Operações de Apache Spark compatíveis com o Hive Warehouse Connector no Azure HDInsight
Este artigo mostra as operações baseadas em Spark compatíveis com o HWC (Hive Warehouse Connector). Todos os exemplos mostrados serão executados por meio do shell do Apache Spark.
Pré-requisito
Conclua as etapas da instalação do Hive Warehouse Connector.
Introdução
Para iniciar uma sessão do shell do Spark, execute as seguintes etapas:
Use o comando ssh para se conectar ao cluster do Apache Spark. Edite o comando substituindo CLUSTERNAME pelo nome do cluster e, em seguida, insira o comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netEm sua sessão SSH, execute o seguinte comando para anotar a versão de
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorEdite o código com a versão de
hive-warehouse-connector-assemblyidentificada acima. Em seguida, execute o comando para iniciar o shell do Spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<STACK_VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseDepois de você iniciar o shell do Spark, uma instância do Hive Warehouse Connector pode ser iniciada usando os seguintes comandos:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Criar DataFrames do Spark usando consultas do Hive
Os resultados de todas as consultas que usam a biblioteca do HWC são retornados como um DataFrame. Os exemplos a seguir demonstram como criar uma consulta básica do Hive.
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
Os resultados da consulta são os DataFrames do Spark, que podem ser usados com bibliotecas do Spark como MLIB e SparkSQL.
Gravar DataFrames do Spark em tabelas do Hive
O Spark não dá suporte nativo à gravação em tabelas ACID gerenciadas do Hive. No entanto, usando o HWC, você pode gravar qualquer DataFrame em uma tabela do Hive. Você pode ver essa funcionalidade em operação no seguinte exemplo:
Crie uma tabela chamada
sampletable_coloradoe especifique as colunas dela usando o seguinte comando:hive.createTable("sampletable_colorado").column("clientid","string").column("querytime","string").column("market","string").column("deviceplatform","string").column("devicemake","string").column("devicemodel","string").column("state","string").column("country","string").column("querydwelltime","double").column("sessionid","bigint").column("sessionpagevieworder","bigint").create()Filtre a tabela
hivesampletableem que a colunastateé igual aColorado. Esta consulta do Hive retorna um DataFrame do Spark e o resultado é salvo na tabela do Hivesampletable_coloradousando a funçãowrite.hive.table("hivesampletable").filter("state = 'Colorado'").write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table","sampletable_colorado").save()Veja os resultados usando o seguinte comando:
hive.table("sampletable_colorado").show()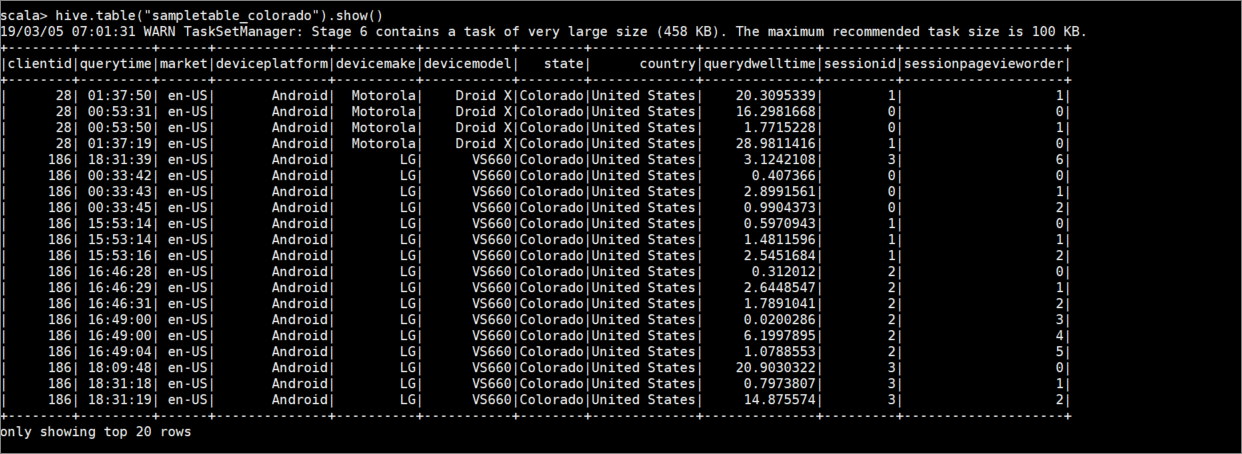
Gravações de streaming estruturado
Usando o Hive Warehouse Connector, você pode usar o streaming do Spark para gravar dados em tabelas do Hive.
Importante
Gravações de streaming estruturado não são compatíveis com clusters Spark 4.0 habilitados para ESP.
Siga as etapas para ingerir dados de um fluxo do Spark na porta localhost 9999 em uma tabela do Hive. Hive Warehouse Connector.
No shell do Spark aberto, inicie um fluxo do Spark com o seguinte comando:
val lines = spark.readStream.format("socket").option("host", "localhost").option("port",9999).load()Gere dados para o fluxo do Spark que você criou, executando as seguintes etapas:
- Abra uma segunda sessão SSH no mesmo cluster do Spark.
- No prompt de comando, digite
nc -lk 9999. Esse comando usa o utilitárionetcatpara enviar dados da linha de comando para a porta especificada.
Retorne à primeira sessão SSH e crie uma tabela do Hive para armazenar os dados de streaming. No shell do Spark, digite o seguinte comando:
hive.createTable("stream_table").column("value","string").create()Em seguida, grave os dados de streaming na tabela recém-criada usando o seguinte comando:
lines.filter("value = 'HiveSpark'").writeStream.format("com.hortonworks.spark.sql.hive.llap.streaming.HiveStreamingDataSource").option("database", "default").option("table","stream_table").option("metastoreUri",spark.conf.get("spark.datasource.hive.warehouse.metastoreUri")).option("checkpointLocation","/tmp/checkpoint1").start()Importante
Atualmente, as opções
metastoreUriedatabaseprecisam ser definidas manualmente devido a um problema conhecido no Apache Spark. Para obter mais informações sobre esse problema, confira SPARK-25460.Retorne à segunda sessão SSH e insira os seguintes valores:
foo HiveSpark barRetorne à primeira sessão SSH e observe a atividade breve. Para ver os dados, use o seguinte comando:
hive.table("stream_table").show()
Use Ctrl + C para interromper netcat a segunda sessão SSH. Use :q para sair do shell do Spark na primeira sessão SSH.