Ciência de Dados usando a Máquina Virtual de Ciência de Dados do Windows.
A DSVM (Máquina Virtual de Ciência de Dados) do Windows é um ambiente de desenvolvimento de ciência de dados incrível, que dá suporte a tarefas de exploração e modelagem de dados. O ambiente vem predefinido e pré-agrupado com várias ferramentas populares de análise de dados que facilitam o início de sua análise para implantações locais, na nuvem ou híbridas.
A DSVM trabalha junto com os serviços do Azure. Ela pode ler e processar dados já armazenados no Azure, no Azure Synapse (anteriormente conhecido como SQL DW), Azure Data Lake, Armazenamento do Azure ou Azure Cosmos DB. Ela também aproveita outras ferramentas de análise, como o Azure Machine Learning.
Neste artigo, você aprenderá a usar sua DSVM para lidar com tarefas de ciência de dados e interagir com outros serviços do Azure. Este é um exemplo de tarefas que a DSVM pode abranger:
- Use um Jupyter Notebook para experimentar com seus dados em um navegador usando Python 2, Python 3 e Microsoft R. (O Microsoft R é uma versão do R pronta para a empresa, criada para alto desempenho.)
- Explorar dados e desenvolver modelos localmente na DSVM usando o Microsoft Machine Learning Server e Python.
- Administrar os recursos do Azure usando o portal do Azure ou o PowerShell.
- Estender o espaço de armazenamento e compartilhar conjuntos de dados/códigos em grande escala com toda sua equipe com um compartilhamento de Arquivos do Azure como uma unidade montável na DSVM.
- Compartilhe o código com sua equipe com o GitHub. Acesse seu repositório com os clientes Git pré-instalados: Git Bash e Git GUI.
- Acesse os serviços de análise e dados do Azure:
- Armazenamento de Blobs do Azure
- Azure Cosmos DB
- Azure Synapse (anteriormente conhecido como SQL DW)
- Banco de Dados SQL do Azure
- Crie relatórios e painéis com a instância do Power BI Desktop, pré-instalado na DSVM, e implante-os na nuvem.
- Instale mais ferramentas na sua máquina virtual.
Observação
Encargos de uso adicionais se aplicam a muitos dos serviços de armazenamento e análise de dados listados neste artigo. Para obter mais informações, acesse a página de preços do Azure.
Pré-requisitos
- Uma assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Uma DSVM provisionada no portal do Azure. Para obter mais informações, visite o recurso Criação de uma máquina virtual.
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Usar o Jupyter Notebooks
O Notebook Jupyter fornece um IDE baseado em navegador para exploração e modelagem de dados. Você pode usar Python 2, Python 3 ou R em um Jupyter Notebook.
Para iniciar o Jupyter Notebook, selecione o ícone Jupyter Notebook no menu Iniciar ou na área de trabalho. No prompt de comando da DSVM, você também pode executar o comando jupyter notebook no diretório que hospeda os notebooks existentes ou onde você quiser criar novos notebooks.
Depois de iniciar o Jupyter, navegue até o diretório /notebooks. Esse diretório hospeda os notebooks de exemplo que são pré-empacotados na DSVM. Você poderá:
- Selecionar o notebook para exibir o código.
- Selecione Shift+Enter para executar cada célula.
- Selecione Célula>Executar para executar todo o notebook.
- Crie um novo notebook, selecione o ícone do Jupyter (canto superior esquerdo), selecione o botão Novo e escolha o idioma do notebook (também conhecido como kernels).
Observação
No momento, há suporte para kernels Python 2.7, Python 3.6, R, Julia e PySpark no Jupyter. O kernel R dá suporte à programação no R de software livre e no Microsoft R. No notebook, você pode explorar seus dados, criar seu modelo e testar esse modelo com sua escolha de bibliotecas.
Explore dados e desenvolva modelos com o Microsoft Machine Learning Server
Observação
O suporte para Machine Learning Server Standalone terminou em 1º de julho de 2021. Nós o removemos das imagens da DSVM depois de 30 de junho de 2021. As implantações existentes ainda podem acessar o software, mas o suporte terminou depois de 1º de julho de 2021.
Você pode usar R e Python para sua análise de dados diretamente na DSVM.
Para R, você pode usar Ferramentas do R para Visual Studio. A Microsoft fornece outras bibliotecas, além do recurso CRAN R de software livre. Essas bibliotecas permitem análises escalonáveis e a capacidade de analisar massas de dados que excedem as limitações de tamanho de memória da análise em partes paralelas.
Para Python, você pode usar um IDE, por exemplo, o Visual Studio Community Edition, que tem a extensão PTVS (Ferramentas Python para Visual Studio) pré-instalada. Por padrão, somente o Python 3.6, o ambiente do Conda raiz, é configurado em PTVS. Para habilitar o Anaconda Python 2.7:
- Crie ambientes personalizados para cada versão. Selecione Ferramentas>Ferramentas do Python>Ambientes do Python e, em seguida, selecione + Personalizado no Visual Studio Community Edition.
- Forneça uma descrição e defina o caminho de prefixo do ambiente como c:\anaconda\envs\python2 para o Anaconda Python 2.7.
- Selecione Detecção Automática>Aplicar para salvar o ambiente.
Visite o recurso Documentação de PTVS para obter mais informações sobre como criar ambientes do Python.
Agora você pode criar um novo projeto do Python. Selecione Arquivo>Novo>Projeto>Python e selecione o tipo de aplicativo Python que você deseja compilar. Você pode definir o ambiente do Python para o projeto atual na versão desejada (Python 2.7 ou 3.6) clicando com o botão direito do mouse em Ambientes Python, e, em seguida, selecionando Adicionar/Remover Ambientes Python. Visite a documentação do produto para obter mais informações sobre como trabalhar com PTVS.
Gerenciar recursos do Azure
A DSVM permite compilar a solução de análise localmente na máquina virtual. Ela também permite que você acesse serviços na plataforma de nuvem do Azure. O Azure fornece vários serviços, inclusive computação, armazenamento, análise de dados e muitos outros serviços que você pode administrar e acessar na DSVM.
Você tem duas opções disponíveis para administrar seus recursos de nuvem e sua assinatura do Azure:
Visite o portal do Azure no seu navegador.
Use os scripts do PowerShell. Execute o Azure PowerShell em um atalho na área de trabalho ou no menu Iniciar. Visite o recurso Documentação do Microsoft Azure PowerShell para obter mais informações.
Amplie o armazenamento usando sistemas de arquivos compartilhados
Os cientistas de dados podem compartilhar grandes conjuntos de dados, códigos ou outros recursos dentro da equipe. A DSVM tem cerca de 45 GB de espaço disponível. Para aumentar o armazenamento, você pode usar os Arquivos do Azure e montá-los em uma ou mais instâncias da DSVM ou acessá-los com uma API REST. Você também pode usar portal do Azure ou usar o Azure PowerShell para adicionar discos de dados extras dedicados.
Observação
O espaço máximo em um compartilhamento de Arquivos do Azure é de 5 TB. Cada arquivo tem um limite de tamanho de 1 TB.
Esse script do Azure PowerShell cria um compartilhamento de Arquivos do Azure:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Você pode montar um compartilhamento de Arquivos do Azure em qualquer máquina virtual no Azure. Sugerimos que você coloque a VM e a conta de armazenamento no mesmo data center do Azure, para evitar encargos de latência e transferência de dados. Esses comandos do Azure PowerShell montam a unidade na DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Você pode acessar essa unidade como faria com qualquer unidade normal na VM.
Compartilhe o código no GitHub
O repositório de código do GitHub hospeda exemplos de código e fontes de código para muitas ferramentas compartilhadas pela comunidade de desenvolvedores. Ele usa Git como a tecnologia para rastrear e armazenar versões dos arquivos de código. O GitHub também atua como uma plataforma para criar seu próprio repositório. Seu próprio repositório pode armazenar o código compartilhado e a documentação da sua equipe, implementar o controle de versão e controlar as permissões de acesso para os stakeholders que desejam exibir e contribuir com o código. O GitHub dá suporte à colaboração na sua equipe, ao uso de código desenvolvido pela comunidade e às contribuições do código para a comunidade. Visite as páginas de ajuda do GitHub para obter mais informações sobre como o Git.
A DSVM vem carregada com ferramentas cliente na linha de comando e na GUI para acessar o repositório do GitHub. A ferramenta de linha de comando do Git Bash opera com o Git e o GitHub. O Visual Studio está instalado na DSVM e tem as extensões de Git. O menu Iniciar e a área de trabalho têm ícones para essas ferramentas.
Use o comando git clone para baixar o código de um repositório GitHub. Para baixar o repositório de ciência de dados publicado pela Microsoft no diretório atual, por exemplo, execute este comando no Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
O Visual Studio pode lidar com a mesma operação de clone. Esta captura de tela mostra como acessar as ferramentas Git e GitHub no Visual Studio:

Você pode trabalhar com os recursos de github.com disponíveis no seu repositório GitHub. Para obter mais informações, visite o recurso Folha de referências do GitHub.
Acessar serviços de análise e dados do Azure
Armazenamento de Blobs do Azure
O armazenamento de Blob do Azure é um serviço de armazenamento em nuvem confiável e econômico para recursos de pequenos e grandes volumes de dados. Essa seção descreve como mover os dados para o armazenamento de Blob e acessar os dados armazenados em um blob do Azure.
Pré-requisitos
Uma conta de armazenamento de Blobs do Azure, criada no portal do Azure.

Confirme se a ferramenta de linha de comando AzCopy foi pré-instalada, com este comando:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeO diretório que hospeda o azcopy.exe já está na sua variável de ambiente PATH para evitar ter que digitar o caminho completo do comando ao executar essa ferramenta. Para obter mais informações sobre a ferramenta AzCopy, leia a documentação do AzCopy.
Inicie o Gerenciador de Armazenamento do Azure. Ele pode ser baixado na página da Web do Gerenciador de Armazenamento.


Mover dados da VM para o blob do Azure: AzCopy
Para mover dados entre seus arquivos locais e o armazenamento de Blob, você pode usar AzCopy na linha de comando ou no PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Substituir C:\myfolder pelo caminho do diretório que hospeda seu arquivo
- Substituir mystorageaccount pelo nome da sua conta de armazenamento de Blobs
- Substituir mycontainer pelo nome do contêiner
- Substituir a chave da conta de armazenamento pela chave de acesso do Armazenamento de Blobs
Você pode encontrar as credenciais da conta de armazenamento no portal do Azure.
Execute o comando AzCopy no PowerShell ou em um prompt de comando. Estes são exemplos de comando do AzCopy:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Depois de executar o comando AzCopy para copiar o arquivo para um blob do Azure, seu arquivo aparecerá no Gerenciador de Armazenamento do Azure.

Mover dados da VM para o blob do Azure: Gerenciador de Armazenamento do Azure
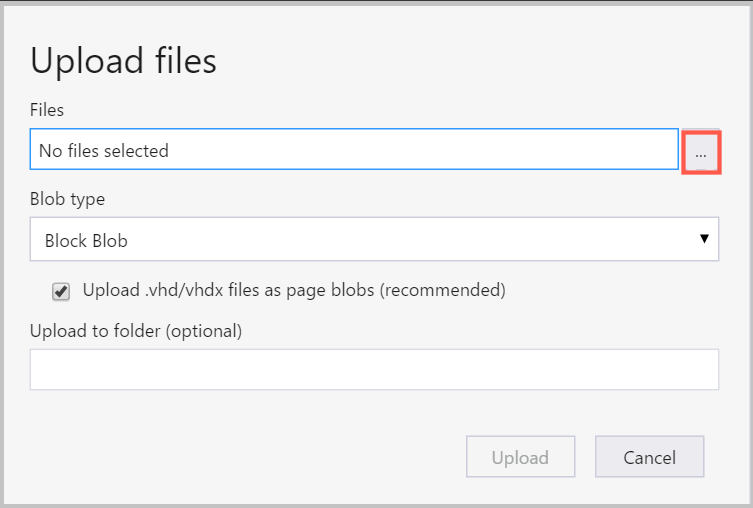
Você também pode carregar dados do arquivo local na VM com o Gerenciador de Armazenamento do Azure:
Para carregar dados em um contêiner, selecione o contêiner de destino e selecione o botão Carregar.

À direita da caixa Arquivos, selecione as reticências (...), selecione um ou vários arquivos para carregar no sistema de arquivos e selecione Carregar para começar a carregar os arquivos.


Ler dados do blob do Azure: ODBC do Python
A biblioteca do BlobService pode ler dados diretamente do blob em um Jupyter Notebook ou em um programa Python. Primeiro, importe os pacotes necessários:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Conecte suas credenciais da conta de armazenamento do Blob e leia os dados no blob:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Os dados são lidos como em um quadro de dados:

Azure Synapse Analytics e banco de dados
O Azure Synapse Analytics é um "warehouse como serviço" de dados elásticos, com uma experiência em SQL Server de nível corporativo. Este recurso descreve como provisionar o Azure Synapse Analytics. Após provisionar o Azure Synapse Analytics, este passo a passo explica como carregar, explorar e modelar dados usando os dados do Azure Synapse Analytics.
Azure Cosmos DB
O Azure Cosmos DB é um banco de dados NoSQL na nuvem. Ele pode identificar documentos JSON, por exemplo, e pode armazenar e consultar os documentos. Estas etapas de exemplo mostram como acessar o Azure Cosmos DB por meio da DSVM:
O SDK de Python do Azure Cosmos DB já está instalado no DSVM. Para atualizá-lo, execute
pip install pydocumentdb --upgradea partir de um prompt de comando.Criar uma conta do Azure Cosmos DB e um banco de dados no Portal do Azure.
Baixe a Ferramenta de Migração de Dados do Cosmos DB do Azure do Centro de Download da Microsoft e a extraia para um diretório de sua escolha.
Importe os dados JSON (dados do vulcão) armazenados em um blob público para o Azure Cosmos DB com os seguintes parâmetros de comando para a ferramenta de migração. (Use dtui.exe no diretório em que você instalou a Ferramenta de Migração de Dados do Azure Cosmos DB.) Insira o local de origem e destino com estes parâmetros:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Depois de importar os dados, você pode acessar o Jupyter e abrir o notebook denominado DocumentDBSample. Ele contém o código Python para acessar o Azure Cosmos DB e lidar com algumas consultas básicas. Visite a página de documentação do serviço do Azure Cosmos DB para obter mais informações sobre o Azure Cosmos DB.
Use relatórios e dashboards do Power BI
Você pode visualizar o arquivo JSON do Volcano descrito no exemplo anterior do Azure Cosmos DB no Power BI Desktop para obter insights visuais sobre os dados em si. Este artigo do Power BI oferece etapas detalhadas. Estas são as etapas em um alto nível:
- Abra o Power BI Desktop e selecione Obter dados. Especifique este URL:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Os registros JSON, importados como uma lista, devem ficar visíveis. Converta a lista em uma tabela para que o Power BI possa trabalhar com ela.
- Selecione o ícone de expansão (seta) para expandir as colunas.
- O local é um campo Registro. Expanda o registro e selecione apenas as coordenadas. A Coordenada é uma coluna de lista.
- Adicione uma nova coluna para converter a coluna de coordenadas da lista em uma coluna LatLong separada por vírgulas. Use a fórmula
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})para concatenar os dois elementos no campo lista de coordenadas. - Converta a coluna Elevação em decimal e selecione os botões Fechar e Aplicar.
Você pode usar o código a seguir como uma alternativa às etapas anteriores. Ele cria o script com base nas etapas usadas no Editor Avançado no Power BI para escrever as transformações de dados em uma linguagem de consulta:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Agora você tem os dados no modelo de dados do Power BI. A instância da Área de Trabalho do Power BI deve aparecer da seguinte maneira:

É possível iniciar a criação de relatórios e as visualizações com o modelo de dados. Este artigo do Power BI explica como criar um relatório.
Ajustar a escala da DSVM dinamicamente
Você pode ajustar escala na DSVM para cima e para baixo para atender às necessidades do seu projeto. Se você não precisar usar a VM à noite ou nos fins de semana, desligue-a no portal do Azure.
Observação
Você incorrerá em cobranças de computação se usar apenas o botão de desligamento do sistema operacional na VM. Em vez disso, você deve desalocar sua DSVM usando o portal do Azure ou Cloud Shell.
Para um projeto de análise em grande escala, talvez seja necessário ter mais capacidade de CPU, memória ou disco. Nesse caso, você pode encontrar VMs de diferentes números de núcleos de CPU, capacidade de memória, tipos de disco (inclusive unidades de estado sólido) e instâncias baseadas em GPU para aprendizado profundo que atendam às suas necessidades de computação e orçamento. A página de preços das Máquinas Virtuais do Azure mostra a lista completa de VMs e os preços de computação por hora.
Adicionar mais ferramentas
A DSVM oferece ferramentas predefinidas que podem atender a muitas necessidades comuns de análise de dados. Elas economizam tempo porque você não precisa instalar e configurar individualmente os ambientes. Elas também economizam dinheiro, pois você paga apenas pelos recursos que usa.
Utilize outros serviços de análise e dados do Azure listados neste artigo para aprimorar seu ambiente de análise. Em alguns casos, você pode precisar de outras ferramentas, incluindo ferramentas patenteadas de parceiros específicas. Você tem acesso administrativo completo na máquina virtual para instalar as ferramentas necessárias. Você também pode instalar outros pacotes em Python e R que não estão pré-instalados. Para Python, você pode usar conda ou pip. Para R, você pode usar o install.packages() no console do R ou usar o IDE e selecionar Pacotes>Instalar Pacotes.
Aprendizado
Além dos exemplos baseados na estrutura, você também pode obter um conjunto de orientações passo a passo abrangentes que foram validados na DSVM. Essas orientações passo a passo ajudam a iniciar o desenvolvimento de aplicativos de aprendizado profundo em domínios de análise de imagem e texto/linguagem.
Executando redes neurais em estruturas diferentes: este passo a passo mostra como migrar o código de uma estrutura para outra. Ele também mostra como comparar modelos e o desempenho do runtime entre estruturas.
Um guia de instruções para criar uma solução de ponta a ponta para detectar produtos em imagens: a técnica de detecção de imagem pode localizar e classificar objetos dentro de imagens. Essa tecnologia tem o potencial de trazer grande recompensa em vários domínios de negócios da vida real. Por exemplo, os varejistas podem usar essa técnica para identificar um produto que um cliente pegou na prateleira. Essas informações ajudam as lojas de varejo a gerenciar o estoque do produtos.
Aprendizado profundo para áudio: Este tutorial mostra como treinar um modelo de aprendizado profundo para detecção de eventos no conjunto de dados de sons urbanos. Ele também fornece uma visão geral de como trabalhar com dados de áudio.
Classificação de documentos de texto: esse passo a passo demonstra como compilar e treinar duas arquiteturas de redes neurais: Rede de Atenção Hierárquica e rede LSTM (Memória Longa de Curto Prazo). Essas redes neurais usam a API Keras para aprendizagem profunda para classificar documentos de texto.
Resumo
Este artigo descreveu algumas das coisas que você pode fazer na Máquina Virtual de Ciência de Dados da Microsoft. Há muito mais coisas que você fazer para tornar o DSVM um ambiente eficaz de análise.