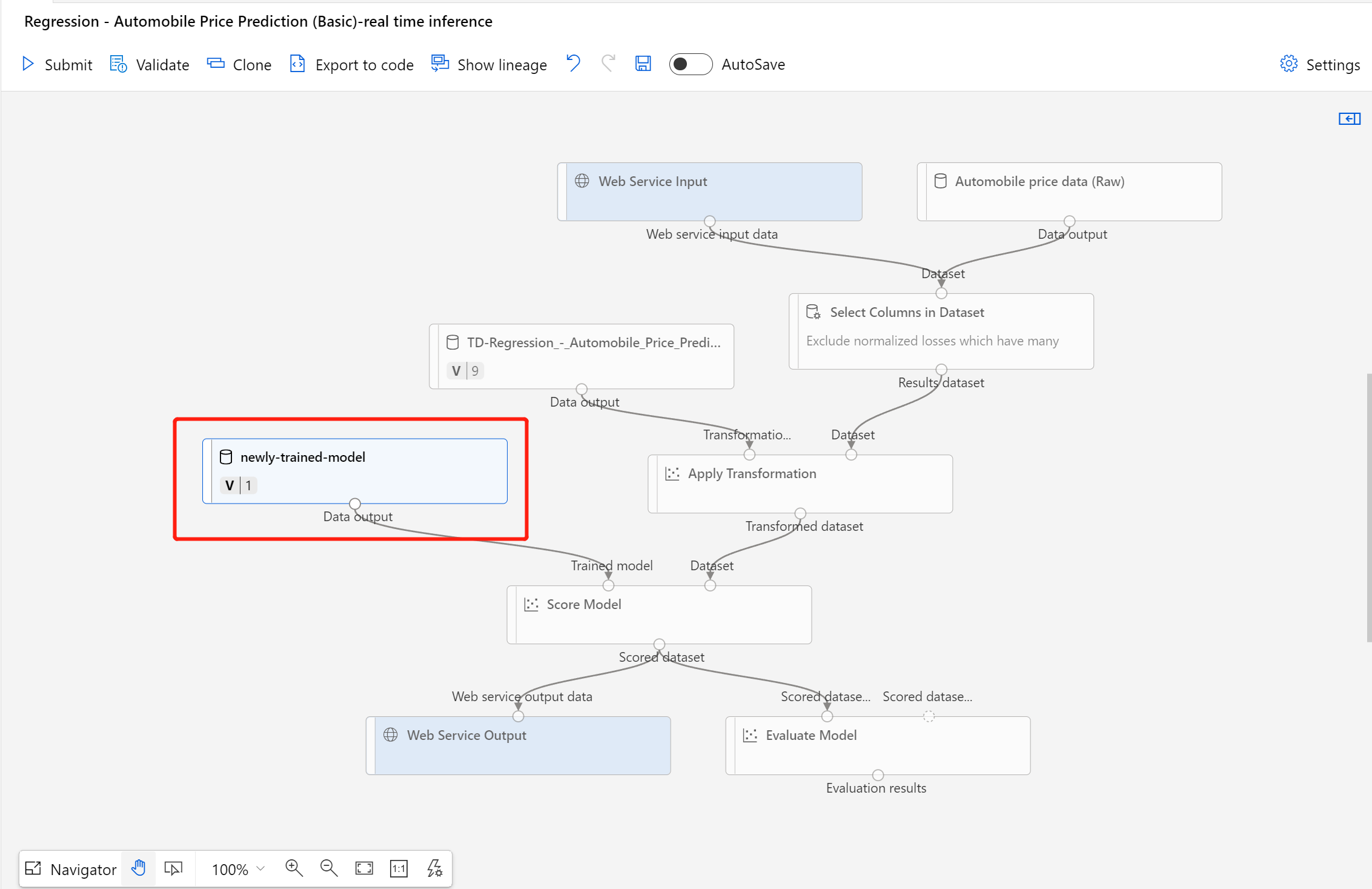
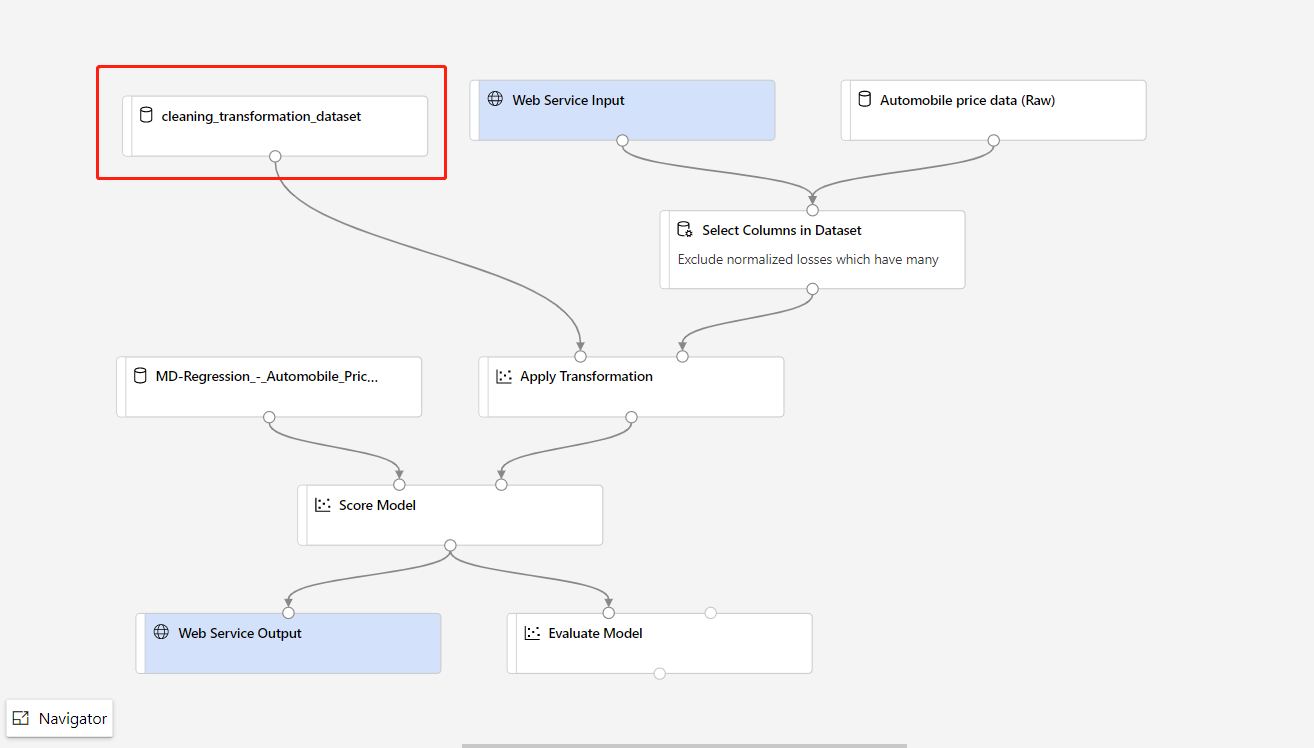
Se for preciso atualizar a parte de pré-processamento de dados do pipeline de treinamento e você quiser atualizá-la no pipeline de inferência, o processamento será semelhante às etapas acima.
Você precisa apenas registrar a saída de transformação do componente de transformação como um conjunto de dados.
Em seguida, substitua manualmente o componente TD- no pipeline de inferência pelo conjunto de dados registrado.
Depois de modificar o pipeline de inferência com o modelo ou transformação que acaba de ser treinado, envie-o. Quando o trabalho for concluído, implante-o no ponto de extremidade online implantado antes.




Limitações
Devido à limitação de acesso ao armazenamento de dados, se o seu pipeline de inferência contiver componentes Importar Dados ou Exportar Dados, eles serão removidos automaticamente quando implantados no ponto de extremidade em tempo real.
Se você tiver conjuntos de dados no pipeline de inferência em tempo real e quiser implantá-lo no ponto de extremidade em tempo real, atualmente, esse fluxo dá suporte apenas a conjuntos de dados registrados no armazenamento de dados de Blob. Se você quiser usar conjuntos de dados de outros tipos de armazenamento de dados, pode usar Selecionar Coluna para conectar-se ao seu conjunto de dados inicial com as configurações de seleção de todas as colunas, registrar as saídas de Selecionar Coluna como um conjunto de dados de Arquivo e, em seguida, substituir o conjunto de dados inicial no pipeline de inferência em tempo real por este novo conjunto de dados registrado.
