Instalar o Jupyter Notebook em seu computador e conectar-se ao Apache Spark no HDInsight
Neste artigo, você aprenderá a instalar o Jupyter Notebook, com os kernels PySpark (para Python) e Apache Spark (para Scala) personalizados com o Spark Magic. Em seguida, conecte o notebook a um cluster do HDInsight.
Há quatro etapas principais na instalação do Jupyter e na conexão com o Apache Spark no HDInsight.
- Configurar o cluster do Spark.
- Instalar o Jupyter Notebook.
- Instale os kernels PySpark e Spark com a mágica do Spark.
- Configure a mágica do Spark para acessar o cluster Spark no HDInsight.
Para obter mais informações sobre kernels personalizados e Spark magic, confira Kernels disponíveis para Jupyter Notebooks com clusters do Linux Apache Spark no HDInsight.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight. O notebook local se conecta ao cluster do HDInsight.
Familiaridade com o uso de anotações do Jupyter com Spark no HDInsight.
Instalar o Jupyter Notebook no computador
Instale o Python antes de instalar Jupyter Notebooks. A distribuição Anaconda instala ambos, Python e Jupyter Notebook.
Baixe o instalador do Anaconda para sua plataforma e execute a instalação. Ao executar o assistente de instalação, não deixe de selecionar a opção de adicionar o Anaconda à variável PATH. Confira também Installing Jupyter using Anaconda.
Instalar o Spark magic
Insira o comando
pip install sparkmagic==0.13.1para instalar o Spark magic para clusters do HDInsight versão 3.6 e 4.0. Confira também a documentação do sparkmagic.Execute este comando para verificar se o
ipywidgetsestá devidamente instalado:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Instalar PySpark e kernels do Spark
Digite este comando para verificar onde o
sparkmagicestá instalado:pip show sparkmagicEm seguida, altere o diretório de trabalho para o local identificado com o comando acima.
No novo diretório de trabalho, insira um ou mais dos comandos abaixo para instalar os kernels desejados:
Kernel Comando Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOpcional. Digite o comando a seguir para habilitar a extensão do servidor:
jupyter serverextension enable --py sparkmagic
Configurar a mágica do Spark para se conectar ao cluster do HDInsight Spark
Nesta seção, você configura o Spark magic que você instalou para se conectar a um cluster do Apache Spark.
Inicie o shell do Python com o seguinte comando:
pythonAs informações de configuração do Jupyter normalmente são armazenadas no diretório base dos usuários. Digite o seguinte comando para identificar o diretório base e crie uma pasta chamada .sparkmagic. O caminho completo será emitido.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Dentro da pasta
.sparkmagic, crie um arquivo chamado config.json e adicione o snippet de código JSON a seguir dentro dele.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Faça as seguintes edições no arquivo:
Valor do modelo Novo valor {USERNAME} Logon do cluster, o padrão é admin.{CLUSTERDNSNAME} Nome do cluster {BASE64ENCODEDPASSWORD} Uma senha codificada em base64 da senha real. Você pode gerar uma senha base64 em https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Mantenha se estiver usando sparkmagic 0.12.7(clusters v3.5 e v3.6). Se estiver usandosparkmagic 0.2.3(clusters v3.4), substitua por"should_heartbeat": true.Você pode ver um arquivo de exemplo completo na amostra de config.json.
Dica
As pulsações são enviadas para garantir que as sessões não sejam perdidas. Quando um computador entra em suspensão ou está desligado, a pulsação não é enviada e, como resultado, a sessão é limpa. Para clusters v3.4, se desejar desabilitar esse comportamento, você poderá definir a configuração Livy
livy.server.interactive.heartbeat.timeoutpara0da interface do usuário do Ambari. Para clusters v3.5, se você não definir a configuração de 3.5 ou acima, a sessão não será excluída.Inicie o Jupyter. Use o comando do prompt de comando a seguir.
jupyter notebookVerifique se você pode usar o Spark magic disponível com os kernels. Conclua as etapas a seguir.
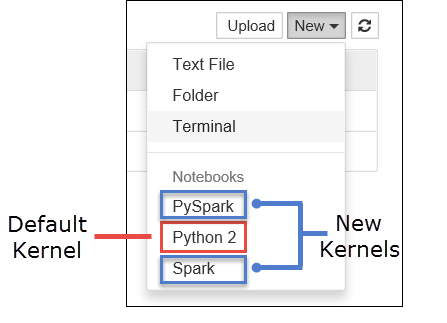
a. Crie um novo bloco de anotações. No canto direito, selecione Novo. Você deve ver o kernel padrão Python 2 ou Python 3 e os kernels instalados. Os valores reais podem variar dependendo das opções de instalação. Selecione PySpark.
Importante
Depois de selecionar Novo, verifique se há erros no shell. Caso ocorra o erro
TypeError: __init__() got an unexpected keyword argument 'io_loop', talvez você esteja enfrentando um problema conhecido com algumas versões do Tornado. Nesse caso, pare o kernel e faça downgrade da instalação do Tornado com o seguinte comando:pip install tornado==4.5.3.b. Execute o snippet de código a seguir.
%%sql SELECT * FROM hivesampletable LIMIT 5Se você puder recuperar a saída com êxito, a conexão com o cluster HDInsight será testada.
Se você quiser atualizar a configuração do notebook para se conectar a um cluster diferente, atualize o config.json com o novo conjunto de valores, conforme mostrado na Etapa 3 acima.
Por que devo instalar o Jupyter no meu computador?
Motivos para instalar o Jupyter no computador e conectá-lo a um cluster do Apache Spark no HDInsight:
- Permite criar notebooks localmente, testar o aplicativo no cluster em execução depois e carregar os notebooks no cluster. Para carregar os notebooks no cluster, você pode carregá-los usando o Jupyter Notebook que está em execução ou o cluster, ou salvá-los na pasta
/HdiNotebooksna conta de armazenamento associada ao cluster. Para saber mais sobre o armazenamento dos notebooks no cluster, confira Onde os Jupyter Notebooks são armazenados? - Com os blocos de notas disponíveis localmente, você pode se conectar a clusters Spark diferentes com base nos requisitos do aplicativo.
- É possível usar o GitHub para implementar um sistema de controle de origem e ter o controle de versão para os blocos de notas. Você também pode ter um ambiente colaborativo, onde vários usuários podem trabalhar com o mesmo bloco de notas.
- Você pode trabalhar com blocos de notas localmente sem sequer ter um cluster em operação. É preciso apenas um cluster no qual testar seus blocos de notas, e não para gerenciar manualmente os blocos de notas ou um ambiente de desenvolvimento.
- Pode ser mais fácil configurar seu próprio ambiente de desenvolvimento local que configurar a instalação do Jupyter no cluster. É possível usar todo o software que você tem instalado localmente sem configurar um ou mais clusters remotos.
Aviso
Com o Jupyter instalado no computador local, vários usuários podem executar o mesmo bloco de notas no mesmo cluster Spark ao mesmo tempo. Nessa situação, várias sessões Livy são criadas. Se você tiver um problema e desejar depurá-lo, será uma tarefa complexa rastrear qual sessão Livy pertence a qual usuário.