Tutorial: Migrar o Oracle WebLogic Server para o AKS (Serviço de Kubernetes do Azure) com redundância geográfica
Este tutorial é uma maneira direta e eficaz de implementar uma estratégia de continuidade dos negócios e recuperação de desastres (DR) para um ambiente Java usando o Oracle WebLogic Server (WLS) no AKS (Serviço de Kubernetes do Azure). A solução ilustra como fazer backup e restauração de uma carga de trabalho WLS usando um aplicativo Jakarta EE orientado por banco de dados simples em execução no AKS. A redundância geográfica é um tópico complexo, com muitas soluções possíveis. A melhor solução dependerá das suas necessidades específicas. Para conhecer outras maneiras de implementar a redundância geográfica, consulte os recursos ao final deste artigo.
Neste tutorial, você aprenderá a:
- Use as práticas recomendadas otimizadas do Azure para entender a alta disponibilidade e recuperação de desastre (HA/DR).
- Configure um grupo de failover do Banco de Dados SQL do Microsoft Azure em regiões associadas.
- Instalar e configurar clusters WLS primários no AKS.
- Configure a redundância geográfica usando o Backup do Azure.
- Restaure um cluster WLS em uma região secundária.
- Configure um Gerenciador de Tráfego do Azure.
- Testar o failover.
O diagrama a seguir ilustra a arquitetura que você cria:

O Gerenciador de Tráfego do Azure verifica a integridade de suas regiões e roteia o tráfego de acordo com a camada de aplicativo. A região primária tem uma implantação completa do cluster WLS. Somente a região primária está entregando ativamente solicitações de rede dos usuários. A região secundária restaura o cluster WLS de backups da região primária quando há um desastre ou evento de DR declarado. A região secundária se mantém ativada para receber tráfego apenas quando a região primária apresenta uma interrupção do serviço.
O Gerenciador de Tráfego do Azure usa o recurso de verificação de integridade do Gateway de Aplicativo do Azure e do WKO (Operador de Kubernetes WebLogic) para implementar esse roteamento condicional. O WKO se integra totalmente às verificações de integridade do AKS, permitindo que o Gerenciador de Tráfego do Azure tenha um alto nível de reconhecimento da integridade da carga de trabalho do Java. O cluster primário WLS se mantém em execução e o cluster secundário é desligado.
O RTO (objetivo de tempo de recuperação) de failover geográfico da camada de aplicativo depende do tempo para iniciar o AKS e executar o cluster WLS secundário, que normalmente não passa de uma hora. Os dados do aplicativo persistem e replicam no grupo de failover do Banco de Dados SQL do Azure, com um RTO e um RPO (objetivo de ponto de recuperação) de minutos ou horas. Nessa arquitetura, o backup do Azure tem apenas um backup padrão do cofre para a configuração do WLS todos os dias. Para saber mais, acesse O que é o backup do Serviço de Kubernetes do Azure (AKS)?
A camada do banco de dados consiste em um grupo de failover do Banco de Dados SQL do Azure com um servidor primário e um servidor secundário. O servidor primário está no modo de leitura/gravação ativo e conectado ao cluster WLS primário. O servidor secundário está no modo passivo somente leitura e conectado ao cluster WLS secundário. Um failover geográfico alterna todos os bancos de dados secundários no grupo para a função primária. Para RPO de failover geográfico e RTO do Banco de Dados SQL do Azure, consulte Visão geral da continuidade dos negócios.
Este artigo foi escrito com o serviço de Banco de Dados SQL do Azure porque se baseia nos recursos de HA (alta disponibilidade) desse serviço. Há outras opções de banco de dados possíveis, mas você deve considerar os recursos de HA de qualquer banco de dados escolhido. Para obter mais informações, incluindo como otimizar a configuração de fontes de dados para replicação, consulte Configurar fontes de dados para implantação ativa-passiva do Oracle Fusion Middleware.
Este artigo usa o Backup do Azure para proteger o AKS. Para conhecer a disponibilidade de regiões, os cenários compatíveis e as limitações, consulte a Matriz de suporte para backup do Serviço de Kubernetes do Azure. Atualmente, o Backup do Azure dá suporte a backups de camadas do cofre e restauração entre regiões, que estão disponíveis em versão prévia pública. Para obter mais informações, consulte Habilitar backups de camadas do cofre para o AKS e restauração entre regiões usando o Backup do Azure.
Observação
Neste artigo, você deve criar identificadores exclusivos com frequência para vários recursos. Este artigo usa a convenção de <initials><sequence-number> como prefixo. Por exemplo, seu nome é Emily Juanita Bernal, então, seu identificador exclusivo seria ejb01. Para fins de mais desambiguidade, você pode anexar a data de hoje no formato MMDD, como ejb010307.
Pré-requisitos
Uma assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Verifique se você tem as funções
OwnerouContributoreUser Access Administratorna assinatura. Você pode verificar a atribuição pelas etapas em Listar atribuições de função do Azure usando o portal do Azure.Prepare uma máquina local com Windows, Linux ou macOS instalado.
Instale a CLI do Azure versão 2.54.0 ou posterior para executar seus comandos.
Instale e configure kubectl.
Instale e configure o Git.
Instale uma implementação do Java SE, versão 17 ou posterior; por exemplo, o build da Microsoft do OpenJDK.
Instale o Maven, versão 3.9.3 ou posterior.
Tenha as credenciais para uma conta de SSO (logon único) da Oracle. Para criar uma, consulte Criar conta Oracle.
Siga estas etapas para aceitar os termos de licença do WLS:
- Acesse o Registro de Contêiner Oracle e entre.
- Se você tiver um direito de suporte, selecione Middleware e, em seguida, pesquise e selecione weblogic_cpu.
- Se você não tiver um direito de suporte da Oracle, selecione Middleware e, em seguida, pesquise e selecione weblogic.
- Aceite o contrato de licença.
Para executar o WLS no AKS, é preciso entender os domínios do WLS. Para obter mais informações sobre domínios do WLS, consulte a seção Decidir se deseja usar a oferta predefinida do Azure Marketplace de Migrar aplicativos do WebLogic Server para o Serviço de Kubernetes do Azure. Este artigo pressupõe que você esteja executando o WLS no AKS usando o modelo no tipo de origem inicial do domínio de imagem, com logs de transações e repositórios em um banco de dados externo sem armazenamento externo.
Configurar um grupo de failover do Banco de Dados SQL do Azure em regiões associadas
Nesta seção, você cria um grupo de failover do Banco de Dados SQL do Azure em regiões associadas para uso com seus clusters e aplicativo WLS. Em uma seção posterior, você configura o WLS para armazenar seus dados de sessão e dados de log de transações (TLOG) nesse banco de dados. Essa prática é consistente com a Arquitetura de Disponibilidade Máxima (MAA) da Oracle. Esta orientação fornece uma adaptação do Azure para MAA. Para obter mais informações sobre MAA, consulte Arquitetura de Disponibilidade Máxima da Oracle.
Primeiro, crie o Banco de Dados primário do SQL do Azure seguindo as etapas do portal do Azure em Início Rápido: criar um banco de dados individual - Banco de Dados SQL do Azure. Siga as etapas até, mas não incluindo, a seção "Limpar recursos". Use as instruções a seguir ao ler o artigo e, em seguida, retorne a este artigo depois de criar e configurar o Banco de Dados SQL do Azure:
Quando você chegar à seção Criar um banco de dados individual, siga estas etapas:
- Na etapa 4 para criar um novo grupo de recursos, salve o valor Nome do grupo de recursos; por exemplo myResourceGroup.
- Na etapa 5 para o nome do banco de dados, salve o valor Nome do banco de dados; por exemplo, mySampleDatabase.
- Na etapa 6 para criar o servidor, sigas estas etapas:
- Salve o nome exclusivo do servidor; por exemplo, sqlserverprimary-ejb120623.
- Em Local, selecione (EUA) Leste dos EUA.
- Em Método de autenticação, selecione Usar autenticação do SQL.
- Salve o valor de Logon do administrador do servidor; por exemplo, azureuser.
- Salve o valor da Senha.
- Na etapa 8, em Ambiente de carga de trabalho, selecione Desenvolvimento. Leia a descrição e considere outras opções para sua carga de trabalho.
- Na etapa 11, em Redundância de armazenamento de backup, selecione Armazenamento de backup com redundância local. Considere outras opções para seus backups. Para obter mais informações, consulte a seção Redundância de armazenamento de backup de Backups automatizados no Banco de Dados SQL do Azure.
- Na etapa 14, na configuração de Regras de firewall, em Permitir que serviços e recursos do Azure acessem este servidor, selecione Sim.
