Analise os logs de telemetria do Application Insights com o Apache Spark no HDInsight
Aprenda como usar o Apache Spark no HDInsight para analisar os dados de telemetria do Application Insight.
Visual Studio Application Insights é um serviço de análise que monitora seus aplicativos Web. Os dados de telemetria gerados pelo Application Insights podem ser exportados para o armazenamento do Azure. Depois que os dados estiverem no armazenamento do Azure, o HDInsight pode ser usado para analisá-los.
Pré-requisitos
Um aplicativo que está configurado para usar o Application Insights.
Familiaridade com a criação de um cluster HDInsight baseado em Linux. Para obter mais informações, consulte Criar o Spark do Apache no HDInsight .
Um navegador da Web.
Os recursos a seguir foram usados para desenvolvimento e testes deste documento:
Os dados de telemetria do Application Insights foram gerados usando um aplicativo Web do Node.js configurado para usar o Application Insights.
Um cluster Spark no HDInsight versão 3.5 baseado em Linux foi usado para analisar os dados.
Arquitetura e planejamento
O diagrama a seguir ilustra a arquitetura de serviço deste exemplo:
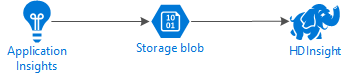
Armazenamento do Azure
O Application Insights pode ser configurado para exportar informações de telemetria para blobs continuamente. O HDInsight poderá então ler os dados armazenados em blobs. No entanto, há alguns requisitos que devem ser seguidos:
Local: se a conta de armazenamento e o HDInsight estiverem em locais diferentes, isso poderá aumentar a latência. Isso também aumenta o custo, pois os encargos são aplicados a dados sendo transferidos entre regiões.
Aviso
Não há suporte para o uso de uma Conta de armazenamento em um local diferente do HDInsight.
Tipo de Blob: o HDInsight dá suporte apenas aos blobs de bloco. O Application Insights usa blobs de bloco como padrão, então, deve funcionar por padrão com o HDInsight.
Para obter informações sobre como adicionar armazenamento adicional a um cluster existente, consulte o documento Adicionar contas de armazenamento adicionais.
Esquema de dados
O Application Insights fornece informações para exportar o modelo de dados para o formato de dados de telemetria exportados para os blobs. As etapas neste documento usam Spark SQL para trabalhar com os dados. O Spark SQL pode gerar automaticamente um esquema para a estrutura de dados JSON registrada pelo Application Insights.
Exportar dados de telemetria
Siga as etapas em Configurar a exportação contínua para configurar o Application Insights para exportar informações de telemetria para um blob de Armazenamento do Azure.
Configurar o HDInsight para acessar os dados
Se você estiver criando um cluster HDInsight, adicione a conta de armazenamento durante a criação do cluster.
Para adicionar a Conta de armazenamento do Azure a um cluster existente, use as informações no documento Adicionar contas de armazenamento adicionais.
Analisar os dados: PySpark
Em um navegador da Web, acesse
https://CLUSTERNAME.azurehdinsight.net/jupyter, em que CLUSTERNAME é o nome do cluster.No canto superior direito da página Jupyter, selecione Novo, então, PySpark. Uma nova guia do navegador que contém um Bloco de Notas Jupyter com base em Python é aberta.
No primeiro campo (denominado célula) na página, digite o seguinte texto:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Esse código configura o Spark para acessar de forma recursiva a estrutura de diretórios para os dados de entrada. A Application Insights Telemetry é registrada em uma estrutura de diretórios semelhante ao
/{telemetry type}/YYYY-MM-DD/{##}/.Use SHIFT+ENTER para executar o código. No lado esquerdo da célula, um '*' aparece entre colchetes para indicar que o código nessa célula está sendo executado. Quando concluído, o '*' é alterado para um número e uma saída semelhante à seguinte é exibida abaixo da célula:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Uma nova célula é criada abaixo da primeira. Digite o texto a seguir na nova célula. Substitua
CONTAINEReSTORAGEACCOUNTpelo nome da conta de Armazenamento do Azure e pelo nome do contêiner do blob que contém dados do Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Use SHIFT+ENTER para executar essa célula. Você verá um resultado semelhante ao seguinte texto:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831O caminho wasbs retornado é o local dos dados de telemetria do Application Insights. Altere a linha
hdfs dfs -lsna célula para usar o caminho wasbs retornado, em seguida, use SHIFT+ENTER para executar a célula novamente. Desta vez, os resultados devem exibir os diretórios que contêm dados de telemetria.Observação
Para o restante das etapas desta seção, foi usado o diretório
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. A estrutura de diretório pode ser diferente.Na próxima célula, digite o seguinte código: substitua
WASB_PATHpelo caminho da etapa anterior.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Esse código cria um dataframe dos arquivos JSON exportados pelo processo de exportação contínua. Use SHIFT+ENTER para executar essa célula.
Na próxima célula, digite e execute o seguinte para exibir o esquema que o Spark criou para os arquivos JSON:
jsonData.printSchema()O esquema para cada tipo de telemetria é diferente. O exemplo a seguir é o esquema gerado para solicitações da Web (dados armazenados no subdiretório
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Use o seguinte para registrar o dataframe como uma tabela temporária e executar uma consulta em relação aos dados:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Essa consulta retorna as informações de cidade para os primeiros 20 registros em que context.location.city não é nulo.
Observação
A estrutura de contexto está presente em toda a telemetria registrada pelo Application Insights. O elemento de cidade não pode ser preenchido em seus logs. Use o esquema para identificar outros elementos que você possa consultar e que possam conter dados para seus logs.
Essa consulta retorna informações semelhantes ao seguinte texto:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Analisar os dados: Scala
Em um navegador da Web, acesse
https://CLUSTERNAME.azurehdinsight.net/jupyter, em que CLUSTERNAME é o nome do cluster.No canto superior direito da página Jupyter, selecione Novo, então, Scala. Uma nova guia do navegador contendo um Bloco de anotações do Jupyter com base em Scala é exibida.
No primeiro campo (denominado célula) na página, digite o seguinte texto:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Esse código configura o Spark para acessar de forma recursiva a estrutura de diretórios para os dados de entrada. A Application Insights Telemetry é registrada em uma estrutura de diretórios semelhante a
/{telemetry type}/YYYY-MM-DD/{##}/.Use SHIFT+ENTER para executar o código. No lado esquerdo da célula, um '*' aparece entre colchetes para indicar que o código nessa célula está sendo executado. Quando concluído, o '*' é alterado para um número e uma saída semelhante à seguinte é exibida abaixo da célula:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Uma nova célula é criada abaixo da primeira. Digite o texto a seguir na nova célula. Substitua
CONTAINEReSTORAGEACCOUNTpelo nome da conta de Armazenamento do Azure e pelo nome do contêiner de blob que contém logs do Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Use SHIFT+ENTER para executar essa célula. Você verá um resultado semelhante ao seguinte texto:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831O caminho wasbs retornado é o local dos dados de telemetria do Application Insights. Altere a linha
hdfs dfs -lsna célula para usar o caminho wasbs retornado, em seguida, use SHIFT+ENTER para executar a célula novamente. Desta vez, os resultados devem exibir os diretórios que contêm dados de telemetria.Observação
Para o restante das etapas desta seção, foi usado o diretório
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Este diretório pode não existir, a menos que os dados de telemetria sejam para um aplicativo Web.Na próxima célula, digite o seguinte código: substitua
WASB\_PATHpelo caminho da etapa anterior.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Esse código cria um dataframe dos arquivos JSON exportados pelo processo de exportação contínua. Use SHIFT+ENTER para executar essa célula.
Na próxima célula, digite e execute o seguinte para exibir o esquema que o Spark criou para os arquivos JSON:
jsonData.printSchemaO esquema para cada tipo de telemetria é diferente. O exemplo a seguir é o esquema gerado para solicitações da Web (dados armazenados no subdiretório
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Use o seguinte para registrar o dataframe como uma tabela temporária e executar uma consulta em relação aos dados:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Essa consulta retorna as informações de cidade para os primeiros 20 registros em que context.location.city não é nulo.
Observação
A estrutura de contexto está presente em toda a telemetria registrada pelo Application Insights. O elemento de cidade não pode ser preenchido em seus logs. Use o esquema para identificar outros elementos que você possa consultar e que possam conter dados para seus logs.
Essa consulta retorna informações semelhantes ao seguinte texto:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Próximas etapas
Para obter mais exemplos do uso do Apache Spark para trabalhar com dados e serviços no Azure, consulte os seguintes documentos:
- Apache Spark com BI: execute análise de dados interativa usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever os resultados da inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Para saber mais sobre a criação e a execução de aplicativos Spark, veja os seguintes documentos: