Julho de 2019
Esses recursos e melhorias da plataforma Azure Databricks foram lançados em julho de 2019.
Observação
As versões são disponibilizadas em fases. Talvez sua conta do Azure Databricks só seja atualizada uma semana após a data de lançamento inicial.
Em breve! O Databricks 6.0 não dará suporte a Python 2
Em antecipação ao futuro fim da vida útil do Python 2, anunciado para 2020, o Python 2 não terá suporte no Databricks Runtime 6.0. As versões anteriores do Databricks Runtime continuarão a dar suporte ao Python 2. Esperamos lançar o Databricks Runtime 6.0 posteriormente em 2019.
Pré-carregar a versão Databricks Runtime em instâncias ociosas do pool
30 de julho – 6 de agosto de 2019: versão 2.103
Agora você pode acelerar as iniciações de cluster com suporte de pool selecionando uma Databricks Runtime para ser carregada em instâncias ociosas no pool. O campo na interface do usuário do pool é chamado de Versão do Spark Pré-carregada.

Marcas de cluster personalizadas e marcas de pool funcionam melhor juntas
30 de julho – 6 de agosto de 2019: versão 2.103
No início deste mês, pools do Azure Databricks, um conjunto de instâncias ociosas que ajudam a criar clusters rapidamente. Na versão original, os clusters com suporte de pool herdaram marcas padrão e personalizadas da configuração do pool e você não pôde modificar essas marcas no nível do cluster. Agora você pode configurar marcas personalizadas específicas a um cluster com suporte de pool e esse cluster aplicará todas as marcas personalizadas, sejam herdadas do pool ou atribuídas especificamente a esse cluster. Você não pode adicionar uma marca personalizada específica do cluster com o mesmo nome de chave que uma marca personalizada herdada de um pool (ou seja, não é possível substituir uma marca personalizada herdada do pool). Para obter detalhes, confira Marcas de pool.
O MLflow 1.1 traz vários aprimoramentos na interface do usuário e na API
30 de julho – 6 de agosto de 2019: versão 2.103
O MLflow 1.1 apresenta vários novos recursos para melhorar a usabilidade da interface do usuário e da API:
A interface do usuário de visão geral das execuções agora permite navegar por várias páginas de execuções se o número de execuções exceder 100. Após a 100ª, clique no botão Carregar mais para carregar as próximas 100 execuções.
A interface do usuário de comparar executa agora fornece um gráfico de coordenadas paralelas. O gráfico permite que você observe as relações entre um conjunto enedimensional de parâmetros e métricas. Ele visualiza todas as execuções como linhas codificadas por cores com base no valor de uma métrica (por exemplo, precisão) e mostra os valores de parâmetro que cada executado levou.
Agora você pode adicionar e editar marcas da interface do usuário de visão geral de executar e exibir marcas na exibição de pesquisa de experimento.
A nova API MLflowContext permite criar e registrar em log as execuções de uma maneira semelhante à API do Python. Essa API contrasta com a API de nível baixo
MlflowClientexistente, que simplesmente envolve as APIs REST.Agora você pode excluir marcas de execuções do MLflow usando a API DeleteTag.
Para obter detalhes, confira a Postagem no blog do MLflow 1.1. Para ver a lista completa de recursos e correções, confira o Log de alteração do MLflow.
O DataFrame do Pandas exibe renderizações como faz no Jupyter
30 de julho – 6 de agosto de 2019: versão 2.103
Agora, quando você chamar um DataFrame pandas, ele renderizará da mesma maneira do que no Jupyter.
Novas regiões
30 de julho de 2019
O Azure Databricks agora está disponível nas seguintes regiões adicionais:
- Coreia Central
- Norte da África do Sul
Limite de conexão do metastore atualizado
16 - 23 de julho de 2019: versão 2.102
Os novos espaços de trabalho do Azure Databricks no eastus, eastus2, centralus, westus, westus2, westeurope, northeurope terão um limite de conexão de metastore superior a 250. Os espaços de trabalho existentes continuarão a usar o metastore atual sem interrupção e continuarão a ter um limite de conexão de 100.
Definir permissões em pools (visualização pública)
16 - 23 de julho de 2019: versão 2.102
A interface do usuário do pool agora dá suporte à configuração de permissões em quem pode gerenciar pools e quem pode anexar clusters a pools.
Para obter detalhes, confira Permissões do pool.
Databricks Runtime 5.5 para Machine Learning
15 de julho de 2019
O Databricks Runtime 5.5 ML foi desenvolvido com base no Databricks Runtime 5.5 LTS (EoS). Ele contém muitas bibliotecas populares de aprendizado de máquina, incluindo TensorFlow, PyTorch, Keras e XGBoost, e fornece treinamento de TensorFlow distribuído usando o Horovod.
Esta versão inclui os seguintes novos recursos e melhorias:
- Adicionado o pacote Python do MLflow 1.0
- Atualização das bibliotecas de aprendizado de máquina
- TensorFlow atualizado da 1.12.0 para a 1.13.1
- PyTorch atualizado de 0.4.1 para 1.1.0
- scikit-learn atualizado de 0.19.1 para 0.20.3
- Operação de nó único para HorovodRunner
Para ver detalhes, consulte Databricks Runtime 5.5 LTS para ML (EoS).
Databricks Runtime 5.5
15 de julho de 2019
O Databricks Runtime 5.5 já está disponível. O Databricks Runtime 5.5 inclui Apache Spark 2.4.3, bibliotecas Python, R, Java e Scala aprimoradas, bem como os seguintes novos recursos:
- Delta Lake no Azure Databricks GA de otimização automática
- Desempenho de consulta de agregação min, max e count aprimorado do Data Lake no Azure Databricks
- Pipelines de inferência de modelo mais rápidos com uma fonte de dados de arquivo binário aprimorada e UDF do iterador escalar pandas (versão preliminar pública)
- API de Segredos em notebooks R
Para obter detalhes, consulte a Databricks Runtime 5.5 LTS (EoS).
Manter um pool de instâncias em espera para a inicialização rápida do cluster (visualização pública)
9 - 11 de julho de 2019: versão 2.101
Para reduzir a hora de início do cluster, o Azure Databricks agora dá suporte à anexação de um cluster a um pool pré-definido de instâncias ociosas. Quando anexado a um pool, um cluster aloca o driver e os nós de trabalho do pool. Se o pool não tiver recursos ociosos suficientes para acomodar a solicitação do cluster, o pool se expandirá alocando novas instâncias do provedor de instâncias. Quando um cluster anexado é encerrado, as instâncias usadas por ele são retornadas para o pool e podem ser reutilizadas por outro cluster.
O Azure Databricks não cobra DBUs enquanto as instâncias estão ociosas no pool. A cobrança do provedor de instâncias se aplica. Confira o preço.
Para obter detalhes, confira Referência de configuração do pool.
Métricas de Ganglia
9 - 11 de julho de 2019: versão 2.101
Ganglia é um sistema de monitoramento distribuído escalonável que agora está disponível em clusters do Azure Databricks. As métricas do Ganglia ajudam você a monitorar o desempenho e a integridade do cluster. Você pode acessar as métricas do Ganglia na página de detalhes do cluster:
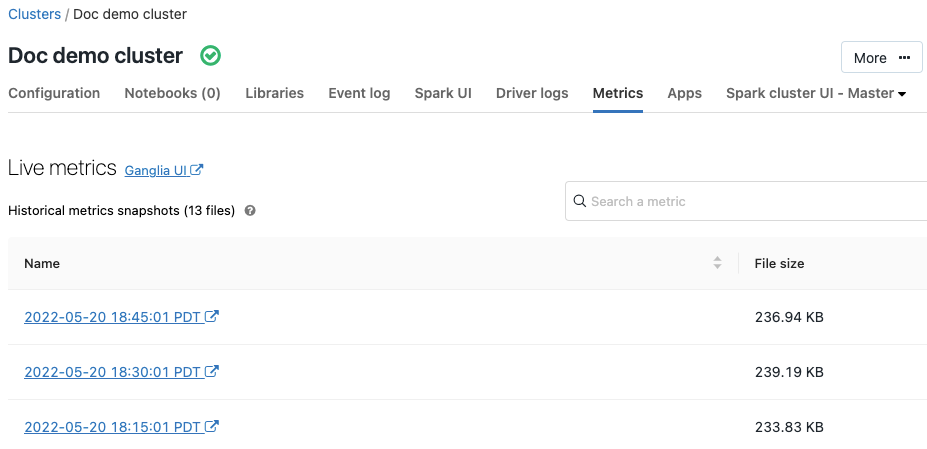
Para obter detalhes sobre como usar e configurar as métricas, confira Métricas do Ganglia.
Cor da série de gráfico
9 - 11 de julho de 2019: versão 2.101
Agora você pode especificar que as cores de uma série devem ser consistentes em todos os gráficos em seu notebook. Confira Consistência de cores entre gráficos.