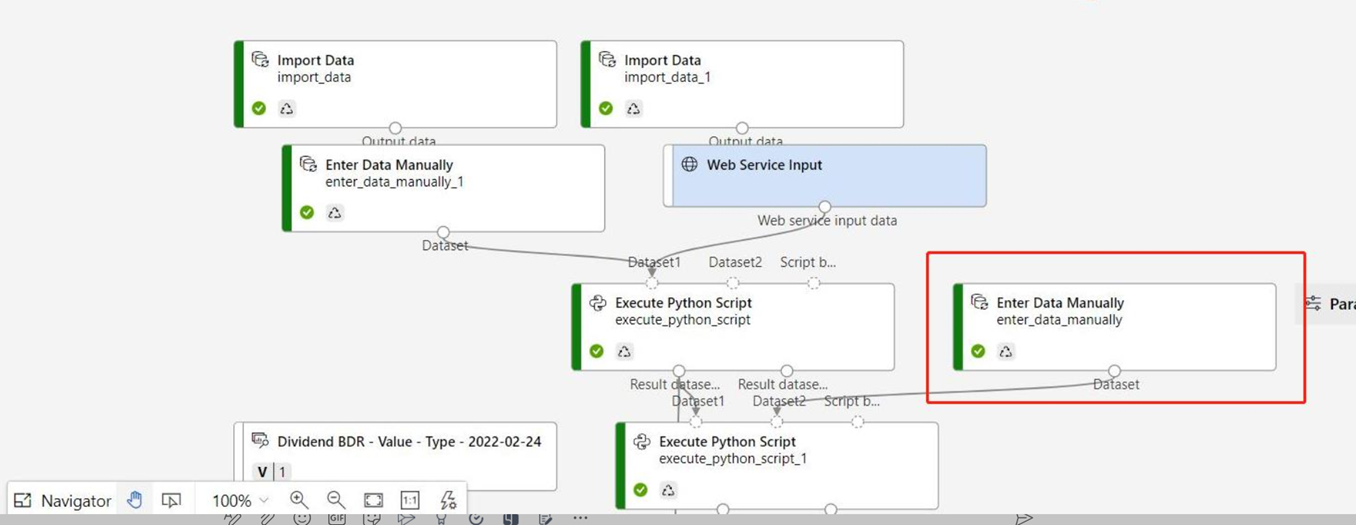
Se seu gráfico de inferência contiver o componente Inserir Dados Manualmente que não esteja conectado à mesma porta que o componente Entrada do Serviço Web, o componente Inserir Dados Manualmente não será executado durante o processamento da chamada HTTP. Uma solução alternativa é registrar as saídas desse componente Inserir Dados Manualmente como um conjunto de dados e, em seguida, no rascunho do pipeline de inferência, substituir o componente Inserir Dados Manualmente pelo conjunto de dados registrado.

Limpar os recursos
Importante
Você pode usar os recursos que criou como pré-requisitos em outros tutoriais e artigos de instruções do Serviço do Azure Machine Learning.
Excluir tudo
Se você não pretende usar os recursos criados, exclua todo o grupo de recursos para não gerar encargos.
No portal do Azure, selecione Grupos de recursos no lado esquerdo da janela.
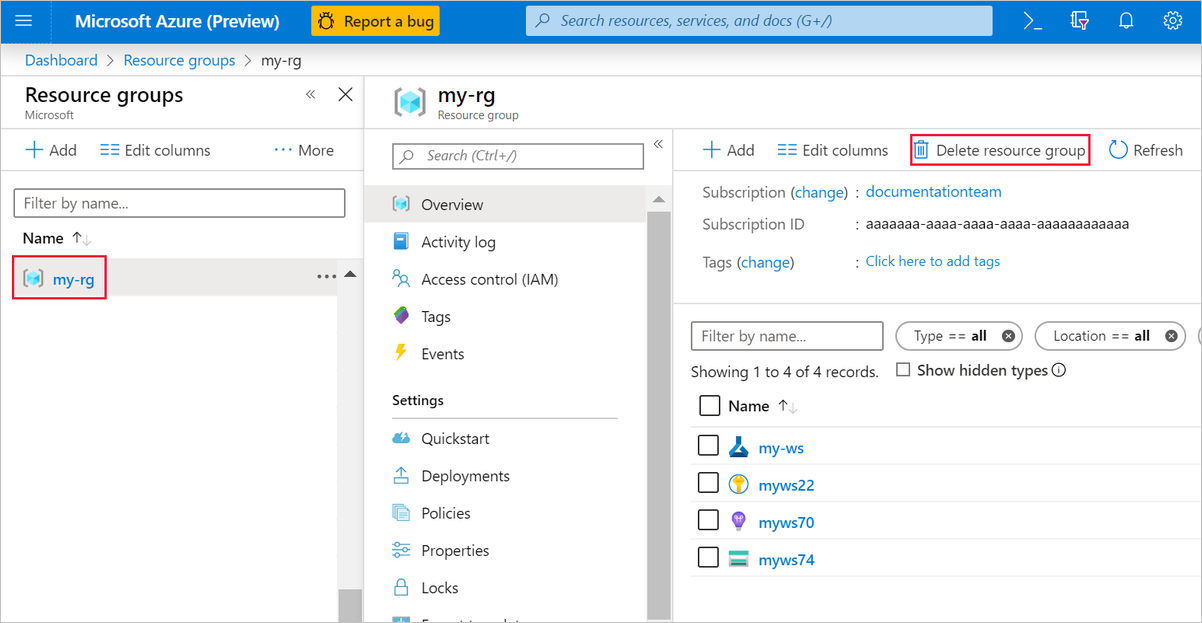
Na lista, selecione o grupo de recursos que você criou.