Ao acessar a seção Consultar o banco de dados, siga estas etapas:
Na etapa 3, insira as informações de entrada do administrador do servidor de autenticação SQL para entrar.
Observação
Se a entrada falhar e gerar uma mensagem de erro semelhante a Cliente com endereço IP "xx.xx.xx.xx" não tem permissão para acessar o servidor, selecione IP da lista de permissões xx.xx.xx.xx no servidor <your-sqlserver-name> ao final da mensagem de erro. Aguarde até que as regras de firewall do servidor concluam a atualização e selecione OK novamente.
Depois de executar a consulta de exemplo na etapa 5, limpe o editor e crie tabelas.
Para criar o esquema, insira as seguintes consultas:
Para criar o esquema para o TLOG, insira a seguinte consulta:
create table TLOG_msp1_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp2_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp3_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp4_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp5_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table wl_servlet_sessions (wl_id VARCHAR(100) NOT NULL, wl_context_path VARCHAR(100) NOT NULL, wl_is_new CHAR(1), wl_create_time DECIMAL(20), wl_is_valid CHAR(1), wl_session_values VARBINARY(MAX), wl_access_time DECIMAL(20), wl_max_inactive_interval INTEGER, PRIMARY KEY (wl_id, wl_context_path));Depois de uma execução bem-sucedida, você verá a mensagem
Query succeeded: Affected rows: 0.Essas tabelas de banco de dados são usadas para armazenar dados de log de transações (TLOG) e sessão para seus clusters e aplicativos WLS. Para obter mais informações, consulte Usar um repositório TLOG JDBC e Usar um banco de dados para armazenamento persistente (persistência JDBC).
Para criar o esquema para o aplicativo de exemplo, insira a seguinte consulta:
CREATE TABLE COFFEE (ID NUMERIC(19) NOT NULL, NAME VARCHAR(255) NULL, PRICE FLOAT(32) NULL, PRIMARY KEY (ID)); CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT NUMERIC(28) NULL, PRIMARY KEY (SEQ_NAME));Depois de uma execução bem-sucedida, você verá a mensagem
Query succeeded: Affected rows: 0.
Você chegou ao fim do artigo "Início Rápido: Criar um banco de dados individual – Banco de Dados SQL do Azure".
Então, crie um grupo de failover do Banco de Dados SQL do Azure seguindo as etapas do portal do Azure em Configurar um grupo de failover para o Banco de Dados SQL do Azure. Você só precisa das seguintes seções: Criar grupo de failover e Testar recuperação panejada. Use as etapas a seguir ao ler o artigo e, em seguida, retorne a este artigo depois de criar e configurar o grupo de failover do Banco de Dados SQL do Azure:
Quando você chegar à seção Criar grupo de failover, use as seguintes etapas:
- Na etapa 5 para criar o grupo de failover, selecione a opção para criar um servidor secundário e execute as seguintes etapas:
- Insira e salve o nome do grupo de failover; por exemplo, failovergroupname-ejb120623.
- Insira e salve o nome exclusivo do servidor; por exemplo, sqlserversecondary-ejb120623.
- Digite o mesmo administrador e senha do servidor primário.
- Em Local, selecione uma região diferente daquela usada para o banco de dados primário.
- Verifique se Permitir que os serviços do Azure acessem o servidor está selecionado.
- Na etapa 5 para configurar os Bancos de dados dentro do grupo, selecione o banco de dados que você criou no servidor primário; por exemplo, mySampleDatabase.
- Na etapa 5 para criar o grupo de failover, selecione a opção para criar um servidor secundário e execute as seguintes etapas:
Depois de concluir todas as etapas na seção Testar recuperação panejada, mantenha a página do grupo de failover aberta e use-a para o teste de failover dos clusters WLS posteriormente.
Obter a string de conexão JDBC e o nome de usuário do administrador do banco de dados para o grupo de failover
As etapas a seguir orientam você a obter a string de conexão JDBC e o nome de usuário do banco de dados dentro do grupo de failover. Esses valores são diferentes daqueles correspondentes para o banco de dados primário.
No portal do Azure, localize o grupo de recursos em que você implantou o banco de dados primário.
Na lista de recursos, selecione o banco de dados primário com o tipo banco de dados SQL.
Em Configurações, selecione Cadeias de conexão.
Selecione JDBC.
Na área de texto, em JDBC (autenticação SQL), selecione o ícone de cópia para colocar o valor da string de conexão JDBC na área de transferência.
Cole o valor em um editor de texto. Você vai editá-lo em outra etapa.
Volte ao grupo de recursos.
Selecione o recurso do tipo SQL Server que contém o banco de dados que você acabou de observar nas etapas anteriores.
Em Gerenciamento de dados selecione Grupos de failover.
Na tabela no meio da página, selecione o grupo de failover.
Na área de texto, em Ponto de extremidade do ouvinte de leitura/gravação, selecione o ícone de cópia para colocar o valor da string de conexão JDBC na área de transferência.
Cole o valor em uma nova linha no editor de texto. Agora, o editor de texto deve ter linhas semelhantes ao exemplo a seguir:
jdbc:sqlserver://ejb010307db.database.windows.net:1433;database=ejb010307db;user=azureuser@ejb010307db;password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30; ejb010307failover.database.windows.netCrie uma linha usando as seguintes modificações:
Copie a primeira linha inteira.
Altere a parte do nome de host da URL para usá-lo a partir da linha do ponto de extremidade do ouvinte de leitura/gravação.
Remova tudo o que estiver depois do par
name=valueparadatabase. Ou seja, remova tudo, incluindo o que vem após;e imediatamente apósdatabase=ejb010307db.Quando terminar, a string deverá ser semelhante ao exemplo a seguir:
jdbc:sqlserver://ejb010307failover.database.windows.net:1433;database=ejb010307dbEsse valor é a string de conexão JDBC.
Ainda no editor de texto, extraia o nome de usuário do banco de dados obtendo o valor do parâmetro
userda string de conexão JDBC original e substituindo o nome do banco de dados pela primeira parte da linha do ponto de extremidade do ouvinte de leitura/gravação. Continuando no exemplo anterior, o valor seráazureuser@ejb010307failover. Esse valor é o nome de usuário do administrador do banco de dados.
Instalar e configurar os clusters WLS primários no AKS
Nesta seção, você vai criar um cluster WLS no AKS usando a oferta do Oracle WebLogic Server no AKS. O cluster no Leste dos EUA é o primário, configurado como cluster ativo.
Observação
Você encontra mais informações sobre a oferta do Oracle WebLogic Server no AKS nos seguintes artigos:
Preparar aplicativo de exemplo
Nesta seção, você cria e compacta um aplicativo CRUD Java/JakartaEE de amostra que você implanta e executa posteriormente em clusters WLS para teste de failover.
O aplicativo usa a persistência de sessão JDBC do WebLogic Server para armazenar dados de sessão HTTP. A fonte de dados jdbc/WebLogicCafeDB armazena os dados da sessão para habilitar o failover e o balanceamento de carga em um cluster de WebLogic Servers. Ele configura um esquema de persistência para persistir os dados do aplicativo coffee na mesma fonte de dados jdbc/WebLogicCafeDB.
Use as seguintes etapas para criar e compactar o exemplo:
Use os seguintes comandos para clonar o repositório de amostra e verificar a tag correspondente a este artigo:
git clone https://github.com/Azure-Samples/azure-cafe.git cd azure-cafe git checkout 20231206Se você vir uma mensagem sobre
Detached HEAD, pode ignorá-la com segurança.Use os seguintes comandos para acessar o diretório de exemplo e, em seguida, compilar e compactar o exemplo:
cd weblogic-cafe mvn clean package
Quando o pacote for gerado com êxito, ele estará em <parent-path-to-your-local-clone>/azure-cafe/weblogic-cafe/target/weblogic-cafe.war. Se você não vir o pacote, resolva o problema antes de continuar.
Crie uma conta de armazenamento e um contêiner de armazenamento para armazenar o aplicativo de exemplo
Use as etapas a seguir para criar um contêiner e uma conta de armazenamento. Algumas dessas etapas direcionam você para outros guias. Depois de concluir as etapas, você pode carregar um aplicativo de exemplo para implantar no WLS.
Entre no portal do Azure.
Crie uma conta de armazenamento seguindo as etapas em Criar uma conta de armazenamento. Use as seguintes especializações para os valores no artigo:
- Crie um um grupo de recursos para a conta de armazenamento:
- Em Região, selecione Leste dos EUA.
- Para Nome da conta de armazenamento, use o mesmo valor que o nome do grupo de recursos.
- Para Desempenho, selecione Standard.
