Inferência e avaliação de modelos de previsão
Este artigo apresenta conceitos relacionados à inferência e à avaliação do modelo em tarefas de previsão. Para obter instruções e exemplos sobre como treinar modelos de previsão no AutoML, consulte Configurar o AutoML para treinar um modelo de previsão de série temporal com SDK e CLI.
Depois de usar o AutoML para treinar e selecionar o melhor modelo, a próxima etapa é gerar previsões. Em seguida, se possível, avalie a precisão das previsões em um conjunto de teste separado dos dados de treinamento. Para ver como configurar e executar a avaliação do modelo de previsão no machine learning automatizado, confira Orquestração de treinamento, inferência e avaliação.
Cenários de inferência
No aprendizado de máquina, a inferência é o processo de geração de previsões de modelo para novos dados não usados no treinamento. Há várias maneiras de gerar previsões devido ao fato de os dados dependerem do tempo. O cenário mais simples é quando o período de inferência segue imediatamente o período de treinamento e você gera previsões até o horizonte de previsão. O diagrama a seguir ilustra este cenário:
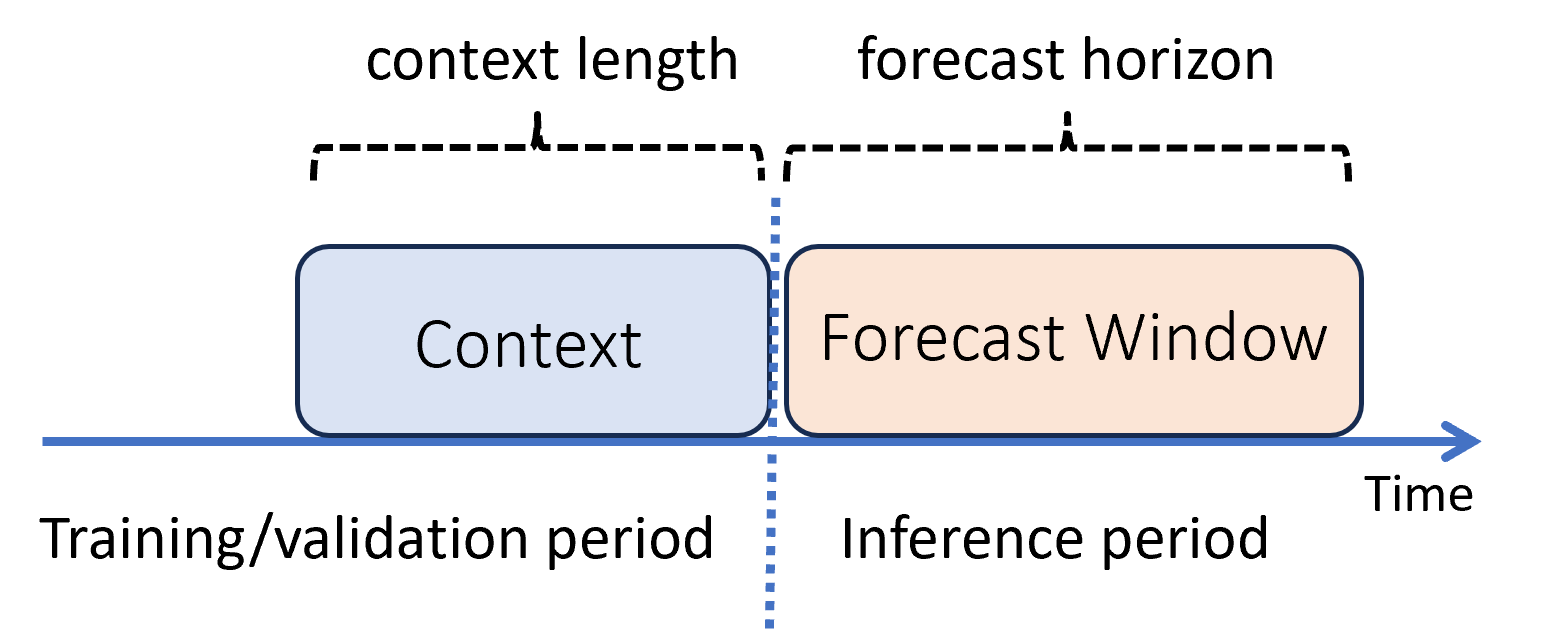
O diagrama mostra dois parâmetros de inferência importantes:
- O comprimento do contexto é a quantidade de histórico que o modelo requer para fazer uma previsão.
- O horizonte de previsão é a distância temporal para a qual o modelo de previsão é treinado para fazer previsões.
Os modelos de previsão geralmente usam algumas informações históricas e o contexto para fazer previsões com antecedência até o horizonte de previsão. Quando o contexto faz parte dos dados de treinamento, o AutoML salva o que precisa para fazer as previsões. Não há necessidade de fornecê-lo explicitamente.
Há dois outros cenários de inferência que são mais complicados:
- Gerar previsões mais para o futuro do que o horizonte de previsão
- Obter previsões quando há uma lacuna entre os períodos de treinamento e inferência
As subseções a seguir analisam esses casos.
Prever além do horizonte de previsão: previsão recursiva
Quando você precisa de previsões além do horizonte, o AutoML aplica o modelo recursivamente durante o período de inferência. As previsões do modelo são realimentadas como entrada para gerar previsões para janelas de previsão subsequentes. O diagrama a seguir mostra um exemplo simples:
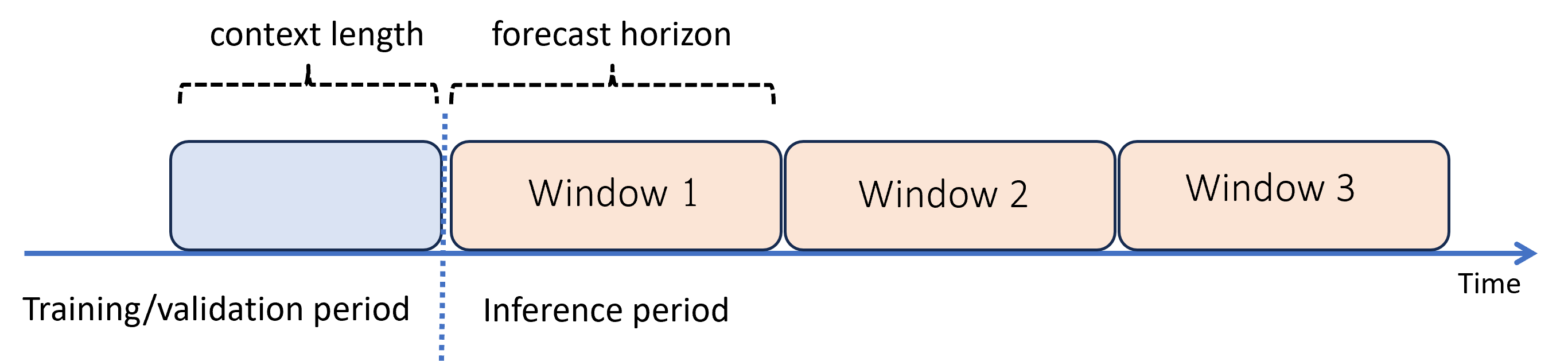
Aqui, o aprendizado de máquina gera previsões para um período três vezes o comprimento do horizonte de previsão. Ele usa previsões de uma janela como o contexto para a próxima janela.
Aviso
A previsão recursiva acumula erros de modelagem. As previsões se tornam menos precisas quanto mais distantes estão do horizonte de previsão original. Você pode encontrar um modelo mais preciso ao treinar novamente com um horizonte mais longo.
Prever com uma lacuna entre períodos de treinamento e inferência
Suponha que, após treinar um modelo, você queira usá-lo para fazer previsões com base em novas observações que não estavam disponíveis durante o treinamento. Nesse caso, há uma diferença de tempo entre os períodos de treinamento e inferência:
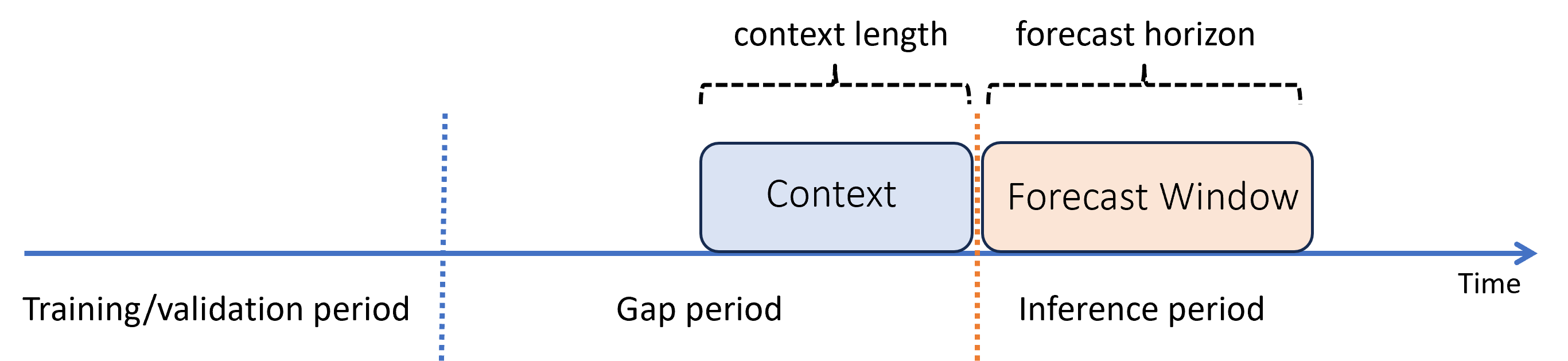
O AutoML dá suporte a esse cenário de inferência, mas você precisa fornecer os dados de contexto no período de lacuna, conforme mostrado no diagrama. Os dados de previsão passados para o componente de inferência precisam de valores para recursos e valores de destino observados na lacuna e valores ausentes ou valores NaN para o destino no período de inferência. A tabela a seguir mostra um exemplo desse padrão:
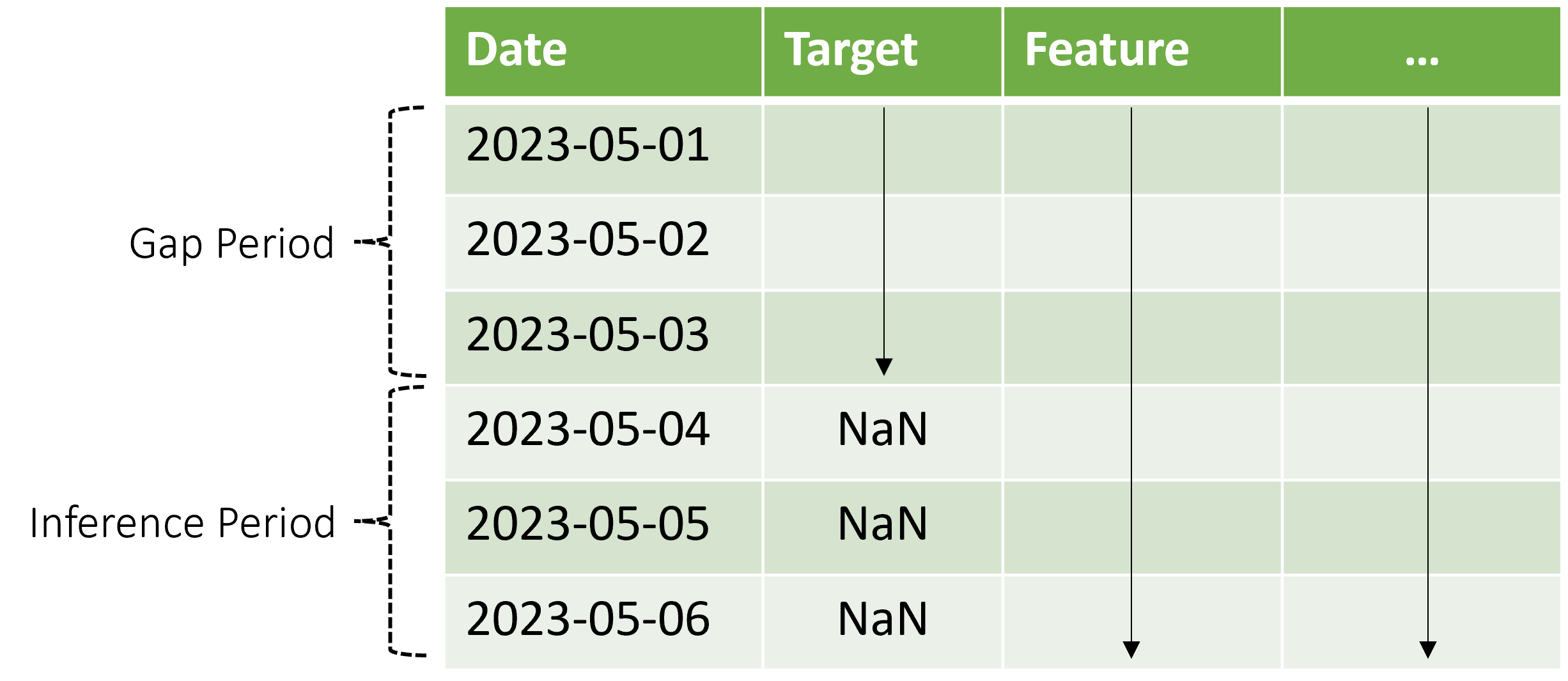
Os valores conhecidos do destino e dos recursos são fornecidos para o período de 2023-05-01 a 2023-05-03. Valores de destino ausentes a partir de 2023-05-04 indicam que o período de inferência começa nessa data.
O AutoML usa os novos dados de contexto para atualizar o retardo e outros recursos de pesquisa e também para atualizar modelos como o ARIMA, que mantêm um estado interno. Essa operação não atualiza nem reajusta os parâmetros do modelo.
Avaliação de modelos
A avaliação é o processo de gerar previsões em um conjunto de testes separado dos dados de treinamento e calcular métricas dessas previsões que orientam as decisões de implantação do modelo. Dessa forma, há um modo de inferência adequado para a avaliação do modelo: uma previsão contínua.
Um procedimento de melhor prática para avaliação de um modelo de previsão é encaminhar o forecaster treinado no tempo ao longo do conjunto de testes, calculando as médias das métricas de erro em várias janelas de previsão. Às vezes, esse procedimento é chamado de backtest. O ideal é que o conjunto de testes para a avaliação seja longo em relação ao horizonte de previsão do modelo. Caso contrário, as estimativas de erro de previsão podem apresentar ruído estatístico e, portanto, ser menos confiáveis.
O diagrama a seguir mostra um exemplo simples com três janelas de previsão:
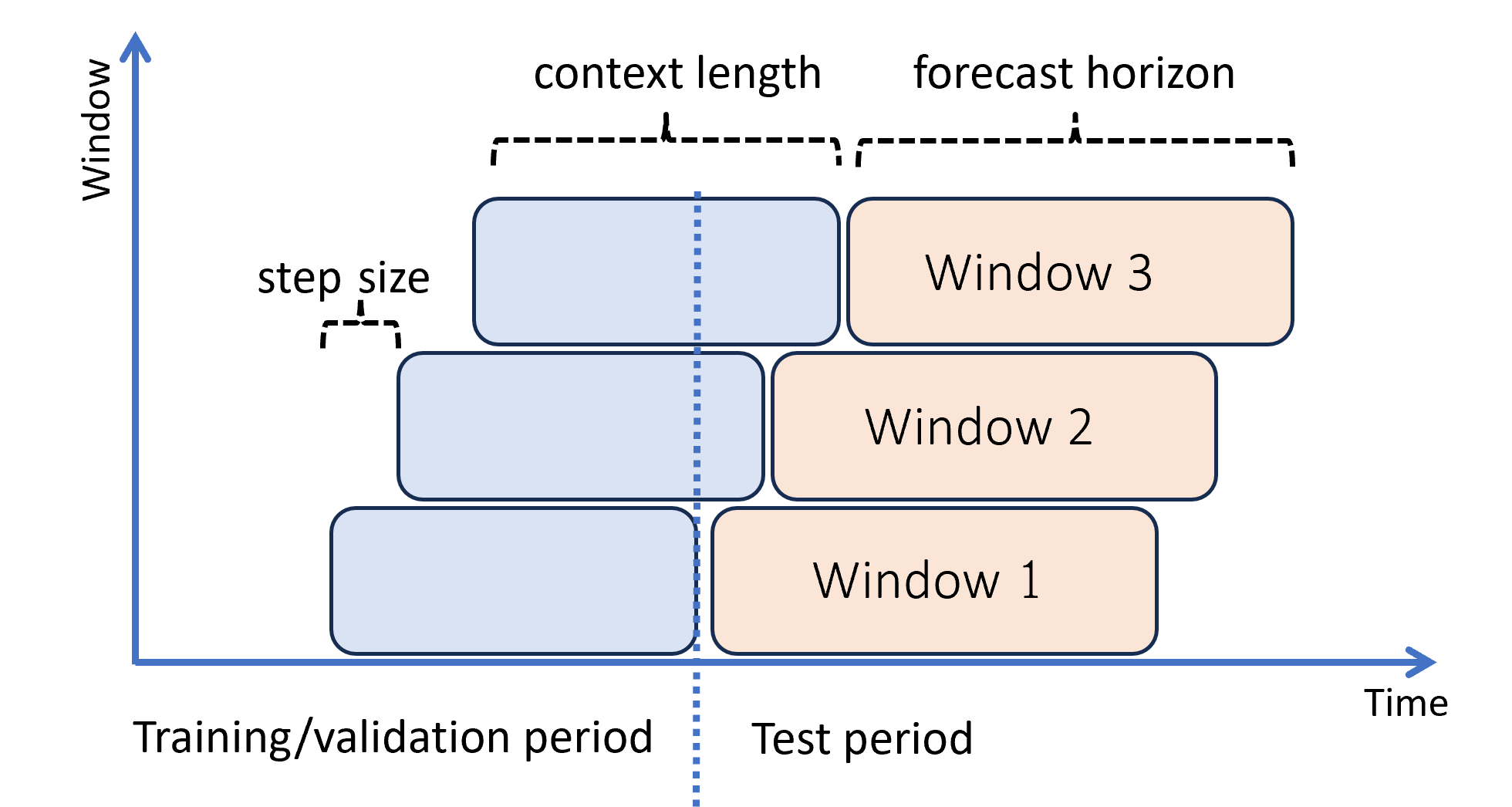
O diagrama ilustra três parâmetros de avaliação sem interrupção:
- O comprimento do contexto é a quantidade de histórico que o modelo requer para fazer uma previsão.
- O horizonte de previsão é a distância temporal para a qual o modelo de previsão é treinado para fazer previsões.
- O passo é a distância temporal que a janela móvel avança em cada iteração no conjunto de teste.
O contexto avança junto com a janela de previsão. Os valores reais do conjunto de testes são usados para fazer previsões quando eles se enquadram na janela de contexto atual. A data mais recente dos valores reais usados para uma determinada janela de previsão é chamada de hora de origem da janela. A tabela a seguir mostra um exemplo de saída da previsão sem interrupção de três janelas com um horizonte de três dias e um tamanho de etapa de um dia:
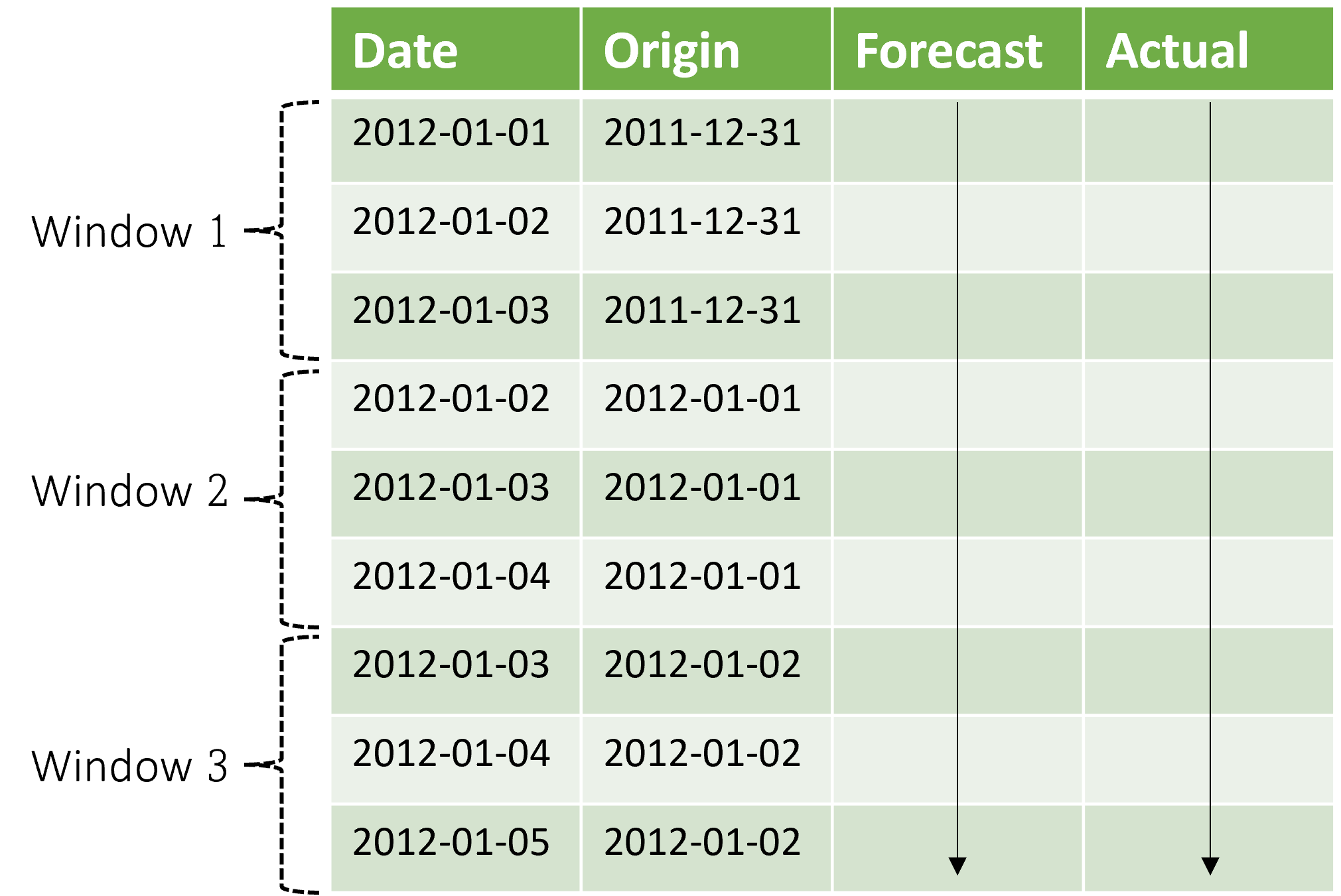
Com uma tabela como essa, é possível visualizar as previsões versus as métricas reais e de avaliação desejadas de computação. Os pipelines de AutoML podem gerar previsões sem interrupção em um conjunto de testes com um componente de inferência.
Observação
Quando o período de teste tem o mesmo comprimento que o horizonte de previsão, uma previsão sem interrupção fornece uma única janela de previsões até o horizonte.
Métricas da avaliação
O cenário de negócios específico geralmente determina a escolha do resumo de avaliação ou métrica. Algumas opções comuns incluem os seguintes exemplos:
- Gráficos dos valores reais observados versus os valores previstos para verificar se o modelo captura certas dinâmicas dos dados
- Erro percentual absoluto médio (MAPE) entre valores reais e previstos
- Raiz do erro quadrático médio (RMSE), possivelmente com uma normalização, entre valores reais e previstos
- Erro absoluto médio (MAE), possivelmente com uma normalização, entre valores reais e previstos
Há muitas outras possibilidades, dependendo do cenário de negócios. Talvez seja necessário criar seus próprios utilitários pós-processamento para calcular métricas de avaliação de resultados de inferência ou previsões contínuas. Para obter mais informações sobre métricas, consulte Regressão/previsão de métricas.
Conteúdo relacionado
- Saiba mais sobre como configurar o AutoML para treinar um modelo de previsão de série temporal.
- Saiba mais sobre como o AutoML usa o aprendizado de máquina para compilar modelos de previsão.
- Leia respostas para perguntas frequentes sobre previsão no AutoML.