Selecione Excluir grupo de recursos.
A exclusão de um grupo de recursos também exclui todos os recursos criados no designer.
Excluir recursos individuais
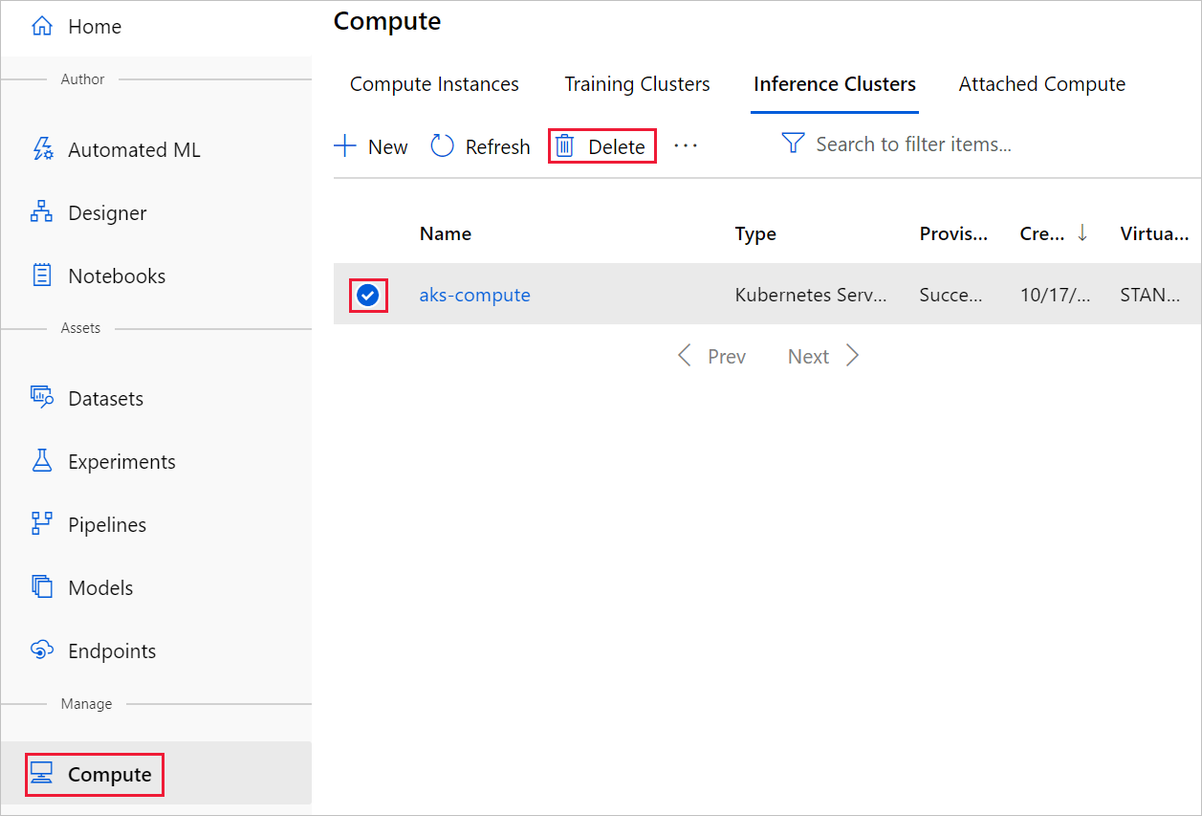
No designer em que você criou seu experimento, exclua ativos individuais selecionando-os e, em seguida, selecionando o botão Excluir.
O destino de computação que você criou aqui é dimensionado automaticamente para zero nós quando não estiver sendo usado. Essa ação é executada para minimizar encargos. Se você quiser excluir o destino de computação, siga estas etapas:
É possível cancelar o registro de conjuntos de dados do seu workspace selecionando cada conjunto de dados e, Cancelar registro.
Para excluir um conjunto de dados, acesse a conta de armazenamento usando o portal do Azure ou o Gerenciador de Armazenamento do Azure e exclua manualmente esses ativos.
Conteúdo relacionado
Neste tutorial, você aprendeu como criar, implantar e consumir um modelo de machine learning no designer. Para saber mais sobre como usar o designer, confira os seguintes artigos: