Como usar foundation models de código aberto coletados pelo Azure Machine Learning
Neste artigo, você aprenderá a ajustar, avaliar e implantar modelos de base no catálogo de modelos.
Você pode testar rapidamente qualquer modelo pré-treinado usando o formulário de Inferência de Amostra no cartão do modelo, fornecendo sua própria entrada de amostra para testar o resultado. Além disso, o cartão de modelo de cada modelo inclui uma breve descrição do modelo e links para códigos de exemplo de inferência baseada em código, ajuste fino e avaliação do modelo.
Como avaliar foundation models usando seus próprios dados de teste
Você pode avaliar um foundation model em relação ao conjunto de dados de teste, usando o formulário Avaliar interface do usuário ou usando os exemplos baseados em código, vinculados do cartão de modelo.
Avaliando o uso do estúdio
Você pode invocar o formulário Avaliar modelo selecionando o botão Avaliar no cartão de modelo para qualquer modelo de base.
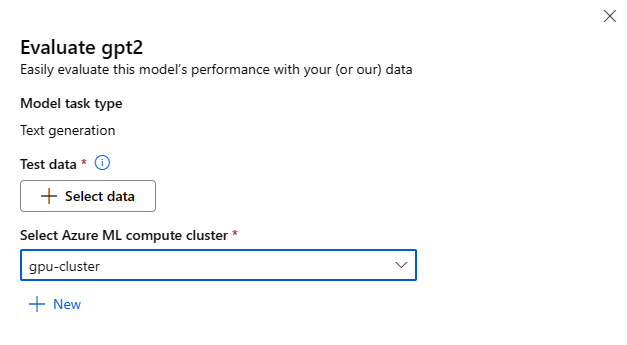
Cada modelo pode ser avaliado para a tarefa de inferência específica para a qual o modelo será usado.
Dados de teste:
- Passe os dados de teste que você gostaria de usar para avaliar seu modelo. Você pode optar por carregar um arquivo local (no formato JSONL) ou selecionar um conjunto de dados registrado existente no seu espaço de trabalho.
- Uma vez selecionado o conjunto de dados, é necessário mapear as colunas dos dados de entrada, com base no esquema necessário para a tarefa. Por exemplo, mapeie os nomes de coluna que correspondem às chaves 'sentence' e 'label' para a Classificação de Texto

Computação:
Forneça o cluster de Computação do Azure Machine Learning que você gostaria de usar para fazer o ajuste fino do modelo. A avaliação precisa ser executada na computação de GPU. Verifique se você tem cota de computação suficiente para os SKUs de computação que deseja usar.
Selecione Concluir no formulário Avaliar para enviar seu trabalho de avaliação. Depois que o trabalho for concluído, você poderá exibir as métricas de avaliação do modelo. Com base nas métricas de avaliação, você pode decidir se deseja ajustar o modelo usando seus próprios dados de treinamento. Além disso, você pode decidir se deseja registrar o modelo e implantá-lo em um ponto de extremidade.
Avaliação usando exemplos baseados em código
Para permitir que os usuários iniciem a avaliação do modelo, publicamos exemplos (notebooks Python e exemplos da CLI) em Exemplos de avaliação no repositório git azureml-examples. Cada cartão de modelo apresenta links para exemplos de avaliação para tarefas correspondentes
Como ajustar os modelos de base usando seus próprios dados de treinamento
Para melhorar o desempenho do modelo na sua carga de trabalho, convém refinar um foundation model usando seus próprios dados de treinamento. Você pode ajustar facilmente esses modelos de base usando as configurações de ajuste fino no estúdio ou usando os exemplos baseados em código vinculados ao cartão do modelo.
Ajuste fino usando o estúdio
Você pode invocar o formulário de ajustes finos selecionando o botão Ajustes fino no cartão do modelo para qualquer modelo de base.
Configurações de Ajuste fino:
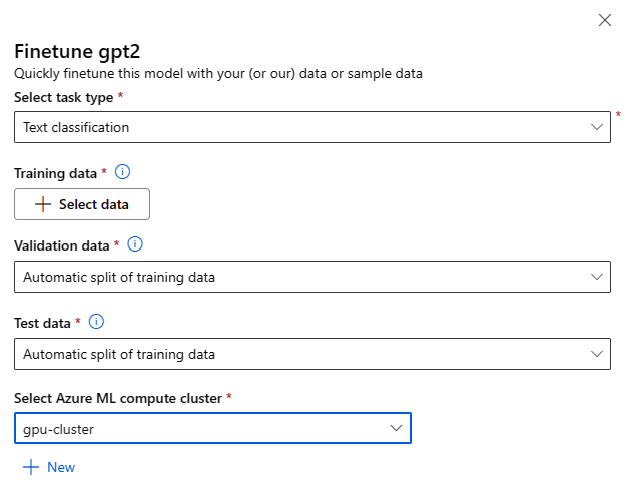
Tipo de tarefa de ajuste fino
- Cada modelo pré-treinado do catálogo de modelos pode ser ajustado para um conjunto específico de tarefas (por exemplo: Classificação de texto, Classificação de tokens, Resposta às perguntas). Selecione a tarefa que você deseja usar na lista suspensa.
Dados de treinamento
Passe os dados de treinamento que você gostaria de usar para ajustar seu modelo. Você pode optar por carregar um arquivo local (no formato JSONL, CSV ou TSV) ou selecionar um conjunto de dados registrado existente no seu espaço de trabalho.
Depois de selecionar o conjunto de dados, você precisará mapear as colunas dos dados de entrada, com base no esquema necessário para a tarefa. Por exemplo: mapear os nomes de coluna que correspondem às chaves 'sentence' e 'label' para a Classificação de Texto

- Dados de validação: passe os dados que você gostaria de usar para validar seu modelo. Selecionar Divisão automática reserva uma divisão automática dos dados de treinamento para validação. Como alternativa, você pode fornecer um conjunto de dados de validação diferente.
- Dados de teste: passe os dados de teste que você gostaria de usar para avaliar seu modelo ajustado. Selecionar Divisão automática reserva uma divisão automática dos dados de treinamento para teste.
- Computação: forneça o cluster de Computação do Azure Machine Learning que você gostaria de usar para fazer o ajuste fino do modelo. O ajuste fino precisa ser executado na computação da GPU. Recomendamos usar SKUs de computação com GPUs A100/V100 ao fazer o ajuste fino. Verifique se você tem cota de computação suficiente para os SKUs de computação que deseja usar.
- Selecione Concluir no formulário de ajuste fino para enviar seu trabalho de ajuste fino. Uma vez concluído o trabalho, você poderá exibir as métricas de avaliação do modelo ajustado. Em seguida, é possível registrar a saída do modelo ajustado pelo trabalho de ajuste fino e implantar esse modelo em um ponto de extremidade para inferência.
Ajuste fino utilizando exemplos baseados em código
Atualmente, o Azure Machine Learning dá suporte a modelos de ajuste fino para as seguintes tarefas de idioma:
- Classificação de texto
- Classificação de token
- Respostas às perguntas
- Resumo
- Tradução
Para permitir que os usuários iniciem rapidamente o ajuste fino, publicamos amostras (notebooks Python e exemplos de CLI) para cada tarefa no repositório Git de exemplos do Finetune azureml-examples. Cada cartão de modelo também é vinculado a amostras de ajuste fino para tarefas de ajuste fino com suporte.
Implantando foundation models em pontos de extremidade para inferência
É possível implantar modelos de base (modelos pré-treinados do catálogo de modelos e modelos ajustados, uma vez registrados no seu espaço de trabalho) em um ponto de extremidade que poderá ser usado para inferência. Há suporte para implantação em APIs sem servidor e computação gerenciada. Você pode implantar esses modelos usando o assistente de interface do usuário Implantar ou usando os exemplos baseados em código vinculados do cartão de modelo.
Implantar usando o estúdio
Invoque o formulário Implantar interface do usuário selecionando o botão Implantar no cartão de modelo para qualquer modelo de base e selecionando a API sem servidor com Segurança de Conteúdo de IA do Azure ou Computação Gerenciada sem Segurança de Conteúdo de IA do Azure

Configurações de implantação
Como o script de pontuação e o ambiente são incluídos automaticamente no modelo de base, você só precisa especificar a SKU da máquina virtual a ser usada, o número de instâncias e o nome do computador a ser usado na implantação do modelo.
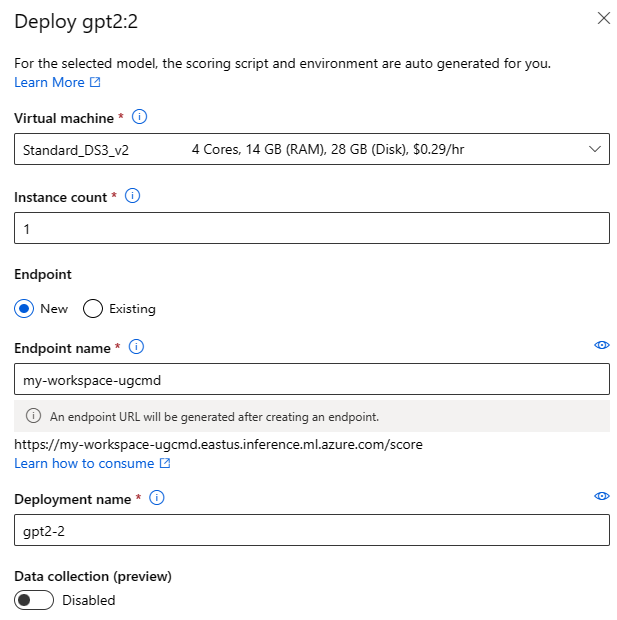
Cota compartilhada
Se você estiver implantando um modelo Llama-2, Phi, Nemotron, Mistral, Dolly ou Deci-DeciLM do catálogo de modelos, mas não tiver cota suficiente disponível para a implantação, o Azure Machine Learning permitirá que você use a cota de um pool de cotas compartilhado por um tempo limitado. Para obter mais informações sobre a cota compartilhada, consulte Cota compartilhada do Azure Machine Learning.

Implantação usando exemplos baseados em código
Para permitir que os usuários iniciem rapidamente a implantação e a inferência, publicamos exemplos em Exemplos de inferência no repositório git azureml-examples. Os exemplos publicados incluem notebooks Python e exemplos da CLI. Cada cartão de modelo também apresenta links para exemplos de inferência para Inferência em tempo real e inferência do Lote.
Importar modelos base
Se você quiser usar um modelo de código aberto que não está incluído no catálogo de modelos, poderá importar o modelo da Hugging Face para o workspace do Azure Machine Learning. A Hugging Face é uma biblioteca de software livre para NLP (processamento de linguagem natural) que fornece modelos pré-treinados para tarefas populares de NLP. Atualmente, a importação de modelo dá suporte à importação de modelos para as seguintes tarefas, desde que o modelo atenda aos requisitos listados no Notebook de Importação de Modelo:
- máscara de preenchimento
- classificação de token
- resposta a perguntas
- resumo
- geração de texto
- classificação de texto
- tradução
- classificação de imagem
- texto para imagem
Observação
Os modelos da Hugging Face estão sujeitos aos termos de licença de terceiros disponíveis na página de detalhes do modelo dessa empresa. É sua responsabilidade cumprir os termos de licença do modelo.
Você pode selecionar o botão Importar no canto superior direito do catálogo de modelos para usar o notebook de importação de modelo.
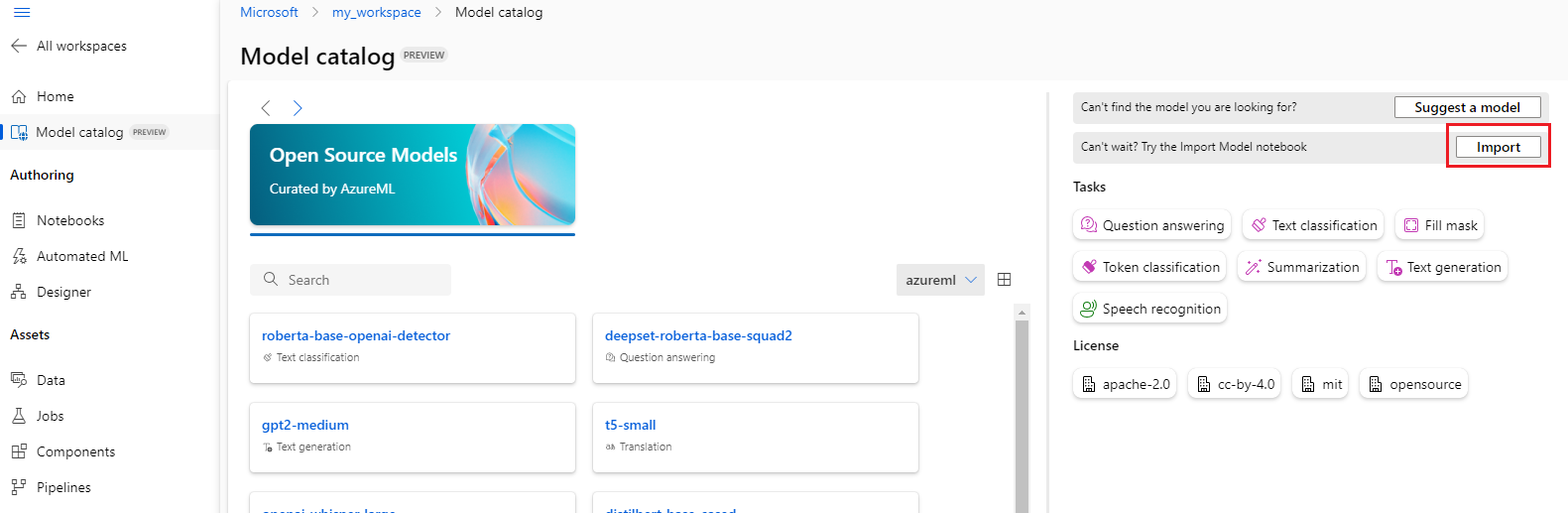
O notebook de importação de modelo também está incluído no repositório git azureml-examples aqui.
Para importar o modelo, você precisa passar o MODEL_ID do modelo que deseja importar da Hugging Face. Procure modelos no Hub da Hugging Face e identifique o modelo a ser importado. Verifique se o tipo de tarefa do modelo está entre os tipos de tarefa com suporte. Copie a ID do modelo, que está disponível no URI da página ou pode ser copiada usando o ícone de cópia ao lado do nome do modelo. Atribua-o à variável 'MODEL_ID' no notebook de importação de modelo. Por exemplo:
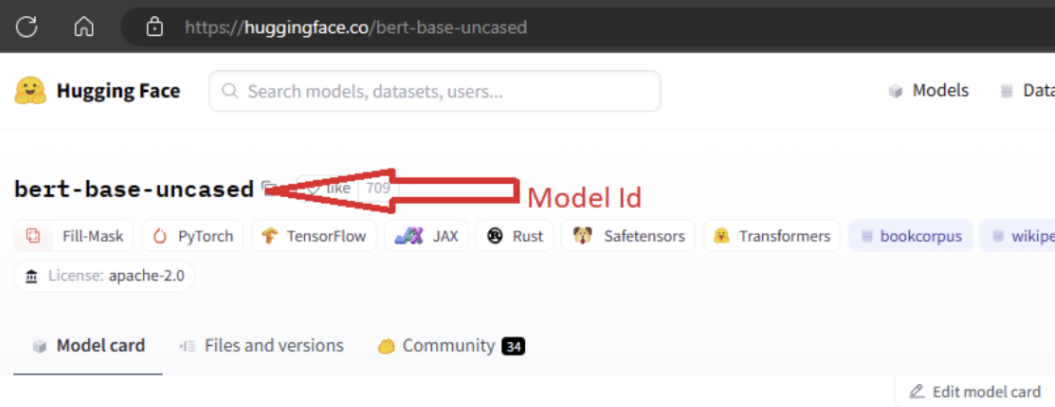
Você precisa fornecer computação para que a importação de modelo seja executada. A execução da Importação de Modelo resulta na importação do modelo especificado da Hugging Face e registrado no workspace do Azure Machine Learning. Em seguida, é possível fazer o ajuste fino desse modelo ou implantá-lo em um ponto de extremidade para inferência.
Saiba mais
- Explore o Catálogo de Modelos no Estúdio do Azure Machine Learning. Você precisa de um workspace do Azure Machine Learning para explorar o catálogo.
- Explorar o catálogo e as coleções de modelos