Avaliar os resultados do experimento de machine learning automatizado
Neste artigo, saiba como avaliar e comparar modelos treinados por seu experimento de machine learning automatizado (ML automatizado). Ao longo de um experimento de ML automatizado, muitos trabalhos são criados e cada trabalho cria um modelo. Para cada modelo, o ML automatizado gera métricas de avaliação e gráficos que ajudam a medir o desempenho do modelo. Além disso, você pode gerar um painel de IA responsável para fazer uma avaliação holística e depuração do melhor modelo recomendado por padrão. Isso inclui insights como explicações do modelo, explorador de imparcialidade e desempenho, data explorer e análise de erros do modelo. Saiba mais sobre como você pode gerar um painel de AI Responsável.
Por exemplo, o ML automatizado gera os gráficos a seguir com base no tipo de experimento.
Importante
Os itens marcados (versão prévia) neste artigo estão atualmente em versão prévia pública. A versão prévia é fornecida sem um contrato de nível de serviço e não é recomendada para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
Pré-requisitos
- Uma assinatura do Azure. (Caso você não tenha uma assinatura do Azure, crie uma conta gratuita antes de começar)
- Um experimento do Azure Machine Learning criado com:
- O Estúdio do Azure Machine Learning (nenhum código necessário)
- O SDK do Python do Azure Machine Learning
Ver resultados do trabalho
Após a conclusão do experimento de ML automatizado, um histórico dos trabalhos pode ser encontrado por meio de:
- Um navegador com o Estúdio do Azure Machine Learning
- Um notebook Jupyter usando o widget Jupyter JobDetails
As etapas e o vídeo a seguir mostram como exibir o histórico de execuções e os gráficos e as métricas de avaliação do modelo no estúdio:
- Entre no estúdio e navegue até seu espaço de trabalho.
- No menu à esquerda, selecione Trabalhos.
- Selecione seu experimento na lista de experimentos.
- Na tabela na parte inferior da página, selecione um trabalho de ML automatizado.
- Na guia Modelos, selecione o Nome do algoritmo para o modelo que você deseja avaliar.
- Na guia Métricas, use as caixas de seleção à esquerda para exibir métricas e gráficos.
Métricas de classificação
O ML automatizado calcula as métricas de desempenho para cada modelo de classificação gerado para o experimento. Essas métricas se baseiam na implementação da Scikit-learn.
Muitas métricas de classificação são definidas para classificação binária em duas classes, e exigem a média de classes para produzir uma pontuação para classificação multiclasse. Scikit-learn fornece vários métodos de média, três dos quais o ML automatizado expõe: macro, micro e ponderada.
- Macro - Calcula a métrica para cada classe e calcula a média não ponderada
- Micro - Calcula a métrica globalmente contando o total de verdadeiros positivos, falsos negativos e falsos positivos (independentes das classes).
- Ponderada - Calcula a métrica para cada classe e usa a média ponderada com base no número de amostras por classe.
Embora cada método de média tenha seus benefícios, uma consideração comum ao selecionar o método apropriado é o desequilíbrio de classe. Se as classes tiverem diferentes números de amostras, talvez seja mais informativo usar uma média de macro em que as classes minoritárias recebem peso igual ao das classes majoritárias. Saiba mais sobre as métricas binária vs multiclasse no ML automatizado.
A tabela a seguir resume as métricas de desempenho do modelo que o ML automatizado calcula para cada modelo de classificação gerado para o experimento. Para obter mais detalhes, consulte a documentação da scikit-Learn vinculada no campo de cálculo de cada métrica.
Observação
Confira a seção de métricas de imagem para ver mais detalhes sobre métricas de modelos de classificação de imagem.
| Métrica | Descrição | Cálculo |
|---|---|---|
| AUC | AUC é a área embaixo da Curva de Característica Operacional do Receptor. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] Os nomes de métrica com suporte incluem, AUC_macro, a média aritmética da AUC para cada classe.AUC_micro, computada globalmente contando o total de verdadeiros positivos, falsos negativos e falsos positivos. AUC_weighted, média aritmética da pontuação para cada classe, ponderada pelo número de instâncias verdadeiras em cada classe. AUC_binary, o valor de AUC ao tratar uma classe específica como classe true e combinar todas as outras classes como classe false. |
Cálculo |
| accuracy | Precisão é o percentual de previsões que coincidem exatamente com os rótulos de classe verdadeiros. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] |
Cálculo |
| average_precision | A precisão média resume uma curva de recolhimento de precisão como a média ponderada de precisões atingidas em cada limite, com o aumento no recolhimento do limite anterior usado como o peso. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] Os nomes de métrica com suporte incluem, average_precision_score_macro, a média aritmética da pontuação de precisão média de cada classe.average_precision_score_micro, computada globalmente contando o total de verdadeiros positivos, falsos negativos e falsos positivos.average_precision_score_weighted, a média aritmética da pontuação de precisão média para cada classe, ponderada pelo número de instâncias verdadeiras em cada classe. average_precision_score_binary, o valor de precisão média ao tratar uma classe específica como classe true e combinar todas as outras classes como classe false. |
Cálculo |
| balanced_accuracy | Precisão equilibrada é a média aritmética do recolhimento de cada classe. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] |
Cálculo |
| f1_score | Pontuação F1 é a média harmônica de precisão e recuperação. É uma medida equilibrada de falsos positivos e falsos negativos. Entretanto, não leva em conta os verdadeiros negativos. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] Os nomes de métrica com suporte incluem, f1_score_macro: a média aritmética da pontuação F1 para cada classe. f1_score_micro: computada globalmente contando o total de verdadeiros positivos, falsos negativos e falsos positivos. f1_score_weighted: média ponderada por frequência de classe ou pontuação F1 para cada classe. f1_score_binary, o valor de f1 ao tratar uma classe específica como classe true e combinar todas as outras classes como classe false. |
Cálculo |
| log_loss | Essa é a função de perda usada na regressão logística (multinomial) e nas extensões dela, como redes neurais, definidas como a probabilidade logarítmica negativa dos rótulos verdadeiros dadas as previsões de um classificador probabilístico. Objetivo: quanto mais próximo de 0 melhor Intervalo: [0, inf) |
Cálculo |
| norm_macro_recall | Recall de macro normalizado é o recall de macro médio e normalizado, para que o desempenho aleatório tenha uma pontuação de 0 e o desempenho perfeito tenha uma pontuação de 1. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] |
(recall_score_macro - R) / (1 - R) onde, R é o valor esperado de recall_score_macro para previsões aleatórias.R = 0.5 para classificação binária. R = (1 / C) para problemas de classificação de classe C. |
| matthews_correlation | Coeficiente de correlação de Matthews é uma medida equilibrada de precisão, que pode ser usada mesmo que uma classe tenha muito mais amostras do que outra. Um coeficiente de 1 indica previsão perfeita, 0 previsão aleatória e -1 previsão inversa. Objetivo: quanto mais próximo de 1 melhor Intervalo: [-1, 1] |
Cálculo |
| precisão | Precisão é a capacidade de um modelo para evitar rotular amostras negativas como positivas. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] Os nomes de métrica com suporte incluem, precision_score_macro, a média aritmética da precisão para cada classe. precision_score_micro, computada globalmente contando o total de verdadeiros positivos e falsos positivos. precision_score_weighted, a média aritmética da precisão para cada classe, ponderada pelo número de instâncias verdadeiras em cada classe. precision_score_binary, o valor de precisão ao tratar uma classe específica como classe true e combinar todas as outras classes como classe false. |
Cálculo |
| recall | Recall é a capacidade de um modelo para detectar todas as amostras positivas. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] Os nomes de métrica com suporte incluem, recall_score_macro: a média aritmética do recall para cada classe. recall_score_micro: computado globalmente pela contagem do total de verdadeiros positivos, falsos negativos e falsos positivos.recall_score_weighted: a média aritmética do recall para cada classe, ponderada pelo número de instâncias verdadeiras em cada classe. recall_score_binary, o valor de recall ao tratar uma classe específica como classe true e combinar todas as outras classes como classe false. |
Cálculo |
| weighted_accuracy | Precisão ponderada é a precisão em que cada amostra é ponderada pelo número total de amostras que pertencem à mesma classe. Objetivo: quanto mais próximo de 1 melhor Intervalo: [0, 1] |
Cálculo |
Métricas de classificação binárias versus multiclasse
O ML automaticamente detecta se os dados são binários e também permite que os usuários ativem métricas de classificação binária, mesmo se os dados são multiclasse especificando uma classe true. As métricas de classificação multiclasse são relatadas se um conjunto de dados tem duas ou mais classes. As métricas de classificação binária são relatadas somente quando os dados são binários.
Observe que as métricas de classificação multiclasse destinam-se à classificação multiclasse. Quando aplicadas a um conjunto de dados binário, essas métricas não tratam nenhuma classe como a classe true, como seria de se esperar. As métricas que são claramente destinadas para multiclasse são sufixadas com micro, macro ou weighted. Exemplos incluem average_precision_score, f1_score, precision_score, recall_score e AUC. Por exemplo, em vez de calcular a recall como tp / (tp + fn), o recall médio de multiclasse (micro, macro ou weighted) é calculado em ambas as classes de um conjunto de dados de classificação binária. Isso é equivalente a calcular o recall para a classe true e a classe false separadamente e, em seguida, usar a média dos dois.
Além disso, embora haja suporte para a detecção automática de classificação binária, ainda é recomendável sempre especificar a classe true manualmente para garantir que as métricas de classificação binária sejam calculadas para a classe correta.
Para ativar métricas para conjuntos de dados de classificação binária quando o próprio conjunto de dados é multiclasse, os usuários só precisam especificar a classe a ser tratada como classe true e essas métricas são calculadas.
Matriz de confusão
As matrizes de confusão fornecem um objeto visual de como um modelo de machine learning está cometendo erros sistemáticos em suas previsões para modelos de classificação. A palavra "confusão" no nome vem de um modelo "confuso" ou de amostras de rotulagem incorreta. Uma célula na linha i e na coluna j em uma matriz de confusão contém o número de amostras no conjunto de dados de avaliação que pertencem à classe C_i e são classificadas pelo modelo como classe C_j.
No estúdio, uma célula mais escura indica um número maior de amostras. A seleção da exibição Normalizado na lista suspensa normaliza cada linha da matriz para mostrar a porcentagem da classe C_i prevista como classe C_j. O benefício da exibição Bruta padrão é que você pode ver se o desequilíbrio na distribuição das classes reais fez com que o modelo classificasse incorretamente amostras da classe minoritária, um problema comum em conjuntos de dados desequilibrados.
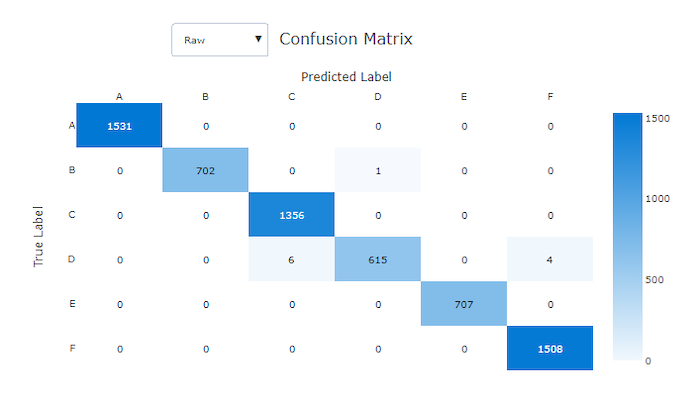
A matriz de confusão de um bom modelo tem a maioria das amostras ao longo da diagonal.
Matriz de confusão para um modelo bom
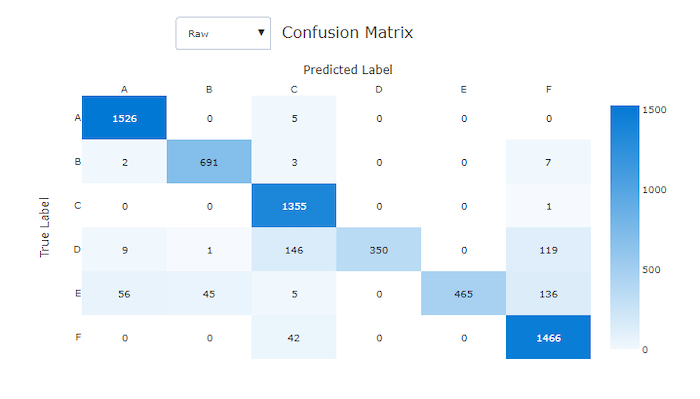
Matriz de confusão para um modelo ruim
Curva ROC
A curva de característica operacional do receptor (ROC) plota a relação entre taxa de verdadeiro positivo (TPR) e a taxa de falso positivo (FPR) à medida que o limite de decisão muda. A curva ROC pode ser menos informativa ao treinar modelos em conjuntos de dados com alto desequilíbrio de classe, já que a classe majoritária pode anular contribuições de classes minoritárias.
A área sob a curva (AUC) pode ser interpretada como a proporção de amostras classificadas corretamente. Mais precisamente, a AUC é a probabilidade de o classificador classificar uma amostra positiva escolhido aleatoriamente mais acima do que uma amostra negativa escolhido aleatoriamente. A forma da curva proporciona uma intuição para a relação entre TPR e FPR como uma função do limite de classificação ou do limite de decisão.
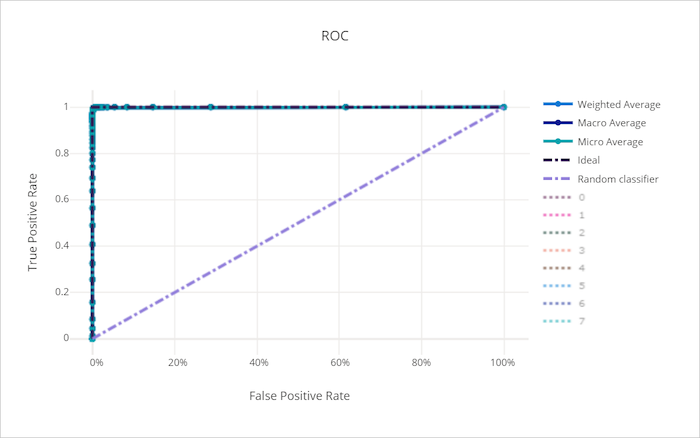
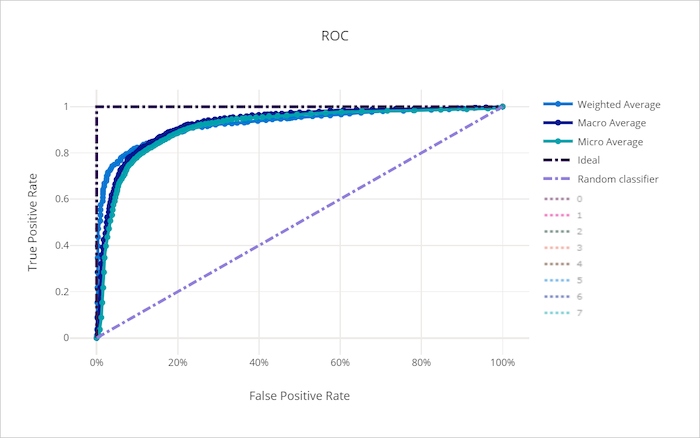
Uma curva que se aproxima do canto superior esquerdo do gráfico está se aproximando de um TPR 100% e FPR 0%, o melhor modelo possível. Um modelo aleatório produziria uma curva ROC ao longo da linha y = x do canto inferior esquerdo para a parte superior direita. Um modelo pior do que o aleatório teria uma curva ROC que fica abaixo da linha y = x.
Dica
Para experimentos de classificação, cada um dos gráficos de linhas produzidos para modelos de ML automatizado pode ser usado para avaliar o modelo por classe ou a média em todas as classes. Você pode alternar entre esses modos de exibição diferentes clicando nos rótulos de classe na legenda à direita do gráfico.
Curva ROC para um modelo bom
Curva ROC para um modelo ruim
Curva de precisão-recall
A curva de precisão-recall plota a relação entre precisão e recall à medida que o limite de decisão é alterado. Recall é a capacidade de um modelo para detectar todos os exemplos positivos e a precisão é a capacidade de um modelo evitar rotular amostras negativas como positivas. Alguns problemas empresariais podem exigir uma recall mais alta e uma precisão mais alta, dependendo da importância relativa de evitar falsos negativos versus falsos positivos.
Dica
Para experimentos de classificação, cada um dos gráficos de linhas produzidos para modelos de ML automatizado pode ser usado para avaliar o modelo por classe ou a média em todas as classes. Você pode alternar entre esses modos de exibição diferentes clicando nos rótulos de classe na legenda à direita do gráfico.
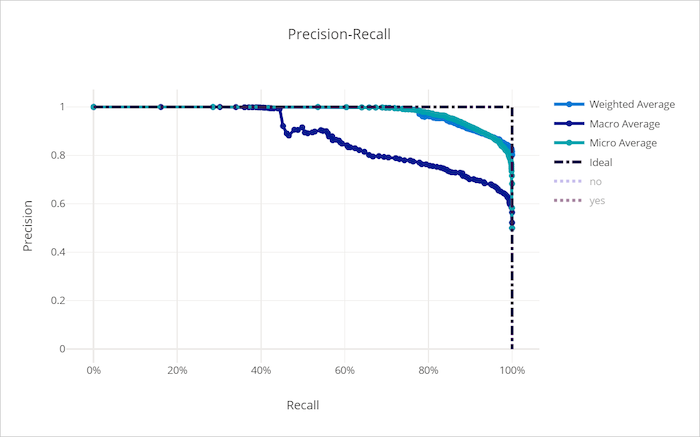
Curva de recall-precisão para um modelo bom
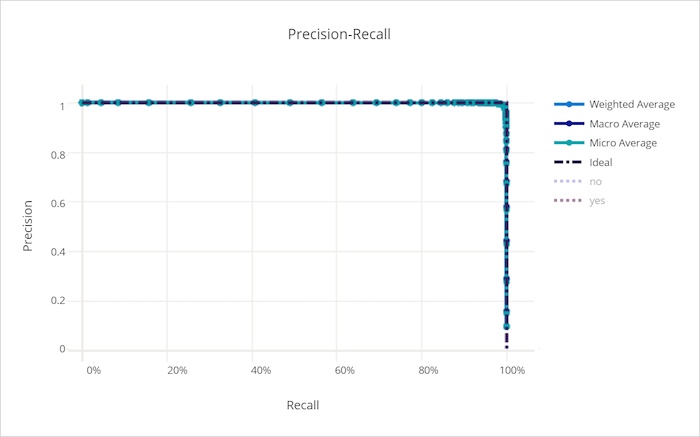
Curva de recall-precisão para um modelo ruim
Curva de ganhos cumulativos
A curva de ganhos cumulativos plota a porcentagem de amostras positivas classificadas corretamente como uma função da porcentagem de amostras consideradas onde consideramos as amostras na ordem de probabilidade prevista.
Para calcular o ganho, primeiro classifique todas as amostras da probabilidade mais alta para a mais baixa prevista pelo modelo. Em seguida, use x% das previsões de confiança mais altas. Divida o número de amostras positivas detectadas nesse x% pelo número total de amostras positivas para obter o ganho. O ganho cumulativo é o percentual de amostras positivas que detectamos ao considerar algum percentual dos dados que têm mais probabilidade de pertencer à classe positiva.
Um modelo perfeito classifica todas as amostras positivas acima de todas as amostras negativas, fornecendo uma curva de ganhos cumulativos composta de dois segmentos retos. O primeiro é uma linha com inclinação 1 / x de (0, 0) para (x, 1) onde x é a fração de exemplos que pertencem à classe positiva (1 / num_classes se as classes forem equilibradas). O segundo é uma linha horizontal de (x, 1) para (1, 1). No primeiro segmento, todas as amostras positivas são classificadas corretamente e o ganho cumulativo vai para 100% dentro do primeiro x% das amostras consideradas.
O modelo aleatório de linha de base tem uma curva de ganhos cumulativos seguindo y = x em que, para x% das amostras consideradas, apenas cerca de x% do total de amostras positivas foram detectadas. Um modelo perfeito para um conjunto de dados equilibrado tem uma curva de média micro e uma linha de média macro com inclinação num_classes até que o ganho cumulativo seja 100% e, em seguida, horizontal até que a porcentagem de dados seja 100.
Dica
Para experimentos de classificação, cada um dos gráficos de linhas produzidos para modelos de ML automatizado pode ser usado para avaliar o modelo por classe ou a média em todas as classes. Você pode alternar entre esses modos de exibição diferentes clicando nos rótulos de classe na legenda à direita do gráfico.
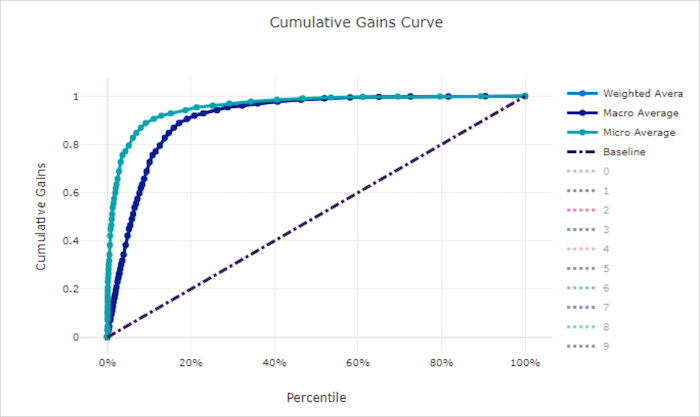
Curva de ganhos cumulativos para um modelo bom
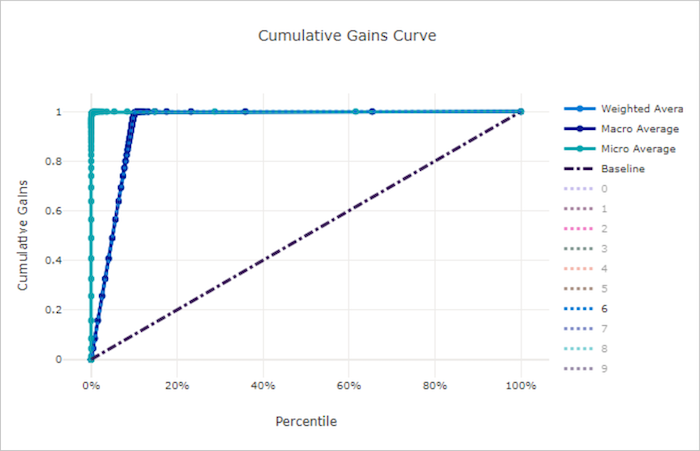
Curva de ganhos cumulativos para um modelo ruim
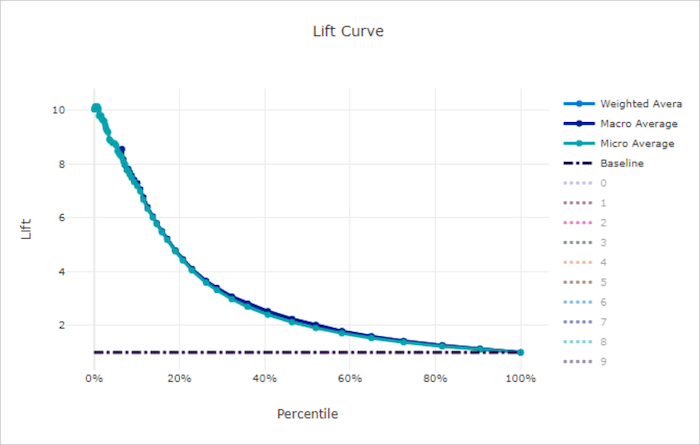
Curva de comparação de precisão
A curva de desempenho mostra quantas vezes o desempenho de um modelo é melhor comparado a um modelo aleatório. Desempenho (lift) é definido como a taxa de ganho cumulativo para o ganho cumulativo de um modelo aleatório (que deve sempre ser 1).
Esse desempenho relativo leva em conta o fato de que a classificação fica mais difícil à medida que você aumenta o número de classes. (Um modelo aleatório prevê incorretamente uma fração mais alta de exemplos de um conjunto de dados com 10 classes comparado a um conjunto com uma com duas classes)
A curva de comparação de linha de base é a linha y = 1 em que o desempenho do modelo é consistente com o de um modelo aleatório. Em geral, a curva de desempenho de um bom modelo é mais alta nesse gráfico e mais distante do eixo x, mostrando que, quando o modelo está mais confiante em suas previsões, ele tem um desempenho muitas vezes melhor do que a adivinhação aleatória.
Dica
Para experimentos de classificação, cada um dos gráficos de linhas produzidos para modelos de ML automatizado pode ser usado para avaliar o modelo por classe ou a média em todas as classes. Você pode alternar entre esses modos de exibição diferentes clicando nos rótulos de classe na legenda à direita do gráfico.
Curva de desempenho para um modelo bom
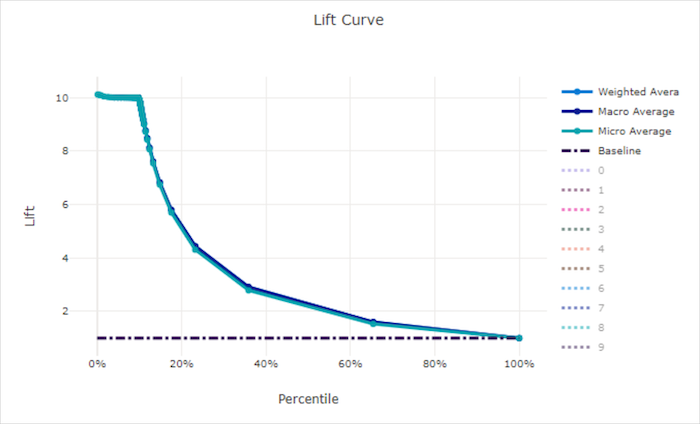
Curva de desempenho para um modelo ruim
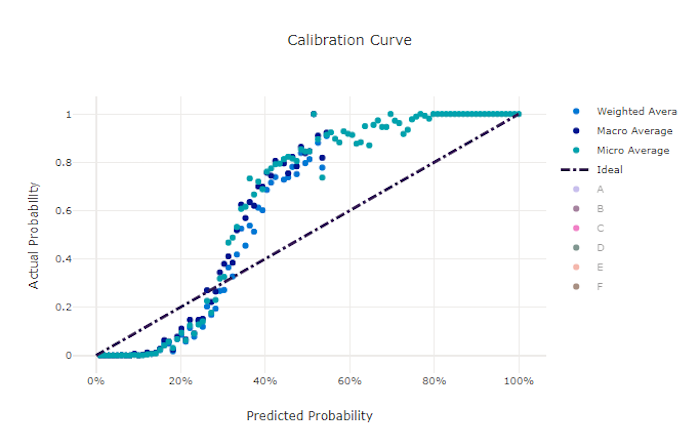
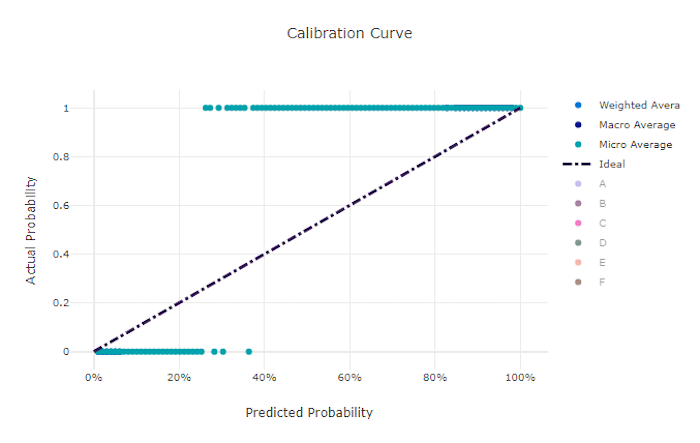
Curva de calibragem
A curva de calibragem plota a confiança de um modelo nas suas previsões em relação à proporção de amostras positivas em cada nível de confiança. Um modelo bem calibrado classificará corretamente 100% das previsões às quais atribui 100% de confiança, 50% das previsões que atribui 50% de confiança, 20% das previsões que atribui uma confiança de 20% e assim por diante. Um modelo perfeitamente calibrado tem uma curva de calibração seguindo a linha y = x em que o modelo prevê perfeitamente a probabilidade de as amostras pertencerem a cada classe.
Um modelo com confiança excessiva prevê probabilidades próximas a zero e um, raramente sendo incerto sobre a classe de cada amostra, e a curva de calibração será semelhante a um "S" invertido. Um modelo pouco confiante atribui uma probabilidade menor, em média, à classe que prevê, e a curva de calibração associada é semelhante a um "S". A curva de calibração não representa a capacidade de um modelo de classificar corretamente, mas sim sua capacidade de atribuir confiança corretamente às suas previsões. Um modelo ruim ainda pode ter uma boa curva de calibragem se o modelo atribui corretamente baixa confiança e alta incerteza.
Observação
A curva de calibragem é sensível ao número de amostras, de modo que um pequeno conjunto de validação pode produzir resultados com ruídos que podem ser difíceis de interpretar. Isso não significa, necessariamente, que o modelo não esteja bem calibrado.
Curva de calibragem para um modelo bom
Curva de calibragem para um modelo ruim
Métricas de regressão/previsão
O ML automatizado calcula as mesmas métricas de desempenho para cada modelo gerado, independentemente de se tratar de um experimento de regressão ou previsão. Essas métricas também passam por normalização para permitir a comparação entre modelos treinados em dados com diferentes intervalos. Para saber mais, confira normalização de métricas.
A tabela a seguir resume as métricas de desempenho de modelos geradas para os experimentos de regressão e previsão. Tal como as métricas de classificação, essas métricas também são baseadas nas implementações de scikit learn. A documentação apropriada da scikit learn está vinculada de forma correspondente, no campo Cálculo.
| Métrica | Descrição | Cálculo |
|---|---|---|
| explained_variance | A variância explicada mede a extensão que um modelo conta para a variação na variável de destino. É a diminuição percentual da variância dos dados originais em relação à variância dos erros. Quando a média dos erros é 0, ela é igual ao coeficiente de determinação (consulte r2_score no gráfico a seguir). Objetivo: quanto mais próximo de 1 melhor Intervalo: (-inf, 1] |
Cálculo |
| mean_absolute_error | Erro médio absoluto é o valor esperado do valor absoluto da diferença entre o alvo e a previsão. Objetivo: quanto mais próximo de 0 melhor Intervalo: [0, inf) Tipos: mean_absolute_error normalized_mean_absolute_error, o mean_absolute_error dividido pelo intervalo dos dados. |
Cálculo |
| mean_absolute_percentage_error | Erro de percentual absoluto médio (MAPE) é uma medida da diferença média entre um valor previsto e o valor real. Objetivo: quanto mais próximo de 0 melhor Intervalo: [0, inf) |
|
| median_absolute_error | O erro absoluto mediano é a mediana de todas as diferenças absolutas entre a meta e a previsão. Essa perda é robusta para exceções. Objetivo: quanto mais próximo de 0 melhor Intervalo: [0, inf) Tipos: median_absolute_errornormalized_median_absolute_error: o median_absolute_error dividido pelo intervalo dos dados. |
Cálculo |
| r2_score | R2 (o coeficiente de determinação) mede a redução proporcional no erro quadrático médio (MSE) em relação à variância total dos dados observados. Objetivo: quanto mais próximo de 1 melhor Intervalo: [-1, 1] Observação: R2 geralmente tem o intervalo (-inf, 1]. O MSE pode ser maior do que a variância observada, portanto, R2 pode ter valores negativos arbitrariamente grandes, dependendo dos dados e das previsões do modelo. Os clipes do ML automatizado relataram pontuações de R2 em -1, portanto, um valor de -1 para R2 provavelmente significa que a pontuação de R2 verdadeira é menor que -1. Considere os outros valores de métricas e as propriedades dos dados ao interpretar uma pontuação de R2 negativa. |
Cálculo |
| root_mean_squared_error | Raiz do erro quadrático médio (RMSE) é a raiz quadrada da diferença esperada ao quadrado entre o alvo e a previsão. Para um estimador não polarizado, o RMSE é igual ao desvio padrão. Objetivo: quanto mais próximo de 0 melhor Intervalo: [0, inf) Tipos: root_mean_squared_error normalized_root_mean_squared_error: o root_mean_squared_error dividido pelo intervalo dos dados. |
Cálculo |
| root_mean_squared_log_error | Raiz do erro de log quadrático médio é a raiz quadrada do erro logarítmico quadrático esperado. Objetivo: quanto mais próximo de 0 melhor Intervalo: [0, inf) Tipos: root_mean_squared_log_error normalized_root_mean_squared_log_error: o root_mean_squared_log_error dividido pelo intervalo dos dados. |
Cálculo |
| spearman_correlation | Correlação de Spearman é uma medida não paramétrica da monotonicidade da relação entre dois conjuntos de dados. Diferentemente da correlação de Pearson, a correlação de Spearman não pressupõe que os dois conjuntos de dados sejam normalmente distribuídos. Como outros coeficientes de correlação, Spearman varia entre -1 e 1 com 0 implicando nenhuma correlação. As correlações de -1 ou 1 implicam uma relação monotônica exata. Spearman é uma métrica de correlação de ordem de classificação, o que significa que as alterações nos valores previstos ou reais não alterarão o resultado de Spearman se não alterarem a ordem de classificação dos valores previstos ou reais. Objetivo: quanto mais próximo de 1 melhor Intervalo: [-1, 1] |
Cálculo |
Normalização de métricas
O ML automatizado normaliza as métricas de regressão e previsão, o que habilita a comparação entre modelos treinados em dados com diferentes intervalos. Um modelo treinado em um dado com um intervalo maior tem um erro maior do que o mesmo modelo treinado em dados com um intervalo menor, a menos que esse erro seja normalizado.
Embora não haja um método padrão para normalizar as métricas de erro, o ML automatizado adota a abordagem comum de dividir o erro pelo intervalo dos dados: normalized_error = error / (y_max - y_min)
Observação
O intervalo de dados não é salvo com o modelo. Se você fizer inferência com o mesmo modelo em um conjunto de teste de dados de controle, y_min e y_max poderão mudar de acordo com os dados de teste, e as métricas normalizadas não poderão ser usadas diretamente para comparar o desempenho do modelo em conjuntos de teste e treinamento. Você pode passar o valor de y_min e y_max do conjunto de treinamento para tornar a comparação justa.
Métricas de previsão: normalização e agregação
O cálculo de métricas para a avaliação do modelo de previsão requer algumas considerações especiais quando os dados contêm várias séries temporais. Há duas opções naturais para agregar métricas em várias séries:
- Uma média macro em que as métricas de avaliação de cada série recebem peso igual,
- Uma média micro em que as métricas de avaliação para cada previsão têm peso igual.
Esses casos têm analogias diretas com a média macro e micro na classificação multiclasse.
A distinção entre a média macro e micro pode ser importante ao selecionar uma métrica primária para seleção de modelo. Por exemplo, considere um cenário de varejo em que você deseja prever a demanda por uma seleção de produtos de consumo. Alguns produtos são vendidos em volumes maiores do que outros. Se você escolher um RMSE com média micro como a métrica principal, é possível que os itens de alto volume contribuam com a maior parte do erro de modelagem e, portanto, dominem a métrica. O algoritmo de seleção de modelos pode favorecer modelos com maior exatidão nos itens de alto volume do que nos de baixo volume. Por outro lado, uma REQM normalizada e com média macro fornece aos itens de baixo volume um peso aproximadamente igual ao dos itens de alto volume.
A tabela a seguir lista quais métricas de previsão do AutoML usam macro versus micro média:
| Com média macro | Com média micro |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Observe que as métricas com média macro normalizam cada série separadamente. As métricas normalizadas de cada série são então arredondadas para dar o resultado final. A escolha correta de macro ou micro depende do cenário de negócios, mas geralmente é recomendável usar normalized_root_mean_squared_error.
Resíduos
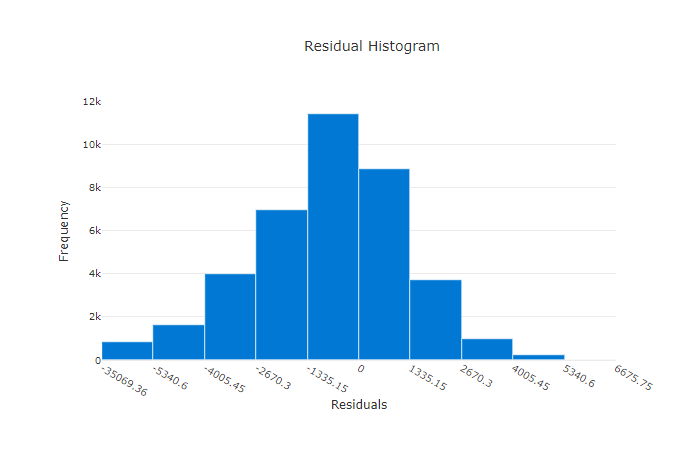
O gráfico de resíduos é um histograma dos erros de previsão (resíduos) gerados para experimentos de regressão e previsão. Os resíduos são calculados como y_predicted - y_true para todas as amostras e, em seguida, exibidos como um histograma para mostrar o desvio do modelo.
Neste exemplo, ambos os modelos são ligeiramente tendenciosos para prever um valor inferior ao real. Isso não é incomum em um conjunto de dados com uma distribuição distorcida de alvos reais, mas indica um desempenho pior do modelo. Um bom modelo tem uma distribuição de resíduos que atinge o pico em zero, com poucos resíduos nos extremos. Um modelo pior tem uma distribuição de resíduos espalhada com menos amostras em torno de zero.
Gráfico de resíduos para um modelo bom
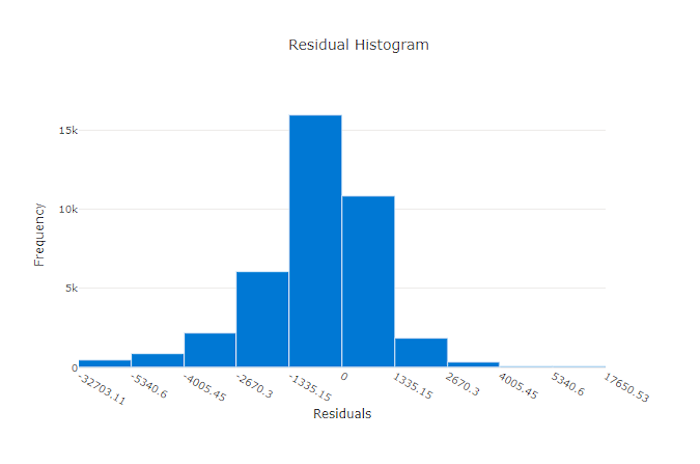
Gráfico de resíduos para um modelo ruim
Previsto versus verdadeiro
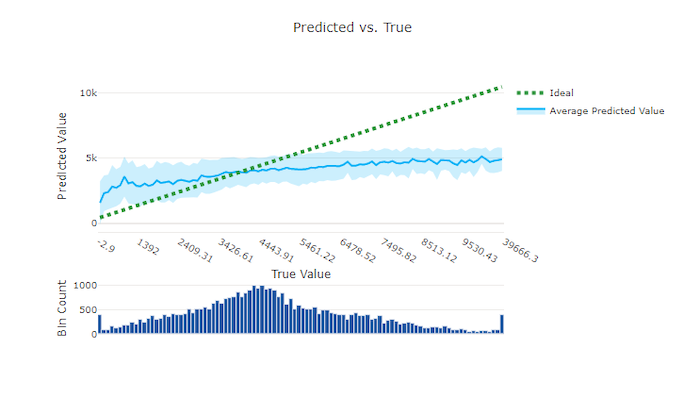
Para o experimento de regressão e previsão, o gráfico previsto versus verdadeiro plota a relação entre o recurso alvo (valores verdadeiros/reais) e as previsões do modelo. Os valores verdadeiros são compartimentalizados ao longo do eixo x e, para cada compartimento, o valor estimado médio é plotado com barras de erro. Isso permite que você veja se um modelo tende a prever determinados valores. A linha exibe a previsão média e a área sombreada indica a variância de previsões em torno dessa média.
Geralmente, o valor verdadeiro mais comum tem as previsões mais precisas com a menor variação. A distância da linha de tendência da linha y = x ideal em que há poucos valores verdadeiros é uma boa medida do desempenho do modelo em exceções. Você pode usar o histograma na parte inferior do gráfico para a razão da distribuição de dados reais. Incluir mais amostras de dados onde a distribuição for esparsa pode melhorar o desempenho do modelo em dados não vistos.
Neste exemplo, observe que o melhor modelo tem uma linha prevista versus verdadeira que está mais próxima da linha y = x ideal.
Gráfico previsto versus verdadeiro para um modelo bom
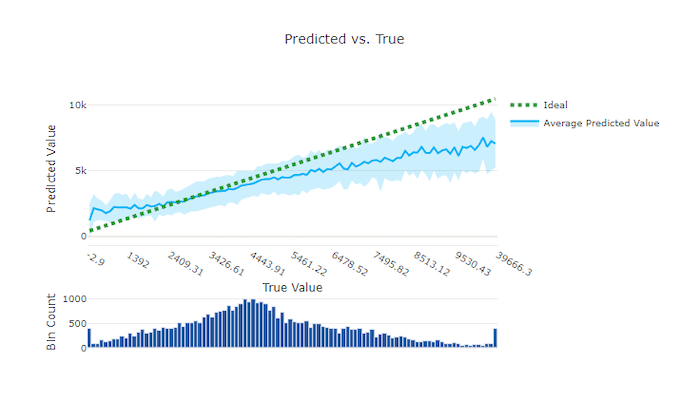
Gráfico previsto versus verdadeiro para um modelo ruim
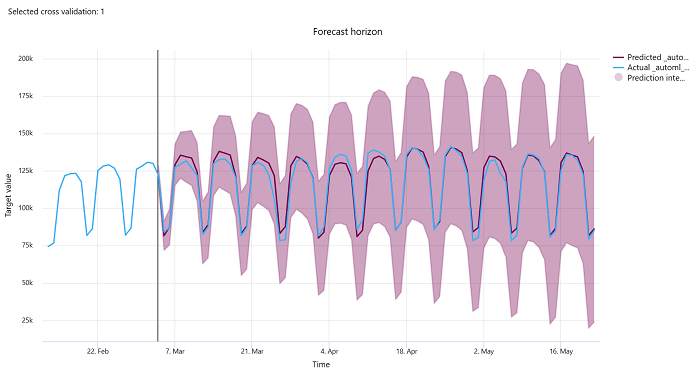
Horizonte de previsão
Para experimentos de previsão, o gráfico de horizonte de previsão traça a relação entre o valor previsto pelos modelos e os valores reais mapeados ao longo do tempo por dobra de validação cruzada, até cinco dobras. O eixo x mapeia o tempo com base na frequência fornecida durante a configuração do treinamento. A linha vertical no gráfico marca o ponto do horizonte de previsão, também conhecido como a linha do horizonte, que é o período com base no qual você gostaria de começar a gerar previsões. À esquerda da linha do horizonte de previsão, você pode exibir dados de treinamento históricos para visualizar melhor as tendências passadas. À direita do horizonte de previsão, você pode visualizar as previsões (a linha roxa) em relação aos valores reais (a linha azul) para as diferentes dobras de validação cruzada e identificadores de série temporal. A área sombreada roxa indica os intervalos de confiança ou a variância das previsões em torno dessa média.
Você pode escolher quais combinações de dobras de validação cruzada e identificadores de séries temporais serão exibidas clicando no ícone de lápis editado no canto superior direito do gráfico. Selecione entre as cinco primeiras dobras de validação cruzada e até 20 identificadores de séries temporais diferentes para visualizar o gráfico de suas várias séries temporais.
Importante
Esse gráfico está disponível na execução de treinamento para os modelos gerados com base nos dados de treinamento e validação, bem como na execução de teste baseada em dados de treinamento e em dados de teste. Permitimos até 20 pontos de dados antes e até 80 pontos de dados após a origem da previsão. Para os modelos DNN, esse gráfico na execução de treinamento mostra os dados da última época, ou seja, depois que o modelo foi treinado por completo. Esse gráfico na execução de teste poderá ter uma lacuna antes da linha do horizonte se os dados de validação tiverem sido fornecidos explicitamente durante a execução do treinamento. Isso ocorre porque os dados de treinamento e os dados de teste são usados na execução de teste, deixando de fora os dados de validação que resultam na lacuna.
Métricas de modelos de imagem (versão prévia)
O ML automatizado usa as imagens do conjunto de dados de validação para avaliar o desempenho do modelo. O desempenho do modelo é medido em um nível de época para entender o progresso do treinamento. Uma época passa quando um conjunto de dados inteiro é passado para frente e para trás pela rede neural exatamente uma vez.
Métricas de classificação de imagem
A principal métrica para avaliação é a precisão para modelos de classificação binários e multiclasse, e IoU (Interseção sobre União) para modelos de classificação multirrótulo. As métricas de classificação para modelos de classificação de imagem são as mesmas definidas na seção de métricas de classificação. Os valores de perda associados a uma época também são registrados, o que pode ajudar a monitorar o progresso do treinamento e determinar se o desempenho do modelo está acima ou abaixo do ajuste.
Cada previsão de um modelo de classificação é associada a uma pontuação que indica o nível de confiança com o qual a previsão foi feita. Por padrão, os modelos de classificação de imagens de multirrótulo são avaliados com um limite de pontuação de 0,5, o que significa que somente as previsões com pelo menos esse nível de confiança são consideradas como uma previsão positiva para a classe associada. A classificação multiclasse não usa um limite de pontuação, mas, em vez disso, a classe com a pontuação de confiança máxima é considerada como a previsão.
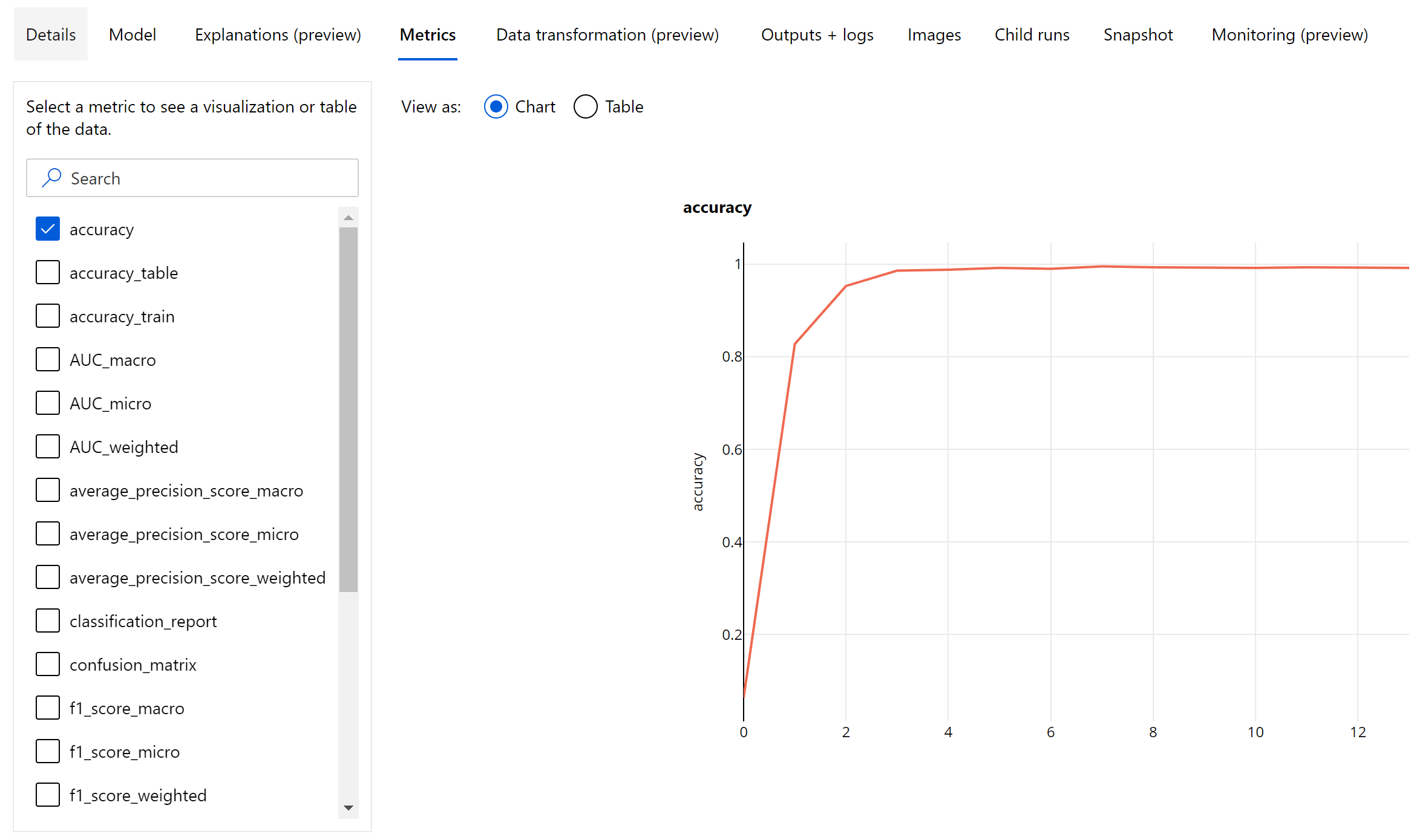
Métricas em nível de época de classificação de imagem
Ao contrário das métricas de classificação de conjuntos de dados tabulares, os modelos de classificação de imagem registram todas as métricas de classificação em um nível de época, conforme mostrado abaixo.
Métricas de resumo de classificação de imagem
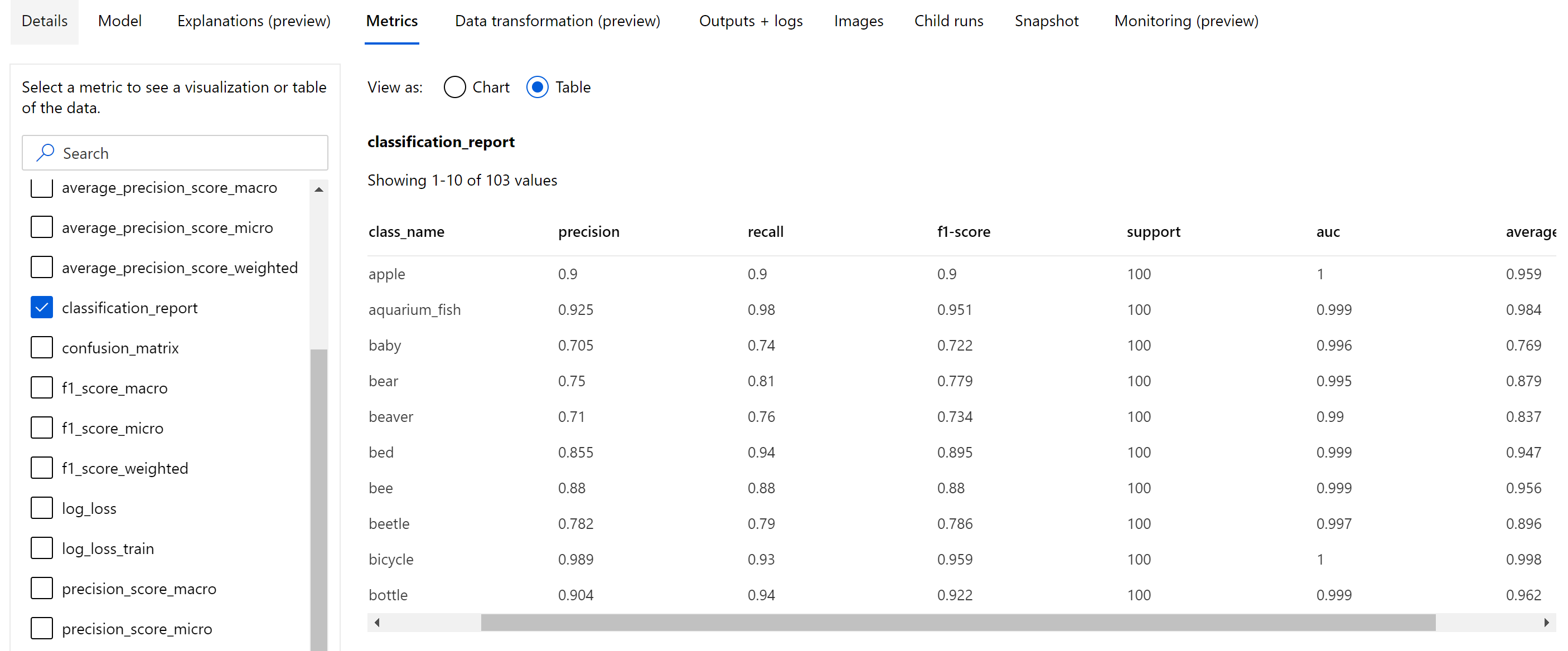
Além das métricas escalares, que são registradas em nível de época, o modelo de classificação de imagem também registra métricas de resumo, como matriz de confusão, gráficos de classificação, incluindo curva ROC, curva de precisão de recall e relatório de classificação para o modelo proveniente da melhor época em que se pode obter a maior pontuação da métrica primária (precisão).
O relatório de classificação fornece os valores em nível de classe para métricas como precisão, recuperação, pontuação f1, suporte, auc e average_precision com vários níveis de definição da média - micro, macro e ponderado, conforme mostrado abaixo. Consulte as definições de métricas na seção métricas de classificação.
Detecção de objetos e métricas de segmentação de instância
Cada previsão de um modelo de detecção de objeto de imagem ou segmentação de instância está associada a uma pontuação de confiança.
As previsões com pontuação de confiança maior que o limite de pontuação são geradas como previsões e usadas no cálculo da métrica, cujo valor padrão é específico do modelo e pode ser conferido na página de ajuste de hiperparâmetro (hiperparâmetro box_score_threshold).
O cálculo de métrica de uma detecção de objeto de imagem e modelo de segmentação de instância é baseado em uma medição de sobreposição definida por uma métrica chamada IoU (Intersecção sobre União), que é calculada dividindo o resultado da área de sobreposição entre e a realidade prática e as previsões pela área de união da realidade prática e as previsões. O IoU computado a partir de cada previsão é comparado com um limite de sobreposição chamado de limite de IoU, que determina o quanto uma previsão deve se sobrepor a uma verdade básica anotada pelo usuário para ser considerada uma previsão positiva. Se o IoU computado a partir da previsão for menor que o limite de sobreposição, a previsão não será considerada uma previsão positiva para a classe associada.
A principal métrica para a avaliação da detecção de objetos de imagem e modelos de segmentação de instância é a mAP (média das precisões médias) . A mAP indica a média do valor de precisão média (AP) em todas as classes. Os modelos automatizados de detecção de objetos de ML oferecem suporte ao cálculo de mAP usando os dois métodos populares seguintes.
Métricas Pascal VOC:
A métrica mAP para Pascal VOC é a forma padrão de computação de mAP para modelos de detecção de objetos/segmentação de instâncias. O método mAP de estilo Pascal VOC calcula a área em uma versão da curva de recall de precisão. O primeiro p(rᵢ), que é a precisão no recall i, é calculado para todos os valores de recall únicos. O p(rᵢ) então é substituído pela precisão máxima obtida para qualquer recall r' >= rᵢ. Nessa versão da curva, o valor de precisão está diminuindo de forma monotônica. A métrica mAP para Pascal VOC é avaliada por padrão com um limite de IoU de 0,5. Leia uma explicação completa desse conceito neste blog.
Métricas COCO:
O método de avaliação COCO usa um método de interpolação de 101 pontos para cálculo de AP junto com a média de mais de dez limites de IoU. AP@[.5:.95] corresponde a uma média de AP para IoU de 0,5 a 0,95 com um tamanho de etapa de 0,05. O ML automatizado registra todas as 12 métricas definidas pelo método COCO, incluindo o AP e o AR (recuperação média) em várias escalas nos logs do aplicativo, enquanto a interface do usuário das métricas mostra apenas o mAP em um limite de IoU de 0,5.
Dica
A avaliação do modelo de detecção de objeto de imagem poderá usar métricas COCO se o hiperparâmetro validation_metric_type estiver definido como 'coco', conforme explicado na seção de ajuste de hiperparâmetro.
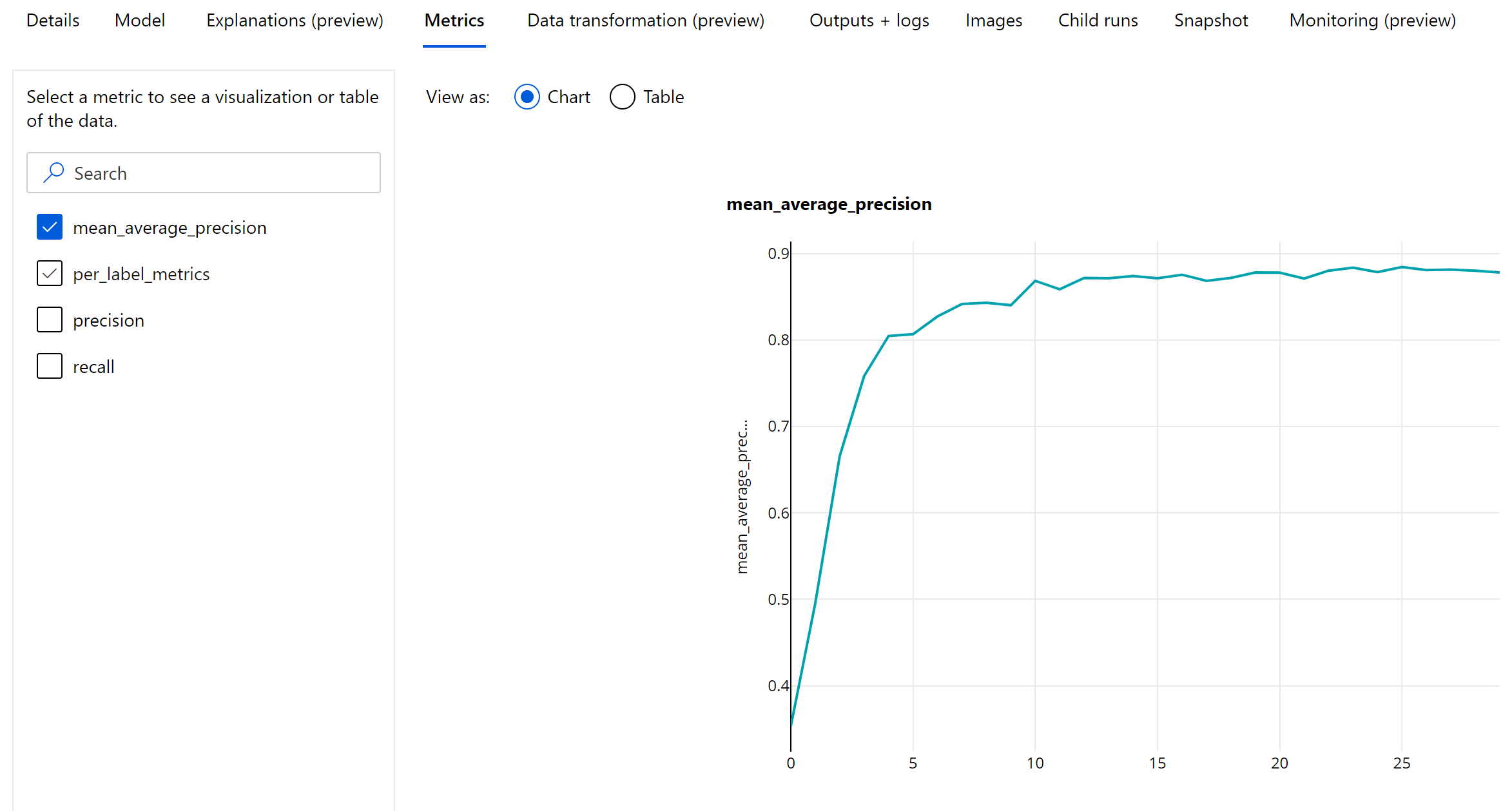
Métricas em nível de época para detecção de objetos e segmentação de instâncias
Os valores de mAP, precisão e recuperação são registrados em nível de época para modelos de detecção de objetos de imagem/segmentação de instâncias. As métricas de mAP, precisão e recuperação também são registradas em um nível de classe com o nome "per_label_metrics". O "per_label_metrics" deve ser exibido como uma tabela.
Observação
As métricas em nível de época para precisão, recall e per_label_metrics não estão disponíveis ao usar o método 'coco'.
Dashboard de IA responsável para o modelo AutoML mais recomendado (versão prévia)
O painel de IA Responsável do Azure Machine Learning fornece uma única interface para ajudar você a implementar a IA Responsável na prática de forma eficaz e eficiente. O dashboard de IA responsável só é compatível com o uso de dados tabulares e com modelos de classificação e regressão. Ele reúne várias ferramentas de IA Responsável maduras nas áreas de:
- Avaliação de desempenho e imparcialidade de modelo
- Exploração de dados
- Interpretabilidade de aprendizado de máquina
- Análise de erros
Embora as métricas e os gráficos de avaliação de modelos sejam bons para medir a qualidade geral de um modelo, operações como inspecionar a imparcialidade do modelo, exibir suas explicações (também conhecidas como os recursos de conjuntos de dados que um modelo usou para fazer previsões), inspecionar seus erros e pontos cegos potenciais são essenciais para a prática de IA responsável. É por isso que o ML automatizado fornece um painel de IA responsável para ajudá-lo a observar vários insights do seu modelo. Confira como visualizar o painel de IA Responsável no Estúdio do Azure Machine Learning.
Veja como você pode gerar esse painel por meio da interface do usuário ou do SDK.
Explicações do modelo e importância do recurso
Embora as métricas e os gráficos de avaliação de modelos sejam bons para medir a qualidade geral de um modelo, inspecionar quais recursos de conjuntos de dados são usados por um modelo para fazer suas previsões é essencial para a prática de IA responsável. É por isso que o ML automatizado disponibiliza um painel de explicações de modelo para medir e relatar as contribuições relativas das funcionalidades do conjunto de dados. Confira como exibir o painel de explicações no Estúdio do Azure Machine Learning.
Observação
A interpretabilidade, a melhor explicação do modelo, não está disponível para experimentos de previsão de ML automatizado que recomendam os seguintes algoritmos como o melhor modelo ou conjunto:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- Média
- Naive
- Seasonal Average
- Seasonal Naive
Próximas etapas
- Experimente os cadernos de amostra de explicação de modelos de aprendizado de máquina automatizado.
- Para perguntas específicas do ML automatizado, entre em contato com askautomatedml@microsoft.com.