Obter recomendações do Azure para migrar seu banco de dados SQL Server
A extensão da Migração de SQL do Azure para Azure Data Studio ajuda você a avaliar os requisitos do banco de dados, obter as recomendações de SKU na medida certa para recursos do Azure e migrar o banco de dados SQL Server para o Azure.
Saiba como usar essa experiência unificada, coletando dados de desempenho da instância do SQL Server de origem para obter as recomendações do Azure ideais para seus destinos do SQL do Azure.
Visão geral
Antes de migrar para o SQL do Azure, você pode usar a extensão de Migração de SQL no Azure Data Studio para ajudar a gerar as recomendações ideais para o Banco de Dados SQL do Azure, a Instância Gerenciada de SQL do Azure e o SQL Server em destinos de Máquinas Virtuais do Azure. A ferramenta ajuda você a coletar dados de desempenho da instância do SQL de origem (em execução local ou em outra nuvem) e recomendar uma configuração de computação e armazenamento para atender às necessidades da sua carga de trabalho.
O diagrama apresenta o fluxo de trabalho para recomendações do Azure na extensão de Migração de SQL do Azure para o Azure Data Studio:

Observação
O recurso de avaliação e de recomendação do Azure na extensão de Migração de SQL do Azure para o Azure Data Studio oferece suporte às instâncias do SQL Server de origem em execução no Windows ou Linux.
Pré-requisitos
Para obter uma introdução de recomendações do Azure para a migração de banco de dados do SQL Server, é necessário atender aos seguintes pré-requisitos:
Instale a extensão de Migração do SQL do Azure do Marketplace do Azure Data Studio.
O logon usado para conectar a instância do SQL Server de origem deve ter as permissões mínimas.
Origens e destinos com suporte
As recomendações do Azure podem ser geradas para as seguintes versões do SQL Server:
- Há suporte para o SQL Server 2008 e versões posteriores no Windows ou Linux.
- O SQL Server em execução em outras nuvens pode ter suporte, mas a precisão dos resultados pode variar
As recomendações do Azure podem ser geradas para os seguintes destinos do SQL do Azure:
- Banco de Dados SQL do Azure
- Famílias de hardware: série Standard (Gen5)
- Camadas de serviço: Uso Geral, Comercialmente Crítico, Hiperescala
- Instância Gerenciada de SQL do Azure
- Famílias de hardware: série Standard (Gen5), série Premium, série Premium com otimização de memória
- Camadas de serviço: Uso Geral, Comercialmente Crítico
- SQL Server na Máquina Virtual do Azure
- Famílias de VM: uso geral, com otimização de memória
- Famílias de armazenamento: SSD Premium
Coleta de dados de desempenho
Para que as recomendações possam ser geradas, os dados de desempenho precisam ser coletados da instância do SQL Server de origem. Durante essa etapa de coleta de dados, várias DMVs (exibições dinâmicas do sistema) da instância do SQL Server são consultadas para capturar as características de desempenho da carga de trabalho. A ferramenta captura métricas incluindo uso de CPU, memória, armazenamento e E/S a cada 30 segundos e salva os contadores de desempenho localmente em seu computador como um conjunto de arquivos CSV.
Nível de instância
Esses dados de desempenho são coletados uma vez por instância do SQL Server:
| Dimensão de desempenho | Descrição | DMV (exibição de gerenciamento dinâmico) |
|---|---|---|
SqlInstanceCpuPercent |
A quantidade de CPU que o processo do SQL Server estava usando, como um percentual | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Volume de memória geral do processo do SQL Server | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Utilização de memória do SQL Server | sys.dm_os_process_memory |
Nível de banco de dados
| Dimensão de desempenho | Descrição | DMV (exibição de gerenciamento dinâmico) |
|---|---|---|
DatabaseCpuPercent |
O percentual total de CPU usado por um banco de dados | sys.dm_exec_query_stats |
CachedSizeInMb |
Tamanho total, em Megabytes, de cache usado por um banco de dados | sys.dm_os_buffer_descriptors |
Nível de arquivo
| Dimensão de desempenho | Descrição | DMV (exibição de gerenciamento dinâmico) |
|---|---|---|
ReadIOInMb |
O número total de megabytes lidos deste arquivo | sys.dm_io_virtual_file_stats |
WriteIOInMb |
O número total de megabytes gravados neste arquivo | sys.dm_io_virtual_file_stats |
NumOfReads |
O número total de leituras emitidas neste arquivo | sys.dm_io_virtual_file_stats |
NumOfWrites |
O número total de gravações emitidas neste arquivo | sys.dm_io_virtual_file_stats |
ReadLatency |
A latência de leitura de E/S neste arquivo | sys.dm_io_virtual_file_stats |
WriteLatency |
A latência de gravação de E/S neste arquivo | sys.dm_io_virtual_file_stats |
Um mínimo de 10 minutos de coleta de dados é necessário para que uma recomendação possa ser gerada, mas para avaliar com precisão sua carga de trabalho, é recomendável que você execute a coleta de dados por um período suficientemente longo a fim de capturar o uso no pico e fora do pico.
Para iniciar o processo de coleta de dados, comece conectando-se à instância do SQL de origem no Azure Data Studio e inicie o assistente de Migração de SQL. Na etapa 2, selecione "Obter recomendação do Azure". Selecione "Coletar dados de desempenho agora" e selecione uma pasta no computador em que os dados coletados serão salvos.
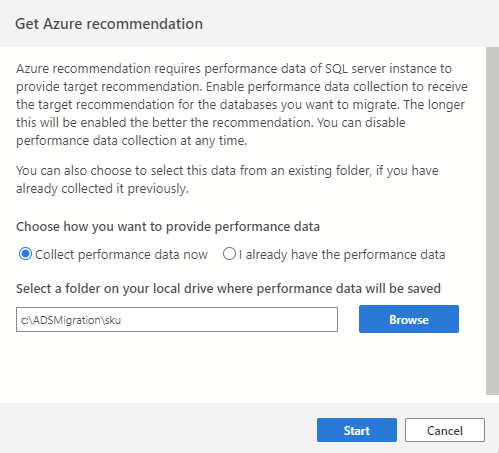
O processo de coleta de dados é executado por 10 minutos a fim de gerar a primeira recomendação. É importante iniciar o processo de coleta de dados quando a carga de trabalho do banco de dados ativo refletir o uso semelhante aos dos seus cenários de produção.
Depois que a primeira recomendação for gerada, você poderá continuar a executar o processo de coleta de dados para refinar as recomendações. Essa opção será especialmente útil se os padrões de uso variarem ao longo do tempo.
O processo de coleta de dados começa quando você seleciona Iniciar. A cada 10 minutos, os pontos de dados coletados são agregados e o máximo, a média e a variação de cada contador serão gravados em disco em um conjunto de três arquivos CSV.
Normalmente, você observa um conjunto de arquivos CSV com os seguintes sufixos na pasta:
SQLServerInstance_CommonDbLevel_Counters.csv: contém dados de configuração estáticos sobre o layout do arquivo de banco de dados e os metadados.SQLServerInstance_CommonInstanceLevel_Counters.csv: contém dados estáticos sobre a configuração de hardware da instância do servidor.SQLServerInstance_PerformanceAggregated_Counters.csv: contém dados agregados de desempenho que são atualizados com frequência.
Durante esse tempo, deixe o Azure Data Studio aberto, embora você possa continuar com outras operações. A qualquer momento, você pode interromper o processo de coleta de dados retornando para esta página e selecionando Parar coleta de dados.
Como gerar as recomendações ideais
Se você já tiver coletado dados de desempenho de uma sessão anterior ou usando uma ferramenta diferente (como o Assistente de Migração de Banco de Dados), importe os dados de desempenho existentes selecionando a opção Já tenho os dados de desempenho. Prossiga para selecionar a pasta na qual os dados de desempenho (três arquivos .csv) são salvos e selecione Iniciar para iniciar o processo de recomendação.
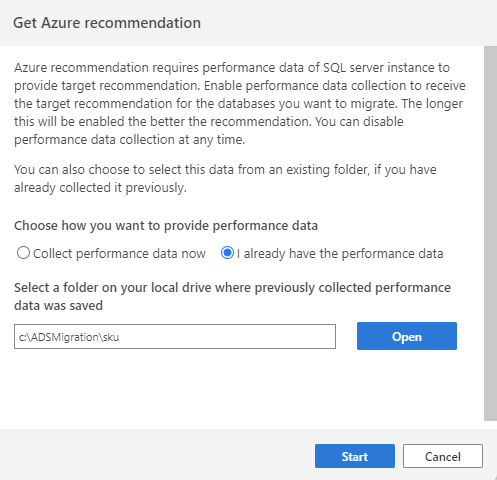
A primeira etapa do assistente de Migração de SQL pede que você selecione um conjunto de bancos de dados para avaliar e esses são os únicos bancos de dados que serão levados em consideração durante o processo de recomendação.
No entanto, o processo de coleta de dados de desempenho coleta contadores de desempenho para todos os bancos de dados da instância do SQL Server de origem, não apenas os que foram selecionados.
Isso significa que os dados de desempenho coletados anteriormente podem ser usados para regenerar repetidamente recomendações para um subconjunto diferente de bancos de dados especificando uma lista diferente na primeira etapa.
Parâmetros de recomendação
Há várias definições configuráveis que podem afetar suas recomendações.

Selecione a opção Editar parâmetros para ajustar esses parâmetros de acordo com suas necessidades.
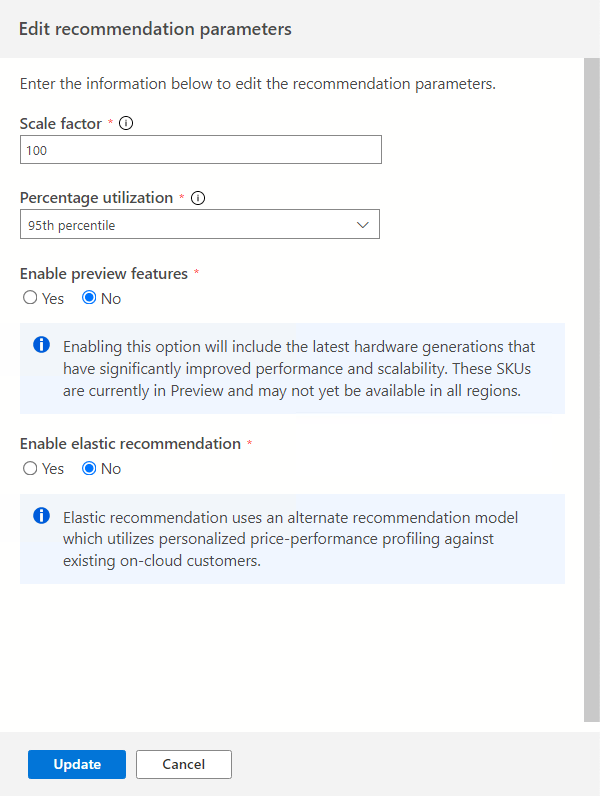
Fator de escala:
Essa opção permite que você forneça um buffer a ser aplicado a cada dimensão de desempenho. Essa opção detecta problemas como uso sazonal, histórico de baixo desempenho e prováveis aumentos no uso futuro. Por exemplo, se você determinar que um requisito de CPU de quatro vCore tem um fator de escala de 150%, o verdadeiro requisito de CPU é de seis vCores.
O volume de fator de escala padrão é de 100%.
Utilização percentual:
O percentil de pontos de dados a ser usado como dados de desempenho é agregado.
O valor padrão é o 95º percentil.
Habilitar versão prévia de recursos:
Essa opção permite que as configurações que talvez ainda não estejam disponíveis para todos os usuários em todas as regiões sejam recomendadas.
Por padrão, essa opção é desativada.
Habilitar a recomendação elástica:
Essa opção utiliza um modelo alternativo de recomendação que utiliza um perfil de preço e desempenho personalizado em relação aos clientes existentes na nuvem.
Por padrão, essa opção é desativada.
O processo de coleta de dados é encerrado se você fechar o Azure Data Studio. Os dados que foram coletados até esse ponto são salvos em sua pasta.
Se você fechar o Azure Data Studio enquanto a coleta de dados estiver em andamento, use uma das seguintes opções para reiniciar a coleta de dados:
Reabra o Azure Data Studio e importe os arquivos de dados salvos para sua pasta local. Em seguida, gere uma recomendação dos dados coletados.
Reabra o Azure Data Studio e inicie a coleta de dados novamente usando o assistente de migração.
Permissões mínimas
Para consultar as exibições necessárias do sistema para coleta de dados de desempenho, permissões específicas são necessárias para o logon do SQL Server usado para essa tarefa. Você pode criar um usuário com privilégios mínimos para avaliação e coleta de dados de desempenho usando o seguinte script:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Cenários e limitações sem suporte
As Recomendações do Azure não incluem estimativas de preço, pois essa situação pode variar dependendo da região, da moeda e dos descontos, como o Benefício Híbrido do Azure. Para obter estimativas de preço, use a Calculadora de Preços do Azure ou crie uma Avaliação do SQL no serviço Migrações para Azure.
Não há suporte para recomendações para o Banco de Dados SQL do Azure com o modelo de compra baseado em DTU.
Atualmente, não há suporte para recomendações do Azure para a camada de computação sem servidor do Banco de Dados SQL do Azure e de Pools Elásticos.
Solucionar problemas
- Nenhuma recomendação gerada
- Se nenhuma recomendação tiver sido gerada, essa situação poderá significar que nenhuma configuração foi identificada, o que pode atender totalmente aos requisitos de desempenho da instância de origem. Para ver os motivos pelos quais uma família de hardware, camada de serviço ou tamanho específico foi desclassificada:
- Acesse os logs do Azure Data Studio acessando Ajuda > Mostrar Todos os Comandos > Abrir Pasta de Logs de Extensão
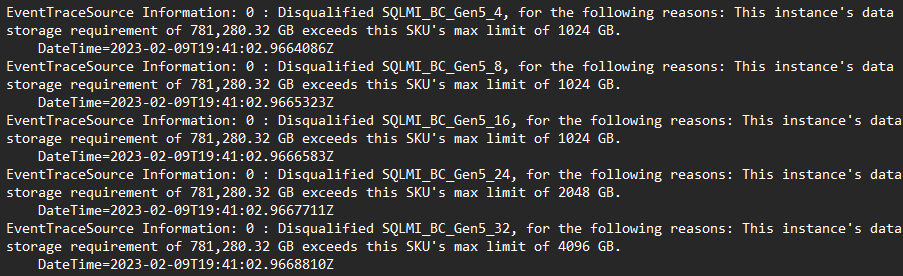
- Navegue até Microsoft.mssql > SqlAssessmentLogs > e abra o SkuRecommendationEvent.log
- O log contém um rastreamento de todas as configurações potenciais que foram avaliadas e o motivo pelo qual ela foi/não foi considerada uma configuração qualificada:
- Tente regenerar a recomendação com a recomendação elástica habilitada. Essa opção utiliza um modelo alternativo de recomendação que utiliza um perfil de preço e desempenho personalizado em relação aos clientes existentes na nuvem.
- Se nenhuma recomendação tiver sido gerada, essa situação poderá significar que nenhuma configuração foi identificada, o que pode atender totalmente aos requisitos de desempenho da instância de origem. Para ver os motivos pelos quais uma família de hardware, camada de serviço ou tamanho específico foi desclassificada:
