Criar e gerenciar ativos de dados
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Este artigo mostra como criar e gerenciar ativos de dados no Azure Machine Learning.
Os ativos de dados podem ajudar quando você precisa:
- Controle de versão: os ativos de dados dão suporte ao controle de versão de dados.
- Reprodutibilidade: Depois de criar uma versão de ativo de dados, ela será imutável. Não pode ser modificado ou excluído. Portanto, os trabalhos de treinamento ou pipelines que consomem o ativo de dados podem ser reproduzidos.
- Auditabilidade: como a versão do ativo de dados é imutável, você pode acompanhar as versões do ativo, quem atualizou uma versão e quando ocorreram as atualizações da versão.
- Linhagem: para um determinado ativo de dados, é possível exibir quais trabalhos ou pipelines consomem dados.
- Facilidade de uso: um ativo de dados de machine learning do Azure é semelhante aos indicadores do navegador da Web (favoritos). Em vez de se lembrar de longos caminhos de armazenamento (URIs) que fazem referência aos dados usados com frequência no Armazenamento do Azure, você pode criar uma versão de ativo de dados e, em seguida, acessar essa versão do ativo com um nome amigável (por exemplo:
azureml:<my_data_asset_name>:<version>).
Dica
Para acessar seus dados em uma sessão interativa (por exemplo, um notebook) ou em um trabalho, não será necessário criar um ativo de dados primeiro. Você pode usar URIs do armazenamento de dados para acessar os dados. As URIs do Armazenamento de Dados oferecem uma maneira simples de acessar dados para começar a usar o Azure Machine Learning.
Pré-requisitos
Para criar e trabalhar com ativos de dados, você precisa do seguinte:
Uma assinatura do Azure. Se você não tiver uma, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Um Workspace do Azure Machine Learning. Criar recursos do workspace.
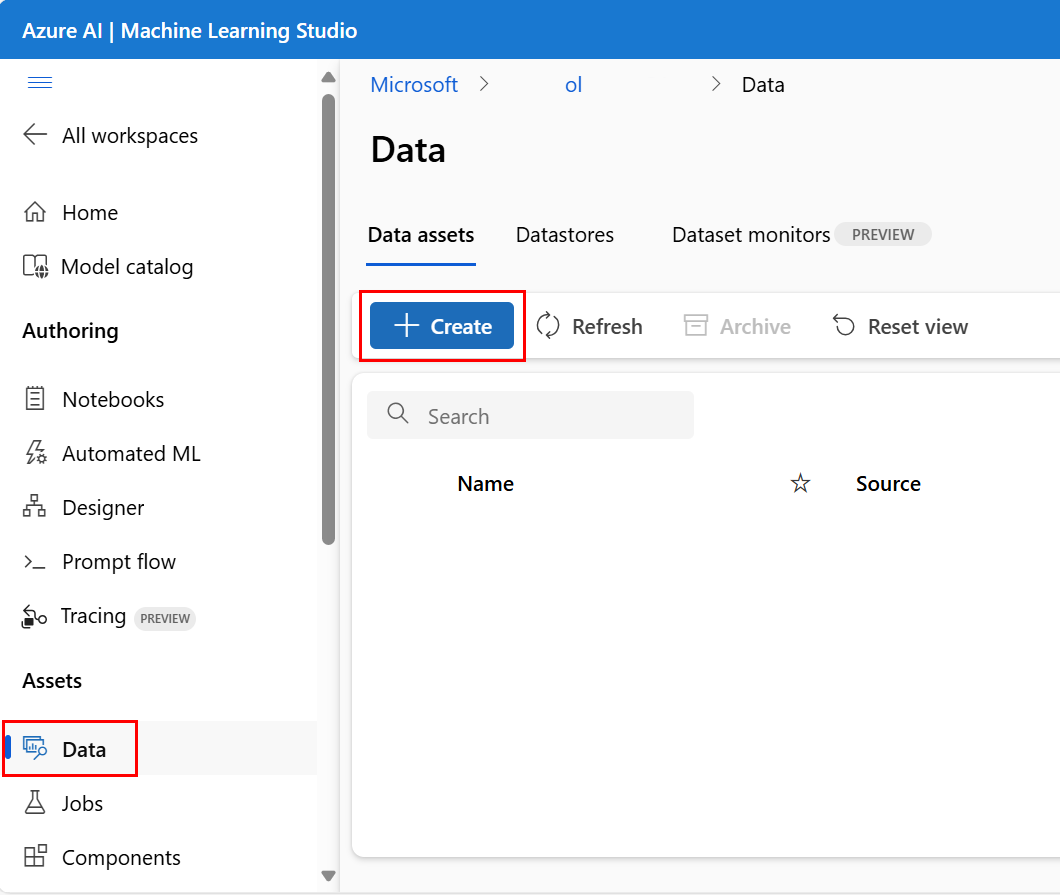
Criar ativos de dados
Ao criar seu ativo de dados, você precisa definir o tipo de ativo de dados. O Azure Machine Learning oferece suporte a três tipos de ativos de dados:
| Type | API | Cenários canônicos |
|---|---|---|
| Arquivo Referenciar um só arquivo |
uri_file |
Leia um único arquivo no Armazenamento do Azure (o arquivo pode ter qualquer formato). |
| Pasta Referenciar uma pasta |
uri_folder |
Leia uma pasta de arquivos parquet/CSV no Pandas/Spark. Leia dados não estruturados (imagens, texto, áudio etc.) localizados em uma pasta. |
| Tabela Referenciar uma tabela de dados |
mltable |
Você tem um esquema complexo sujeito a alterações frequentes ou precisa de um subconjunto de dados tabulares grandes. AutoML com Tabelas. Leia dados não estruturados (imagens, texto, áudio etc.) que estão distribuídos em vários locais de armazenamento. |
Observação
Use apenas novas linhas inseridas em arquivos csv se você registrar os dados como uma MLTable. As novas linhas inseridas em arquivos csv podem causar valores de campo desalinhados quando você lê os dados. O MLTable tem o parâmetro support_multi_line disponível na transformação read_delimited, para interpretar as quebras de linha entre aspas como um registro.
Ao consumir o ativo de dados em um trabalho do Azure Machine Learning, você pode montar ou baixar o ativo para os nós de computação. Para obter mais informações, visite Modos.
Além disso, você deve especificar um parâmetro path que aponte para o local do ativo de dados. Caminhos com suporte incluem:
| Localização | Exemplos |
|---|---|
| Um caminho no computador local | ./home/username/data/my_data |
| Um caminho em um armazenamento de dados | azureml://datastores/<data_store_name>/paths/<path> |
| Um caminho em um servidor https(s) público | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Um caminho no Armazenamento do Azure | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Observação
Quando você cria um ativo de dados de um caminho local, ele é carregado automaticamente no armazenamento de dados na nuvem padrão do Azure Machine Learning.
Criar um ativo de dados: tipo de arquivo
Um ativo de dados de um tipo de arquivo (uri_file) aponta para um único arquivo no armazenamento (por exemplo, um arquivo CSV). Você pode criar um ativo de dados de tipo de arquivo com:
Crie um arquivo YAML e copie e cole o snippet de código a seguir. Certifique-se de atualizar os espaços reservados <> com o
- nome do ativo de dados
- a versão
- descrição
- caminho para um único arquivo em um local com suporte
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Em seguida, execute o seguinte comando na CLI. Certifique-se de atualizar o espaço reservado <filename> com o nome do arquivo YAML.
az ml data create -f <filename>.yml

Criar um ativo de dados: tipo de pasta
Um ativo de dados de tipo Pasta (uri_folder) aponta para uma pasta em um recurso de armazenamento – por exemplo, uma pasta que contém várias subpastas de imagens. Você pode criar um ativo de dados de tipo de pasta com:
Copie e cole o código a seguir em um novo arquivo YAML. Certifique-se de atualizar os espaços reservados <> com o
- Nome do ativo de dados
- A versão
- Descrição
- Caminho para uma pasta em um local com suporte
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Em seguida, execute o seguinte comando na CLI. Certifique-se de atualizar o espaço reservado <filename> com o nome do arquivo YAML.
az ml data create -f <filename>.yml

Criar um ativo de dados: tipo de tabela
As Tabelas do Azure Machine Learning (MLTable) têm funcionalidade avançada, descritas com mais detalhes em Trabalhar com tabelas no Azure Machine Learning. Em vez de repetir essa documentação aqui, leia este exemplo que descreve como criar um ativo de dados de tipo de tabela, com dados do Titanic localizados em uma conta de Armazenamento de Blobs do Azure disponível publicamente.
Primeiro, crie um novo diretório chamado data e crie um arquivo chamado MLTable:
mkdir data
touch MLTable
Em seguida, copie e cole o seguinte YAML no arquivo MLTable que você criou na etapa anterior:
Cuidado
Não renomeie o arquivo MLTable para MLTable.yaml ou MLTable.yml. O Azure Machine Learning espera um arquivo MLTable.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Execute o comando a seguir na CLI. Atualize os espaços reservados <> com os valores de versão e nome do ativo de dados.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Importante
O path deve ser uma pasta que contém um arquivo MLTable válido.
Criando ativos de dados a partir de saídas de trabalho
Você pode criar um ativo de dados de um trabalho do Azure Machine Learning. Para fazer isso, defina o parâmetro name na saída. Neste exemplo, você envia um trabalho que copia dados de um repositório de blobs público para o Datastore do Azure Machine Learning padrão e cria um ativo de dados chamado job_output_titanic_asset.
Crie um arquivo YAML de especificação de trabalho (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Em seguida, envie o trabalho usando a CLI:
az ml job create --file <file-name>.yml
Gerenciar ativos de dados
Excluir um ativo de dados
Importante
Por padrão, não há suporte para a exclusão de ativos de dados.
Se o Azure Machine Learning permitisse a exclusão de ativos de dados, ele teria os seguintes efeitos adversos e negativos:
- Os trabalhos de produção que consomem ativos de dados que foram posteriormente excluídos falharão.
- Seria mais difícil reproduzir um experimento de ML.
- A linhagem do trabalho seria interrompida, porque seria impossível exibir a versão do ativo de dados excluído.
- Você não conseguiria acompanhar e auditar corretamente, pois as versões poderiam estar faltando.
Portanto, a imutabilidade dos ativos de dados oferece um nível de proteção ao trabalhar em uma equipe que cria cargas de trabalho de produção.
Para um ativo de dados criado erroneamente – por exemplo, com um nome, tipo ou caminho incorreto – o Azure Machine Learning oferece soluções para lidar com a situação sem as consequências negativas da exclusão:
| Quero excluir esse ativo de dados porque... | Solução |
|---|---|
| O nome está incorreto | Arquivar o ativo de dados |
| A equipe não usa mais o ativo de dados | Arquivar o ativo de dados |
| Ele está desorganizando a listagem de ativos de dados | Arquivar o ativo de dados |
| O caminho está incorreto | Crie uma nova versão do ativo de dados (mesmo nome) com o caminho correto. Para obter mais informações, visite Criar ativos de dados. |
| Possui um tipo incorreto | No momento, o Azure Machine Learning não permite a criação de uma nova versão com um tipo diferente em comparação com a versão inicial. (1) Arquivar o ativo de dados (2) Criar um novo ativo de dados com um nome diferente e o tipo correto. |
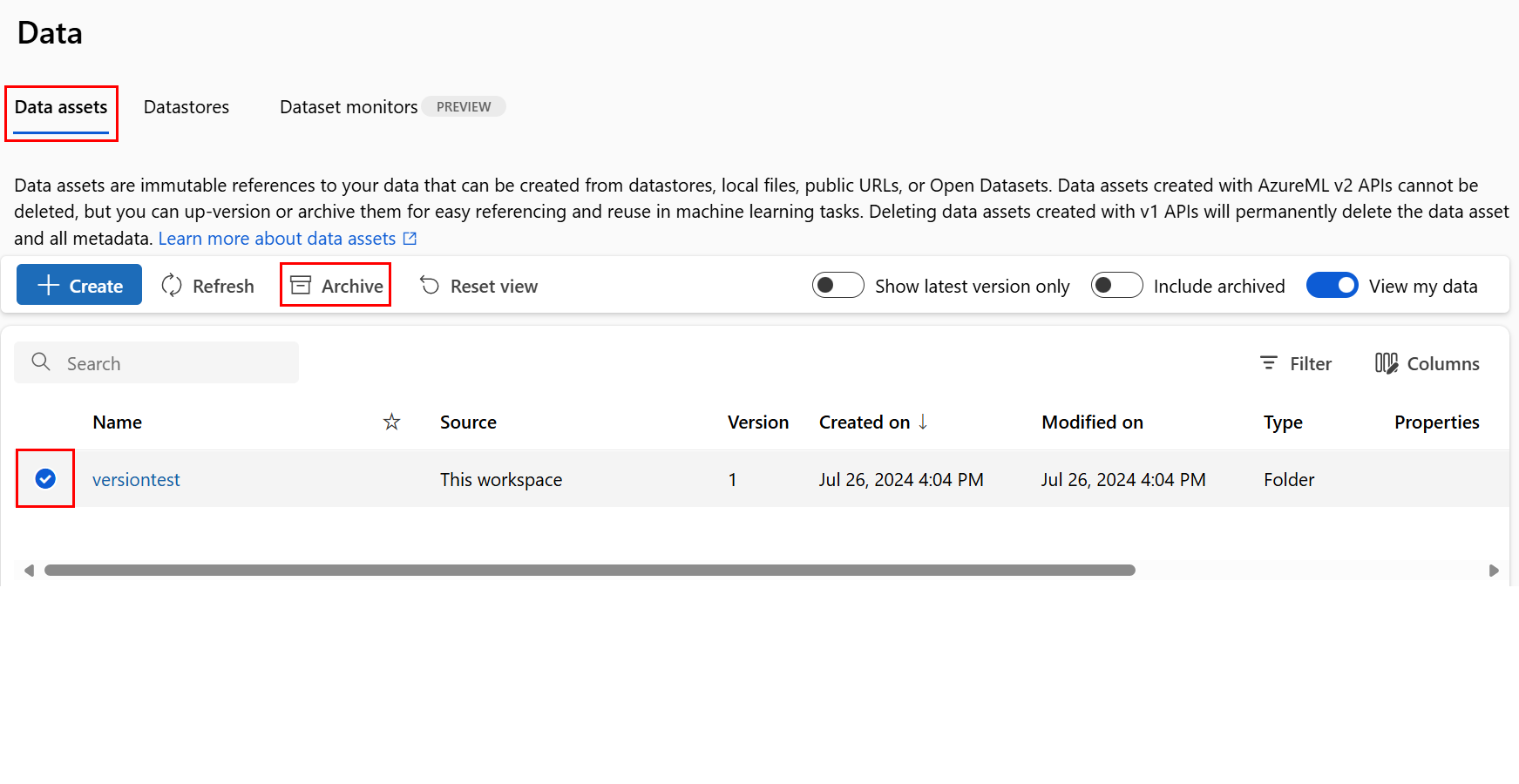
Arquivar um ativo de dados
O arquivamento de um ativo de dados o oculta por padrão das consultas de lista (por exemplo, na CLI az ml data list) e da listagem de ativos de dados na interface do usuário do Estúdio. Você ainda pode continuar a fazer referência e usar um ativo de dados arquivado nos fluxos de trabalho. Você pode arquivar qualquer um deles:
- Todas as versões do ativo de dados em um determinado nome
or
- Uma versão específica do ativo de dados
Arquivar todas as versões de um ativo de dados
Para arquivar todas as versões do ativo de dados com um determinado nome, use:
Execute o comando a seguir. Atualize os espaços reservados <> com as suas informações.
az ml data archive --name <NAME OF DATA ASSET>
Arquivar uma versão específica do ativo de dados
Para arquivar uma versão específica do ativo de dados, use:
Execute o comando a seguir. Atualize os espaços reservados <> com o nome do ativo de dados e a versão.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
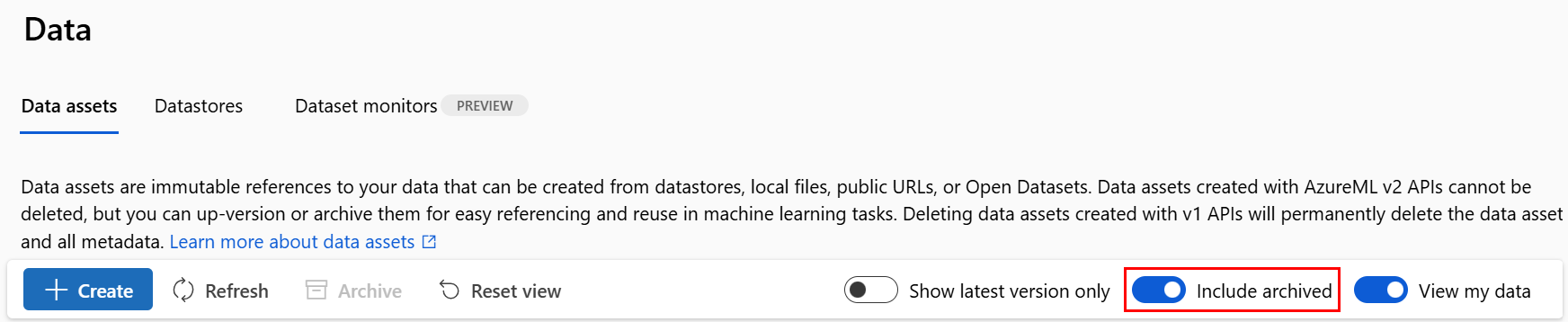
Restaurar um ativo de dados arquivado
Você pode restaurar um ativo de dados arquivado. Se todas as versões do ativo de dados estiverem arquivadas, não será possível restaurar versões individuais do ativo de dados. Você deverá restaurar todas as versões.
Restaurar todas as versões de um ativo de dados
Para restaurar todas as versões do ativo de dados com um determinado nome, use:
Execute o comando a seguir. Atualize os espaços reservados <> com o nome do ativo de dados.
az ml data restore --name <NAME OF DATA ASSET>
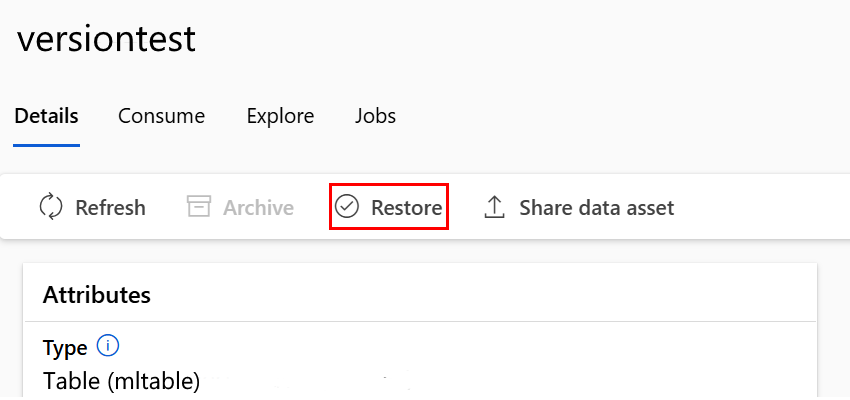
Restaurar uma versão específica do ativo de dados
Importante
Se todas as versões de ativos de dados foram arquivadas, não será possível restaurar versões individuais do ativo de dados. Você deverá restaurar todas as versões.
Para restaurar uma versão específica do ativo de dados, use:
Execute o comando a seguir. Atualize os espaços reservados <> com o nome do ativo de dados e a versão.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Linhagem de dados
A linhagem de dados é amplamente compreendida como o ciclo de vida que abrange a origem dos dados e para onde eles se movem ao longo do tempo no armazenamento. Diferentes tipos de cenários com aparência de versões anteriores o usam, por exemplo
- Solução de problemas
- Causas raiz de rastreamento em pipelines de ML
- Depuração
A análise da qualidade dos dados, a conformidade e cenários hipotéticos também usam linhagem. A linhagem é representada visualmente para mostrar os dados se movendo da origem para o destino e também abrande as transformações de dados. Devido à complexidade da maioria dos ambientes de dados corporativos, essas exibições podem se tornar difíceis de entender sem consolidação ou mascaramento de pontos de dados periféricos.
Em um pipeline do Azure Machine Learning, os ativos de dados mostram a origem dos dados e como os dados foram processados, por exemplo:
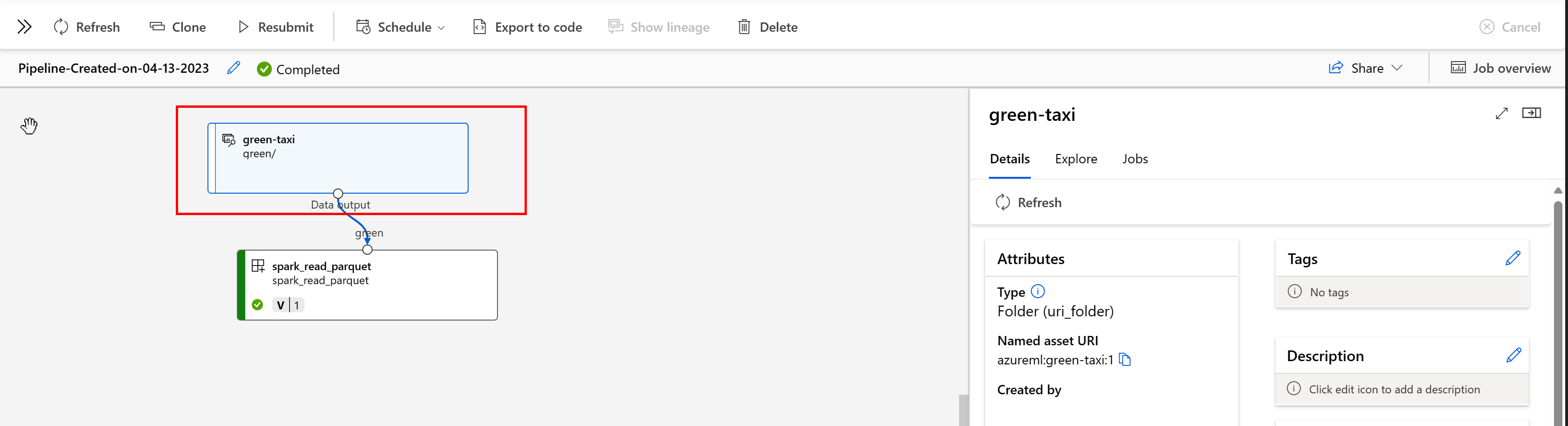
Você pode exibir os trabalhos que consomem o ativo de dados na interface do usuário do Estúdio. Primeiro, selecione Dados no menu à esquerda e, em seguida, selecione o nome do ativo de dados. Observe os trabalhos que consomem o ativo de dados:
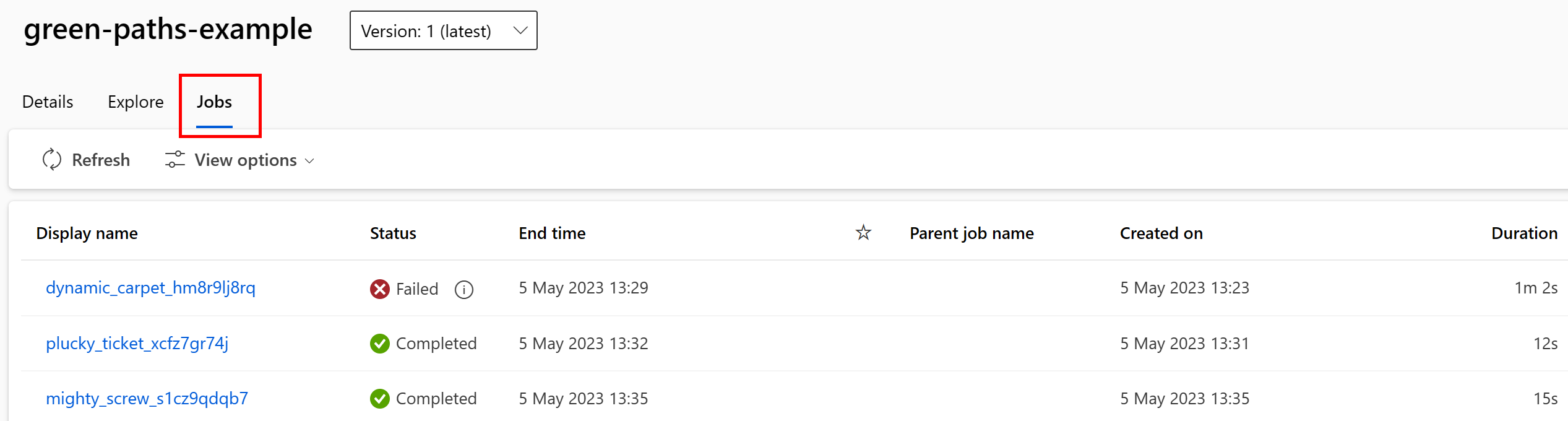
A exibição de trabalhos em ativos de dados facilita a localização de falhas de trabalho e a análise de causa raiz em seus pipelines de ML e depuração.
Marcação de ativos de dados
Os ativos de dados dão suporte à marcação, que consiste em metadados extras aplicados ao ativo de dados como um par chave-valor. A marcação de dados oferece muitos benefícios:
- Descrição da qualidade dos dados. Por exemplo, se a sua organização usa uma arquitetura medallion do Lakehouse, você pode marcar os ativos com
medallion:bronze(bruto),medallion:silver(validado) emedallion:gold(enriquecido). - Pesquisa e filtragem eficientes de dados, para ajudar na descoberta de dados.
- Identificação de dados pessoais confidenciais, para gerenciar e controlar corretamente o acesso a dados. Por exemplo,
sensitivity:PII/sensitivity:nonPII. - Determinação de se os dados são aprovados ou não por uma auditoria de IA (RAI) responsável. Por exemplo,
RAI_audit:approved/RAI_audit:todo.
Você pode adicionar marcas a ativos de dados como parte do fluxo de criação ou pode adicionar marcas a ativos de dados existentes. Esta seção mostra:
Adicionar marcas como parte do fluxo de criação de ativos de dados
Crie um arquivo YAML e copie e cole o código a seguir nesse arquivo YAML. Certifique-se de atualizar os espaços reservados <> com o
- nome do ativo de dados
- a versão
- descrição
- marcas (pares chave-valor)
- caminho para um único arquivo em um local com suporte
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Execute o comando a seguir na CLI. Certifique-se de atualizar o espaço reservado <filename> com o nome do arquivo YAML.
az ml data create -f <filename>.yml
Adicionar marcas a um ativo de dados existente
Execute o comando a seguir na CLI do Azure. Certifique-se de atualizar os espaços reservados <> com o
- Nome do ativo de dados
- A versão
- Par chave-valor para a marca
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Práticas recomendadas de controle de versão
Normalmente, os processos de ETL organizam a estrutura de pastas no armazenamento do Azure por tempo, por exemplo:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
A combinação de pastas estruturadas de tempo/versão e tabelas do Azure Machine Learning (MLTable) permite que você construa conjuntos de dados com versão. Um exemplo hipotético mostra como obter dados com versões com tabelas do Azure Machine Learning. Suponha que você tenha um processo que carrega imagens de câmera no Armazenamento de Blobs do Azure toda semana, nesta estrutura:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Observação
Embora mostremos como fazer controle de versão de dados de imagem (jpeg), a mesma abordagem funciona para qualquer tipo de arquivo (por exemplo, Parquet, CSV).
Com as Tabelas do Azure Machine Learning (mltable), construa uma tabela de caminhos que inclua os dados até o final da primeira semana em 2023. Em seguida, crie um ativo de dados:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
No final da semana seguinte, o ETL atualizou os dados para incluir mais dados:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
A primeira versão (20230108) continua a montar/baixar apenas arquivos de year=2022/week=52 e year=2023/week=1 porque os caminhos são declarados no arquivo MLTable. Isso garante a reprodutibilidade dos seus experimentos. Para criar uma nova versão do ativo de dados que inclua year=2023/week2, use:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Agora você tem duas versões dos dados, em que o nome da versão corresponde à data em que as imagens foram carregadas no armazenamento:
- 20230108: as imagens até 2023-Jan-08.
- 20230115: as imagens até 2023-Jan-15.
Em ambos os casos, o MLTable cria uma tabela de caminhos que inclui apenas as imagens até essas datas.
Em um trabalho do Azure Machine Learning, você pode montar ou baixar esses caminhos na tabela MLTable com versão para seu destino de computação usando os modos eval_download ou eval_mount:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Observação
Os modos eval_mount e eval_download são exclusivos do MLTable. Nesse caso, o recurso de tempo de execução de dados do AzureML avalia o arquivo MLTable e monta os caminhos no destino da computação.