- Em Redundância, selecione LRS (armazenamento com redundância local).
- As guias restantes não precisam de especializações.
Prossiga para validar e criar a conta e retorne a este artigo.
Crie um contêiner de armazenamento na conta de acordo com as etapas na seção Criar um contêiner de Início Rápido: carregar, baixar e listar blobs com o portal do Azure.
Usando o mesmo artigo, carregue o pacote azure-cafe/weblogic-cafe/target/weblogic-cafe.war que você criou anteriormente seguindo as etapas na seção Carregar um blob de blocos. Depois, retorne a este artigo.
Implantar o WLS no AKS
Siga as seguintes etapas para implantar o WLS no AKS:
Abra a oferta do Oracle WebLogic Server no AKS no navegador e selecione Criar. Você deve ver o painel Noções básicas da oferta.
Siga estas etapas para preencher o painel Noções básicas:
Certifique-se de que o valor mostrado em Assinatura seja o mesmo que tem as funções listadas na seção de pré-requisitos.
No campo Grupo de recursos, selecione Criar novo e preencha um valor exclusivo para o grupo de recursos; por exemplo, wlsaks-eastus-20240109.
Em Detalhes da instância, em Região, selecione Leste dos EUA.
Em Credenciais do WebLogic, forneça uma senha para a criptografia do Administrador do WebLogic e do Modelo do WebLogic, respectivamente. Salve o nome de usuário e a senha do Administrador do WebLogic.
Em Configuração Básica Opcional, em Aceitar padrões para configuração opcional?, selecione Não. A configuração opcional é exibida.
Em Prefixo de Nome para o Servidor Gerenciado, preencha msp. Você vai configurar a tabela WLS TLOG com o prefixo
TLOG_${serverName}_posteriormente. Este artigo cria uma tabela TLOG com o nomeTLOG_msp${index}_WLStore. Se quiser usar outro prefixo de nome de servidor gerenciado, verifique se o valor corresponde às Convenções de Nomenclatura de Tabela do Microsoft SQL Server e aos nomes de tabela reais.Deixe os padrões dos outros campos.
Selecione Avançar para acessar o painel AKS.
Em Seleção de imagem, forneça as seguintes informações:
- Para Nome de usuário para autenticação do Oracle Single Sign-On, preencha seu nome de usuário do Oracle SSO nas pré-condições.
- Para Senha para autenticação do Oracle Single Sign-On, preencha as credenciais do Oracle SSO nas pré-condições.
Realize as etapas a seguir em Aplicativo:
- Na seção Aplicativo, ao lado de Implantar um aplicativo?, selecione Sim.
- Ao lado de Pacote de aplicativos (.war, .ear, .jar), selecione Procurar.
- Comece a digitar o nome da conta de armazenamento criada na seção anterior. Quando a conta de armazenamento desejada for exibida, selecione-a.
- Selecione o contêiner de armazenamento na seção anterior.
- Marque a caixa de seleção ao lado de weblogic-cafe.war, que você carregou na seção anterior. Escolha Selecionar.
- Deixe os padrões dos outros campos.
Selecione Avançar.
Deixe os padrões no painel Configuração TLS/SSL e selecione Avançar para ir ao painel Balanceamento de Carga.

No painel Balanceamento de Carga, ao lado de Criar entrada para o Console de Administração, veja se não há um aplicativo com o caminho /console*, pois isso pode causar conflito com o caminho do Console de Administração, e selecione Sim.
Mantenha os padrões para os outros campos e selecione Avançar
Mantenha os valores padrão no painel DNS e selecione Avançar para ir ao painel Banco de Dados.
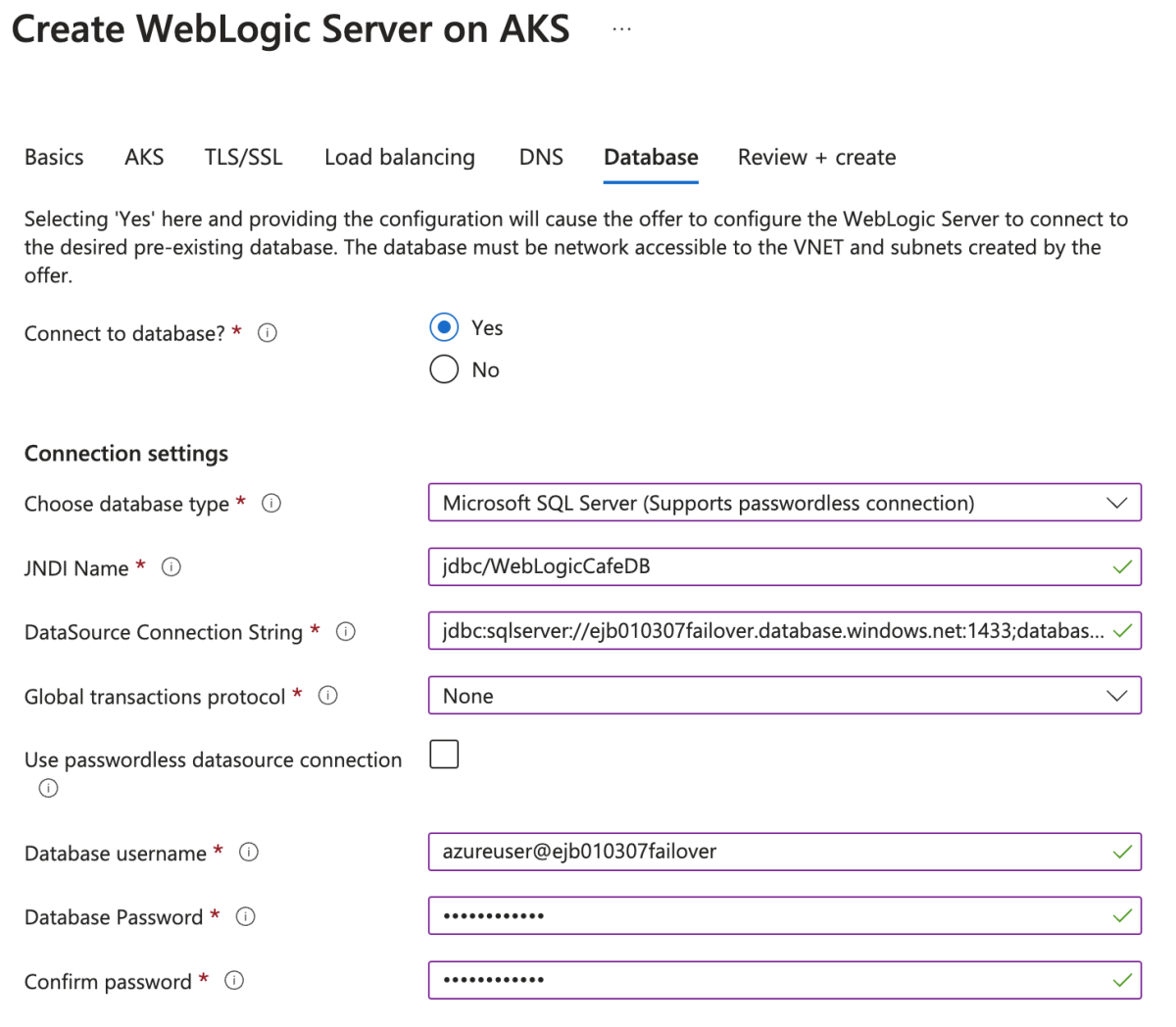
No painel Banco de Dados, insira os seguintes valores:
- Em Conectar a um banco de dados?, selecione Sim.
- Em Escolher tipo de banco de dados, selecione Microsoft SQL Server (Suporta conexão sem senha).
- Em Nome JNDI, digite jdbc/WebLogicCafeDB.
- Em String de Conexão de Fonte de Dados, cole o valor salvo para a String de conexão JDBC na seção Obter a string de conexão JDBC e o nome de usuário do administrador do banco de dados para o grupo de failover.
- Para Protocolo de transação global, selecione Nenhum.
- Em Nome de usuário do banco de dados, cole o valor salvo para Nome de usuário do administrador do banco de dados na seção Obter a string de conexão JDBC e o nome de usuário do administrador do banco de dados para o grupo de failover.
- Digite a senha de entrada do administrador do servidor de banco de dados que você salvou anteriormente para Senha do Banco de Dados. Insira o mesmo valor para Confirmar senha.
- Deixe os padrões dos outros campos.
Selecione Examinar + criar.
Aguarde até que Execução da validação final... seja concluída com êxito e selecione Criar. Depois de alguns instantes, você deverá ver a página Implantação, onde Implantação em andamento é exibido.






Observação
Se você encontrar problemas durante a Execução da validação final..., corrija-o e tente novamente.
Dependendo das condições da rede e de outras atividades na região selecionada, a implantação pode levar até 70 minutos para ser concluída. Depois disso, você deverá ver o texto Sua implantação está concluída exibido na página de implantação.
Configurar o armazenamento de dados TLOG
Nesta seção, você configura o armazenamento de dados TLOG substituindo o modelo de imagem WLS por um ConfigMap. Para obter mais informações sobre ConfigMap, consulte Modelo ConfigMap das ferramentas de implantação do WebLogic.
Esta seção requer um terminal Bash com a CLI do Azure e o kubectl instalados. Siga estas etapas para extrair o YAML necessário e configurar o armazenamento de dados TLOG:
Use as seguintes etapas para conectar ao cluster do AKS:
- Abra o portal do Azure e acesse o grupo de recursos provisionado na seção Implantar o WLS no AKS.
- Selecione o cluster do AKS na lista de recursos e, em seguida, selecione Conectar para se conectar ao cluster do AKS.
- Selecione CLI do Azure e siga as etapas para se conectar ao cluster do AKS em seu terminal local.
Siga estas etapas para obter a entrada do
topology:a partir do YAML do modelo de imagem WLS:- Abra o portal do Azure e acesse o grupo de recursos provisionado na seção Implantar o WLS no AKS.
- Selecione Configurações>Implantações. Selecione a primeira implantação, cujo nome começa com oracle.20210620-wls-on-aks.
- Selecione Saídas. Copie o valor shellCmdtoOutputWlsImageModelYaml na área de transferência. O valor é um comando shell que decodifica a cadeia de caracteres base64 do arquivo de modelo e salva o conteúdo em um arquivo chamado model.yaml.
- Cole o valor no terminal Bash e execute o comando para produzir o arquivo model.yaml.
- Edite o arquivo para remover todo o conteúdo, exceto a entrada
topology:de nível superior. Não deve haver entradas de nível superior em seu arquivo, excetotopology:. - Salve o arquivo.
Siga estas etapas para obter o nome e o nome
ConfigMape o nome do namespace do YAML do modelo de domínio WLS:Abra o portal do Azure e acesse o grupo de recursos que foi provisionado na seção Implantar o WLS no AKS .
Selecione Configurações>Implantações. Selecione a primeira implantação, cujo nome começa com oracle.20210620-wls-on-aks.
Selecione Saídas. Copie o valor de shellCmdtoOutputWlsDomainYaml na área de transferência. O valor é um comando shell para decodificar a cadeia de caracteres base64 do arquivo de modelo e salvar o conteúdo em model.yaml.
Cole o valor no terminal e você terá um arquivo chamado domain.yaml.
Procure no domain.yaml para obter os valores a seguir.
spec.configuration.model.configMap. Se você aceitou os padrões, esse valor serásample-domain1-wdt-config-map.metadata.namespace. Se você aceitou os padrões, esse valor serásample-domain1-ns.
Para sua conveniência, você pode usar o comando a seguir para salvar esses valores como variáveis de shell:
export CONFIG_MAP_NAME=sample-domain1-wdt-config-map export WLS_NS=sample-domain1-ns
Use o seguinte comando para obter o
ConfigMapYAML:kubectl get configmap ${CONFIG_MAP_NAME} -n ${WLS_NS} -o yaml > configMap.yamlSiga estas etapas para criar o arquivo tlog-db-model.yaml:
Em um editor de texto, crie um arquivo vazio chamado tlog-db-model.yaml.
Insira o conteúdo de model.yaml, adicione uma linha em branco e insira o conteúdo do arquivo configMap.yaml.
No arquivo tlog-db-model.yaml, localize a linha que termina com
ListenPort: 8001. Acrescente este texto na linha a seguir, tomando muito cuidado para queTransactionLogJDBCStorefique exatamente abaixo deListenPorte as linhas restantes no snippet a seguir sejam recuadas em incrementos de dois, conforme mostrado no exemplo a seguir:TransactionLogJDBCStore: Enabled: true DataSource: jdbc/WebLogicCafeDB PrefixName: TLOG_${serverName}_O tlog-db-model.yaml concluído deve ser muito parecido com o do exemplo a seguir:
topology: Name: "@@ENV:CUSTOM_DOMAIN_NAME@@" ProductionModeEnabled: true AdminServerName: "admin-server" Cluster: "cluster-1": DynamicServers: ServerTemplate: "cluster-1-template" ServerNamePrefix: "@@ENV:MANAGED_SERVER_PREFIX@@" DynamicClusterSize: "@@PROP:CLUSTER_SIZE@@" MaxDynamicClusterSize: "@@PROP:CLUSTER_SIZE@@" MinDynamicClusterSize: "0" CalculatedListenPorts: false Server: "admin-server": ListenPort: 7001 ServerTemplate: "cluster-1-template": Cluster: "cluster-1" ListenPort: 8001 TransactionLogJDBCStore: Enabled: true DataSource: jdbc/WebLogicCafeDB PrefixName: TLOG_${serverName}_ SecurityConfiguration: NodeManagerUsername: "@@SECRET:__weblogic-credentials__:username@@" NodeManagerPasswordEncrypted: "@@SECRET:__weblogic-credentials__:password@@" resources: JDBCSystemResource: jdbc/WebLogicCafeDB: Target: 'cluster-1' JdbcResource: JDBCDataSourceParams: JNDIName: [ jdbc/WebLogicCafeDB ] GlobalTransactionsProtocol: None JDBCDriverParams: DriverName: com.microsoft.sqlserver.jdbc.SQLServerDriver URL: '@@SECRET:ds-secret-sqlserver-1709938597:url@@' PasswordEncrypted: '@@SECRET:ds-secret-sqlserver-1709938597:password@@' Properties: user: Value: '@@SECRET:ds-secret-sqlserver-1709938597:user@@' JDBCConnectionPoolParams: TestTableName: SQL SELECT 1 TestConnectionsOnReserve: trueSubstitua o modelo WLS pelo
ConfigMap. Para substituir o modelo WLS, substitua o modelo existenteConfigMappelo novo. Para obter mais informações, consulte Atualizar um modelo existente na documentação do Oracle. Para recriar oConfigMap, execute os comandos a seguir:export CM_NAME_FOR_MODEL=sample-domain1-wdt-config-map kubectl -n sample-domain1-ns delete configmap ${CM_NAME_FOR_MODEL} # replace path of tlog-db-model.yaml kubectl -n sample-domain1-ns create configmap ${CM_NAME_FOR_MODEL} \ --from-file=tlog-db-model.yaml kubectl -n sample-domain1-ns label configmap ${CM_NAME_FOR_MODEL} \ weblogic.domainUID=sample-domain1Reinicie o cluster do WLS usando os seguintes comandos: Você precisa causar uma atualização contínua para que o novo modelo funcione.
export RESTART_VERSION=$(kubectl -n sample-domain1-ns get domain sample-domain1 '-o=jsonpath={.spec.restartVersion}') # increase restart version export RESTART_VERSION=$((RESTART_VERSION + 1)) kubectl -n sample-domain1-ns patch domain sample-domain1 \ --type=json \ '-p=[{"op": "replace", "path": "/spec/restartVersion", "value": "'${RESTART_VERSION}'" }]'
Verifique se os pods WLS estão em execução antes de prosseguir. Você pode usar o seguinte comando para observar o status dos pods:
kubectl get pod -n sample-domain1-ns -w
Observação
Neste artigo, os modelos WLS são incluídos na imagem de contêiner do aplicativo, que foi criada pela oferta WLS no AKS. O TLOG é configurado ao substituir o modelo existente pelo WDT ConfigMap que contém o arquivo de modelo e usa o campo CRD configuration.model.configMap de domínio para fazer referência ao mapa. Em cenários de produção, as imagens auxiliares são a melhor abordagem recomendada para incluir arquivos de Modelo em imagem, arquivos mortos do aplicativo e a instalação das Ferramentas de implantação do WebLogic em seus pods. Esse recurso elimina a necessidade de fornecer esses arquivos na imagem especificada em domain.spec.image.
Configurar a redundância geográfica usando o Backup do Azure
Nesta seção, você usa o Backup do Azure para fazer backup de clusters do AKS usando a extensão Backup, que deve ser instalada no cluster.
Siga estas etapas para configurar a redundância geográfica:
Crie um novo contêiner de armazenamento para a extensão de backup do AKS na conta de armazenamento que você criou na seção Criar uma conta de armazenamento e um contêiner de armazenamento para manter o aplicativo de exemplo.
