Introdução aos objetos de workspace
Este artigo fornece uma introdução de alto nível aos objetos de workspace do Azure Databricks. Você pode criar, ver e organizar todos os objetos de workspace no navegador de workspace entre personas.
Observação sobre como nomear ativos de workspace
O nome completo de um ativo de espaço de trabalho consiste em seu nome base e sua extensão de arquivo. Por exemplo, a extensão de arquivo de um notebook pode ser .py, .sql, .scala, .r e .ipynb dependendo do idioma e do formato do notebook.
Quando você cria um ativo notebook, seu nome base e seu nome completo (o nome base concatenado com a extensão de arquivo) devem ser exclusivos em qualquer pasta do workspace. Quando você nomeia um ativo, o Databricks verifica se ele atende a esses critérios adicionando a extensão de arquivo a ele. Se o nome completo corresponder a um arquivo existente na pasta, esse nome não será permitido e você deverá escolher um novo nome de bloco de anotações. Por exemplo, se você tentar criar um notebook Python (no formato de fonte Python) chamado test na mesma pasta que um arquivo Python chamado test.py, isso não será permitido.
Clusters
Os clusters de Engenharia e Ciência de Dados do Azure Databricks e de Mosaic AI do Databricks fornecem uma plataforma unificada para vários casos de uso, como execução de pipelines ETL de produção, análise de streaming, análise ad-hoc e Machine Learning. Um cluster é um tipo de recurso de computação do Azure Databricks. Outros tipos de recursos de computação incluem os SQL warehouses do Azure Databricks.
Para obter informações detalhadas sobre como gerenciar e usar clusters, confira Computação.
Notebooks
Um notebook é uma interface baseada na Web para documentos que contém uma série de células executáveis (comandos) que operam em arquivos e tabelas, visualizações e texto de narração. Os comandos podem ser executados em sequência, referindo-se à saída de um ou mais comandos executados anteriormente.
Os notebooks são um mecanismo de execução de código no Azure Databricks. O outro mecanismo é trabalhos.
Para obter informações detalhadas sobre como gerenciar e usar notebooks, consulte Introdução aos notebooks do Databricks.
Cargos
Os trabalhos são um mecanismo de execução de código no Azure Databricks. O outro mecanismo é notebooks.
Para obter informações detalhadas sobre como gerenciar e usar tarefas, consulte Visão geral da orquestração no Databricks.
Bibliotecas
Uma biblioteca torna o código de terceiros ou criado localmente disponível para notebooks e trabalhos em execução nos clusters.
Para obter informações detalhadas sobre como gerenciar e usar bibliotecas, confira Bibliotecas.
Dados
Você pode importar dados para um sistema de arquivos distribuído montado em um workspace do Azure Databricks e trabalhar com ele em notebooks e clusters do Azure Databricks. Você também pode usar uma grande variedade de fontes de dados do Apache Spark para acessar dados.
Para obter informações detalhadas sobre o carregamento de dados, confira Ingerir dados em um lakehouse do Azure Databricks.
Arquivos
Importante
Esse recurso está em uma versão prévia.
No Databricks Runtime 11.3 LTS e versões superiores, você pode criar e usar arquivos arbitrários no workspace do Databricks. Os arquivos podem ser qualquer tipo de arquivo. Exemplos comuns de tipo de arquivo incluem:
- Arquivos
.pyusados em módulos personalizados. - Arquivos
.md, comoREADME.md. .csvou outros arquivos de dados pequenos..txtarquivos.- Arquivos de log.
Para obter informações detalhadas sobre como usar arquivos, consulte Como trabalhar com arquivos no Azure Databricks. Para obter informações sobre como usar arquivos para modularizar seu código conforme você desenvolve com notebooks do Databricks, consulte Compartilhar código entre notebooks do Databricks
pastas Git
As pastas Git são pastas do Azure Databricks cujos conteúdos são co-versionados em conjunto, sincronizando-os com um repositório Git remoto. Usando pastas Git do Databricks, você pode desenvolver notebooks no Azure Databricks e usar um repositório Git remoto para colaboração e controle de versão.
Para obter informações detalhadas sobre o uso de repositórios, consulte Integração do Git para pastas Git do Databricks.
Modelos
Modelo refere-se a um modelo registrado no Registro de Modelos MLflow. O Registro de Modelos é um armazenamento de modelos centralizado que permite gerenciar o ciclo de vida completo dos modelos MLflow. Ele fornece linhagem de modelo cronológica, controle de versão do modelo, transições de fase e anotações e descrições de versão do modelo e do modelo.
Para obter informações detalhadas sobre como gerenciar e usar modelos, veja Gerenciar ciclo de vida do modelo no Unity Catalog.
Experimentos
Um experimento do MLflow é a principal unidade de organização e controle de acesso para execuções de treinamento de modelos de machine learning do MLflow. Todas as execuções do MLflow pertencem a um experimento. Cada experimento permite visualizar, pesquisar e comparar execuções e baixar e executar artefatos ou metadados para análise em outras ferramentas.
Para obter informações detalhadas sobre como gerenciar e usar experimentos, consulte Organizar execuções de treinamento com experimentos de MLflow.
Consultas
As consultas são instruções SQL que permitem que você interaja com seus dados. Para obter mais informações, confira Acessar e gerenciar consultas salvas.
Painéis
Os dashboards são apresentações de visualizações de consulta e comentários. Veja Painéis ou Painéis herdados.
Alertas
Os alertas são notificações de que um campo retornado por uma consulta atingiu um limite. Para obter mais informações, consulte O que são alertas do Databricks SQL?.
Referências a objetos de workspace
Historicamente, os usuários eram obrigados a incluir o prefixo de caminho /Workspace para algumas APIs do Databricks (%sh), mas não para outras (%run, entradas da API REST).
Os usuários podem usar caminhos de workspace com o prefixo /Workspace em todos os lugares. Referências antigas a caminhos sem o prefixo /Workspace são redirecionadas e continuam funcionando. Recomendamos que todos os caminhos de workspace usem o prefixo /Workspace para se diferenciarem dos caminhos Volume e DBFS.
Para que o comportamento do prefixo do caminho /Workspace seja consistente, é necessário o seguinte: não pode existir uma pasta /Workspace no nível raiz do workspace. Se você tiver uma pasta /Workspace no nível raiz e quiser habilitar essa melhoria de UX, exclua ou renomeie a pasta /Workspace que você criou e entre em contato com sua equipe de conta do Azure Databricks.
Compartilhe um URL de arquivo, pasta ou bloco de anotações
No seu espaço de trabalho Azure Databricks, os URLs para ficheiros, cadernos e pastas do espaço de trabalho estão nos formatos:
URLs de arquivos do espaço de trabalho
https://<databricks-instance>/?o=<16-digit-workspace-ID>#files/<16-digit-object-ID>
URLs do Notebook
https://<databricks-instance>/?o=<16-digit-workspace-ID>#notebook/<16-digit-object-ID>/command/<16-digit-command-ID>
URLs de pasta (espaço de trabalho e Git)
https://<databricks-instance>/browse/folders/<16-digit-ID>?o=<16-digit-workspace-ID>
Esses links podem quebrar se qualquer pasta, arquivo ou notebook no caminho atual for atualizado com um comando pull do Git ou for excluído e recriado com o mesmo nome. No entanto, pode construir uma ligação com base no caminho do espaço de trabalho para partilhar com outros utilizadores do Databricks com níveis de acesso apropriados, alterando-a para uma ligação nesse formato:
https://<databricks-instance>/?o=<16-digit-workspace-ID>#workspace/<full-workspace-path-to-file-or-folder>
Links para pastas, blocos de anotações e arquivos podem ser compartilhados substituindo tudo na URL após ?o=<16-digit-workspace-ID> pelo caminho para o arquivo, pasta ou bloco de notas da raiz do espaço de trabalho. Se você estiver compartilhando um URL em uma pasta, remova também /browse/folders/<16-digit-ID> do URL original.
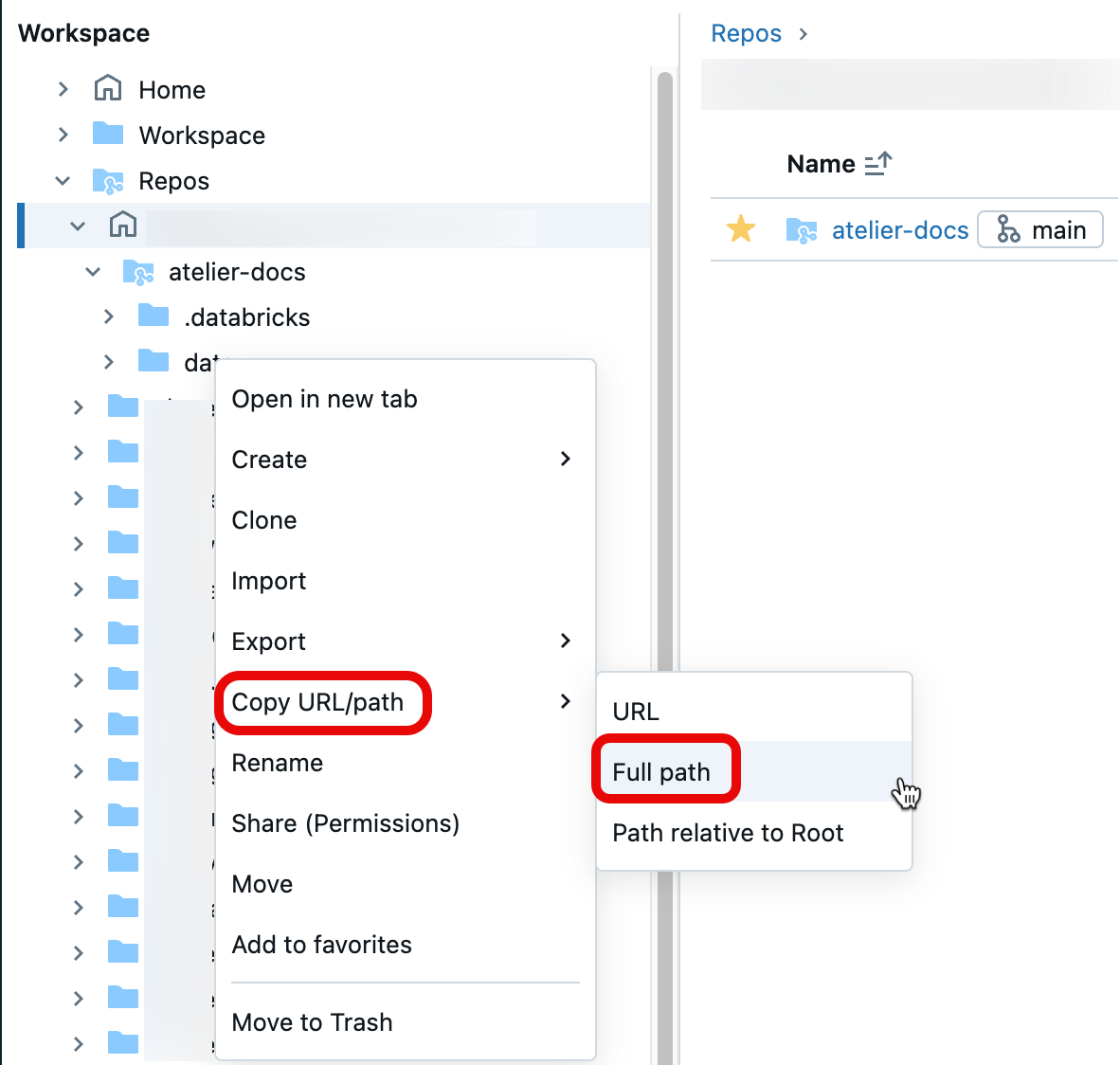
Para obter o caminho do arquivo, abra o menu de contexto clicando com o botão direito na pasta, bloco de notas ou arquivo em seu espaço de trabalho que você deseja compartilhar e selecione Copiar URL/caminho>Caminho completo. Anexe #workspace ao caminho do arquivo que você acabou de copiar e anexe a cadeia de caracteres resultante após o ?o=<16-digit-workspace-ID> para que corresponda ao formato de URL acima.
Exemplo de formulação de URL #1: URLs de pasta
Para compartilhar o URL da pasta do espaço de trabalho https://<databricks-instance>/browse/folders/1111111111111111?o=2222222222222222, remova a substring browse/folders/1111111111111111 do URL. Adicione #workspace seguido do caminho para a pasta ou objeto de espaço de trabalho que você deseja compartilhar.
Nesse caso, o caminho do espaço de trabalho é para uma pasta, /Workspace/Users/user@example.com/team-git/notebooks. Depois de copiar o caminho completo do seu espaço de trabalho, agora você pode construir o link compartilhável:
https://<databricks-instance>/?o=2222222222222222#workspace/Workspace/Users/user@example.com/team-git/notebooks
Exemplo 2 de formulação de URL: URLs do Notebook
Para compartilhar o URL do notebook https://<databricks-instance>/?o=1111111111111111#notebook/2222222222222222/command/3333333333333333, remova #notebook/2222222222222222/command/3333333333333333. Adicione #workspace seguido do caminho para a pasta ou objeto de espaço de trabalho.
Nesse caso, o caminho do workspace aponta para um notebook, /Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook. Depois de copiar o caminho completo do seu espaço de trabalho, agora você pode construir o link compartilhável:
https://<databricks-instance>/?o=1111111111111111#workspace/Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook
Agora você tem um URL estável para compartilhar um arquivo, pasta ou caminho de notebook! Para obter mais informações sobre URLs e identificadores, veja Obter identificadores para objetos de espaço de trabalho.