Disparar pipelines do aprendizado de máquina
APLICA-SE A:  SDK do Python azureml v1
SDK do Python azureml v1
Neste artigo, é mostrado como agendar programaticamente um pipeline para ser executado no Azure. É possível criar um agendamento com base no tempo decorrido ou nas alterações do sistema de arquivos. Agendamentos baseados em tempo podem ser usados para cuidar de tarefas rotineiras, como o monitoramento de descompasso de dados. Os agendamentos baseados em alterações podem ser usados para reagir a alterações irregulares ou imprevisíveis, como carga de novos dados ou dados edição de dados antigos. Depois de aprender a criar agendamentos, aprenderá a recuperá-los e desativá-los. Por fim, aprenderá a usar outros serviços do Azure, o aplicativo lógico do Azure e o Azure Data Factory, para executar pipelines. Um aplicativo lógico do Azure permite lógicas ou comportamentos mais complexos de gatilhos. Os pipelines do Azure Data Factory permitem chamar um pipeline do Machine Learning como parte de um pipeline de orquestração de dados maior.
Pré-requisitos
Uma assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita.
Um ambiente do Python no qual o SDK do Azure Machine Learning para Python está instalado. Para obter mais informações, consulte Criar e gerenciar ambientes reutilizáveis para treinamento e implantação com o Azure Machine Learning.
Um workspace do Machine Learning com um pipeline publicado. É possível usar o workspace interno Criar e executar pipelines de machine learning com o SDK do Azure Machine Learning.
Disparar pipelines com Azure Machine Learning SDK para Python
Para agendar um pipeline, é necessária uma referência ao workspace, o identificador do pipeline publicado e o nome do experimento no qual deseja criar o agendamento. É possível ter vários tipos com o seguinte código:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Criar um agendamento
Para executar um pipeline de forma recorrente, crie um agendamento. Um Schedule associa um pipeline, um experimento e um gatilho. O gatilho pode ser um ScheduleRecurrence, que descreve a espera entre trabalhos ou um caminho de armazenamento de dados que especifica um diretório para observar as alterações. Nos dois casos, será necessário o identificador do pipeline e do nome do experimento no qual será criado o agendamento.
Na parte superior do arquivo Python, importe as classes Schedule e ScheduleRecurrence:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Criar um agendamento baseado em tempo
O ScheduleRecurrence Construtor tem um argumento obrigatóriofrequency que deve ser uma das seguintes cadeias de caracteres: "minuto", "hora", "dia", "semana" ou "mês". Também exige um interval argumento inteiro especificando quantas frequency unidades devem decorrer entre os inícios do agendamento. Os argumentos opcionais permitem que ser mais específico sobre os horários de início, conforme detalhado nos documentos do SDK do ScheduleRecurrence.
Crie um Schedule que comece um trabalho a cada 15 minutos:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Criar um agendamento baseado em alteração
Os pipelines disparados por alterações de arquivo podem ser mais eficientes do que os agendamentos baseados em tempo. Quando desejar fazer algo antes de um arquivo ser alterado, ou quando um novo arquivo for adicionado a um diretório de dados, é possível pré-processar esse arquivo. É possível monitorar qualquer alteração em um armazenamento de dados ou alterações dentro de um diretório específico armazenamento de dados. Se monitorar um diretório específico, as alterações nos subdiretórios desse diretório não dispararão um trabalho.
Observação
Os agendamentos com base em alterações dão suporte apenas ao monitoramento do Armazenamento de Blobs do Azure.
Para criar um arquivo-reativo Schedule, deverá definir o parâmetro datastore na chamada para Schedule.create. Para monitorar uma pasta, defina o argumento path_on_datastore.
O argumento polling_interval permite especificar, em minutos, a frequência na qual o repositório de armazenamento é verificado quanto a alterações.
Se o pipeline foi construído com um DataPath PipelineParameter, é possível definir essa variável como o nome do arquivo alterado, definindo o argumento data_path_parameter_name.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Argumentos opcionais ao criar um agendamento
Além dos argumentos discutidos anteriormente, é possível definir o argumento status como "Disabled" para criar um agendamento inativo. Por fim, o continue_on_step_failure permite passar um booliano que substituirá o comportamento de falha padrão do pipeline.
Exibir os pipelines agendados
No navegador da Web, navegue até o Azure Machine Learning. Na seção Pontos de extremidade do painel de navegação, escolha Pontos de extremidade de pipeline. Com isso será direcionado para uma lista com os pipelines publicados no Workspace.
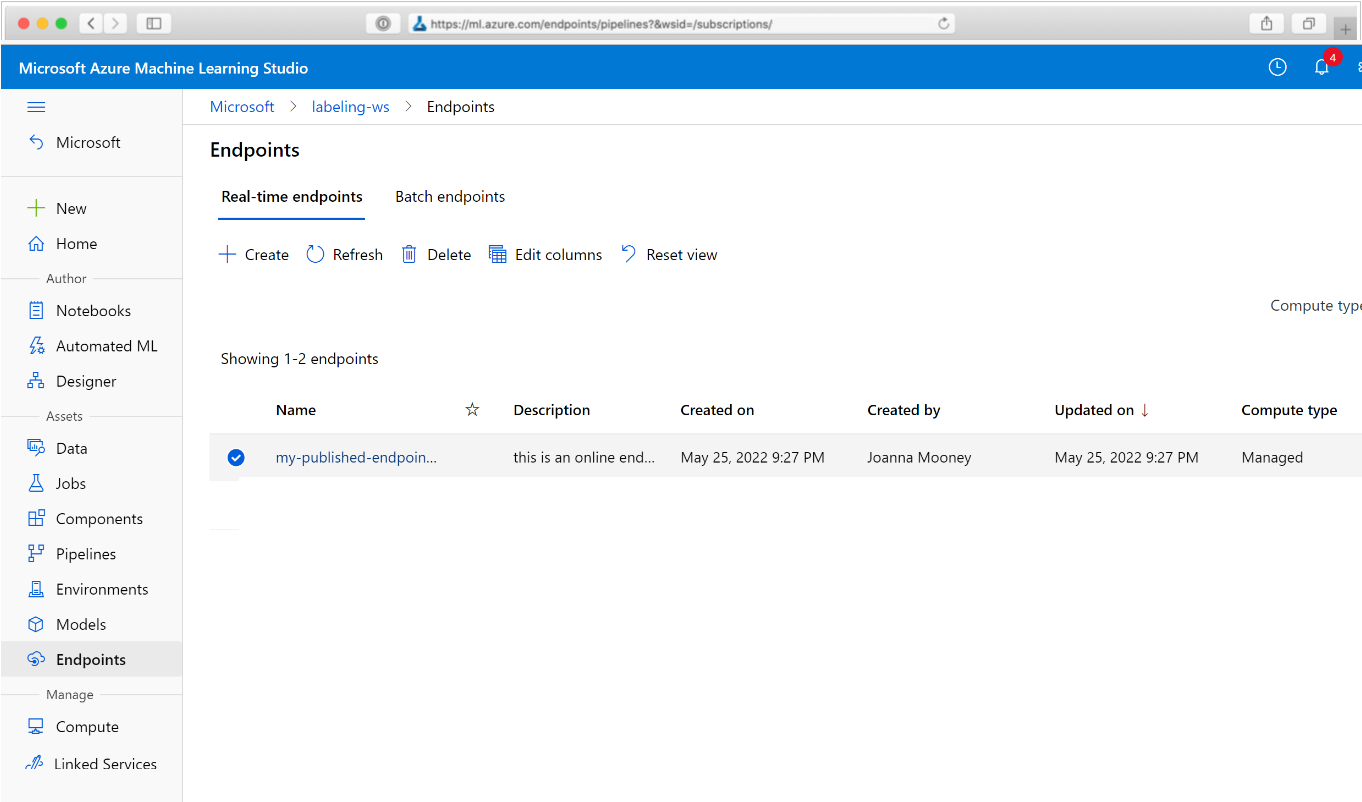
Nesta página, é possível ver informações resumidas sobre todos os pipelines no Workspace: nomes, descrições, status e assim por diante. Faça uma busca detalhada clicando em seu pipeline. Na página resultante, há mais detalhes sobre o pipeline e é possível fazer busca detalhada em trabalhos individuais.
Desativar o pipeline
Caso tenha um Pipeline que está publicado, mas não agendado, é possível desabilitá-lo com:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Se o pipeline estiver agendado, deverá primeiro cancelar o agendamento. Recupere o identificador do agendamento do portal ou executando:
ss = Schedule.list(ws)
for s in ss:
print(s)
Quando tiver o schedule_id que deseja desabilitar, execute:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Se executar Schedule.list(ws) novamente, deverá obter uma lista vazia.
Usar Aplicativos Lógicos do Azure para gatilhos complexos
Regras mais complexas de gatilho ou de comportamento podem ser criadas usando um Aplicativo Lógico do Azure.
Para usar um aplicativo lógico do Azure para disparar um pipeline de Machine Learning, será necessário o ponto de extremidade REST para um pipeline de Machine Learning publicado. Criar e publicar o pipeline. Em seguida, localize o ponto de extremidade REST de seu PublishedPipeline usando a ID do pipeline:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Criar um aplicativo lógico no Azure
Agora, crie uma instância do aplicativo lógico do Azure. Depois que o aplicativo lógico for provisionado, use estas etapas para configurar um gatilho para o pipeline:
Crie uma identidade gerenciada atribuída pelo sistema para conceder ao aplicativo acesso ao Workspace do Azure Machine Learning.
Navegue até o modo de exibição designer de aplicativo lógico e selecione o modelo aplicativo lógico em branco.
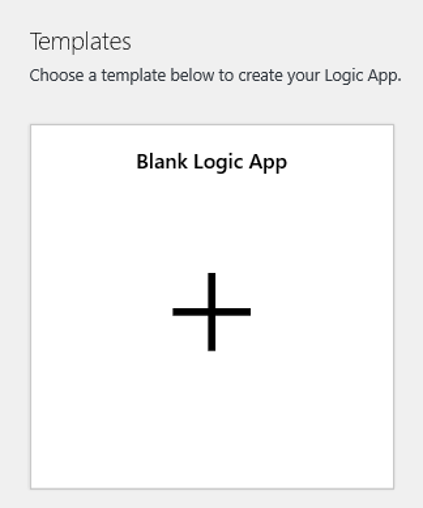
No Designer, pesquise por blob. Selecione o gatilho Quando um blob é adicionado ou modificado (somente Propriedades) e adicione esse gatilho ao aplicativo lógico.
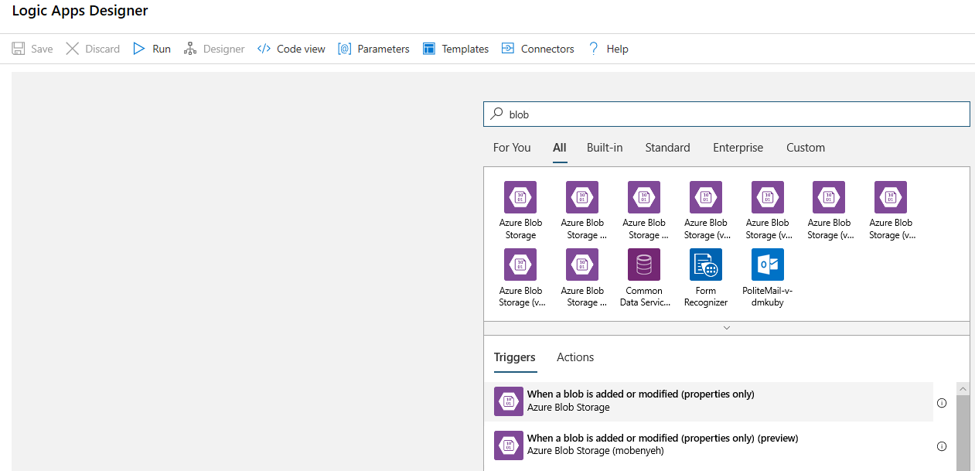
Preencha as informações de conexão para a conta de armazenamento de blobs que deseja monitorar para adições ou modificações de blobs. Selecione o contêiner a ser monitorado.
Escolha o Intervalo e a Frequência para sondar as atualizações adequadas para você.
Observação
Esse gatilho irá monitorará o contêiner selecionado, mas não as subpastas.
Adicione uma ação HTTP que será executada quando for detectado um blob novo ou modificado. Selecione + nova etapa, procure e selecione a ação HTTP.
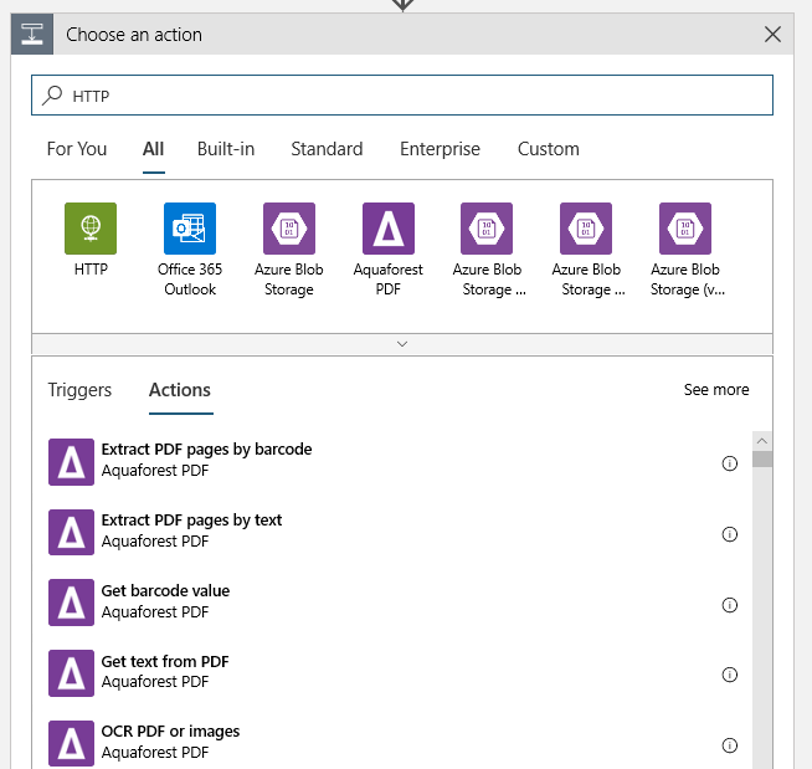
Use as configurações a seguir para configurar a ação:
| Configuração | Valor |
|---|---|
| Ação HTTP | POST |
| URI | o ponto de extremidade para o pipeline publicado que encontrado como um pré-requisito |
| Modo de autenticação | Identidade Gerenciada |
Configure sua programação para definir o valor de quaisquer DataPath PipelineParameters que você possa ter:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Use o
DataStoreNameadicionado o seu workspace como um pré-requisito.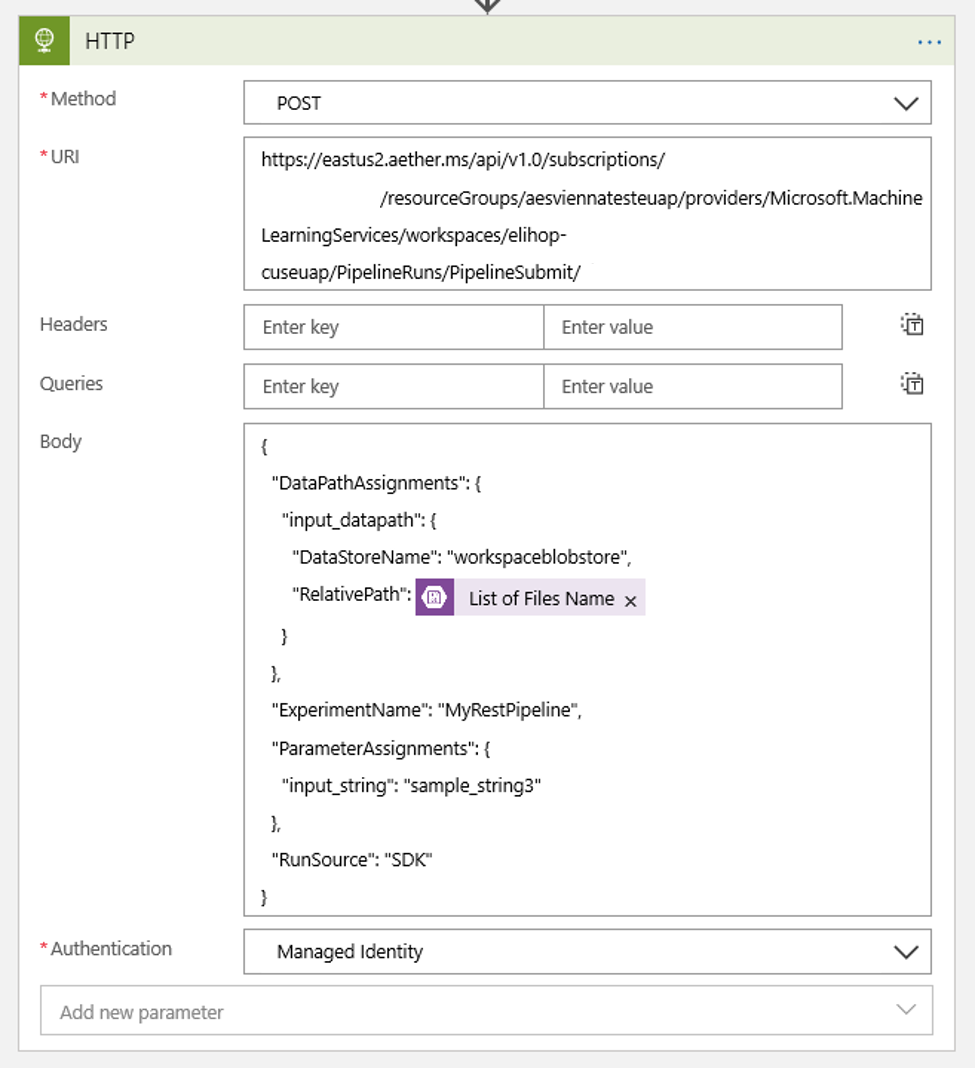
Selecione Salvar e seu agendamento agora está pronto.
Importante
Se estiver usando o RBAC (controle de acesso baseado em função) do Azure para gerenciar o acesso ao pipeline, defina as permissões para o cenário de pipeline (treinamento ou pontuação).
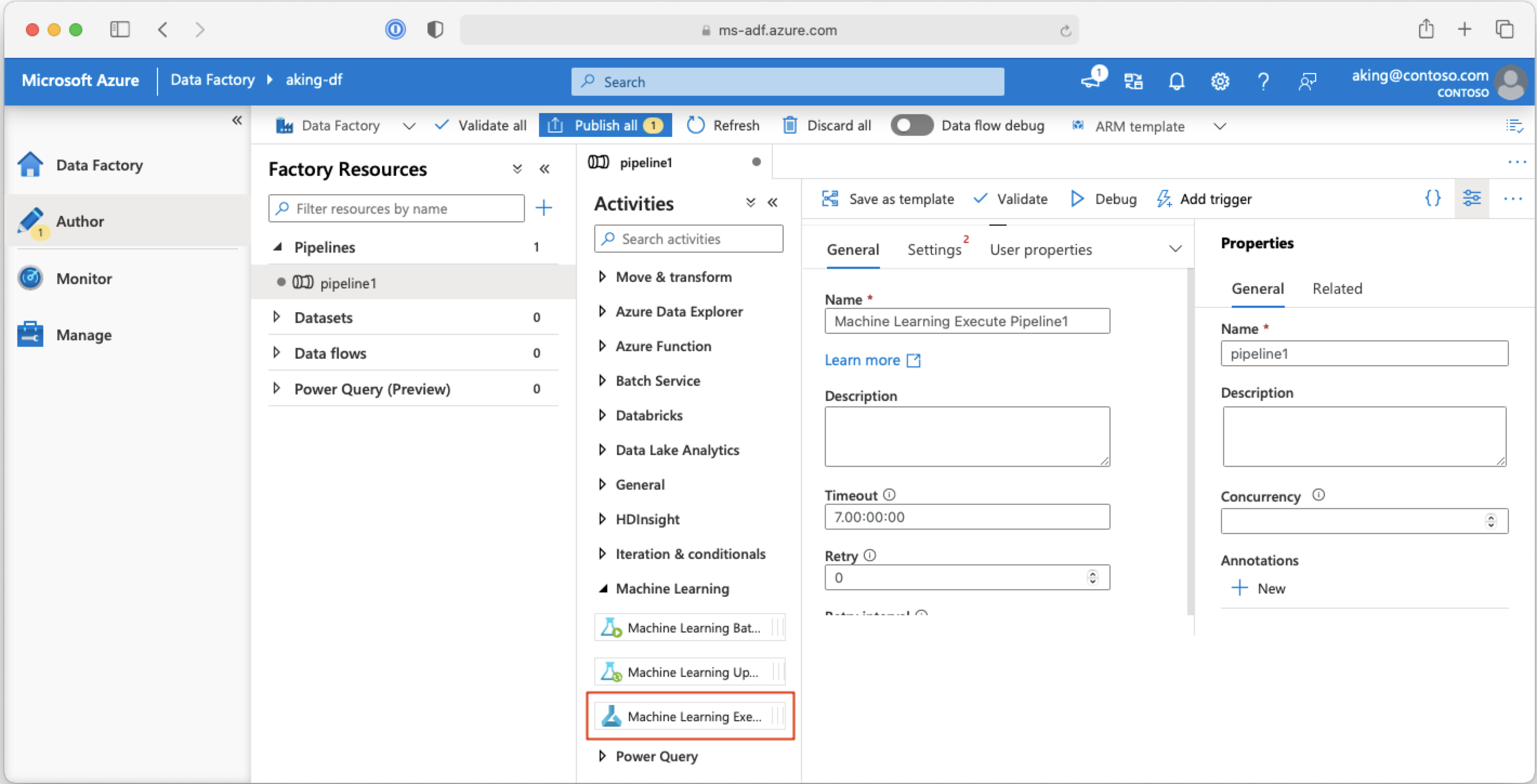
Chamar pipelines do Machine Learning de pipelines do Azure Data Factory
Em um pipeline do Azure Data Factory, a atividade Executar pipeline do Machine Learning executa um pipeline do Azure Machine Learning. É possível encontrar essa atividade na página de criação do Data Factory na categoria Machine Learning:
Próximas etapas
Neste artigo, foi usado o SDK do Azure Machine Learning para Python para agendar um pipeline de duas maneiras diferentes. Um agendamento se repete com base no tempo decorrido do relógio. O outro agendará trabalhos se um arquivo for modificado em um Datastore especificado ou dentro de um diretório nesse armazenamento. Foi visto como usar o portal para examinar o pipeline e os trabalhos individuais. Foi mostrado como desabilitar um agendamento para que o pipeline pare de funcionar. Por fim, foi criado um aplicativo lógico do Azure para disparar um pipeline.
Para obter mais informações, consulte:
- Saiba mais sobre os pipelines
- Saiba mais sobre como explorar o Azure Machine Learning com Jupyter