Use os seguintes comandos para instalar a extensão de backup do AKS e habilitar os drivers e os instantâneos CSI para o cluster:
#replace with your resource group name. export RG_NAME=wlsaks-eastus-20240109 export AKS_NAME=$(az aks list \ --resource-group ${RG_NAME} \ --query "[0].name" \ --output tsv) az aks update \ --resource-group ${RG_NAME} \ --name ${AKS_NAME} \ --enable-disk-driver \ --enable-file-driver \ --enable-blob-driver \ --enable-snapshot-controller --yesLeva cerca de 5 minutos para habilitar os drivers. Antes de continuar, verifique se os comandos foram concluídos sem erros.
Abra o grupo de recursos que está com o AKS implantado. Selecione o cluster do AKS na lista de recursos.
Na página de destino do AKS, selecione Configurações>Fazer backup>Instalar Extensão.
Na página Instalar extensão de Backup do AKS, selecione Avançar. Selecione a conta de armazenamento e o contêiner de blobs criados nas etapas anteriores. Selecione Avançar e, em seguida, Criar. Leva aproximadamente cinco minutos para concluir esta etapa.
Abra o portal do Azure, na barra de pesquisa na parte superior, e pesquise Cofres de backup. Você o verá listado em Serviços. Selecione-a.
Para habilitar o Backup do AKS, siga as etapas em Fazer backup do Serviço de Kubernetes do Azure usando o Backup do Azure até, mas não somente, a seção "Usar ganchos durante o backup do AKS". Faça os ajustes indicados nas etapas a seguir.
Quando você chegar à seção "Criar um cofre de backup", faça os seguintes ajustes:
Na etapa 1, em Regiões, selecione Leste dos EUA. Em Redundância de Armazenamento de Backup, use Redundância Global.
Na etapa 2, habilite Restauração Entre Regiões.
Quando você chegar à seção "Criar uma política de backup", faça os seguintes ajustes quando for criar uma política de retenção:
Adicione uma regra de retenção em que Vault-standard esteja selecionado.
Selecione Adicionar.
Quando você chegar à seção "Configurar backups", faça os seguintes ajustes. As etapas de 1 a 5 são para a instalação da extensão do AKS. Pule as etapas 1 a 5 e comece pela etapa 6.
Na etapa 7, você encontra erros de permissão. Selecione Conceder permissão para prosseguir. Depois de implantar a permissão, se o erro ainda aparecer, selecione Revalidar para atualizar as atribuições de função.
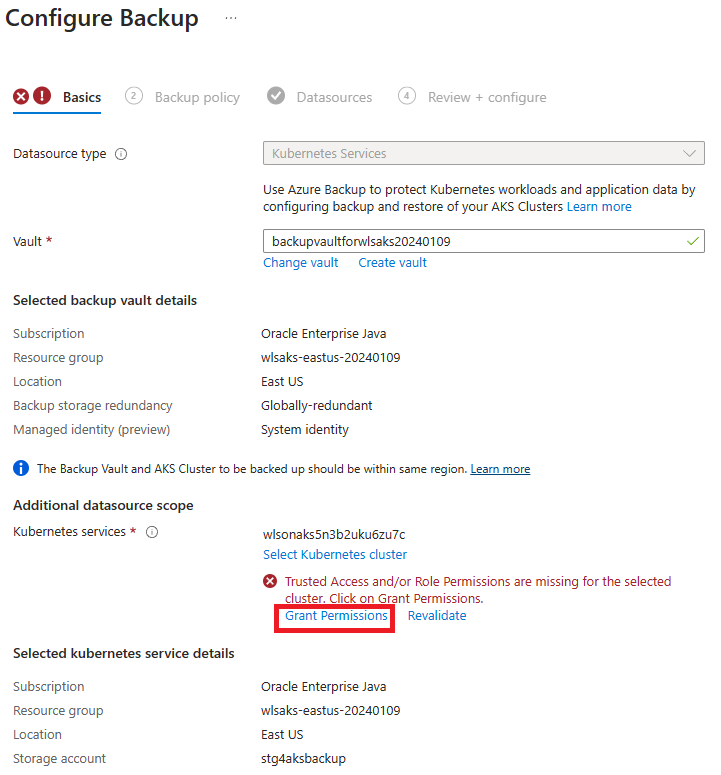
Na etapa 10, localize Selecionar Recursos para Backup e faça os seguintes ajustes:
- Em Nome da instância de backup, preencha um nome exclusivo.
- Para Namespaces, selecione namespaces para WebLogic Operator e WebLogic Server. Neste artigo, selecione weblogic-operator-ns e sample-domain1-ns.
- Para Outras opções, selecione todas as opções. Verifique se a guia Incluir Segredos está selecionado.

Na etapa 11, você encontra um erro de atribuição de função. Selecione sua fonte de dados na lista e selecione Atribuir funções ausentes para atenuar o erro.
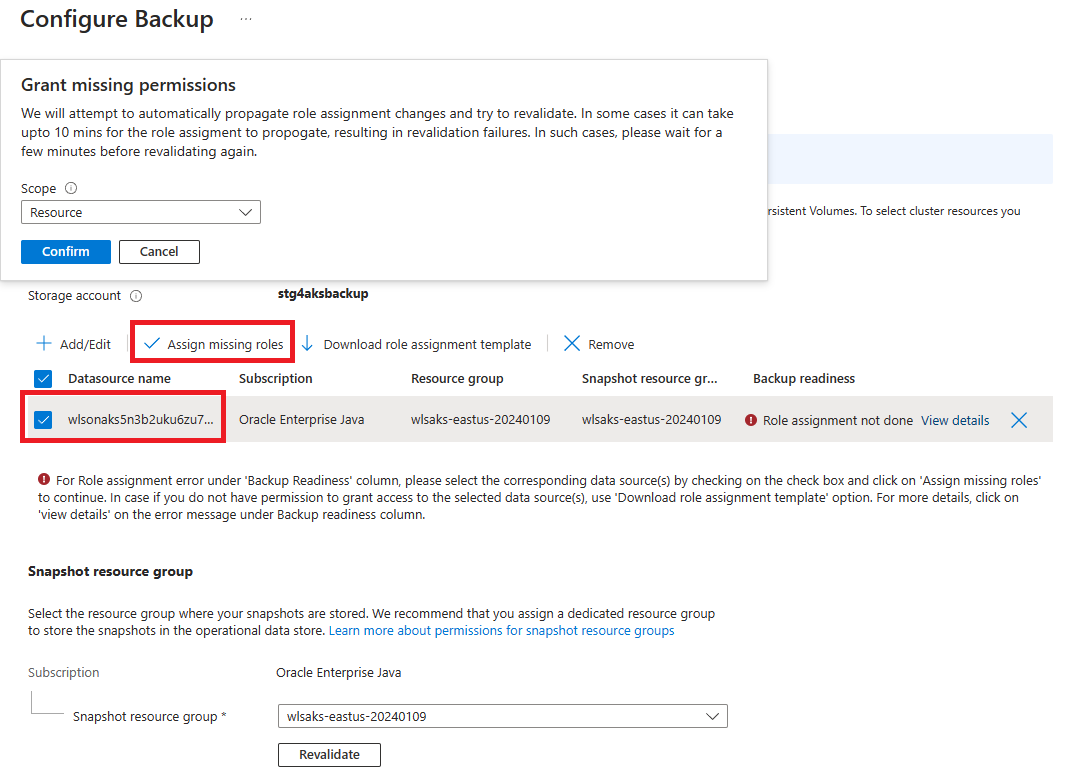





Preparar-se para restaurar o cluster WLS em uma região secundária
Nesta seção, você se prepara para restaurar o cluster WLS na região secundária. Aqui, a região secundária é o Oeste dos EUA 2. Antes da restauração, você deve ter um cluster do AKS com a Extensão de Backup do AKS instalada na região Oeste dos EUA 2.
Configurar o Registro de Contêiner do Azure para replicação geográfica
Siga estas etapas para configurar o ACR (Registro de Contêiner do Azure) para replicação geográfica, que contém a imagem do WLS criada na seção Implantar o WLS no AKS. Para habilitar a replicação do ACR, você precisa atualizá-la para o plano de preços Premium. Para mais informações, confira Replicação geográfica no Registro de Contêiner do Azure.
- Abra o grupo de recursos que você provisionou na seção Implantar o WLS no AKS. Na lista de recursos, selecione o ACR cujo nome começa com wlsaksacr.
- Na página de destino do ACR, selecione Configurações>Propriedades. Para Plano de preços, selecione Premium, depois, selecione Salvar.
- No painel de navegação, selecione Serviços>Replicações geográficas. Selecione Adicionar para adicionar a região de replicação na página.
- Na página Criar replicação, para Local, selecione Oeste dos EUA 2 e, em seguida, selecione Criar.
Depois de concluir a implantação, o ACR é habilitado para replicação geográfica.
Criar uma conta de armazenamento em uma região secundária
Para habilitar a Extensão de Backup do AKS, você deve informar uma conta de armazenamento com um contêiner vazio na mesma região.
Para restaurar o backup entre regiões, você deve informar um local de preparo onde os dados de backup sejam hidratados. Esse local de preparo inclui um grupo de recursos e uma conta de armazenamento nele na mesma região e assinatura que o cluster de destino para restauração.
Use as etapas a seguir para criar um contêiner e uma conta de armazenamento. Algumas dessas etapas direcionam você para outros guias.
- Entre no portal do Azure.
- Crie uma conta de armazenamento seguindo as etapas em Criar uma conta de armazenamento. Você não precisa executar todas as etapas do artigo. Preencha os campos mostrados no painel Noções básicas. Em Região, selecione Oeste dos EUA 2 e, em seguida, selecione Examinar + criar para aceitar as opções padrão. Prossiga para validar e criar a conta e retorne a este artigo.
- Crie um contêiner de armazenamento para a Extensão de Backup do AKS seguindo as etapas na seção Criar um contêiner de Início Rápido: carregar, baixar e listar blobs com o portal do Azure.
- Crie um contêiner de armazenamento como um local de preparo para usar durante a restauração.
Preparar um cluster do AKS em uma região secundária
As seções a seguir mostram como criar um cluster do AKS em uma região secundária.
Criar um cluster do AKS
Este artigo mostra um aplicativo WLS que usa o Controlador de Entrada do Gateway de Aplicativo. Nesta seção, você cria um novo cluster do AKS na região Oeste dos EUA 2. Em seguida, você habilita o complemento do controlador de entrada com uma nova instância do gateway de aplicativo. Para obter mais informações, consulte Habilitar o complemento de controlador de entrada para um novo cluster do AKS com uma nova instância do gateway de aplicativo.
Siga estas etapas para criar o cluster do AKS:
Use os comandos a seguir para criar um grupo de recursos na região secundária:
export RG_NAME_WESTUS=wlsaks-westus-20240109 az group create --name ${RG_NAME_WESTUS} --location westusUse os seguintes comandos para implantar um cluster do AKS com o complemento habilitado:
export AKS_NAME_WESTUS=${RG_NAME_WESTUS}aks export GATEWAY_NAME_WESTUS=${RG_NAME_WESTUS}gw az aks create \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS} \ --network-plugin azure \ --enable-managed-identity \ --enable-addons ingress-appgw \ --appgw-name ${GATEWAY_NAME_WESTUS} \ --appgw-subnet-cidr "10.225.0.0/16" \ --generate-ssh-keysEsse comando cria automaticamente uma instância de gateway de aplicativo
Standard_v2 SKUcom o nome${RG_NAME_WESTUS}gwno grupo de recursos de nó do AKS. Por padrão, o nome do grupo de recursos de nó éMC_resource-group-name_cluster-name_location.Observação
O cluster do AKS provisionado na seção Implantar o WLS no AKS é executado em três zonas de disponibilidade na região Leste dos EUA. Não há suporte para zonas de disponibilidade na região West US 2. O cluster do AKS no Oeste dos EUA 2 não tem redundância de zona. Se o ambiente de produção exigir redundância de zona, verifique se a região emparelhada é compatível com zonas de disponibilidade. Para obter mais informações, consulte a seção Visão geral das zonas de disponibilidade para clusters do AKS de Criar um cluster do AKS (Serviço de Kubernetes do Azure) que usa zonas de disponibilidade.
Use os seguintes comandos para obter o endereço IP público da instância do gateway de aplicativo. Salve o endereço IP, pois você o usará mais adiante neste artigo.
export APPGW_ID=$(az aks show \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS} \ --query 'addonProfiles.ingressApplicationGateway.config.effectiveApplicationGatewayId' \ --output tsv) echo ${APPGW_ID} export APPGW_IP_ID=$(az network application-gateway show \ --id ${APPGW_ID} \ --query frontendIPConfigurations\[0\].publicIPAddress.id \ --output tsv) echo ${APPGW_IP_ID} export APPGW_IP_ADDRESS=$(az network public-ip show \ --id ${APPGW_IP_ID} \ --query ipAddress \ --output tsv) echo "App Gateway public IP address: ${APPGW_IP_ADDRESS}"Use o comando a seguir para anexar um rótulo de nome DNS (serviço de nome de domínio) ao recurso de endereço IP público. Substitua
<your-chosen-DNS-name>por um valor apropriado; por exemplo,ejb010316.az network public-ip update --ids ${APPGW_IP_ID} --dns-name <your-chosen-DNS-name>Você pode verificar o nome de domínio totalmente qualificado (FQDN) do IP público com
az network public-ip show. O exemplo a seguir mostra um FQDN com rótulo de DNSejb010316:az network public-ip show \ --id ${APPGW_IP_ID} \ --query dnsSettings.fqdn \ --output tsvEsse comando produz uma saída semelhante ao seguinte exemplo:
ejb010316.westus.cloudapp.azure.com
Observação
Se você estiver trabalhando com um cluster do AKS existente, realize as duas ações a seguir antes de prosseguir:
- Habilite o complemento do controlador de entrada conforme as etapas em Habilitar o complemento do controlador de entrada do gateway de aplicativo para um cluster AKS existente.
- Se o WLS estiver em execução no namespace de destino, para evitar conflitos, limpe os recursos do WLS no namespace do Operador WebLogic e no namespace do WebLogic Server. Neste artigo, a oferta WLS no AKS provisionou o Operador WebLogic no namespace
weblogic-operator-nse o WebLogic Server no namespacesample-domain1-ns. Executekubectl delete namespace weblogic-operator-ns sample-domain1-nspara excluir os dois namespaces.
Habilitar a extensão de backup do AKS
Antes de continuar, siga estas etapas para instalar a Extensão de Backup do AKS no cluster na região secundária:
Use o seguinte comando para se conectar ao cluster do AKS na região Oeste dos EUA 2:
az aks get-credentials \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS}Use o seguinte comando para habilitar os drivers e instantâneos de CSI para o cluster:
az aks update \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS} \ --enable-disk-driver \ --enable-file-driver \ --enable-blob-driver \ --enable-snapshot-controller --yes
Abra o grupo de recursos que está com o AKS implantado. Selecione o cluster do AKS na lista de recursos.
Na página de destino do AKS, selecione Configurações>Fazer backup>Instalar Extensão.
Na página Instalar extensão de Backup do AKS, selecione Avançar. Selecione a conta de armazenamento e o contêiner de blobs criados nas etapas anteriores. Selecione Avançar e, em seguida, Criar. Leva aproximadamente cinco minutos para concluir esta etapa.
Observação
Para fins de economia, você pode interromper o cluster do AKS na região secundária de acordo com as etapas em Parar e iniciar um cluster do AKS (Serviço de Kubernetes do Azure). Inicie-o antes de restaurar o cluster WLS.
Aguarde até que um backup Vault-standard aconteça
No AKS, a camada standard do cofre é a única que permite Redundância geográfica e Restauração entre regiões. Conforme declarado em Qual camada de armazenamento de backup o AKS aceita?, "Apenas um ponto de recuperação agendado por dia é movido para a camada do cofre". Você deve aguardar até que um backup Vault-standard aconteça. Um limite inferior adequado é aguardar 24 horas para continuar após concluir a etapa anterior.
Interromper o cluster primário
O cluster WLS primário e o cluster WLS secundário são configurados com o mesmo banco de dados TLOG. Apenas um cluster pode ser proprietário do banco de dados ao mesmo tempo. Para que o cluster secundário funcione corretamente, interrompa o cluster WLS primário. Neste artigo, pare o cluster do AKS para desabilitar o cluster WLS de acordo com estas etapas:
- Abra o portal do Azure e acesse o grupo de recursos provisionado na seção Implantar o WLS no AKS.
- Abra o cluster do AKS listado no grupo de recursos.
- Selecione Parar para interromper o cluster do AKS. Verifique se a implantação foi concluída antes de prosseguir.
Restaurar o cluster do WLS
O backup do AKS dá suporte a backups da Camada Operacional e da Camada do Cofre. Somente os backups armazenados na Camada do Cofre podem ser usados para fazer uma restauração em um cluster em uma região diferente (Região Emparelhada do Azure). De acordo com as regras de retenção definidas na política de backup, o primeiro backup bem-sucedido de um dia é movido para a região entre contêineres de blobs. Para obter mais informações, consulte a seção Qual camada de armazenamento de backup o AKS aceita? de O que é o backup do Serviço de Kubernetes do Azure?
Depois de configurar a redundância geográfica na seção Configurar redundância geográfica usando o Backup do Azure, é necessário pelo menos um dia para que os backups da Camada de Cofre fiquem disponíveis para restauração.
Siga estas etapas para restaurar o cluster do WLS:
Abra o portal do Azure e procure o Centro de backup. Em Serviços, selecione Centro de backup.
Em Gerenciar, selecione Instâncias de backup. Filtre o tipo de fonte de dados Serviços de Kubernetes para localizar a instância de backup que você criou na seção anterior.
Selecione a instância de backup para ver a lista de pontos de restauração. Neste artigo, o nome da instância é uma cadeia de caracteres semelhante a
wlsonaks*\wlsaksinstance20240109.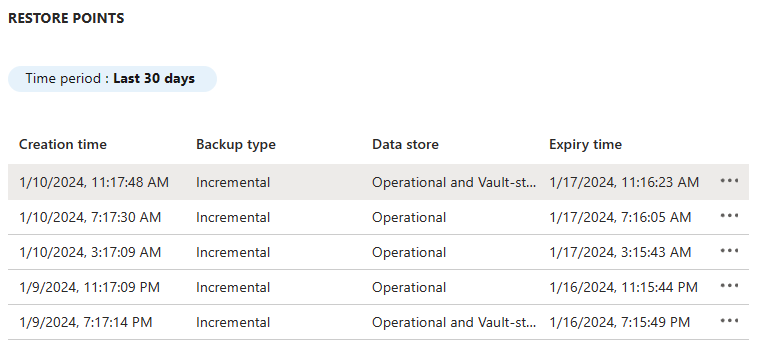
Selecione o backup Operacional e Vault-standard mais recente, depois, selecione Mais opções. Selecione Restaurar para iniciar o processo de restauração.
Na página Restaurar, o painel padrão é Ponto de restauração. Selecione Anterior para alterar para o painel Noções básicas. Para Região de Restauração, selecione Região Secundária e, em seguida, selecione Avançar: Ponto de restauração.

No painel Ponto de restauração, em Selecione a camada a ser restaurada, selecione Armazenamento do Cofre e, em seguida, selecione parâmetros Next:Restore.
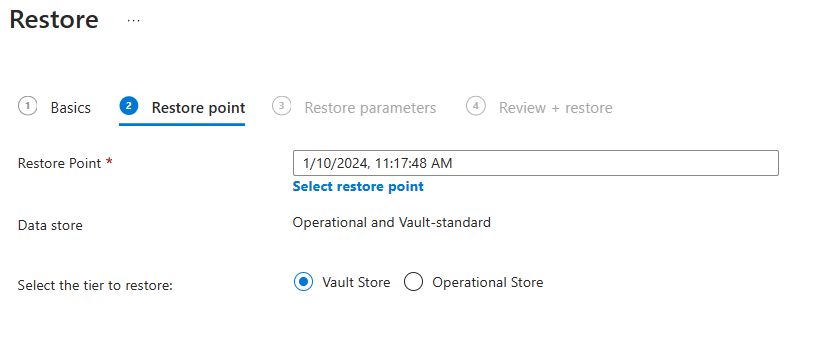
No painel parâmetros Restore, siga estas etapas:
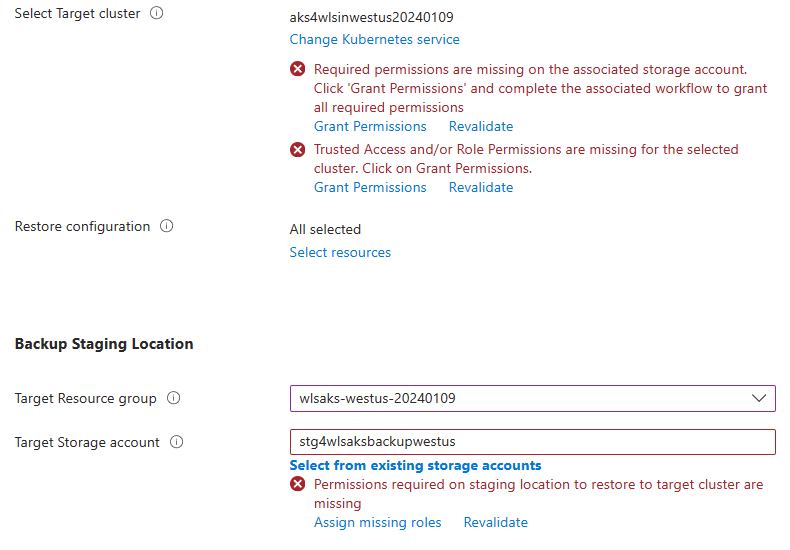
Para Selecionar cluster de destino, selecione o cluster do AKS que você criou na região Oeste dos EUA 2. Você encontra um problema de permissão, como mostra a captura de tela a seguir. Selecione Conceder Permissão para atenuar os erros.
Para Local de Preparo de Backup, selecione a Conta de Armazenamento que você criou em Oeste dos EUA 2. Você encontra um problema de permissão, como mostra a captura de tela a seguir. Selecione Atribuir funções ausentes para atenuar os erros.
Se os erros ainda ocorrerem após a conclusão das atribuições de função, selecione Revalidar para atualizar as permissões.
Ao conceder permissões ausentes, quando for especificar um Escopo, aceite o valor padrão.
Selecione Validar. Você verá a mensagem Validação concluída com êxito. Se não vir, solucione e resolva o problema antes de continuar.
Selecione Next:Review + restore e, em seguida, selecione Restaurar. Demora cerca de 10 minutos para restaurar o cluster WLS.
Você pode monitorar o processo de restauração em Centro de backup>Monitoramento + relatórios>Trabalhos de backup, conforme mostrado na captura de tela a seguir:

Selecione Atualizar para ver o progresso mais recente.
Depois que o processo for concluído sem erros, interrompa o cluster do AKS de backup. Deixar de fazer isso causa conflitos de propriedade quando você acessa o banco de dados TLOG em etapas posteriores.
Inicie o cluster primário.





Configurar um Gerenciador de Tráfego do Azure
Nesta seção, você cria um Gerenciador de Tráfego do Azure para distribuir o tráfego para seus aplicativos voltados para o público nas regiões globais do Azure. O ponto de extremidade primário aponta para o Gateway de Aplicativo do Azure no cluster WLS primário e o ponto de extremidade secundário aponta para o Gateway de Aplicativo do Azure no cluster WLS secundário.
Crie um perfil do Gerenciador de Tráfego do Azure seguindo as etapas em Início Rápido: Criar um perfil do Gerenciador de Tráfego usando o portal do Azure. Ignore a seção "Pré-requisitos". Você só precisa das seguintes seções: Criar um perfil do Gerenciador de Tráfego, Adicionar pontos de extremidade do Gerenciador de Tráfego e Testar o perfil do Gerenciador de Tráfego. Siga estas etapas ao percorrer essas seções e, em seguida, retorne a este artigo depois de criar e configurar o Gerenciador de Tráfego do Azure:
Quando você chegar à seção Criar um perfil do Gerenciador de Tráfego, na etapa 2, Criar perfil do Gerenciador de Tráfego, siga estas etapas:
- Salve o nome de perfil exclusivo do Gerenciador de Tráfego para Nome; por exemplo, tmprofile-ejb120623.
- Em Grupo de recursos, salve o novo nome do grupo de recursos; por exemplo, myResourceGroupTM1.
Quando você chegar à seção Adicionar pontos de extremidade do Gerenciador de Tráfego, execute as seguintes etapas:
- Após a etapa Selecione o perfil nos resultados da pesquisa, siga estas etapas:
- Em Configurações, escolha Configuração.
- Em Vida útil (TTL) do DNS, digite 10.
- Em Configurações do monitor de ponto de extremidade, em Caminho, insira /weblogic/ready.
- Em Configurações de failover de ponto de extremidade rápido, use os seguintes valores:
- Em Investigação interna, digite 10.
- Em Número tolerado de falhas, digite 3.
- Para Tempo limite de investigação, 5.
- Selecione Salvar. Aguarde a conclusão.
- Na etapa 4 para adicionar o ponto de extremidade primário
myPrimaryEndpoint, execute as seguintes etapas:- Para Tipo de recurso de destino, selecione Endereço IP público.
- Selecione a lista suspensa Escolher endereço IP público e insira o endereço IP do Gateway de Aplicativo implantado no cluster WLS Leste dos EUA que você salvou anteriormente. Você deve ver uma correspondência de entrada. Selecione-a para Endereço IP público.
- Na etapa 6 para adicionar um failover/ponto de extremidade secundário myFailoverEndpoint, execute as seguintes etapas:
- Para Tipo de recurso de destino, selecione Endereço IP público.
- Selecione a lista suspensa Escolher endereço IP público e insira o endereço IP do Gateway de Aplicativo implantado no cluster WLS Oeste dos EUA que você salvou anteriormente. Você deve ver uma correspondência de entrada. Selecione-a para Endereço IP público.
- Aguarde. Selecione Atualizar até que o Status do Monitor atinja os seguintes estados:
- O ponto de extremidade primário é Online.
- O ponto de extremidade de failover é Degradado.
- Após a etapa Selecione o perfil nos resultados da pesquisa, siga estas etapas:
Quando você chegar à seção Testar perfil do Gerenciador de Tráfego, siga estas etapas:
- Na subseção Verificar o nome DNS, na etapa 3, salve o nome DNS do seu perfil do Gerenciador de Tráfego; por exemplo,
http://tmprofile-ejb120623.trafficmanager.net. - Na subseção Exibir Gerenciador de Tráfego em ação, execute as seguintes etapas:
- Nas etapas 1 e 3, acrescente /weblogic/ready ao nome DNS do seu perfil do Gerenciador de Tráfego no navegador da Web; por exemplo,
http://tmprofile-ejb120623.trafficmanager.net/weblogic/ready. Você deve ver uma página vazia sem mensagem de erro. - Na etapa 4, você não pode acessar /weblogic/ready, o que é esperado, porque o cluster secundário está parado.
- Reabilite o ponto de extremidade primário.
- Nas etapas 1 e 3, acrescente /weblogic/ready ao nome DNS do seu perfil do Gerenciador de Tráfego no navegador da Web; por exemplo,
- Na subseção Verificar o nome DNS, na etapa 3, salve o nome DNS do seu perfil do Gerenciador de Tráfego; por exemplo,
Agora, o ponto de extremidade primário tem os estados Habilitado e Online, e o ponto de extremidade de failover tem os estados Habilitado e Degradado no perfil do Gerenciador de Tráfego. Mantenha a página aberta para monitorar o status do ponto de extremidade posteriormente.
Testar o failover do primário para o secundário
Para testar o failover, você faz o failover manual do servidor de banco de dados primário e do cluster WLS para o servidor de banco de dados secundário e o cluster WLS nesta seção.
Como o cluster primário está ativo e em execução, ele atua como o cluster ativo e processa todas as solicitações de usuário roteadas pelo perfil do Gerenciador de Tráfego.
Abra o nome DNS do seu perfil do Gerenciador de Tráfego do Azure em uma nova guia do navegador, acrescentando a raiz de contexto /weblogic-cafe do aplicativo implantado; por exemplo, http://tmprofile-ejb120623.trafficmanager.net/weblogic-cafe. Crie um café com nome e preço; por exemplo, Café 1 com preço 10. Essa entrada persiste na tabela de dados do aplicativo e na tabela de sessão do banco de dados. A UI que você verá deve ser semelhante à seguinte captura de tela:

Se sua interface do usuário não for semelhante, solucione e resolva o problema antes de continuar.
Mantenha a página aberta para usá-la para o teste de failover posteriormente.
Failover para o site secundário
Siga estas etapas para fazer failover do primário para o secundário.
Primeiro, use as seguintes etapas para interromper o cluster primário do AKS:
- Abra o portal do Azure e acesse o grupo de recursos que foi provisionado na seção Implantar o WLS no AKS .
- Abra o cluster do AKS listado no grupo de recursos.
- Selecione Parar para interromper o cluster do AKS. Verifique se a implantação foi concluída antes de prosseguir.
Em seguida, siga as próximas etapas para fazer failover do Banco de Dados SQL do Azure do servidor primário para o servidor secundário.
- Mude para a guia do navegador do grupo de failover do Banco de Dados SQL do Azure.
- Selecione Failover>Sim.
- Aguarde a conclusão.
Em seguida, siga estas etapas para iniciar o cluster secundário.
- Abra o portal do Azure e encontre o grupo de recursos que tem o cluster do AKS na região secundária.
- Abra o cluster do AKS listado no grupo de recursos.
- Para iniciar o cluster AKS, selecione Iniciar. Verifique se a implantação foi concluída antes de prosseguir.
Por fim, siga estas etapas para verificar o aplicativo de exemplo depois que o ponto de extremidade myFailoverEndpoint estiver no estado Online:
Mude para a guia do navegador do Gerenciador de Tráfego e atualize a página até ver que o valor de Status do Monitor do ponto de extremidade
myFailoverEndpointentra no estado Online.Mude para a guia do navegador do aplicativo de exemplo e atualize a página. Você deverá ver os mesmos dados persistidos na tabela de dados do aplicativo e na tabela de sessão exibida na interface do usuário, conforme mostrado na captura de tela a seguir:

Se você não observar esse comportamento, pode ser porque o Gerenciador de Tráfego está demorando para atualizar o DNS até apontar para o site de failover. O problema também pode ser que seu navegador armazenou em cache o resultado da resolução de nomes DNS que aponta para o site com falha. Aguarde um pouco e atualize a página novamente.
Observação
Uma solução de HA/DR pronta para produção pode ser responsável pela cópia contínua da configuração do WLS dos clusters primários para os secundários em uma programação regular. Para obter informações sobre como fazer isso, consulte as referências à documentação da Oracle ao final deste artigo.
Para automatizar o failover, use alertas nas métricas do Gerenciador de Tráfego e na Automação do Azure. Para obter mais informações, consulte a seção Alertas sobre métricas do Gerenciador de Tráfego de Métricas e alertas do Gerenciador de Tráfego e Usar um alerta para disparar um runbook de Automação do Azure.
Fazer failback para o primário primário
Para fazer failback para o site primário, é necessário que os dois clusters tenham uma configuração de backup espelhado. É possível atingir esse estado pelas seguintes etapas:
- Habilite os backups de cluster do AKS na região Oeste dos EUA 2 seguindo as etapas na seção Configurar redundância geográfica usando o Backup do Azure, a partir da etapa 4.
- Restaure o backup mais recente da Camada do Vault para o cluster na região Leste dos EUA seguindo as etapas na seção Preparar para restaurar o cluster WLS em uma região secundária. Ignore as etapas que você já concluiu.
- Siga as etapas semelhantes na seção Failover para o site secundário, para fazer failback para o site primário, incluindo servidor de banco de dados e cluster.
Limpar os recursos
Se você não for continuar usando os clusters WLS e outros componentes, siga estas etapas para excluir os grupos de recursos para limpar os recursos usados neste tutorial:
- Na caixa de pesquisa na parte superior do portal do Azure, insira Cofres de backup e selecione os cofres de backup nos resultados da pesquisa.
- Selecione Gerenciar>Propriedades>Exclusão reversível>Atualizar. Desmarque a caixa ao lado de Habilitar Exclusão Reversível.
- Selecione Gerenciar>Instâncias de backup. Selecione a instância que você criou e exclua-a.
- Insira o nome do grupo de recursos dos servidores do Banco de Dados SQL do Azure - por exemplo,
myResourceGroup- na caixa de pesquisa na parte superior do portal do Azure e selecione o grupo de recursos correspondente nos resultados da pesquisa. - Selecione Excluir grupo de recursos.
- Em Inserir nome do grupo de recursos para confirmar a exclusão, insira o nome do grupo de recursos.
- Selecione Excluir.
- Repita as etapas 4 a 7 para o grupo de recursos do Gerenciador de Tráfego; por exemplo,
myResourceGroupTM1. - Repita as etapas 4 a 7 para o grupo de recursos do cluster WLS primário; por exemplo,
wls-aks-eastus-20240109. - Repita as etapas 4 a 7 para o grupo de recursos do cluster WLS secundário; por exemplo,
wls-aks-westus-20240109.
Próximas etapas
Neste tutorial, você configura uma solução HA/DR que consiste em uma camada de infraestrutura de aplicativo ativa-passiva com uma camada de banco de dados ativa-passiva em que as duas camadas abrangem dois sites geograficamente diferentes. No primeiro site, a camada de infraestrutura de aplicativo e a camada de banco de dados estão ativas. No segundo site, o domínio secundário é desligado, e o banco de dados secundário se mantém em espera.
Continue a explorar as seguintes referências para ver outras opções para criar soluções de HA/DR e executar o WLS no Azure: