Guia de dimensionamento do Cluster de Consulta Interativa do Azure HDInsight (Hive LLAP)
Este documento descreve o dimensionamento do cluster de Consulta Interativa do HDInsight (cluster Hive LLAP) para uma carga de trabalho normal para obter um desempenho aceitável. As recomendações deste documento são diretrizes genéricas e cargas de trabalho específicas que podem precisar de ajuste específico.
Tipos de VM padrão do Azure para o Cluster de consulta Interativa do HDInsight (LLAP)
| Tipo de nó | Instância | Tamanho |
|---|---|---|
| Head | D13 v2 | 8 vcpus, 56-GB de RAM, 400 GB de SSD |
| Trabalho | D14 v2 |
16 vcpus, 112 GB de RAM, 800 GB de SSD |
| ZooKeeper | A4 v2 | 4 vcpus, 8-GB de RAM, 40 GB de SSD |
Observação: Todos os valores de configuração recomendados se baseiam no nó de trabalho do tipo D14 v2
Configuração:
| Chave de configuração | Valor recomendado | Descrição |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 102400 (MB) | Memória total fornecida, em MB, para todos os contêineres de YARN em um nó |
| yarn.scheduler.maximum-allocation-mb | 102400 (MB) | A alocação máxima de cada solicitação de contêiner no RM, em MBs. As solicitações de memória maiores que esse valor não entrarão em vigor |
| yarn.scheduler.maximum-allocation-vcores | 12 | O número máximo de núcleos de CPU de cada solicitação de contêiner no Resource Manager. As solicitações maiores que esse valor não entrarão em vigor. |
| yarn.nodemanager.resource.cpu-vcores | 12 | Número de núcleos de CPU por NodeManager que podem ser alocados para contêineres. |
| yarn.scheduler.capacity.root.llap.capacity | 85 (%) | Alocação de capacidade do YARN para fila de LLAP |
| tez.am.resource.memory.mb | 4096 (MB) | A quantidade de memória em MB a ser usada pelo tez AppMaster |
| hive.server2.tez.sessions.per.default.queue | <number_of_worker_nodes> | O número de sessões de cada fila chamada no hive.server2.tez.default.queues. Esse número corresponde ao número de coordenadores de consulta (Tez AMs) |
| hive.tez.container.size | 4096 (MB) | Tamanho do contêiner Tez especificado em MB |
| hive.llap.daemon.num.executors | 19 | Número de executores por daemon de LLAP |
| hive.llap.io.threadpool.size | 19 | Tamanho do pool de threads para executores |
| hive.llap.daemon.yarn.container.mb | 81920 (MB) | Memória total em MB usada por daemons de LLAP individuais (memória por daemon) |
| hive.llap.io.memory.size | 242688 (MB) | Tamanho do cache em MB por daemon LLAP, desde que o cache de SSD esteja habilitado |
| hive.auto.convert.join.noconditionaltask.size | 2048 (MB) | tamanho da memória em MB para fazer a Junção de mapa |
Arquitetura/Componentes do LLAP:
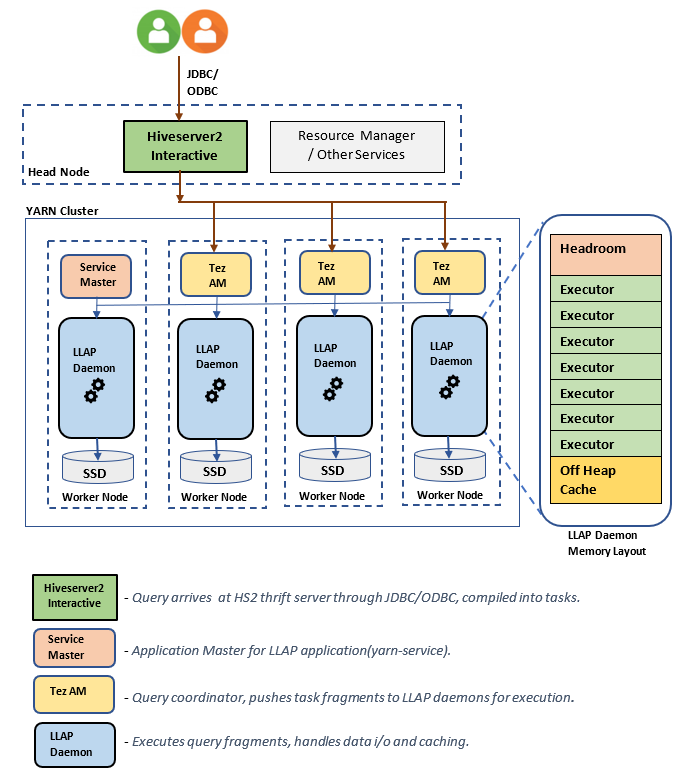
Estimativas de tamanho do daemon de LLAP:
1. Determinação de alocação total de memória YARN para todos os contêineres em um nó
Configuração: yarn.nodemanager.resource.memory-mb
Esse valor indica uma soma máxima da memória em MB que pode ser usada pelos contêineres YARN em cada nó. O valor especificado deve ser menor que a quantidade total de memória física nesse nó.
Memória total para todos os contêineres YARN em um nó = (memória física total para o sistema operacional + outros serviços)
Defina esse valor como aproximadamente 90% da RAM disponível.
Para D14 v2, o valor recomendado é 102400 MB.
2. Determinação da quantidade máxima de memória por solicitação de contêiner do YARN
Configuração: yarn.scheduler.maximum-allocation-mb
Esse valor indica a alocação máxima de cada solicitação de contêiner no Azure Resource Manager, em MB. As solicitações de memória maiores que o valor especificado não entrarão em vigor. O Resource Manager pode fornecer memória para contêineres em incrementos de yarn.scheduler.minimum-allocation-mb e não pode exceder o tamanho especificado por yarn.scheduler.maximum-allocation-mb. O valor especificado não deve ser maior que a memória total especificada para todos os contêineres no nó especificado por yarn.nodemanager.resource.memory-mb.
Para nós de trabalho D14 v2, o valor recomendado é 102400 MB
3. Determinando a quantidade máxima de vcores por solicitação de contêiner YARN
Configuração: yarn.scheduler.maximum-allocation-vcores
Esse valor indica o número máximo de núcleos de CPU virtual de cada solicitação de contêiner no Resource Manager. Solicitando um número maior de vcores que esse valor não terá efeito. É uma propriedade global do Agendador do YARN. Para contêiner daemon LLAP, esse valor pode ser definido como 75% do total disponível vcores. Os 25% restantes devem ser reservados para NodeManager, DataNode e outros serviços em execução nos nós de trabalho.
Existem 16 vcores em VMs D14 v2 e 75% do total 16 vcores pode ser usado pelo contêiner daemon LLAP.
Para D14 v2, o valor recomendado é 12.
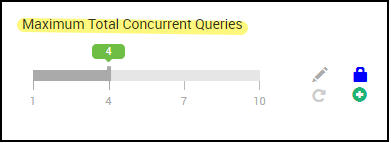
4. Número de consultas simultâneas
Configuração: hive.server2.tez.sessions.per.default.queue
Esse valor de configuração determina o número de sessões de Tez que podem ser iniciadas paralelamente. Essas sessões Tez são iniciadas para cada uma das filas especificadas por "hive.server2.tez.default.queues". Isso corresponde ao número de Tez AMs (Coordenadores de Consulta). É recomendável que seja igual ao número de nós de trabalho. O número de Tez AMs pode ser maior que o número de nós do daemon de LLAP. Sua principal responsabilidade é coordenar a execução da consulta e atribuir fragmentos do plano de consulta aos daemons de LLAP correspondentes para execução. Mantenha esse valor como múltiplo de vários nós daemon LLAP para obter maior taxa de transferência.
O cluster HDInsight padrão tem quatro daemons de LLAP em execução em quatro nós de trabalho. Portanto, o valor recomendado é 4.
Controle deslizante da interface do usuário do Ambari para variável de configuração do Hive hive.server2.tez.sessions.per.default.queue:
5. O contêiner Tez e o tamanho mestre do aplicativo Tez
Configuração: tez.am.resource.memory.mb, hive.tez.container.size
tez.am.resource.memory.mb - define o tamanho mestre do aplicativo Tez.
O valor recomendado é 4096 MB.
hive.tez.container.size - define a quantidade de memória fornecida para o contêiner Tez. Esse valor deve ser definido entre o tamanho mínimo do contêiner YARN (yarn.scheduler.minimum-allocation-mb) e o tamanho máximo de contêiner YARN (yarn.scheduler.maximum-allocation-mb). Os executores de daemon de LLAP usam esse valor para limitar o uso de memória por executor.
O valor recomendado é 4096 MB.
6. Alocação de capacidade de fila de LLAP
Configuração: yarn.scheduler.capacity.root.llap.capacity
Esse valor indica uma porcentagem da capacidade fornecida para a fila de LLAP. As alocações de capacidade podem ter valores diferentes para cargas de trabalho diferentes, dependendo de como as filas do YARN estão configuradas. Se sua carga de trabalho for de operações somente leitura, defini-la como 90% da capacidade deve funcionar. No entanto, se sua carga de trabalho for uma combinação de operações de atualização/exclusão/mesclagem usando tabelas gerenciadas, dê 85% da capacidade para a fila de LLAP. A capacidade restante de 15% pode ser usada por outras tarefas, como compactação etc. para alocar contêineres da fila padrão. Dessa forma, as tarefas na fila padrão não retirarão os recursos do YARN.
Para nós de trabalho D14v2, o valor recomendado para a fila de LLAP é 85.
(Para cargas de trabalho somente leitura, pode ser aumentado até 90 como for adequado.)
7. Tamanho do contêiner do daemon de LLAP
Configuração: hive.llap.daemon.yarn.container.mb
O daemon de LLAP é executado como um contêiner do YARN em cada nó de trabalho. O tamanho total da memória para o contêiner do daemon de LLAP depende dos seguintes fatores,
- Configurações do tamanho do contêiner do YARN (yarn.scheduler.minimum-allocation-mb, yarn.scheduler.maximum-allocation-mb, yarn.nodemanager.resource.memory-mb)
- Número de Tez AMs em um nó
- Memória total configurada para todos os contêineres em um nó e capacidade de fila de LLAP
A memória necessária pelo Tez AM (Tez Application Masters) pode ser calculada da seguinte maneira.
O Tez AM atua como um coordenador de consultas, e o número de Tez AMs deve ser configurado com base em várias consultas simultâneas a serem atendidas. Teoricamente, podemos considerar um Tez AM por nó de trabalho. No entanto, é possível que você veja mais de um Tez AM em um nó de trabalho. Para fins de cálculo, pressupomos a distribuição uniforme de Tez AMs em todos os nós/nós de trabalho do daemon de LLAP.
É recomendável ter 4 GB de memória por Tez AM.
Número de Tez AMs = valor especificado pela configuração do Hive hive.server2.tez.sessions.per.default.queue.
Número de nós do daemon de LLAP = especificado pela variável env num_llap_nodes_for_llap_daemons na interface do usuário do Ambari.
Tamanho do contêiner Tez AM = valor especificado pela configuração do Tez tez.am.resource.memory.mb.
Memória Tez AM por nó = (ceil(Número de Tez AMs / Número de nós do daemon LLAP)x Tamanho do contêiner Tez AM)
Para D14 v2, a configuração padrão tem quatro Tez AMs e quatro nós de daemon de LLAP.
Memória do Tez AM por nó = (ceil(4/4) x 4 GB) = 4 GB
A memória total disponível para a fila de LLAP por nó de trabalho pode ser calculada da seguinte maneira:
Esse valor depende da quantidade total de memória disponível para todos os contêineres de YARN em um nó (yarn.nodemanager.resource.memory-mb) e a porcentagem de capacidade configurada para a fila de LLAP (yarn.scheduler.capacity.root.llap.capacity).
Memória total para a fila de LLAP no nó de trabalho = total de memória disponível para todos os contêineres de YARN em um nó x percentual de capacidade para a fila de LLAP.
Para D14 v2, este valor é (100 GB x 0,85 ) = 85 GB.
O tamanho do contêiner do daemon de LLAP é calculado da seguinte maneira;
Tamanho do contêiner do daemon LLAP = (memória total para fila LLAP em um nó de trabalho) – (memória Tez AM por nó) - (tamanho do contêiner mestre de serviço)
Há apenas um Mestre de Serviço (Mestre de Aplicativo para serviço LLAP) no cluster gerado em um dos nós de trabalho. Para fins de cálculo, consideramos um mestre de serviço por nó de trabalho.
Para o nó de trabalho D14 v2, HDI 4.0 – o valor recomendado é (85 GB - 4 GB - 1 GB) = 80GB
8. Determinação do número de executores por daemon de LLAP
Configuração: hive.llap.daemon.num.executors, hive.llap.io.threadpool.size
hive.llap.daemon.num.executors:
Essa configuração controla o número de executores que podem realizar tarefas em paralelo por daemon LLAP. Esse valor depende do número de vcores, da quantidade de memória usada por executor e da quantidade de memória total disponível para o contêiner do daemon do LLAP. O número de executores pode ser superassinado em 120% de vcores disponíveis por nó de trabalho. No entanto, ele deve ser ajustado se não atender aos requisitos de memória com base na memória necessária por executor e o tamanho do contêiner LLAP daemon.
Cada executor é equivalente a um contêiner tez e pode consumir 4 GB (tamanho do contêiner tez) de memória. Todos os executores no daemon LLAP compartilham a mesma memória de heap. Com a suposição de que nem todos os executores executam operações com uso intensivo de memória ao mesmo tempo, você pode considerar 75% do tamanho do contêiner tez (4 GB) por executor. Dessa forma, você pode aumentar o número de executores dando a cada executor menos memória (por exemplo, 3 GB) para maior paralelismo. No entanto, é recomendável ajustar essa configuração para sua carga de trabalho de destino.
Há 16 vcores em VMs D14 v2. Para D14 v2, o valor recomendado para num dos executores é (16 vcores x 120%) ~ = 19 em cada nó de trabalho considerando 3 GB por executor.
hive.llap.io.threadpool.size:
Esse valor especifica o tamanho do pool de threads para executores. Como os executores são corrigidos conforme especificado, é igual ao número de executores por daemon LLAP.
Para D14 v2, o valor recomendado é 19.
9. Determinando o tamanho do cache do daemon de LLAP
Configuração: hive.llap.io.memory.size
A memória do contêiner do daemon do LLAP consiste nos seguintes componentes;
- Reserva dinâmica
- Memória de heap usada pelos executores (Xmx)
- Cache na memória por daemon (seu tamanho de memória fora do heap, não aplicável quando o cache SSD está habilitado)
- Tamanho de metadados de cache na memória (aplicável somente quando o cache de SSD está habilitado)
Tamanho do headroom: esse tamanho indica uma parte da memória fora do heap usada para sobrecarga do Java VM (metaespaço, pilha de threads, gc estruturas de dados, etc.). Em geral, essa sobrecarga é de cerca de 6% do tamanho do heap (Xmx). Para estar no lado mais seguro, este valor pode ser calculado como 6% do tamanho total da memória do daemon de LLAP.
Para D14 v2, o valor recomendado é ceil(80 GB x 0,06) ~= 4 GB.
Tamanho do heap(Xmx) : É a quantidade de memória heap disponível para todos os executores.
Tamanho total do heap = número de executores x 3 GB
Para D14 v2, esse valor é 19 x 3 GB = 57 GB
Ambari environment variable for LLAP heap size:

Quando o cache de SSD estiver desabilitado, o cache na memória será a quantidade de memória restante após a retirada do tamanho de reserva dinâmica e o tamanho do heap do tamanho do contêiner do daemon do LLAP.
O cálculo do tamanho do cache difere quando o cache de SSD está habilitado.
A configuração hive.llap.io.allocator.mmap = true habilita o cache SSD.
Quando o cache SSD está habilitado, parte da memória será usada para armazenar metadados para o cache de SSD. Os metadados são armazenados na memória e espera-se que seja ~8% do tamanho do cache de SSD.
Tamanho dos metadados de cache de SSD na memória = tamanho do contêiner do daemon do LLAP - (reserva dinâmica + tamanho do heap)
Para D14 v2, com HDI 4.0, o tamanho de metadados na memória do cache de SSD = 80 GB - (4 GB + 57 GB) = 19 GB
Considerando o tamanho da memória disponível para armazenar metadados de cache de SSD, podemos calcular o tamanho do cache de SSD que pode ser suportado.
Tamanho dos metadados de cache de SSD na memória = tamanho do contêiner do daemon do LLAP - ( reserva dinâmica + tamanho do heap) = 19 GB
Tamanho do cache de SSD = tamanho dos metadados de cache de SSD na memória (19 GB)/0.08 (8%)
Para D14 v2 e HDI 4.0, o tamanho recomendado do cache de SSD = 19 GB x 0.08~= 237 GB
10. Ajuste da memória de junção de mapa
Configuração: hive.auto.convert.join.noconditionaltask.size
Verifique se você tem hive.auto.convert.join.noconditionaltask habilitado para que esse parâmetro entre em vigor.
Essa configuração determina o limite para a seleção do MapJoin pelo otimizador do Hive, que considera a superassinatura da memória de outros executores para ter mais espaço para tabelas de hash na memória a fim de permitir mais conversões de junção de mapa. Considerando 3 GB por executor, esse tamanho pode ser superassinado para 3 GB, mas um pouco de memória de heap também pode ser usado para buffers de classificação, buffers de ordem aleatória, etc., por outras operações.
Portanto, para D14 v2, com 3 GB de memória por executor, é recomendado definir esse valor como 2048 MB.
(Observação: esse valor poderá precisar de ajustes adequados para sua carga de trabalho. A definição muito baixa desse valor pode não usar o recurso de conversão automática. Por outro lado, defini-lo com um valor muito alto pode resultar em exceções de memória insuficiente ou pausas do GC que podem resultar em desempenho adverso.)
11. Número de daemons do LLAP
Variáveis de ambiente do Ambari: num_llap_nodes, num_llap_nodes_for_llap_daemons
num_llap_nodes – especifica o número de nós usados pelo serviço LLAP do Hive. Isso inclui os nós que executam o daemon do LLAP, o Mestre de Serviço do LLAP e o Tez AM (Mestre de Aplicativo do Tez).
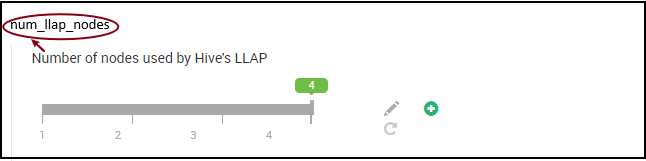
num_llap_nodes_for_llap_daemons – número especificado de nós usados somente para daemons do LLAP. Os tamanhos dos contêineres do daemon LLAP são definidos para o nó máximo de ajuste, portanto, resulta em um daemon llap em cada nó.

É recomendável manter os dois valores iguais ao número de nós de trabalho no cluster do Interactive Query.
Considerações para Gerenciamento de Carga de Trabalho
Se você quiser habilitar o gerenciamento de carga de trabalho para LLAP, reserve capacidade suficiente para que o gerenciamento de carga de trabalho funcione conforme o esperado. O gerenciamento de carga de trabalho requer a configuração de uma fila YARN personalizada, que adicionada à fila llap. Certifique-se de dividir a capacidade total de recursos do cluster entre a fila llap e a fila de gerenciamento de carga de trabalho de acordo com seus requisitos de carga de trabalho.
O gerenciamento de carga de trabalho gera Tez AMs (Mestres de Aplicativo do Tez) quando um plano de recurso é ativado.
Observação:
- Os Tez AMs gerados pela ativação de um plano de recursos consomem recursos da fila de gerenciamento de carga de trabalho, conforme especificado por
hive.server2.tez.interactive.queue. - O número de Tez AMs depende do valor de
QUERY_PARALLELISMespecificado no plano de recursos. - Depois que o gerenciamento de carga de trabalho está ativo, os Tez AMs na fila de LLAP não serão usados. Somente os Tez AMs da fila de gerenciamento de carga de trabalho são usados para coordenação de consultas. Os Tez AMs na fila de
llapsão usados quando o gerenciamento de carga de trabalho está desabilitado.
Por exemplo: capacidade total do cluster = 100 GB de memória, dividida entre LLAP, Gerenciamento de Carga de Trabalho e Filas Padrão da seguinte forma:
- Capacidade da fila de LLAP = 70 GB
- Capacidade da fila de gerenciamento de carga de trabalho = 20 GB
- Capacidade da fila padrão = 10 GB
Com 20 GB de capacidade de fila de gerenciamento de carga de trabalho, um plano de recursos pode especificar o valor QUERY_PARALLELISM como cinco, o que significa que o gerenciamento de carga de trabalho pode lançar cinco Tez AMs com tamanho de contêiner de 4 GB cada. Se QUERY_PARALLELISM for maior do que a capacidade, você poderá ver alguns Tez AMs pararem de responder no estado ACCEPTED. O servidor Hive 2 Interactive não pode enviar fragmentos de consulta para os Tez AMs que não estão no estado RUNNING.
Próximas Etapas
Se definir esses valores não resolver o problema, visite um dos seguintes...
Obtenha respostas de especialistas do Azure por meio do Suporte da Comunidade do Azure.
Conecte-se ao @AzureSupport – a conta oficial do Microsoft Azure para aprimorar a experiência do cliente conectando a comunidade do Azure aos recursos certos: respostas, suporte e especialistas.
Se precisar de mais ajuda, poderá enviar uma solicitação de suporte do portal do Azure. Selecione Suporte na barra de menus ou abra o hub Ajuda + suporte. Para obter informações mais detalhadas, consulte Como criar uma solicitação de Suporte do Azure. O acesso ao Gerenciamento de assinaturas e ao suporte de cobrança está incluído na sua assinatura do Microsoft Azure, e o suporte técnico é fornecido por meio de um dos Planos de suporte do Azure.
Outras referências: