Utilize tabelas online para o fornecimento de recursos em tempo real
Importante
As tabelas online estão em Visualização Pública nas seguintes regiões: westus, eastus, eastus2, northeurope, westeurope. Para obter informações sobre preços, consulte Preços de tabelas online.
Uma tabela online é uma cópia somente leitura de uma Tabela Delta que é armazenada em um formato orientado por linha otimizado para acesso online. As tabelas online são tabelas totalmente sem servidor que dimensionam automaticamente a capacidade de taxa de transferência com a carga de solicitação e fornecem acesso de baixa latência e alta taxa de transferência a dados de qualquer escala. As tabelas online são projetadas para trabalhar com Serviço de Modelo do Mosaic AI, Serviço de Recursos e RAG (geração aumentada de recuperação), em que são usadas para pesquisas de dados rápidas.
Você também pode usar tabelas online em consultas usando Lakehouse Federation. Ao usar Lakehouse Federation, você deve usar um SQL warehouse sem servidor para acessar tabelas online. Há suporte apenas para operações de leitura (SELECT). Essa funcionalidade destina-se apenas a fins interativos ou de depuração e não deve ser usada para cargas de trabalho críticas ou de produção.
A criação de uma tabela online usando a interface do usuário do Databricks é um processo de uma etapa. Basta selecionar a tabela Delta no Gerenciador de Catálogos e selecionar Criar tabela online. Você também pode usar a API REST ou o SDK do Databricks para criar e gerenciar tabelas online. Consulte Trabalhar com tabelas online usando APIs.
Requisitos
- O workspace deve ser habilitado para o Catálogo do Unity. Siga a documentação para criar um Metastore de Catálogo do Unity, habilitá-lo em um espaço de trabalho e criar um Catálogo.
- Um modelo deve ser registrado no Catálogo do Unity para acessar tabelas online.
Trabalhar com tabelas online usando a interface do usuário
Esta seção descreve como criar e excluir tabelas online e como verificar o status e disparar atualizações de tabelas online.
Criar uma tabela online usando a interface do usuário
Você cria uma tabela online usando o Explorador de Catálogos. Para obter informações sobre as permissões necessárias, confira Permissões de acesso do usuário.
Para criar uma tabela online, a tabela Delta de origem deve ter uma chave primária. Se a tabela Delta que você deseja usar não tiver uma chave primária, crie uma seguindo estas instruções: Usar uma tabela Delta existente no Unity Catalog como uma tabela de recursos.
No Gerenciador de Catálogos, navegue até a tabela de origem que deseja sincronizar com uma tabela online. No menu Criar, selecione Tabela online.
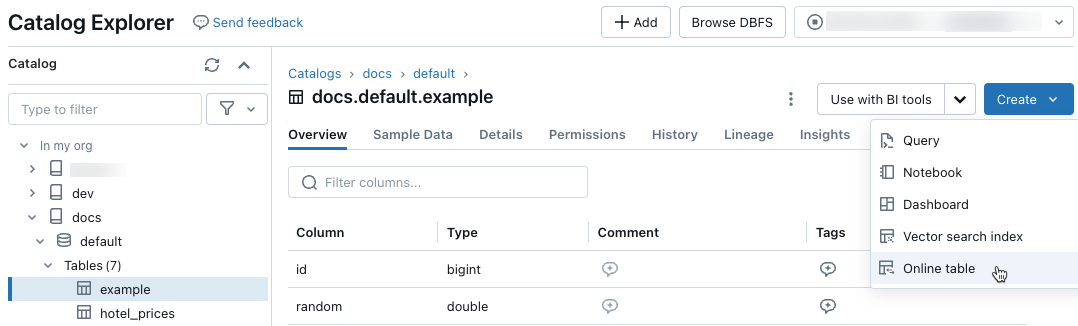
Use os seletores na caixa de diálogo para configurar a tabela online.
Nome: nome a ser usado para a tabela online no Catálogo do Unity.
Chave primária: coluna(s) na tabela de origem a ser(em) usada(s) como chave(s) primária(s) na tabela online.
Chaves Timeseries: (Opcional). Coluna na tabela de origem a ser usada como chave de série temporal. Quando especificado, a tabela online inclui apenas a linha com o valor de chave de série temporal mais recente para cada chave primária.
Modo de sincronização: especifica como o pipeline de sincronização atualiza a tabela online. Selecione uma das opções Instantâneo, Disparado ou Contínuo.
Política Descrição Instantâneo O pipeline é executado uma vez para tirar um instantâneo da tabela de origem e copiá-lo para a tabela online. As alterações subsequentes na tabela de origem são refletidas automaticamente na tabela online, tirando um novo instantâneo da origem e criando uma nova cópia. O conteúdo da tabela online é atualizado atomicamente. Disparado O pipeline é executado uma vez para criar uma cópia instantânea inicial da tabela de origem na tabela online. Ao contrário do modo de sincronização de instantâneo, quando a tabela online é atualizada, somente as alterações desde a última execução do pipeline são recuperadas e aplicadas à tabela online. A atualização incremental pode ser disparada manualmente ou automaticamente de acordo com um agendamento. Contínuo O pipeline é executado continuamente. As alterações subsequentes na tabela de origem são aplicadas de forma incremental à tabela online no modo de streaming em tempo real. Não é necessária nenhuma atualização manual.
Observação
Para dar suporte ao modo de sincronização Disparado ou Contínuo, a tabela de origem deve ter a habilitação Alterar feed de dados.
- Quando terminar, clique em Confirmar. Aparece a página da tabela online.
- A nova tabela online é criada sob o catálogo, o esquema e o nome especificados na caixa de diálogo de criação. No Gerenciador de Catálogos, a tabela online é indicada por
 .
.
Obtenha atualizações de status e gatilho usando a interface do usuário
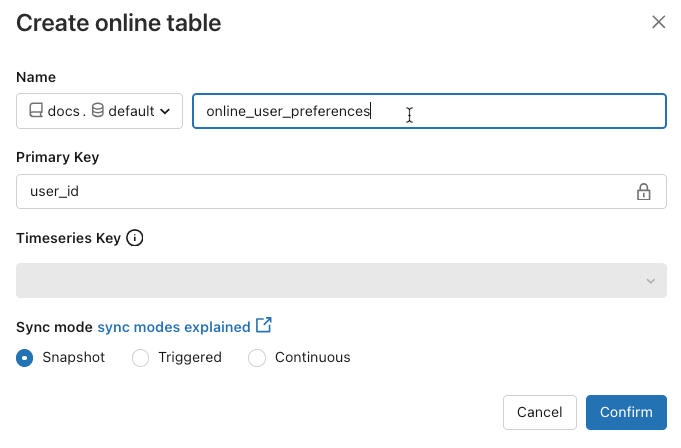
Para verificar o status da tabela online, clique no nome da tabela no Catálogo para abri-la. A página da tabela online aparece com a guia Visão Geral aberta. A seção Ingerir Dados mostra o status da atualização mais recente. Para disparar uma atualização, clique em Sincronizar agora. A seção Ingerir dados também inclui um link para o pipeline do Delta Live Tables que atualiza a tabela.
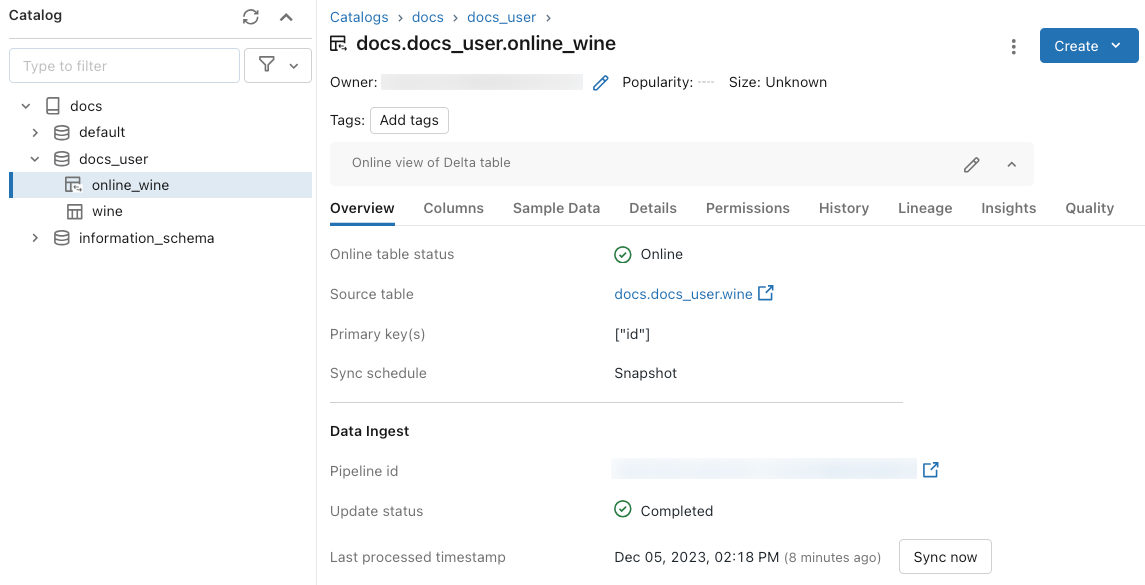
Agende atualizações periódicas
Para tabelas online com modo de sincronização de instantâneo ou disparado , você pode agendar atualizações periódicas automáticas. O agendamento de atualização é gerenciado pelo pipeline do Delta Live Tables que atualiza a tabela.
- No Gerenciador de Catálogos, navegue até a tabela online.
- Na seção Ingestão de Dados, clique no link para o pipeline.
- No canto superior direito, clique em Agenda e adicione uma nova agenda ou atualize as agendas existentes.
Excluir uma tabela online usando a interface do usuário
Na página da tabela online, selecione Excluir no menu ![]() kebab.
kebab.
Trabalhar com tabelas online usando APIs
Você também pode usar o SDK do Databricks ou a API REST para criar e gerenciar tabelas online.
Para obter informações de referência, consulte a documentação de referência do SDK do Databricks para Python ou da API REST.
Requisitos
SDK do Databricks versão 0.20 ou superior.
Criar uma tabela online usando APIs
SDK do Databricks - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
API REST
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
A tabela online é sincronizada automaticamente depois de ser criada.
Obter status e disparar atualização usando APIs
Você pode exibir o status e a especificação da tabela online seguindo o exemplo abaixo. Se a tabela online não for contínua e você quiser disparar uma atualização manual de seus dados, poderá usar a API de pipeline para fazer isso.
Use a ID do pipeline associada à tabela online na especificação da tabela online e inicie uma nova atualização no pipeline para disparar a atualização. Isso é equivalente a clicar em Sincronizar agora na interface do usuário da tabela online no Explorador de Catálogos.
SDK do Databricks - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
API REST
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Excluir uma tabela online usando APIs
SDK do Databricks - Python
w.online_tables.delete('main.default.my_online_table')
API REST
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
A exclusão da tabela online interrompe qualquer sincronização de dados e libere todos os seus recursos.
Servir dados de tabelas online usando um ponto de extremidade de fornecimento de recursos.
Para modelos e aplicativos hospedados fora do Databricks, é possível criar um ponto de extremidade de fornecimento de recursos para servir recursos das tabelas online. O ponto de extremidade disponibiliza recursos com baixa latência usando uma API REST.
Criar uma especificação de recurso.
Ao criar uma especificação de recurso, você especifica a tabela Delta de origem. Isso permite que a especificação do recurso seja usada em cenários offline e online. Para pesquisas online, o ponto de extremidade de serviço usa automaticamente a tabela online para realizar pesquisas de recursos de baixa latência.
A tabela Delta de origem e a tabela online devem usar a mesma chave primária.
A especificação do recurso pode ser exibida na guia Função no Gerenciador de Catálogos.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Criar um ponto de extremidade de fornecimento de recursos.
Esta etapa pressupõe que você tenha criado uma tabela online chamada
user_preferences_online_tableque sincroniza dados da tabela Deltauser_preferences. "Use a especificação de recursos para criar um ponto de extremidade de fornecimento de recursos. O ponto de extremidade disponibiliza dados através de uma API REST usando a tabela online associada.Observação
O usuário que realiza essa operação deve ser o proprietário da tabela offline e da tabela online.
SDK do Databricks - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )API Python
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Obtenha dados do ponto de extremidade de fornecimento de recursos.
Para acessar o ponto de extremidade de API, envie uma solicitação HTTP GET para a URL do ponto de extremidade. O exemplo mostra como fazer isso usando as APIs do Python. Para outras linguagens e ferramentas, consulte Serviço de Recurso.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Use tabelas online com aplicativos RAG
Os aplicativos RAG são um caso de uso comum para tabelas online. Crie uma tabela online para os dados estruturados necessários pelo aplicativo RAG e a hospede em um ponto de extremidade de fornecimento de recursos. O aplicativo RAG utiliza o ponto de extremidade de fornecimento de recursos para consultar dados relevantes na tabela online.
As etapas típicas são as seguintes:
- Criar um ponto de extremidade de fornecimento de recursos.
- Crie uma ferramenta usando o LangChain ou qualquer pacote semelhante que use o ponto de extremidade para procurar dados relevantes.
- Use a ferramenta em um agente LangChain ou similar para recuperar dados relevantes.
- Crie um ponto de extremidade de serviço de modelo para hospedar o aplicativo.
Para obter instruções passo a passo e um notebook de exemplo, consulte Exemplo de engenharia de recursos: aplicativo RAG estruturado.
Exemplos de notebook
O notebook a seguir ilustra como publicar recursos em tabelas online para serviço em tempo real e pesquisa automatizada de recursos.
Notebook de demonstração de tabelas online
Usar tabelas online com o Serviço de Modelo do Mosaic AI
Você pode usar as tabelas online para pesquisar recursos para o Serviço de Modelo do Mosaic AI. Quando você sincroniza uma tabela de recursos com uma tabela online, os modelos treinados usando os recursos dessa tabela de recursos pesquisam automaticamente os valores dos recursos da tabela online durante a inferência. Não requer configuração adicional.
Use um
FeatureLookuppara treinar o modelo.Para o treinamento do modelo, utilize recursos da tabela de recursos offline no conjunto de treinamento do modelo, conforme mostrado no exemplo a seguir:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Forneça o modelo com o Serviço de Modelo Mosaic AI. O modelo pesquisa automaticamente os recursos na tabela online. Consulte Pesquisa automática de recursos com Serviço de Modelo do Databricks para obter detalhes.
Permissões de acesso do usuário
Você deve ter as seguintes permissões de acesso para criar uma tabela online:
SELECTprivilégio na tabela de origem.USE_CATALOGprivilégio no catálogo de destino.USE_SCHEMAeCREATE_TABLEno esquema de destino.
Para gerenciar o pipeline de sincronização de uma tabela online, você precisa ser o proprietário da tabela online ou receber o privilégio REFRESH na tabela online. Os usuários que não tiverem privilégios USE_CATALOG e USE_SCHEMA no catálogo não verão a tabela online no Gerenciador de Catálogos.
O metastore do Catálogo do Unity deve ter Modelo Privilege Versão 1.0.
Modelo de permissões de pontos de extremidade
Uma entidade de serviço exclusiva é criada automaticamente em um ponto de extremidade de fornecimento de recursos ou de fornecimento de modelos, com permissões limitadas necessárias para consultar dados e de tabelas online. Essa entidade de segurança permite que os pontos de extremidade acessem dados independentemente do usuário que criou o recurso e garante que o ponto de extremidade possa continuar a funcionar se o criador deixar o espaço de trabalho.
O tempo de vida dessa entidade de serviço é o tempo de vida do ponto de extremidade. Os logs de auditoria podem indicar registros gerados pelo sistema para o proprietário do Catálogo do Unity que concede os privilégios necessários a essa entidade de serviço.
Limitações
- Há suporte para apenas uma tabela online por tabela de origem.
- Uma tabela online e sua tabela de origem podem ter no máximo 1000 colunas.
- As colunas dos tipos de dados ARRAY, MAP ou STRUCT não podem ser usadas como chaves primárias na tabela online.
- Se uma coluna for usada como chave primária na tabela online, todas as linhas na tabela de origem em que a coluna contém valores nulos serão ignoradas.
- Tabelas externas, de sistema e internas não têm suporte para serem usadas como tabelas de origem.
- As tabelas de origem sem o feed de dados de alterações Delta habilitado suportam apenas o modo de sincronização Instantâneo.
- As tabelas de Compartilhamento Delta são suportadas apenas no modo de sincronização Instantâneo.
- Os nomes de catálogo, esquema e tabela da tabela online só podem conter caracteres alfanuméricos e sublinhados e não devem começar com números. Traços (
-) não são permitidos. - As colunas do tipo Cadeia de caracteres são limitadas a 64 KB de comprimento.
- Os nomes das colunas são limitados a 64 caracteres de comprimento.
- O tamanho máximo da linha é de 2 MB.
- O tamanho combinado de todas as tabelas online em um metastore do Catálogo do Unity durante a visualização pública é de 2TB de dados de usuário descompactados.
- O máximo de consultas por segundo (QPS) é 12.000. Entre em contato com sua equipe de conta do Databricks para aumentar o limite.
Solução de problemas
Não vejo a opção Criar tabela online
A causa geralmente é que a tabela da qual está tentando sincronizar (a tabela de origem) não é um tipo com suporte. Verifique se você tem certeza de que o Tipo Protegível da tabela de origem (mostrado na guia Detalhes do Gerenciador de Catálogos) é uma das opções abaixo que dão suporte:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
Não consigo selecionar modos de sincronização Disparado ou Contínuo ao criar uma tabela online
Isso acontece se a tabela de origem não tiver o feed de dados de alteração Delta habilitado ou se for uma exibição exibida ou materializada. Para usar o modo de sincronização Incremental, habilite o feed de dados de alterações na tabela de origem ou utilize uma tabela que não seja de exibição.
Falha na atualização da tabela online ou o status aparece offline
Para começar a solucionar esse erro, clique na ID do pipeline que aparece na guia Visão geral da tabela online no Explorador de Catálogos.
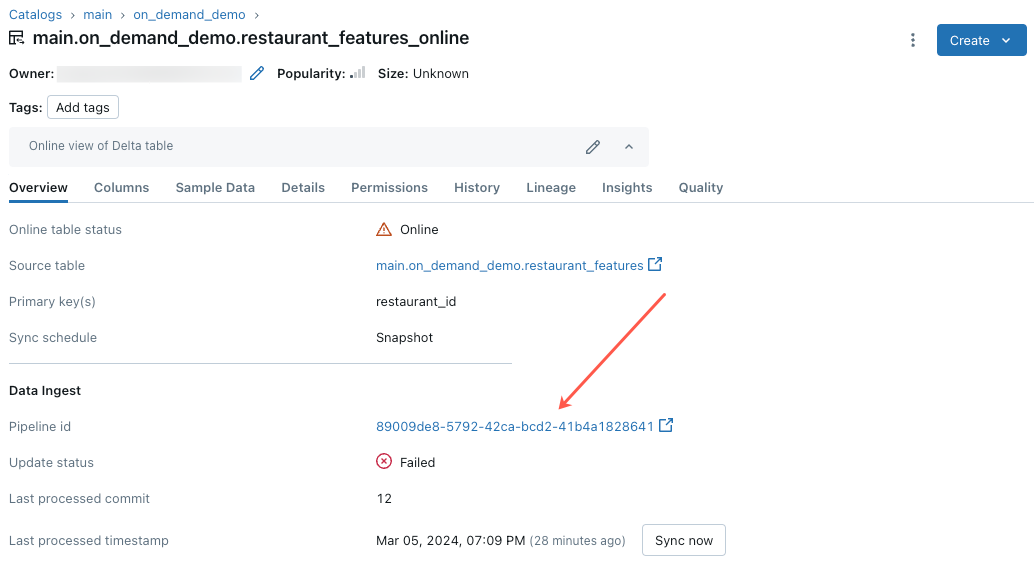
Na página da interface do usuário do pipeline exibida, clique na entrada que diz “Falha ao resolver o fluxo ‘__online_table”.
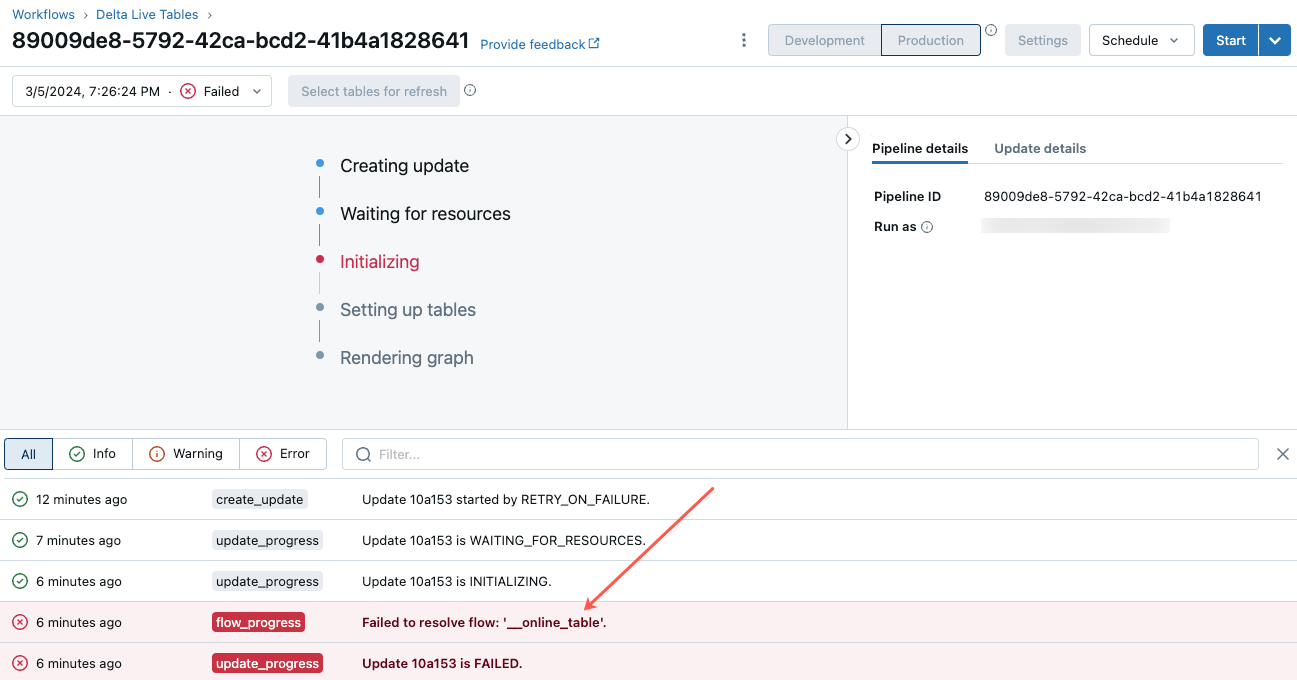
Um pop-up é exibido com detalhes na seção Detalhes do erro.
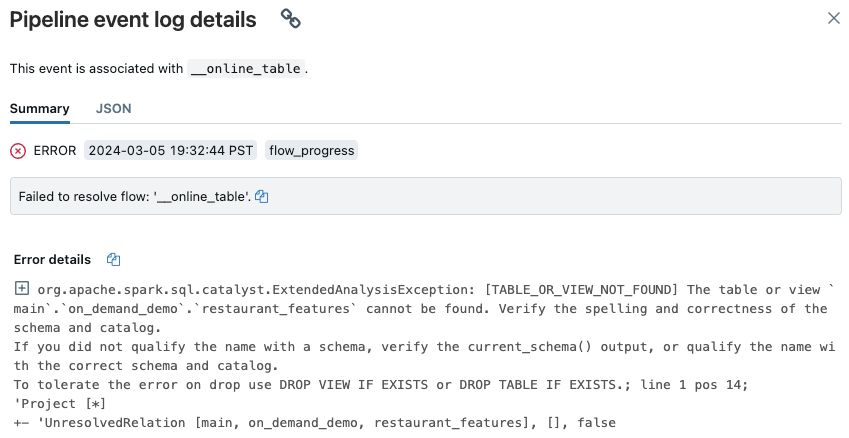
As causas comuns de erros incluem o seguinte:
A tabela de origem foi excluída, ou excluída e recriada com o mesmo nome, enquanto a tabela online estava sendo sincronizada. Isso é particularmente comum com tabelas online contínuas, pois elas estão constantemente sendo sincronizadas.
A tabela de origem não pode ser acessada por meio do computação sem servidor devido às configurações de firewall. Nessa situação, a seção Detalhes do erro pode mostrar a mensagem de erro “Falha ao iniciar o serviço DLT no cluster xxx...”.
O tamanho agregado das tabelas online excede o limite de 2 TB (tamanho não compactado) em todo o metastore. O limite de 2 TB refere-se ao tamanho descompactado após a expansão da tabela Delta no formato orientado a linhas. O tamanho da tabela no formato de linha pode ser significativamente maior do que o tamanho da tabela Delta mostrada no Explorador de Catálogos, que se refere ao tamanho compactado da tabela em um formato orientado por colunas. A diferença pode ser de até 100x, dependendo do conteúdo da tabela.
Para estimar o tamanho descompactado e expandido por linha de uma tabela Delta, use a consulta a seguir de um SQL Warehouse sem servidor. A consulta retorna o tamanho estimado da tabela expandida em bytes. Executar essa consulta com êxito também confirma que a computação sem servidor pode acessar a tabela de origem.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;