Usar o Apache Zeppelin para executar consultas do Apache Phoenix pelo Apache HBase no Azure HDInsight
Apache Phoenix é um banco de dados relacional livre e paralelo em massa criado em camadas em HBase. O Phoenix permite que você use consultas como SQL no HBase. O Phoenix usa drivers JDBC para permitir que você crie, exclua, altere tabelas SQL, índices, exibições e sequências. Você também pode usar o Phoenix para atualizar linhas individualmente e em massa. O Phoenix usa uma compilação nativa NOSQL, em vez de usar o MapReduce para compilar consultas, permitindo a criação de aplicativos de baixa latência sobre HBase.
O Apache Zeppelin é um notebook baseado na Web de software livre que permite que você crie documentos colaborativos controlados por dados usando análises de dados interativas e linguagens como SQL e Scala. Ele ajuda os desenvolvedores de dados e cientistas de dados a desenvolver, organizar, executar e compartilhar código para manipulação de dados. Ele permite visualizar os resultados sem referir-se à linha de comando ou precisar dos detalhes do cluster.
Os usuários do HDInsight podem usar o Apache Zeppelin para consultar tabelas Phoenix. O Apache Zeppelin é integrado ao cluster HDInsight e não há etapas adicionais para usá-lo. Crie um Notebook Zeppelin com o interpretador JDBC e começar a gravar as consultas SQL Phoenix
Pré-requisitos
Um cluster do Apache HBase no HDInsight. Veja Introdução ao Apache HBase.
Criar uma anotação do Apache Zeppelin
Substitua
CLUSTERNAMEpelo nome do cluster na seguinte URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Em seguida, insira a URL em um navegador da Web. Insira o nome de usuário e a senha de logon do cluster.Na página Zeppelin, selecione Criar nova anotação.
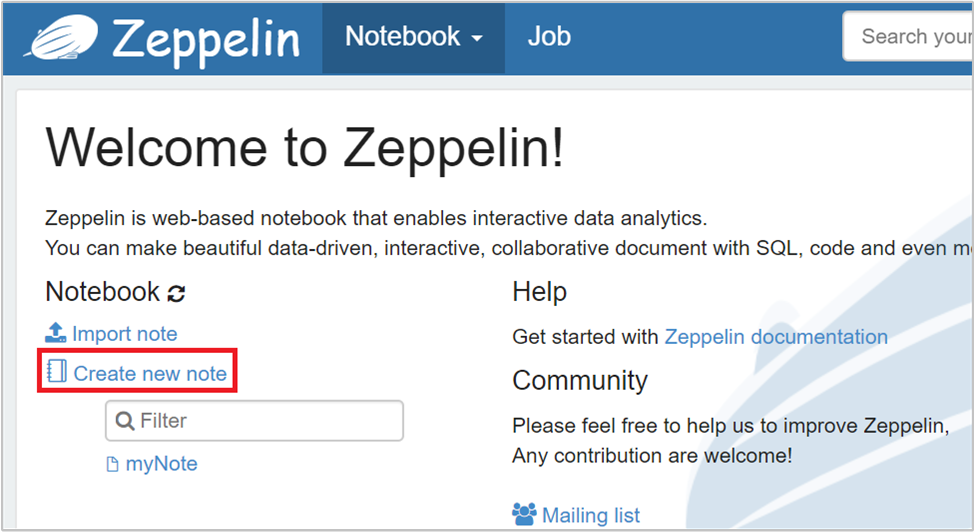
Na caixa de diálogo Criar anotação, digite ou selecione os seguintes valores:
- Nome da anotação: digite o nome da anotação.
- Interpretador padrão: selecione jdbc na lista suspensa.
Em seguida, selecione Criar Anotação.
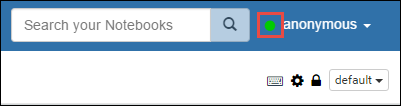
Verifique se o cabeçalho do notebook mostra um status conectado. Isso é indicado por um ponto verde no canto superior direito.
Crie uma tabela do HBase. Insira o comando a seguir e pressione Shift + Enter:
%jdbc(phoenix) CREATE TABLE Company ( company_id INTEGER PRIMARY KEY, name VARCHAR(225) );A instrução %jdbc(hive) na primeira linha informa o notebook para usar o interpretador JDBC do Phoenix.
Veja as tabelas criadas.
%jdbc(phoenix) SELECT DISTINCT table_name FROM SYSTEM.CATALOG WHERE table_schem is null or table_schem <> 'SYSTEM';Insira os valores na tabela.
%jdbc(phoenix) UPSERT INTO Company VALUES(1, 'Microsoft'); UPSERT INTO Company (name, company_id) VALUES('Apache', 2);Consulte a tabela.
%jdbc(phoenix) SELECT * FROM Company;Exclua um registro.
%jdbc(phoenix) DELETE FROM Company WHERE COMPANY_ID=1;Descarte a tabela.
%jdbc(phoenix) DROP TABLE Company;