Consertar um erro de memória insuficiente do Apache Hive no Azure HDInsight
Saiba como consertar um erro OOM (memória insuficiente) do Apache Hive sem ao processar tabelas grandes definindo as configurações de memória do Hive.
Executar a consulta do Apache Hive em tabelas grandes
Um cliente executou uma consulta do Hive:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Algumas nuances desta consulta:
- T1 é um alias para uma grande tabela, TABLE1, com vários tipos de coluna STRING.
- Outras tabelas não são tão grandes, mas têm muitas colunas.
- Todas as tabelas estão associadas umas às outras, em alguns casos com várias colunas em TABLE 1 e em outras.
A consulta do Hive demorou 26 minutos para ser concluída em um cluster HDInsight A3 de 24 nós. O cliente percebeu as seguintes mensagens de aviso:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Usando o mecanismo de execução Apache Tez. A mesma consulta foi executada por 15 minutos e depois lançou o seguinte erro:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
O erro permanece ao usar uma máquina virtual maior (por exemplo, D12).
Depurar o erro de memória insuficiente
Nosso suporte e as equipes de engenharia juntos descobriram que um dos problemas que causou o erro de memória insuficiente era um problema conhecido descrito no Apache JIRA:
"Quando hive.auto.convert.join.noconditionaltask = true, verificamos noconditionaltask.size e, se a soma dos tamanhos de tabelas na junção do mapa for menor que noconditionaltask.size, o plano vai gerar uma junção de mapa. O problema disso é que o cálculo não leva em conta a sobrecarga introduzida por uma implementação diferente de HashTable. Como resultado, se a soma dos tamanhos de entrada for menor do que o tamanho de noconditionaltask por uma pequena margem, as consultas enfrentarão um erro de falta de memória."
O hive.auto.convert.join.noconditionaltask no arquivo hive-site.xml estava definido como true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
É provável que junção de mapa tenha sido a causa do erro de falta de memória do Java Heap Space. Conforme explicado na postagem no blog Configurações de memória Yarn do Hadoop no HDInsight, quando o mecanismo de execução Tez é usado, o espaço de heap usado pertence, na verdade, ao contêiner do Tez. Confira a imagem a seguir que descreve a memória do contêiner Tez.
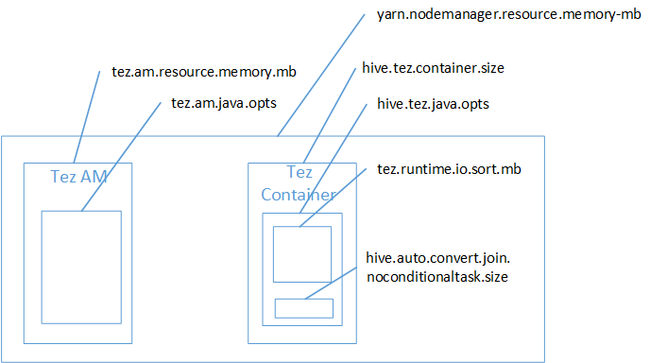
Como sugere a postagem no blog, as duas configurações de memória a seguir definem a memória de contêiner para o heap: hive.tez.container.size e hive.tez.java.opts. Em nossa experiência, a exceção de falta de memória não significa que o tamanho do contêiner seja muito pequeno. Isso significa que o tamanho do heap de Java (hive.tez.java.opts) é muito pequeno. Portanto, sempre que você vir falta de memória, poderá tentar aumentar hive.tez.java.opts. Se necessário, pode ser que você precise aumentar hive.tez.container.size. A configuração java.opts deve ser aproximadamente 80% do container.size.
Observação
A configuração hive.tez.java.opts deve ser menor que hive.tez.container.size.
Como uma máquina D12 tem 28 GB de memória, decidimos usar um tamanho de contêiner de 10 GB (10.240 MB) e atribuir 80% para java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Com as novas configurações, a consulta foi executada com êxito em menos de dez minutos.
Próximas etapas
O recebimento de um erro de memória insuficiente não significa necessariamente que o tamanho do contêiner é muito pequeno. Em vez disso, você deve definir as configurações de memória para que o tamanho do heap seja aumentado para pelo menos 80% do tamanho da memória do contêiner. Para otimizar consultas do Hive, veja Otimizar consultas do Apache Hive para Apache Hadoop no HDInsight.