Criar APIs personalizadas que podem ser chamadas dos Aplicativos Lógicos do Azure
Aplica-se a: Aplicativos Lógicos do Azure (Consumo)
Embora os Aplicativos Lógicos do Azure ofereçam mais de 1.400 conectores que você pode usar em fluxos de trabalho de aplicativo lógico, talvez você queira chamar APIs, sistemas e serviços que não estão disponíveis como conectores. Você pode criar suas próprias APIs que fornecem ações e gatilhos para uso em fluxos de trabalho. Veja outros motivos para criar suas próprias APIs que você pode chamar de fluxos de trabalhos:
- Estender os fluxos de trabalho de integração de dados e integração do sistema.
- Ajudar os clientes a usar seu serviço para gerenciar tarefas profissionais ou pessoais.
- Expandir o alcance, a descoberta e o uso do seu serviço.
Basicamente, os conectores são APIs da web que usam REST para interfaces plugáveis, formatos de metadados da OpenAPI para documentação e JSON como seu formato de troca de dados. Como os conectores são APIs REST que se comunicam por meio de pontos de extremidade HTTP, você pode usar qualquer linguagem, como .NET, Java, Python ou Node.js, para criar conectores. Você também pode hospedar suas APIs no Serviço de Aplicativo do Azure, uma oferta de PaaS (plataforma como serviço) que fornece uma das maneiras mais fáceis, mais escaláveis e melhores de hospedar a API.
Para que as APIs personalizadas funcionem com o fluxo de trabalho de aplicativos lógicos, sua API pode fornecer ações que executam tarefas específicas em fluxos de trabalho de tarefas específicas. Sua API também pode atuar como um gatilho que inicia um fluxo de trabalho quando novos dados ou um evento atendem a uma condição especificada. Este tópico descreve padrões comuns que você pode seguir para criar ações e gatilhos em sua API, com base no comportamento que a API deve fornecer.
Você pode hospedar suas APIs no Serviço de Aplicativo do Azure, uma oferta de PaaS (plataforma como serviço) que fornece uma hospedagem de API fácil e altamente escalonável.
Dica
Embora você possa implantar suas APIs como aplicativos Web, considere implantar suas APIs como aplicativos de API, o que pode facilitar o trabalho quando você criar, hospedar e consumir APIs locais e na nuvem. Você não precisa alterar o código em suas APIs; basta implantar seu código para um aplicativo de API. Por exemplo, saiba como criar aplicativos de API criados com estas linguagens:
Como as APIs personalizadas diferem dos conectores personalizados?
APIs personalizadas e conectores personalizados são APIs da web que usam REST para interfaces plugáveis, formatos de metadados da OpenAPI para documentação e JSON como seu formato de troca de dados. E como essas APIs e conectores são APIs REST que se comunicam por meio de pontos de extremidade HTTP, você pode usar qualquer linguagem, como .NET, Java, Python ou Node.js, para criar APIs e conectores personalizados.
APIs personalizadas permitem que você chame APIs que não são conectores e forneça pontos de extremidade que você pode chamar com HTTP + Swagger, Gerenciamento de API do Azure ou Serviços de Aplicativos. Conectores personalizados funcionam como APIs personalizadas, mas também têm estes atributos:
- Registrados como recursos do Conector de aplicativos lógicos no Azure.
- Aparecem com ícones ao lado de conectores gerenciados pela Microsoft no Designer de Aplicativos Lógicos.
- Disponível somente para usuários de recursos de aplicativos lógicos e de autores de conectores que têm o mesmo locatário do Microsoft Entra e a assinatura do Azure na região em que os aplicativos lógicos são implantados.
Você também pode nominar conectores registrados para certificação da Microsoft. Esse processo verifica se os conectores registrados atendem aos critérios para uso público e disponibiliza os conectores para usuários no Power Automate e no Microsoft Power Apps.
Para obter mais informações, examine a seguinte documentação:
- Visão geral dos conectores personalizados
- Criar conectores personalizados de APIs Web
- Registrar conectores personalizados em Aplicativos Lógicos do Azure
Ferramentas úteis
Uma API personalizada funciona melhor com aplicativos lógicos quando a API também tem um documento da OpenAPI que descreva as operações e parâmetros da API. Muitas bibliotecas, como a Swashbuckle, podem gerar o swagger para você automaticamente. Para anotar nomes de exibição, tipos de propriedade e outros no arquivo do Swagger, você também pode usar TRex para que o arquivo Swagger funcione bem com aplicativos lógicos.
Padrões de ação
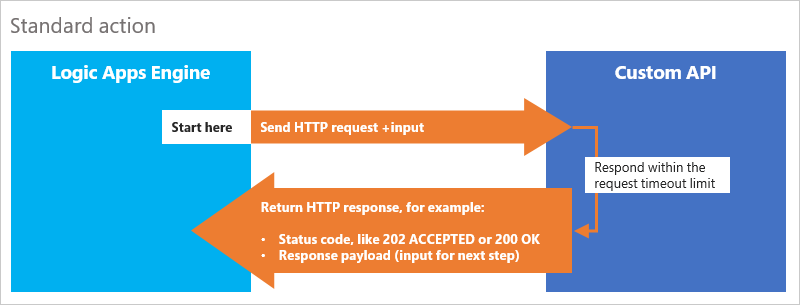
Para que os aplicativos de lógica executem tarefas, sua API personalizada deve fornecer ações. Cada operação em sua API é mapeada para uma ação. Uma ação básica é um controlador que aceita solicitações de HTTP e retorna respostas HTTP. Por exemplo, um fluxo de trabalho envia uma solicitação HTTP para o aplicativo Web ou aplicativo de API. Seu aplicativo, em seguida, retorna uma resposta HTTP, juntamente com conteúdo que pode ser processado pelo fluxo de trabalho.
Para uma ação padrão, você pode escrever um método de solicitação HTTP em sua API e descrever esse método em um arquivo do Swagger. Em seguida, você pode chamar sua API diretamente com uma ação HTTP ou uma ação HTTP + Swagger. Por padrão, as respostas devem ser devolvidas dentro do tempo limite da solicitação.
Para fazer com que um fluxo de trabalho aguarde enquanto sua API conclui tarefas de execução mais longas, sua API pode seguir o padrão de sondagem assíncrono ou o padrão webhook assíncrono descrito neste tópico. Em uma analogia que ajuda você a visualizar os comportamentos diferentes desses padrões, imagine o processo de fazer um bolo personalizado em uma padaria. O padrão de sondagem reflete o comportamento em que você liga para a padaria a cada 20 minutos a fim de verificar se o bolo está pronto. O padrão de webhook reflete o comportamento em que a padaria solicita seu número de telefone para que eles possam ligar quando o bolo estiver pronto.
Executar tarefas de longa execução com o padrão de ação de sondagem
Para fazer sua API executar tarefas que podem levar mais tempo que o tempo limite de solicitação, você pode usar o padrão de sondagem assíncrono. Esse padrão faz sua API trabalhar em um thread separado, mas mantém uma conexão ativa com o mecanismo dos Aplicativos Lógicos do Azure. Dessa forma, o fluxo de trabalho não atinge o tempo limite ou continua na próxima etapa do fluxo de trabalho antes da API concluir o trabalho.
Este é o padrão geral:
- Verificar se o mecanismo sabe que a sua API aceitou a solicitação e começou a trabalhar.
- Quando o mecanismo faz solicitações subsequentes sobre o status do trabalho, informar ao mecanismo quando a API concluir a tarefa.
- Retornar dados relevantes para o mecanismo de forma que o fluxo de trabalho possa continuar.
Agora, aplique a analogia anterior da padaria ao padrão de pesquisa e imagine que você ligou para um padaria e pediu a entrega de um bolo personalizado. O processo para fazer o bolo leva tempo, e você não quer esperar no telefone enquanto a padaria está fazendo o bolo. A padaria confirma seu pedido e faz com que você ligue a cada 20 minutos para saber o status do bolo. Depois de 20 minutos, você liga para a padaria, mas eles indicam que o bolo não está pronto e que você deve ligar novamente daqui a 20 minutos. Esse processo bidirecional continua até que você ligue e a padaria informe que o seu pedido está pronto e entregue o bolo.
Vamos mapear esse padrão de pesquisa novamente. A padaria representa sua API personalizada, enquanto você, o cliente do bolo, representa o mecanismo dos Aplicativos Lógicos do Azure. Quando o mecanismo chama sua API com uma solicitação, a API confirma a solicitação e responde com o intervalo de tempo após o qual o mecanismo pode verificar o status do trabalho. O mecanismo continua verificando o status do trabalho até que sua API responda que o trabalho está feito e retorne dados para seu aplicativo lógico, que continua, em seguida, o fluxo de trabalho.
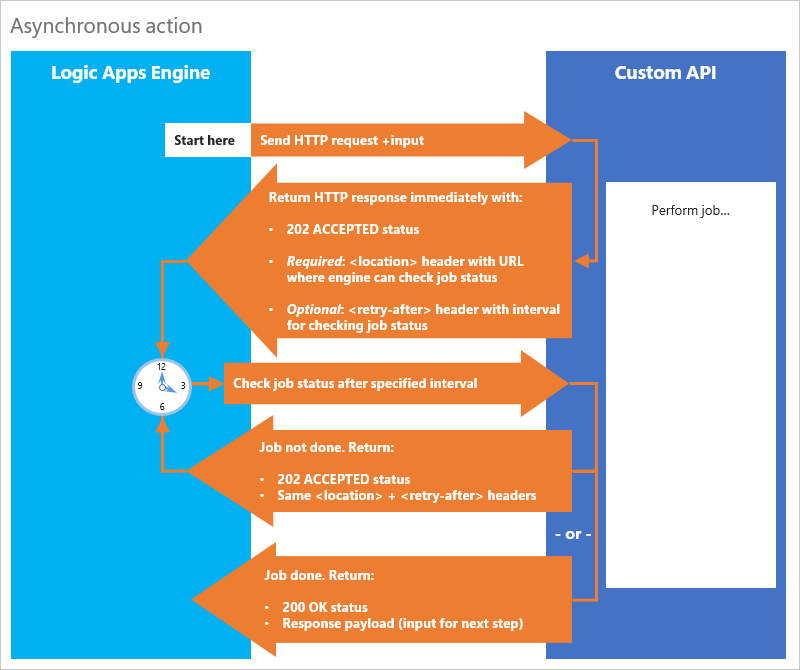
Aqui estão as etapas específicas que sua API deve seguir, descritas da perspectiva da API:
Quando sua API recebe uma solicitação HTTP para iniciar o trabalho, retorna imediatamente uma resposta HTTP
202 ACCEPTEDcom o cabeçalholocationdescrito mais adiante nesta etapa. Essa resposta permite que o mecanismo dos Aplicativos Lógicos do Azure saiba que sua API recebeu a solicitação, aceitou a carga de solicitação (dados de entrada) e está processando.A resposta
202 ACCEPTEDdeve incluir estes cabeçalhos:Obrigatório: um cabeçalho
locationque especifica o caminho absoluto para uma URL onde o mecanismo dos Aplicativos Lógicos pode verificar o status do trabalho da APIOpcional: Um cabeçalho
retry-afterque especifica o número de segundos que o mecanismo deve aguardar antes de verificar a URLlocationem relação ao status do trabalho.Por padrão, o mecanismo sonda a URL
locationapós um segundo. Para especificar um intervalo diferente, inclua o cabeçalhoretry-aftere o número de segundos até o próximo intervalo de sondagem.
Após o tempo especificado expirar, o mecanismo dos Aplicativos Lógicos do Azure sonda a URL
locationpara verificar o status do trabalho. Sua API deve executar estas verificações e retornar estas respostas:Se o trabalho está pronto, retornar uma resposta HTTP
200 OKjuntamente com a carga de resposta (entrada para a próxima etapa).Se o trabalho ainda estiver em processamento: retorne outra resposta HTTP
202 ACCEPTED, mas com os mesmos cabeçalhos que a resposta original.
Quando sua API segue esse padrão, você não precisa fazer nada na definição do fluxo de trabalho para continuar a verificação do status do trabalho.
Quando o mecanismo obtém uma resposta HTTP 202 ACCEPTED válida e um cabeçalho location, o mecanismo respeita o padrão assíncrono e verifica o cabeçalho location até que sua API retorne uma resposta não 202.
Dica
Para um padrão assíncrono de exemplo, examine o exemplo de resposta do controlador assíncrono no GitHub.
Executar tarefas de longa execução com o padrão de ação do webhook
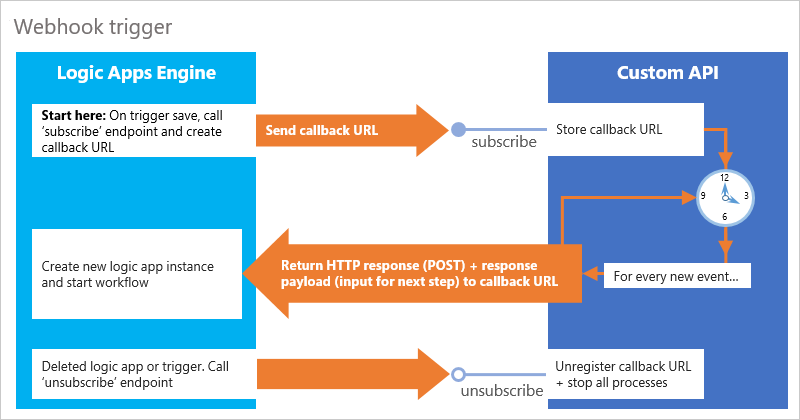
Como alternativa, você pode usar o padrão de webhook para tarefas de longa execução e processamento assíncrono. Esse padrão faz com que o fluxo de trabalho pause e aguarde o "retorno de chamada" da sua API para concluir o processamento antes de continuar o fluxo de trabalho. Esse retorno de chamada é um HTTP POST que envia uma mensagem para uma URL quando ocorre um evento.
Agora, aplique a analogia anterior da padaria ao padrão de webhook e imagine que você ligou para um padaria e pediu a entrega de um bolo personalizado. O processo para fazer o bolo leva tempo, e você não quer esperar no telefone enquanto a padaria está fazendo o bolo. A padaria confirma sua ordem, mas, desta vez, você deu a ela seu número de telefone para que ligue quando o bolo estiver pronto. Dessa vez, a padaria informa quando seu pedido está pronto e entrega o bolo.
Quando traçamos esse padrão de webhook de volta, a padaria representa sua API personalizada, ao passo que você, cliente do bolo, representa o mecanismo dos Aplicativos Lógicos do Azure. O mecanismo chama sua API com uma solicitação e inclui uma URL de "retorno de chamada". Quando o trabalho está pronto, sua API usa a URL para notificar o mecanismo e retornar dados para seu aplicativo lógico, que continua, em seguida, o fluxo de trabalho.
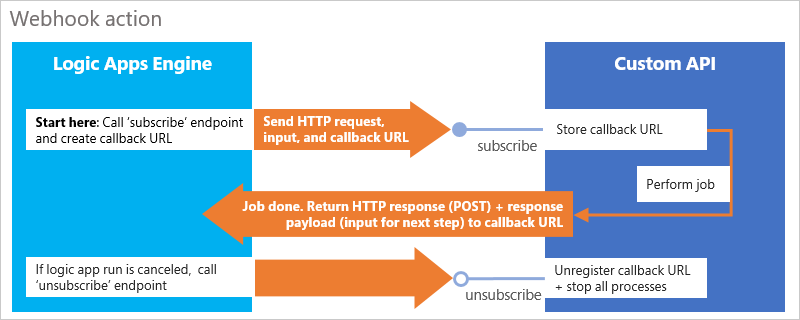
Para esse padrão, configure dois pontos de extremidade em seu controlador: subscribe e unsubscribe
Ponto de extremidade
subscribe: quando a execução atinge a ação da API no fluxo de trabalho, o mecanismo dos Aplicativos Lógicos do Azure chama o ponto de extremidadesubscribe. Esta etapa faz com que o fluxo de trabalho crie uma URL de retorno de chamada que a API armazena e, em seguida, aguarda o retorno de chamada da API quando o trabalho é concluído. Sua API retorna a chamada com um HTTP POST para a URL e transmite o conteúdo retornado e os cabeçalhos como entrada para o aplicativo lógico.Ponto de extremidade
unsubscribe: se a execução do aplicativo lógico for cancelada, o mecanismo dos Aplicativos Lógicos do Azure chama o ponto de extremidadeunsubscribe. Sua API pode cancelar o registro da URL de retorno de chamada e parar todos os processos conforme a necessidade.
Atualmente, o designer de fluxo de trabalho não dá suporte à descoberta de pontos de extremidade de webhook pelo Swagger. Para esse padrão, você precisa adicionar uma ação de Webhook e especificar a URL, os cabeçalhos e o corpo para a sua solicitação. Confira também Gatilhos e ações do fluxo de trabalho. Para um padrão de webhook de exemplo, reveja o exemplo de gatilho webhook no GitHub.
Aqui estão algumas outras dicas e observações:
Para transmitir a URL de retorno de chamada, você pode usar a função de fluxo de trabalho
@listCallbackUrl()em qualquer um desses campos, conforme a necessidade.Se você tiver o recurso do aplicativo lógico e o serviço assinado, não precisará chamar o ponto de extremidade
unsubscribedepois que a URL de retorno de chamada for chamada. Caso contrário, o runtime dos Aplicativos Lógicos do Azure precisa chamar o ponto de extremidadeunsubscribepara sinalizar que não há mais chamadas esperadas e para permitir a limpeza de recursos no lado do servidor.
Padrões de gatilho
Sua API personalizada pode atuar como um gatilho que inicia um fluxo de trabalho quando novos dados ou um evento atendem a uma condição especificada. Esse gatilho pode verificar regularmente, ou aguardar e escutar, novos dados ou eventos em seu ponto de extremidade de serviço. Se novos dados ou um evento atender à condição especificada, o gatilho será acionado e iniciará o aplicativo lógico que está escutando esse gatilho. Para iniciar aplicativos lógicos dessa maneira, sua API pode seguir o padrão de gatilho de sondagem ou gatilho de webhook. Esses padrões são semelhantes às ações de sondagem e ações de webhook correspondentes. Além disso, saiba mais sobre medição de uso para gatilhos.
Verificar se há novos dados ou eventos regularmente com o padrão de gatilho de sondagem
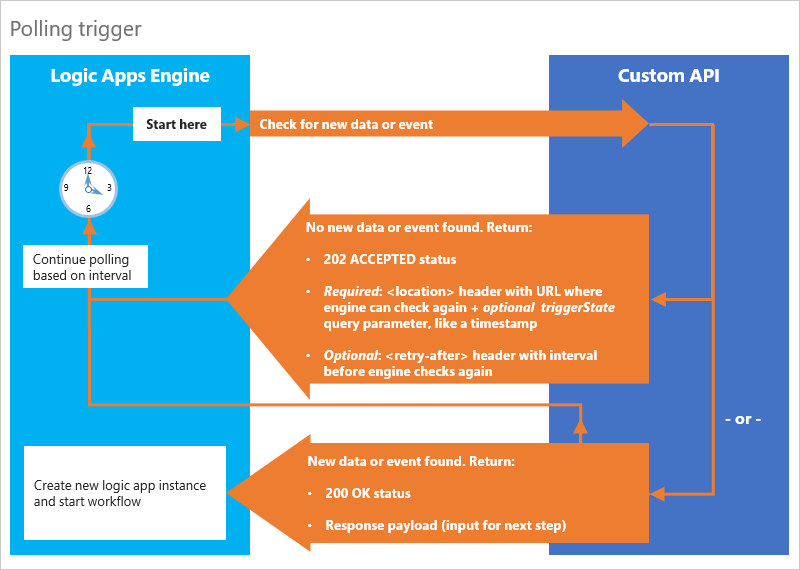
Um gatilho de sondagem atua como a ação de sondagem descrita anteriormente neste tópico. O mecanismo dos Aplicativos Lógicos do Azure chama e verifica se há novos dados ou eventos no ponto de extremidade de gatilho periodicamente. Se o mecanismo localizar novos dados ou um evento que atenda à condição especificada, o gatilho será acionado. Em seguida, o mecanismo cria uma instância de fluxo de trabalho que processa os dados como entrada.
Observação
Cada solicitação de sondagem conta como uma execução de ação, mesmo quando nenhuma instância do fluxo de trabalho é criada. Para evitar o processamento dos mesmos dados várias vezes, o gatilho deve limpar os dados que já foram lidos e transmitidos para o aplicativo lógico.
Aqui estão as etapas específicas para um gatilho de sondagem, descritas da perspectiva da API:
| Encontrou novos dados ou evento? | Resposta da API |
|---|---|
| Encontrado | Retornar um status HTTP 200 OK com a carga de resposta (entrada para a próxima etapa). Essa resposta cria uma instância de fluxo de trabalho e inicia o fluxo de trabalho. |
| Não encontrado | Retornar um status HTTP 202 ACCEPTED com um cabeçalho location e um cabeçalho retry-after. Para gatilhos, o cabeçalho location também deve conter um parâmetro de consulta triggerState, que geralmente é um "carimbo de data/hora". Sua API pode usar esse identificador para acompanhar a última vez em que o fluxo de trabalho foi disparado. |
Por exemplo, para verificar periodicamente novos arquivos no serviço, você pode criar um gatilho de sondagem que tenha estes comportamentos:
A solicitação inclui triggerState? |
Resposta da API |
|---|---|
| Não | Retornar um status HTTP 202 ACCEPTED e um cabeçalho location com triggerState definido com a hora atual e o intervalo retry-after como 15 segundos. |
| Sim | Verifique em seu serviço arquivos adicionados após o DateTime para triggerState. |
| Número de arquivos encontrados | Resposta da API |
|---|---|
| Arquivo único | Retornar um status HTTP 200 OK e a carga de conteúdo, atualizar triggerState para o DateTime do arquivo retornado e definir o intervalo de retry-after como 15 segundos. |
| Vários arquivos | Retornar um arquivo por vez e um status HTTP 200 OK, atualizar triggerStatee definir o intervalo de retry-after como 0 segundo.
Estas etapas permitem que o mecanismo saiba se há mais dados disponíveis e se o mecanismo deve solicitar os dados da URL no cabeçalho location imediatamente. |
| Não há arquivos | Retornar um status HTTP 202 ACCEPTED, não alterar triggerStatee definir o intervalo de retry-after como 15 segundos. |
Dica
Para obter um exemplo do padrão do gatilho de sondagem, reveja este exemplo de controlador de gatilho de sondagem no GitHub.
Aguardar e escutar novos dados ou eventos com o padrão de gatilho de webhook
Um gatilho de webhook é um gatilho de envio por push que aguarda e escuta novos dados ou eventos em seu ponto de extremidade de serviço. Se novos dados ou um evento atendem à condição especificada, o gatilho será acionado e criará uma instância de fluxo de trabalho que processa os dados como entrada.
Os gatilhos de webhook atuam como as ações de webhook descritas anteriormente neste tópico e são configuradas com pontos de extremidade subscribe e unsubscribe.
Ponto de extremidade
subscribe: quando você adiciona e salva um gatilho de webhook em seu aplicativo lógico, o mecanismo dos Aplicativos Lógicos do Azure chama o ponto de extremidadesubscribe. Esta etapa faz com que o fluxo de trabalho crie uma URL de retorno de chamada que é armazenada pela API. Quando há novos dados ou um evento que atenda à condição especificada, sua API retorna a chamada com um HTTP POST para a URL. A carga de conteúdo e os cabeçalhos são transmitidos como entrada para o aplicativo lógico.Ponto de extremidade
unsubscribe: se o gatilho de webhook ou o aplicativo lógico inteiro for excluído, o mecanismo dos Aplicativos Lógicos do Azure chama o ponto de extremidadeunsubscribe. Sua API pode cancelar o registro da URL de retorno de chamada e parar todos os processos conforme a necessidade.
Atualmente, o designer de fluxo de trabalho não dá suporte à descoberta de pontos de extremidade de webhook pelo Swagger. Para esse padrão, você precisa adicionar um gatilho de Webhook e especificar a URL, os cabeçalhos e o corpo para a sua solicitação. Confira também Gatilho HTTPWebhook. Para um padrão de webhook de exemplo, reveja o exemplo de controlador de gatilho webhook no GitHub.
Aqui estão algumas outras dicas e observações:
Para transmitir a URL de retorno de chamada, você pode usar a função de fluxo de trabalho
@listCallbackUrl()em qualquer um desses campos, conforme a necessidade.Para evitar o processamento dos mesmos dados várias vezes, o gatilho deve limpar os dados que já foram lidos e transmitidos para o aplicativo lógico.
Se você tiver o recurso do aplicativo lógico e o serviço assinado, não precisará chamar o ponto de extremidade
unsubscribedepois que a URL de retorno de chamada for chamada. Caso contrário, o runtime dos Aplicativos Lógicos precisa chamar o ponto de extremidadeunsubscribepara sinalizar que não há mais chamadas esperadas e para permitir a limpeza de recursos no lado do servidor.
Melhore a segurança para chamadas para suas APIs de aplicativos lógicos
Depois de criar suas APIs personalizados, configure a autenticação para suas APIs para que você possa chamá-las com segurança de aplicativos lógicos. Saiba como melhorar a segurança em chamadas para APIs personalizadas de aplicativos lógicos.
Implantar e chamar suas APIs
Depois de configurar a autenticação, configure a implantação para suas APIs. Saiba como implantar e chamar APIs personalizadas de aplicativos lógicos.
Publicar APIs personalizadas no Azure
Para disponibilizar seu APIs personalizadas para outros usuários de aplicativos lógicos no Azure, você deve adicionar a segurança e registrá-los como conectores do Aplicativos Lógicos do Azure. Para obter mais informações, consulte Visão geral de conectores personalizados.
Para disponibilizar suas APIs personalizadas a todos os usuários nos Aplicativos Lógicos,no Power Automate e no Microsoft Power Apps, você deve adicionar segurança, registrar suas APIs como conectores de Aplicativos Lógicos do Azure e designar os conectores para o programa Microsoft Azure Certified.
Obtenha suporte
Para obter ajuda específica com APIs personalizadas, entre em contato com customapishelp@microsoft.com.
Em caso de dúvidas, visite a página de perguntas e respostas da Microsoft sobre os Aplicativos Lógicos do Azure.