Junho de 2018
Esses recursos e aprimoramentos da plataforma do Databricks foram lançados em junho de 2018.
Integração RStudio
19 de junho de 2018: Versão 2.74
Agora o Azure Databricks se integra ao RStudio Server, o IDE popular para R. Com essa nova integração poderosa, você pode:
- Iniciar a interface do usuário do RStudio diretamente no Azure Databricks.
- Importar pacotes SparkR e sparklyr dentro do IDE do RStudio.
- Acessar, explorar e transformar grandes conjuntos de dados do IDE do RStudio usando o Apache Spark.
- Executar e monitorar trabalhos do Spark em um cluster do Azure Databricks.
- Gerenciar seu código usando o controle de versão.
- Usar as edições Open Source ou Pro do RStudio Server no Azure Databricks.
A integração do RStudio exige o plano Premium. Você deve instalar a integração em um cluster de alta simultaneidade. Para obter detalhes, confira RStudio no Azure Databricks.
Limpar log de cluster
19 de junho de 2018: Versão 2.74
Por padrão, os logs são retidos por 30 dias. Agora você pode excluí-los permanente e imediatamente acessando a guia Armazenamento do Workspace no Console de Administração. Confira como Limpar o armazenamento do workspace.
Novas regiões
7 de junho 2018
O Azure Databricks agora está disponível nas seguintes regiões:
- Leste da Austrália
- Sudeste da Austrália
- Sul do Reino Unido
- Oeste do Reino Unido
Pasta da lixeira
7 de junho de 2018: Versão 2.73
Uma nova pasta ![]() Lixeira contém todos os notebooks, bibliotecas e pastas que você excluiu. A pasta Lixeira é limpa automaticamente após 30 dias. Você pode restaurar um objeto excluído arrastando-o para fora da pasta Lixeira e soltando-o em outra pasta.
Lixeira contém todos os notebooks, bibliotecas e pastas que você excluiu. A pasta Lixeira é limpa automaticamente após 30 dias. Você pode restaurar um objeto excluído arrastando-o para fora da pasta Lixeira e soltando-o em outra pasta.
Para obter detalhes, confira Excluir um objeto.
Período de retenção de log reduzido
7 de junho de 2018: Versão 2.73
Agora os logs de cluster são retidos por 30 dias. Antes, eles eram retidos indefinidamente.
Respostas da API do gzip
7 de junho de 2018: Versão 2.73
As solicitações enviadas com o cabeçalho Accept-Encoding: gzip retornam respostas gzipped.
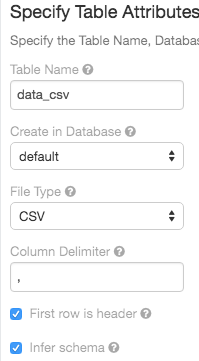
IU de importação de tabela
7 de junho de 2018: Versão 2.73
Agora, a interface do usuário criar tabela dá suporte a uma opção para inferir o esquema de arquivos CSV: