Criar a tabela do Apache Kafka® no Apache Flink® no Azure HDInsight no AKS
Observação
Desativaremos o Microsoft Azure HDInsight no AKS em 31 de janeiro de 2025. Para evitar o encerramento abrupto das suas cargas de trabalho, você precisará migrá-las para o Microsoft Fabric ou para um produto equivalente do Azure antes de 31 de janeiro de 2025. Os clusters restantes em sua assinatura serão interrompidos e removidos do host.
Somente o suporte básico estará disponível até a data de desativação.
Importante
Esse recurso está atualmente na visualização. Os Termos de uso complementares para versões prévias do Microsoft Azure incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, confira Informações sobre a versão prévia do Azure HDInsight no AKS. Caso tenha perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para ver mais atualizações sobre a Comunidade do Azure HDInsight.
Usando esse exemplo, aprenda a criar a tabela Kafka no Apache FlinkSQL.
Pré-requisitos
Conector SQL do Kafka no Apache Flink
O conector do Kafka permite ler dados e gravar dados em tópicos do Kafka. Para obter mais informações, consulte Conector SQL do Apache Kafka.
Criar uma tabela do Kafka no SQL do Flink
Preparar tópicos e dados no Kafka do HDInsight
Preparar mensagens com weblog.py
import random
import json
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://google.com',
'https://facebook.com?id=1',
'https://tmall.com',
'https://baidu.com',
'https://taobao.com',
'https://aliyun.com',
'https://apache.com',
'https://flink.apache.com',
'https://hbase.apache.com',
'https://github.com',
'https://gmail.com',
'https://stackoverflow.com',
'https://python.org'
]
def main():
while True:
if random.randrange(10) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
Tópico pipeline para Kafka
sshuser@hn0-contsk:~$ python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Outros comandos:
-- create topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- consume topic
sshuser@hn0-contsk:~$ /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Tom", "visitURL": "https://stackoverflow.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Chunck", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Chunck", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Andrew", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Pick", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Mike", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Zheng Hu", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Luke", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:44"}
Cliente SQL do Apache Flink
Fornecemos instruções detalhadas sobre como usar o Secure Shell para o cliente do Flink SQL.
Baixar o Conector e Dependências do SQL do Kafka SQL no SSH
Estamos usando as dependências do Kafka 3.2.0 na etapa abaixo. É obrigatório atualizar o comando com base na sua versão do Kafka no cluster do Azure HDInsight.
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.2.0/kafka-clients-3.2.0.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.17.0/flink-connector-kafka-1.17.0.jar
Conectar-se ao Cliente SQL do Apache Flink
Agora vamos nos conectar ao Cliente do Flink SQL com jars do cliente do Kafka SQL.
msdata@pod-0 [ /opt/flink-webssh ]$ bin/sql-client.sh -j flink-connector-kafka-1.17.0.jar -j kafka-clients-3.2.0.jar
Criar tabela Kafka no SQL do Apache Flink
Vamos criar a tabela Kafka no SQL do Flink e selecionar a tabela Kafka no SQL do Flink.
Você precisa atualizar seus IPs de servidor de inicialização do Kafka no trecho de código abaixo.
CREATE TABLE KafkaTable (
`userName` STRING,
`visitURL` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'click_events',
'properties.bootstrap.servers' = '<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092',
'properties.group.id' = 'my_group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
select * from KafkaTable;
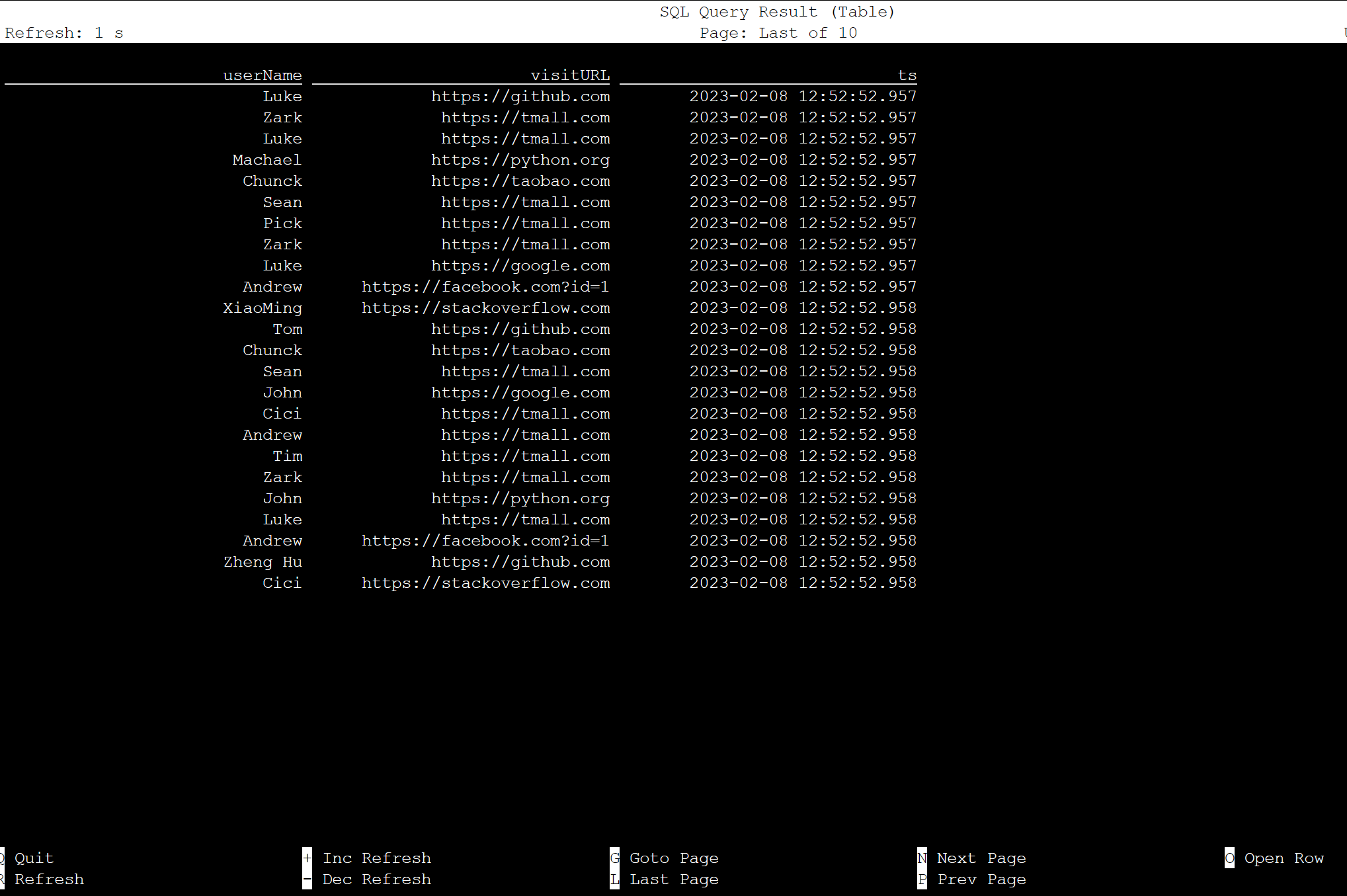
Produzir mensagens Kafka
Agora, vamos produzir mensagens Kafka para o mesmo tópico, usando o Kafka do HDInsight.
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
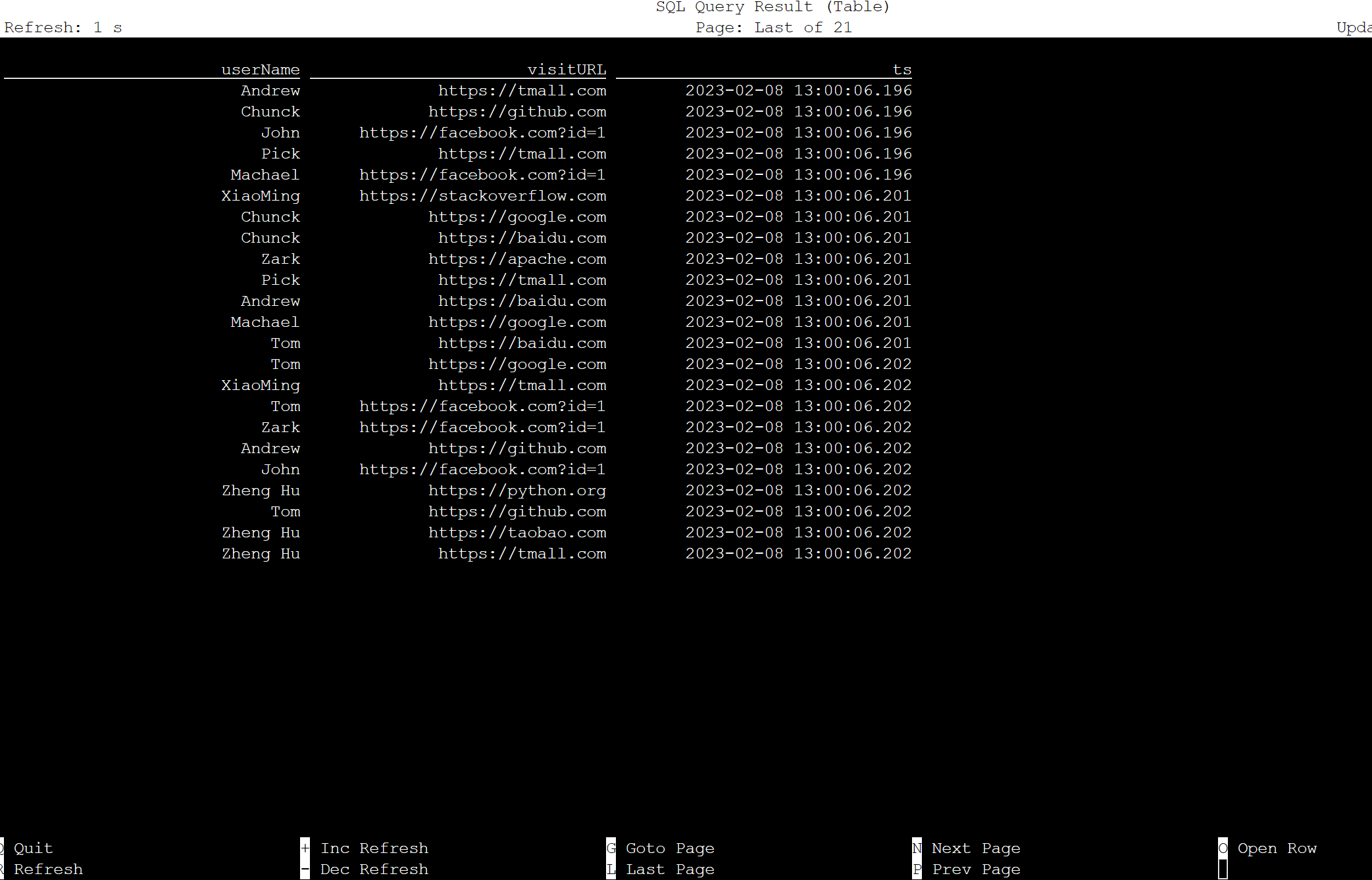
Tabela no SQL do Apache Flink
Você pode monitorar a tabela no Flink SQL.
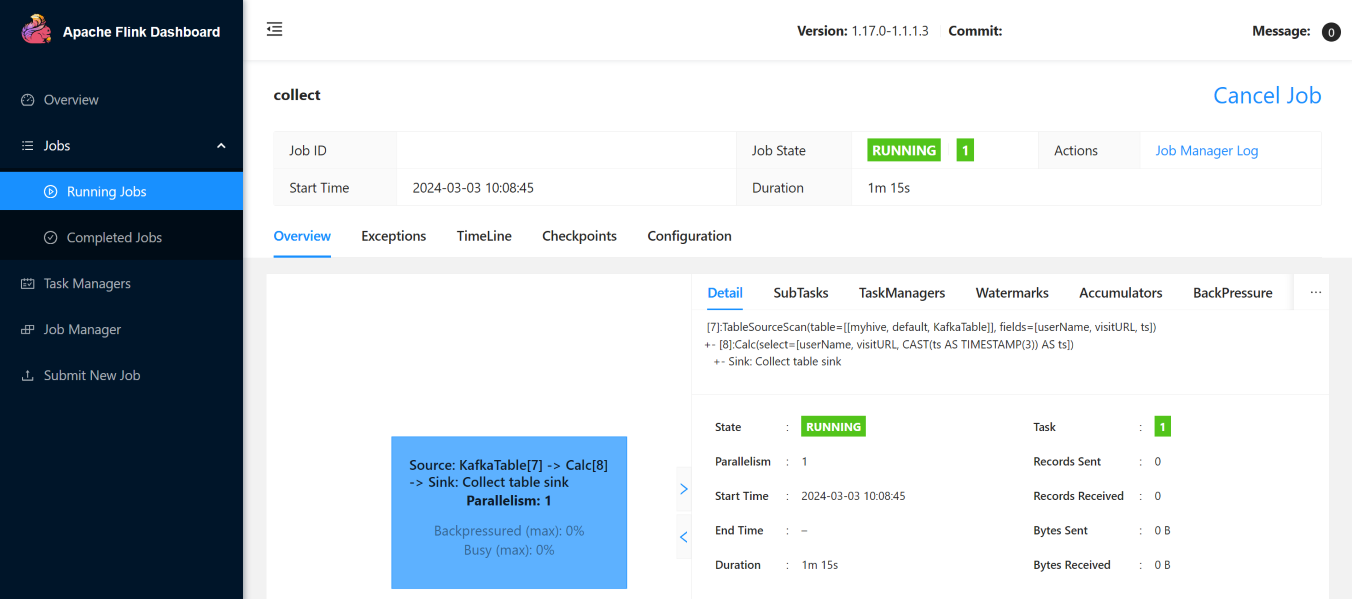
Aqui estão os trabalhos de streaming na interface do usuário da Web do Flink.
Referência
- Conector do SQL do Apache Kafka
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas registradas da Apache Software Foundation (ASF).