O que significam os intervalos de tokens por segundo na taxa de transferência provisionada?
Este artigo descreve como e por que o Databricks mede tokens por segundo para cargas de trabalho de taxa de transferência provisionada para APIs do Modelo de Base.
O desempenho de LLMs (modelos de linguagem grandes) geralmente é medido em termos de tokens por segundo. Ao configurar o modelo de produção que atende pontos de extremidade, é importante considerar o número de solicitações que seu aplicativo envia para o ponto de extremidade. Isso ajuda você a entender se o endpoint precisa ser configurado para escalar de forma a não afetar a latência.
Ao configurar os intervalos de expansão para pontos de extremidade implantados com taxa de transferência provisionada, o Databricks encontrou mais facilidade para raciocinar sobre as entradas indo para o sistema usando tokens.
O que são tokens?
Os LLMs leem e geram textos em termos do que é chamado de token. Tokens podem ser palavras ou sub-palavras, e as regras exatas para segmentar o texto em tokens variam de modelo para modelo. Por exemplo, você pode usar ferramentas online para saber como o tokenizador do Llama converte palavras em tokens.
O diagrama a seguir mostra um exemplo de como o tokenizador Llama segmenta o texto:
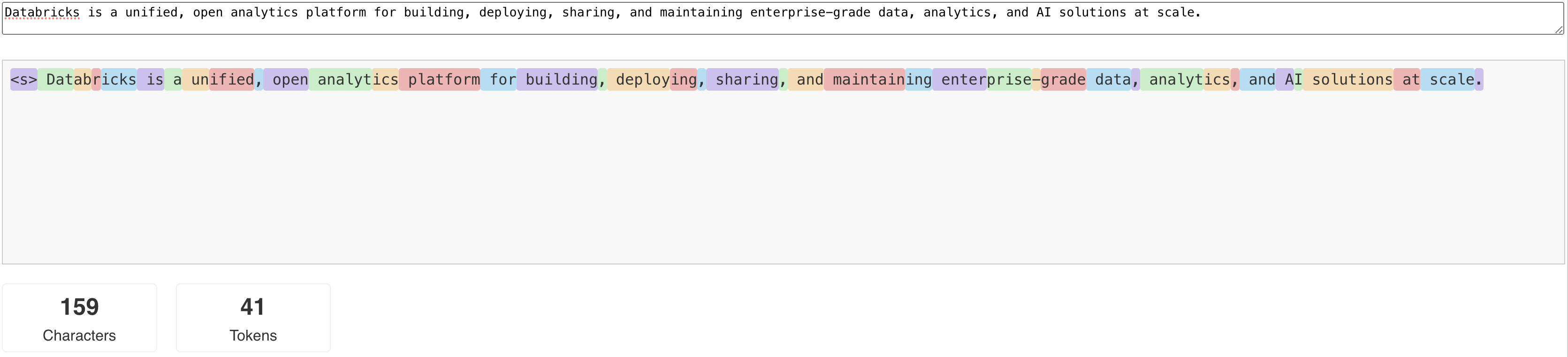 llama-tokenizer-example
llama-tokenizer-example
Por que medir o desempenho do LLM em termos de tokens por segundo?
Tradicionalmente, os pontos de extremidade de serviço são configurados com base no número de RPS (solicitações simultâneas por segundo). No entanto, uma solicitação de inferência de LLM demora uma quantidade de tempo diferente com base na quantidade de tokens passados e na quantidade de tokens que ele gera, que pode entrar em desequilíbrio entre as solicitações. Portanto, decidir a escala horizontal necessária para o ponto de extremidade requer medir a escala do ponto de extremidade em termos do conteúdo de sua solicitação: os tokens.
Diferentes casos de uso apresentam diferentes taxas de token de entrada e saída:
- Diferentes comprimentos de contextos de entrada: embora algumas solicitações possam envolver apenas alguns tokens de entrada, por exemplo, uma pergunta curta, outras podem envolver centenas ou até milhares de tokens, como um documento longo para resumo. Essa variabilidade torna a configuração de um ponto de extremidade de serviço com base apenas no RPS desafiador, pois não contabiliza as diferentes demandas de processamento das diferentes solicitações.
- Comprimentos variáveis de saída dependendo do caso de uso: diferentes casos de uso para LLMs podem levar a comprimentos de token de saída muito diferentes. A geração de tokens de saída é a parte mais demorada da inferência de LLM, portanto, isso pode afetar drasticamente a taxa de transferência. Por exemplo, a sumarização envolve respostas mais curtas e concisas, mas a geração de texto, como escrever artigos ou descrições de produto, pode gerar respostas muito mais longas.
Como fazer para selecionar o intervalo de tokens por segundo do meu ponto de extremidade?
Os pontos de extremidade de fornecimento de taxa de transferência provisionada são configurados em termos de um intervalo de tokens por segundo que você pode enviar ao ponto de extremidade. O ponto de extremidade é escalado verticalmente/horizontalmente para lidar com a carga do seu aplicativo de produção. Você será cobrado por hora com base em um intervalo de tokens por segundo para o qual seu ponto de extremidade será escalado.
A melhor maneira de saber em qual intervalo de tokens por segundo seu ponto de extremidade do serviço de taxa de transferência provisionada funciona para o seu caso de uso é realizar um teste de carga com um conjunto de dados representativo. Consulte Conduzir seu próprio parâmetro de comparação de ponto de extremidade do LLM.
Há dois fatores importantes a serem considerados:
- Como o Databricks mede o desempenho de tokens por segundo da LLM.
- Como funciona o dimensionamento automático.
Como o Databricks mede o desempenho de tokens por segundo do LLM
O Databricks compara os pontos de extremidade com uma carga de trabalho que representa tarefas de resumo comuns para casos de uso de geração com recuperação aumentada. Especificamente, a carga de trabalho consiste em:
- 2048 tokens de entrada
- 256 tokens de saída
Os intervalos de token exibidos combinam a taxa de transferência de token de entrada e saída e, por padrão, otimizam o equilíbrio entre a taxa de transferência e a latência.
O Databricks comprova que os usuários podem enviar muitos tokens por segundo simultaneamente para o ponto de extremidade em um tamanho de lote de um por solicitação. Isso simula várias solicitações atingindo o ponto de extremidade ao mesmo tempo, o que representa com mais precisão como você realmente usaria o ponto de extremidade em produção.
- Por exemplo, se um ponto de extremidade do serviço de taxa de transferência provisionada tiver uma taxa definida de 2.304 tokens por segundo (2.048 + 256), uma solicitação com uma entrada de 2.048 tokens e uma saída esperada de 256 tokens deverá levar cerca de um segundo para ser processada.
- Da mesma forma, se a taxa estiver definida como 5600, você poderá esperar que uma única solicitação, com as contagens de token de entrada e saída acima, leve cerca de 0,5 segundos para ser executada – ou seja, o ponto de extremidade pode processar duas solicitações semelhantes em cerca de um segundo.
Se a sua carga de trabalho variar do que foi mencionado acima, você pode esperar que a latência varie em relação à taxa de transferência provisionada listada. Conforme indicado anteriormente, gerar mais tokens de saída é mais demorado do que incluir mais tokens de entrada. Se você estiver executando inferência em lotes e quiser estimar o tempo necessário para a conclusão, pode calcular o número médio de tokens de entrada e saída e compará-los com a carga de trabalho de referência do Databricks acima.
- Por exemplo, se você tiver 1.000 linhas, com uma contagem média de tokens de entrada de 3.000 e uma contagem média de tokens de saída de 500 e uma taxa de transferência provisionada de 3.500 tokens por segundo, poderá levar mais do que o total de 1.000 segundos (um segundo por linha) devido à contagem média de tokens ser maior do que o parâmetro de comparação do Databricks.
- Da mesma forma, se você tiver 1.000 linhas, uma entrada média de 1.500 tokens, uma saída média de 100 tokens e uma taxa de transferência provisionada de 1.600 tokens por segundo, poderá levar menos do que o total de 1.000 segundos (um segundo por linha) devido à contagem média de tokens ser menos do que o parâmetro de comparação do Databricks.
Para estimar a taxa de transferência provisionada ideal necessária para concluir sua carga de trabalho de inferência em lotes, você pode usar o notebook em Executar inferência de LLM em lote usando ai_query
Como funciona o dimensionamento automático
O Model Serving apresenta um sistema de dimensionamento automático rápido que dimensiona a computação subjacente para atender à demanda de tokens por segundo do aplicativo. O Databricks aumenta a taxa de throughput provisionada em blocos de tokens por segundo, de modo que você só é cobrado por unidades adicionais de taxa de throughput provisionada quando efetivamente as utiliza.
O grafo de taxa de transferência/latência a seguir mostra um ponto de extremidade de taxa de transferência provisionada testado com um número crescente de solicitações paralelas. O primeiro ponto representa 1 solicitação, a segunda, duas solicitações paralelas, a terceira, quatro solicitações paralelas e assim por diante. À medida que o número de solicitações aumenta e, consequentemente, a demanda por tokens por segundo cresce, você percebe que a taxa de transferência provisionada também aumenta. Esse aumento indica que o dimensionamento automático aumenta a computação disponível. No entanto, você pode começar a ver que a taxa de transferência começa a se estabilizar, atingindo um limite de aproximadamente 8.000 tokens por segundo à medida que mais requisições paralelas são feitas. A latência total aumenta à medida que mais solicitações precisam aguardar na fila antes de serem processadas porque a computação alocada está sendo usada simultaneamente.
Nota
Você pode manter a taxa de transferência consistente desativando a escala para zero e configurando uma taxa de transferência mínima no ponto de extremidade do serviço. Isso evita a necessidade de aguardar o ponto de extremidade escalar verticalmente.
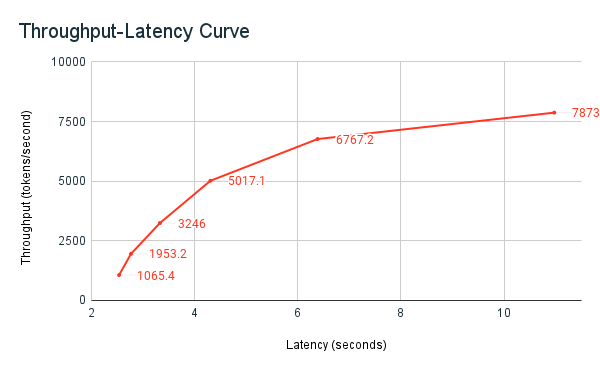
Você também pode ver no ponto de extremidade do Serviço de Modelo como os recursos são rotacionados para cima ou para baixo, dependendo da demanda: