Acessar o Azure Data Lake Storage usando a passagem de credencial do Microsoft Entra ID (herdada)
Importante
Esta documentação foi desativada e pode não estar atualizada.
A passagem de credenciais foi preterida a partir do Databricks Runtime 15.0 e será removida em versões futuras do Databricks Runtime. O Databricks recomenda que você atualize para o Catálogo do Unity. O Unity Catalog simplifica a segurança e a governança de seus dados fornecendo um local central para administrar e auditar o acesso a dados em vários workspaces em sua conta. Veja O que é o Catálogo do Unity?.
Para uma postura aprimorada de segurança e governança, contate sua equipe de conta do Azure Databricks para desativar a passagem de credenciais em sua conta do Azure Databricks.
Observação
Este artigo contém referências ao termo lista de permissões, que o Azure Databricks não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
É possível autenticar automaticamente para Acessar o Azure Data Lake Storage Gen1 do Azure Databricks (ADLS Gen1) e o ADLS Gen2 de clusters do Azure Databricks com a mesma identidade do Microsoft Entra ID usada para entrar no Azure Databricks. Ao habilitar a passagem de credencial do Azure Data Lake Storage para seu cluster, os comandos executados nesse cluster podem ler e gravar dados no Azure Data Lake Storage sem exigir que você configure as credenciais da entidade de serviço para acesso ao armazenamento.
A passagem de credenciais do Azure Data Lake Storage tem suporte apenas com o Azure Data Lake Storage Gen1 e Gen2. O Armazenamento de Blob do Azure não dá suporte à passagem de credenciais.
Este artigo cobre:
- Habilitando a passagem de credencial para clusters padrão e de alta simultaneidade.
- Configurar a passagem de credencial e inicializar recursos de armazenamento em contas do ADLS.
- Acessar recursos do ADLS diretamente quando a passagem de credencial estiver habilitada.
- Acessar recursos do ADLS por meio de um ponto de montagem quando a passagem de credencial estiver habilitada.
- Recursos e limitações com suporte ao usar a passagem de credencial.
Os notebooks são incluídos para fornecer exemplos de como usar a passagem de credenciais com contas de armazenamento do ADLS Gen1 e ADLS Gen2.
Requisitos
- Plano Premium. Consulte Atualizar ou fazer downgrade de um workspace Azure Databricks para obter detalhes sobre como atualizar um plano padrão para um plano Premium.
- Uma conta de armazenamento do Azure Data Lake Storage Gen1 ou Gen2. As contas de armazenamento do Azure Data Lake Storage Gen2 devem usar o namespace hierárquico para trabalhar com a passagem de credencial do Azure Data Lake Storage. Consulte Criar uma conta de armazenamento para obter instruções sobre como criar uma ADLS Gen2, incluindo como habilitar o namespace hierárquico.
- Permissões de usuário configuradas corretamente para o Azure Data Lake Storage. Um Azure Databricks administrador precisa garantir que os usuários tenham as funções corretas, por exemplo, Colaborador de Dados de Blob do Armazenamento, para ler e gravar dados armazenados no Azure Data Lake Storage. Confira Usar o portal do Azure para atribuir uma função do Azure para acesso aos dados de blob e de fila.
- Entenda os privilégios dos administradores em workspaces que estão habilitados para a passagem e examine suas atribuições de administrador de workspace existentes. Os administradores do workspace podem gerenciar operações para seu workspace, incluindo adicionar usuários e entidades de serviço, criar clusters e delegar outros usuários para serem administradores do workspace. As tarefas de gerenciamento de workspace, como gerenciar a propriedade do trabalho e exibir notebooks, podem dar acesso indireto aos dados registrados no Azure Data Lake Storage. O administrador do workspace é uma função privilegiada que você deve distribuir cuidadosamente.
- Você não pode usar um cluster configurado com credenciais do ADLS, por exemplo, credenciais de entidade de serviço, com passagem de credencial.
Importante
Não é possível autenticar no Azure Data Lake Storage com suas credenciais do Microsoft Entra ID se você estiver por trás de um firewall que não foi configurado para permitir o tráfego para o Microsoft Entra ID. O Firewall do Azure bloqueia o acesso ao Active Directory por padrão. Para permitir o acesso, configure a marca de serviço AzureActiveDirectory. É possível encontrar informações equivalentes para soluções de virtualização de rede na marca AzureActiveDirectory no arquivo JSON intervalos de IP do Azure e marcas de serviço. Para obter mais informações, confira Marcas de serviço do Firewall do Azure.
Recomendações de registro em log
É possível registrar identidades passadas para o armazenamento do ADLS nos logs de diagnóstico do armazenamento do Azure. O registro em log de identidades permite que solicitações do ADLS sejam vinculadas a usuários individuais dos clusters Azure Databricks. Ative o log de diagnóstico em sua conta de armazenamento para começar a receber estes logs:
- Azure Data Lake Storage Gen1: siga as instruções em Habilitar o log de diagnóstico para sua conta do Data Lake Storage Gen1.
- Azure Data Lake Storage Gen2: configure usando o PowerShell com o comando
Set-AzStorageServiceLoggingProperty. Especifique 2.0 como a versão, pois o formato de entrada de log 2.0 inclui o nome principal do usuário na solicitação.
Habilitar a passagem de credenciais do Azure Data Lake Storage para um cluster de Alta Simultaneidade
Os clusters de alta simultaneidade podem ser compartilhados por vários usuários. Eles só suportam Python e SQL com passagem de credencial do Azure Data Lake Storage.
Importante
Habilitar a passagem de credencial do Azure Data Lake Storage para um cluster de Alta Simultaneidade bloqueia todas as portas no cluster, exceto as portas 44, 53 e 80.
- Ao criar um cluster, de definido Modo de Clustercomo Alta Simultaneidade.
- Em Opções Avançadas, selecione Habilitar passagem de credencial para acesso a dados no nível do usuário e permitir apenas comandos do Python e SQL.

Habilitar a passagem de credenciais do Azure Data Lake Storage para um cluster Standard
os clusters Standard com passagem de credencial são limitados a um único usuário. Os clusters Standard dão suporte a Python, SQL, Scala e R. No Databricks Runtime 10.4 LTS e superior, há suporte para sparklyr.
Você deve atribuir um usuário na criação do cluster, mas o cluster pode ser editado por um usuário com permissões PODE GERENCIAR a qualquer momento para substituir o usuário original.
Importante
O usuário atribuído ao cluster deve ter pelo menos uma permissão PODE ANEXAR A para o cluster para executar comandos no cluster. Os administradores do workspace e o criador do cluster têm permissões PODE GERENCIAR, mas não podem executar comandos no cluster, a menos que seja o usuário do cluster designado.
- Ao criar um cluster, definido o Modo de Cluster como Standard.
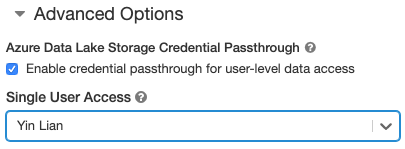
- Em Opções Avançadas, selecione Habilitar passagem de credencial para acesso a dados no nível do usuário e selecione o nome de usuário na lista suspensa Acesso de Usuário Único.
Criar um contêiner
Os contêineres fornecem uma maneira de organizar objetos em uma conta de armazenamento do Azure.
Acessar o Azure Data Lake Storage diretamente usando a passagem de credenciais
Depois de configurar a passagem de credencial do Azure Data Lake Armazenamento e criar contêineres de armazenamento, você pode acessar os dados diretamente no Azure Data Lake Storage Gen1 usando um caminho adl:// e o Azure Data Lake Storage Gen2 usando um caminho abfss://.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Substitua
<storage-account-name>pelo nome da ADLS Gen1 de armazenamento.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Substitua
<container-name>pelo nome de um contêiner na conta de armazenamento do ADLS Gen2. - Substitua
<storage-account-name>pelo nome da ADLS Gen2 de armazenamento.
Montar o Azure Data Lake Storage para DBFS usando a passagem de credenciais
Você pode montar uma conta do Azure Data Lake Storage ou uma pasta dentro dela em O que é DBFS?. A montagem é um ponteiro para um repositório data lake, portanto, os dados nunca são sincronizados localmente.
Ao montar dados usando um cluster habilitado com passagem de credencial do Azure Data Lake Storage, todas as leituras ou gravações no ponto de montagem usam suas credenciais do Microsoft Entra ID. Esse ponto de montagem ficará visível para outros usuários, mas os únicos usuários que terão acesso de leitura e gravação são aqueles que:
- Têm acesso à conta de armazenamento subjacente do Azure Data Lake Storage
- Estão usando um cluster habilitado para passagem de credencial do Azure Data Lake Storage
Azure Data Lake Storage Gen1
Para montar um recurso do Azure Data Lake Storage Gen1 ou uma pasta dentro dele, use os seguintes comandos:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Substitua
<storage-account-name>pelo nome da ADLS Gen2 de armazenamento. - Substitua
<mount-name>pelo nome do ponto de montagem pretendido no DBFS.
Azure Data Lake Storage Gen2
Para montar um sistema de arquivos do Azure Data Lake Storage Gen2 ou uma pasta dentro dele, use os seguintes comandos:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Substitua
<container-name>pelo nome de um contêiner na conta de armazenamento do ADLS Gen2. - Substitua
<storage-account-name>pelo nome da ADLS Gen2 de armazenamento. - Substitua
<mount-name>pelo nome do ponto de montagem pretendido no DBFS.
Aviso
Não forneça as chaves de acesso da conta de armazenamento ou as credenciais da entidade de serviço para autenticar no ponto de montagem. Isso dará a outros usuários acesso ao sistema de arquivos usando essas credenciais. A finalidade da passagem de credencial do Azure Data Lake Storage é impedir que você tenha que usar essas credenciais e garantir que o acesso ao sistema de arquivos seja restrito aos usuários que têm acesso à conta subjacente do Azure Data Lake Storage.
Segurança
É seguro compartilhar o Azure Data Lake Storage de passagem de credenciais com outros usuários. Você será isolado uns dos outros e não poderá ler nem usar as credenciais uns dos outros.
Recursos compatíveis
| Recurso | Versão mínima do Databricks Runtime | Observações |
|---|---|---|
| Python e SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | As credenciais serão passadas somente se o caminho do DBFS for resolvido para um local no Azure Data Lake Storage Gen1 ou Gen2. Para caminhos do DBFS que resolvem para outros sistemas de armazenamento, use um método diferente para especificar suas credenciais. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| cache de disco | 5.5 | |
| API do PySpark do ML | 5.5 | As seguintes classes de ML não há suporte: - org/apache/spark/ml/classification/RandomForestClassifier- org/apache/spark/ml/clustering/BisectingKMeans- org/apache/spark/ml/clustering/GaussianMixture- org/spark/ml/clustering/KMeans- org/spark/ml/clustering/LDA- org/spark/ml/evaluation/ClusteringEvaluator- org/spark/ml/feature/HashingTF- org/spark/ml/feature/OneHotEncoder- org/spark/ml/feature/StopWordsRemover- org/spark/ml/feature/VectorIndexer- org/spark/ml/feature/VectorSizeHint- org/spark/ml/regression/IsotonicRegression- org/spark/ml/regression/RandomForestRegressor- org/spark/ml/util/DatasetUtils |
| Variáveis de difusão | 5.5 | No PySpark, há um limite no tamanho das UDFs do Python que você pode construir, pois UDFs grandes são enviadas como variáveis de difusão. |
| Bibliotecas no escopo do notebook | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Executar um notebook do Databricks por meio de outro notebook | 6.1 | |
| API do PySpark do ML | 6.1 | Todas as classes do PySpark do ML com suporte. |
| Métricas de cluster | 6.1 | |
| Databricks Connect | 7.3 | A passagem tem suporte em clusters Standard. |
Limitações
Não há suporte para os seguintes recursos com a passagem de credenciais do Azure Data Lake Storage:
%fs(use o comando dbutils.fs equivalente).- Trabalhos do Databricks.
- A Referência da API REST do Databricks.
- Unity Catalog.
- Controle de acesso à tabela. As permissões concedidas pela passagem de credencial do Azure Data Lake Storage podem ser usadas para ignorar as permissões finas das ACLs de tabela, enquanto as restrições extras das ACLs de tabela restringirão alguns dos benefícios que você obterá da passagem de credenciais. Especialmente:
- Se você tiver permissão do Microsoft Entra ID para acessar os arquivos de dados que se baseiam em uma tabela específica, terá permissões completas nessa tabela por meio da API do RDD, independentemente das restrições colocadas neles por meio de ACLs de tabela.
- Você será restrito por permissões de ACLs de tabela somente ao usar a API do DataFrame. Você verá avisos sobre não ter permissão
SELECTem nenhum arquivo se tentar ler arquivos diretamente com a API do DataFrame, mesmo que você possa ler esses arquivos diretamente por meio da API do RDD. - Você não poderá ler de tabelas com suporte de sistemas de arquivos diferentes do Azure Data Lake Storage, mesmo se você tiver permissão de ACL de tabela para ler as tabelas.
- Os seguintes métodos em objetos SparkContext (
sc) e SparkSession (spark):- Métodos preteridos.
- Métodos como
addFile()eaddJar()que permitiriam que usuários não administradores chamasse código Scala. - Qualquer método que acesse um sistema de arquivos diferente do Azure Data Lake Storage Gen1 ou Gen2 (para acessar outros sistemas de arquivos em um cluster com a passagem de credencial do Azure Data Lake Storage habilitada, use um método diferente para especificar suas credenciais e consulte a seção sobre sistemas de arquivos confiáveis em Solução de problemas).
- As APIs antigas do Hadoop (
hadoopFile()ehadoopRDD()). - APIs de streaming, uma vez que as credenciais passadas expiram enquanto o fluxo ainda estava em execução.
- As montagens DBFS (
/dbfs) estão disponíveis somente no Databricks Runtime 7.3 LTS e superior. Não há suporte para pontos de montagem com passagem de credencial configurada por esse caminho. - Azure Data Factory.
- MLflow em clusters de alta simultaneidade.
- azureml-sdk Pacote Python em clusters de alta simultaneidade.
- Você não pode estender o tempo de vida dos tokens de passagem do Microsoft Entra ID usando as políticas de tempo de vida do token do Microsoft Entra ID. Como consequência, se você enviar um comando para o cluster que leva mais de uma hora, ele falhará se um recurso do Azure Data Lake Storage for acessado após a marca de 1 hora.
- Ao usar o Hive 2.3 e superior, você não pode adicionar uma partição em um cluster com a passagem de credencial habilitada. Para obter mais informações, consulte a seção de Solucionar problemas relevantes.
Notebooks de exemplo
Os notebooks a seguir demonstram a passagem de credenciais do Azure Data Lake Storage para Azure Data Lake Storage Gen1 e Gen2.
Notebook de passagem do Azure Data Lake Storage Gen1
Notebook de passagem do Azure Data Lake Storage Gen2
Solução de problemas
py4j.security.Py4JSecurityException: … não está na lista de verificação
Essa exceção é gerada quando você acessa um método que o Azure Databricks não marcou explicitamente como seguro para clusters de passagem de credenciais do Azure Data Lake Storage. Na maioria dos casos, isso significa que o método pode permitir que um usuário em um cluster com passagem de credenciais do Azure Data Lake Storage acesse as credenciais de outro usuário.
org.apache.spark.api.python.PythonSecurityException: Path … usa um sistema de arquivos não falso
Essa exceção é lançada ao tentar acessar um sistema de arquivos que não é conhecido pelo cluster de passagem de credenciais do Azure Data Lake Storage para ser seguro. Usar um sistema de arquivos não confiável pode permitir que um usuário em um cluster de passagem de credencial do Azure Data Lake Storage acesse as credenciais de outro usuário, portanto, não permitimos que todos os sistemas de arquivos que não estamos confiantes sejam usados com segurança.
Para configurar o conjunto de sistemas de arquivos confiáveis em um cluster de passagem de credencial do Azure Data Lake Storage, deverão definir a chave de conf do Spark spark.databricks.pyspark.trustedFilesystems nesse cluster como uma lista separada por vírgulas dos nomes de classe que são implementações confiáveis do org.apache.hadoop.fs.FileSystem.
A adição de uma partição falha com AzureCredentialNotFoundException quando a passagem de credencial está habilitada
Ao usar o Hive 2.3-3.1, se você tentar adicionar uma partição em um cluster com a passagem de credencial habilitada, ocorrerá a seguinte exceção:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Para resolver esse problema, adicione partições em um cluster sem a passagem de credencial habilitada.