Abril de 2018
As versões são disponibilizadas em fases. Sua conta do Azure Databricks pode não ser atualizada até uma semana após a data de lançamento inicial.
Nota
Agora estamos fornecendo avisos de desativação do Databricks Runtime nas versões das notas sobre a versão e compatibilidade do Databricks Runtime.
CLI de Segredos
26 de abril de 20180
A CLI do Databricks versão 0.7.0 oferece o poder de gerenciar segredos da linha de comando. A documentação de segredos agora mostra como usar os comandos da CLI de Segredos para criar e gerenciar segredos.
Confira Gerenciamento de segredos.
Guias de Aprendizado Profundo
24 de abril de 2018
Adicionamos documentação para o Deep Learning no Azure Databricks usando clusters de CPU.
Confira Aprendizado profundo.
Atualização da API de Segredos para criar escopo de segredos
25 de abril a 1º de maio de 2018: versão 2.70
O endpoint Create Secret Scope (2.0/preview/secret/scopes/create) agora descontinua o campo initial_manage_acl e usa initial_manage_principal em seu lugar. O novo campo fornece a mesma funcionalidade, mas semântica melhor.
Confira API de Segredos.
Dicas de erro do Spark
24 de abril a 1º de maio de 2018: versão 2.70
O Azure Databricks agora fornece dicas para ajudá-lo a interpretar e solucionar muitos dos erros que você pode ver ao executar comandos do Spark. E continuaremos adicionando mais.
dicas sobre erros do 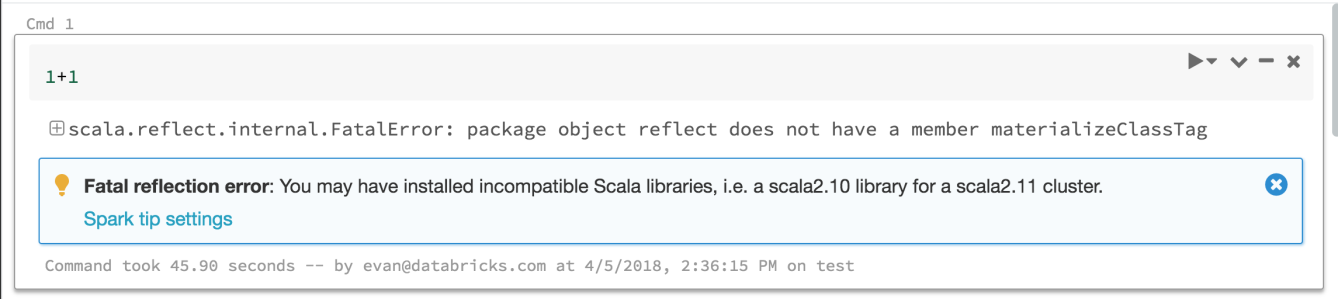
CLI 0.7.0 do Databricks
24 de abril de 2018
A CLI do Databricks 0.7.0 inclui correções de bug.
Ela também fornece uma interface de linha de comando para a API de Segredos.
Confira CLI do Databricks (herdada).
Aumentar o limite de truncamento da saída do script de inicialização
24 de abril a 1º de maio de 2018: versão 2.70
Aumentamos o limite de truncamento de saída para scripts init para 500.000 caracteres.
Confira O que são scripts de inicialização?.
API de clusters: adicionado evento do tipo UPSIZE_COMPLETED
24 de abril a 1º de maio de 2018: versão 2.70
O novo tipo de evento de cluster UPSIZE_COMPLETED indica que os nós terminaram de ser adicionados a um cluster.
Confira API de Clusters na referência da API de Clusters.
Preenchimento automático de comando
10 a 17 de abril de 2018: versão 2.69
O Azure Databricks agora dá suporte a dois tipos de preenchimento automático em seus notebooks: local e servidor. O preenchimento automático local completa palavras que existem no caderno de anotações. O preenchimento automático de servidor é mais avançado porque acessa o cluster para tipos, classes e objetos definidos, além de banco de dados SQL e nomes de tabelas. Para ativar o preenchimento automático do servidor, você deve anexar seu notebook a um cluster em execução e executar todas as células que definem objetos completáveis.
de preenchimento automático do Bloco de Anotações do
Pools sem servidor atualizados para o Databricks Runtime 4.0
10 de abril de 2018
A versão de runtime de pools sem servidor foi atualizada do Databricks Runtime 3.5 (que inclui o Apache Spark 2.2.1) para Databricks Runtime 4.0 (que inclui o Apache Spark 2.3.0). É preciso reiniciar os clusters para obter essa alteração.
A atualização representa uma atualização de versão secundária do Apache Spark e é compatível com versões anteriores.