Regressão com AutoML
Use o AutoML para encontrar automaticamente o melhor algoritmo de regressão e configuração de hiperparâmetro para prever valores numéricos contínuos.
Configurar o experimento de regressão com a interface
Você pode configurar um problema de regressão usando a interface do usuário do AutoML com as seguintes etapas:
Na barra lateral, selecione Experimentos.
No cartão Regressão, selecione Iniciar treinamento.
A página Configurar experimento do AutoML é exibida. Nessa página, você configura o processo AutoML, especificando o conjunto de pontos, o tipo de problema, a coluna de destino ou de rótulo a prever, a métrica a ser usada para avaliar e pontuar as execuções de experimento e as condições de interrupção.
No campo Computação, selecione um cluster executando o Databricks Runtime ML.
Em Conjunto de dados, selecione Procurar.
Navegue até a tabela que você deseja usar e clique em Selecionar. O esquema de tabela é exibido.
- No Databricks Runtime 10.3 ML e versões posteriores, você pode especificar quais colunas o AutoML deve usar para treinamento. Não é possível remover a coluna selecionada como o destino de previsão ou a coluna de tempo para dividir os dados.
- No Databricks Runtime 10.4 LTS ML e versões posteriores, você pode especificar como os valores nulos são imputados ao selecionar Impute com no menu suspenso. Por padrão, o AutoML seleciona um método de imputação com base no tipo de coluna e no conteúdo.
Observação
Se você especificar um método de imputação não padrão, o AutoML não executará a detecção de tipo semântico.
Clique no campo Destino de previsão. Uma lista suspensa é exibida com as colunas mostradas no esquema. Selecione a coluna que você deseja que o modelo preveja.
O campo Nome do experimento mostra o nome padrão. Para alterá-lo, digite o novo nome no campo.
Também é possível:
- Especifique opções de configuração adicionais.
- Use tabelas de recursos existentes no Repositório de Recursos para aumentar o conjunto de dados de entrada original.
Configurações avançadas
Abra a seçãoConfiguração Avançada (opcional) para acessar esses parâmetros.
- A métrica de avaliação é a principal métrica usada para pontuar as executações.
- No Databricks Runtime 10.4 LTS ML e superior, você pode excluir estruturas de treinamento da consideração. Por padrão, o AutoML treina modelos usando estruturas listadas em Algoritmos AutoML.
- Você pode editar as condições de interrupção. As condições de interrupção padrão são:
- Para experimentos de previsão, pare após 120 minutos.
- No Databricks Runtime 10.4 LTS ML e abaixo, para experiências de classificação e regressão, pare após 60 minutos ou após completar 200 ensaios, o que acontecer primeiro. Para o Databricks Runtime 11.0 ML e superior, o número de tentativas não é usado como condição de parada.
- No Databricks Runtime 10.4 LTS ML e superior, para experimentos de classificação e regressão, o AutoML incorpora parada antecipada; ele interrompe o treinamento e o ajuste de modelos se a métrica de validação não estiver mais melhorando.
- No Databricks Runtime 10.4 LTS ML e superior, você pode selecionar a
time columnpara dividir os dados para treinamento, validação e teste em ordem cronológica (aplica-se somente à classificação e regressão). - O Databricks recomenda não preencher o campo do Diretório de dados. Isso dispara o comportamento padrão de armazenar com segurança o conjunto de dados como um artefato do MLflow. Um caminho DBFS pode ser especificado, mas, nesse caso, o conjunto de dados não herda as permissões de acesso do experimento AutoML.
Executar o experimento e monitorar os resultados
Para iniciar o experimento de AutoML, clique em Iniciar AutoML. O experimento começa a ser executado e a página de treinamento do AutoML é exibida. Para atualizar a tabela de execuções, clique no  .
.
Ver o progresso da experiência
Nesta página, você pode:
- Pare o experimento a qualquer momento.
- Abra o notebook de exploração de dados.
- Monitorar execuções
- Navegue até a página de execução para qualquer execução.
Com Databricks Runtime 10.1 ML e superior, o AutoML exibe avisos sobre possíveis problemas com o conjuntos de dados, como tipos de coluna sem suporte ou colunas de alta cardinalidade.
Observação
O Databricks faz o melhor para indicar possíveis erros ou problemas. No entanto, isso pode não ser abrangente e pode não capturar os problemas ou erros que você está procurando.
Para ver os avisos do conjunto de dados, clique na guia Avisos na página de treinamento ou na página do experimento, após a conclusão do experimento.
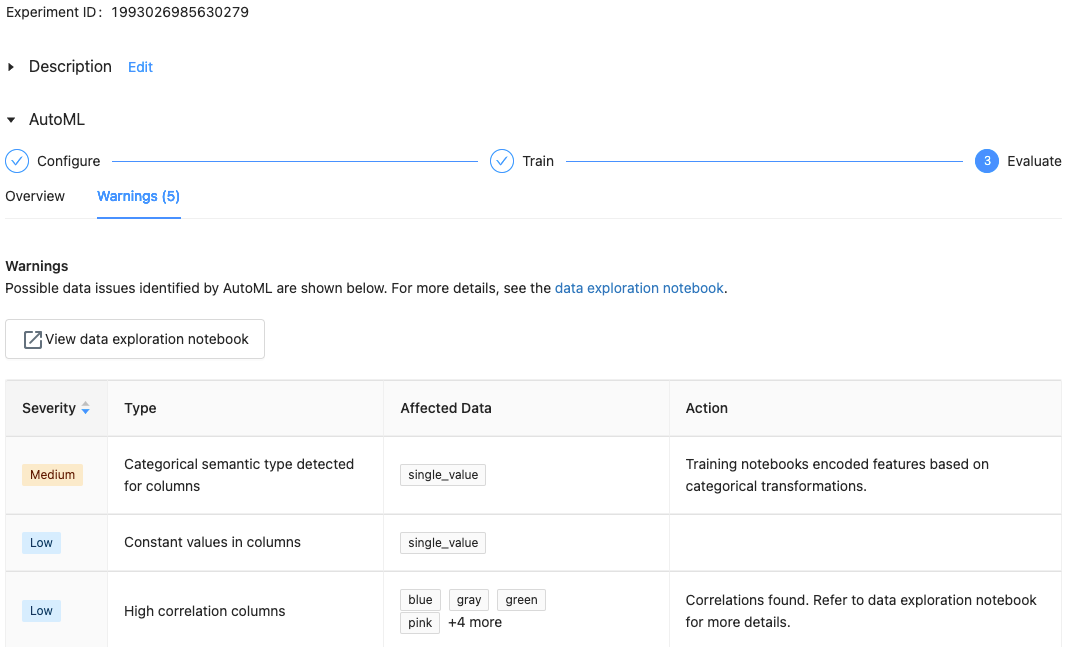
Exibir os resultados
Quando o experimento for concluído, você poderá:
- Registrar e implantar um dos modelos com o MLflow.
- Selecione Exibir notebook para o melhor modelo para revisar e editar o notebook que criou o melhor modelo.
- Selecione Exibir notebook de exploração de dados para abrir o notebook de exploração de dados.
- Pesquise, filtre e classificar as executações na tabela de executações.
- Confira os detalhes de qualquer execução:
- O notebook gerado contendo o código-fonte para uma execução da avaliação gratuita pode ser encontrado clicando na execução do MLflow. O notebooks é salvo na seção Artefatos da página de execução. Você pode baixar esse notebook e importá-lo para o espaço de trabalho, se o download de artefatos estiver habilitado pelos administradores do seu espaço de trabalho.
- Para exibir os resultados da execução, clique na coluna Modelos ou na coluna Hora de Início. A página de execução será exibida, mostrando informações sobre a execução de avaliação (como parâmetros, métricas e marcas) e artefatos criados pela execução, incluindo o modelo. Esta página também inclui snippets de código que você pode usar para fazer previsões com o modelo.
Para retornar a esse experimento de AutoML mais tarde, encontre-o na tabela na página Experimentos. Os resultados de cada experimento de AutoML, incluindo os notebooks de treinamento e exploração de dados, são armazenados em uma pasta databricks_automl na pasta inicial do usuário que fez o experimento.
Registrar e implantar um modelo
Você pode registrar e implantar seu modelo com a interface do usuário do AutoML:
- Selecione o link na coluna Modelos do modelo a ser registrado. Quando uma execução for concluída, a linha superior será o melhor modelo (com base na métrica primária).
- Selecione o
 para registrar o modelo no Registro do modelo.
para registrar o modelo no Registro do modelo. - Selecione
 Modelos na barra lateral para navegar até o Registro de Modelo.
Modelos na barra lateral para navegar até o Registro de Modelo. - Selecione o nome do seu modelo na tabela de modelo.
- Na página do modelo registrado, você pode servir o modelo com Serviço do Modelo.
Nenhum módulo chamado 'pandas.core.indexes.numeric
Ao servir um modelo criado usando o AutoML com o Serviço de Modelo, você pode receber o erro: No module named 'pandas.core.indexes.numeric.
Isso ocorre devido a uma versão incompatível pandas entre o AutoML e o modelo que atende ao ambiente de ponto de extremidade. Você pode resolve esse erro executando o script add-pandas-dependency.py. O script edita o requirements.txt e conda.yaml para que o modelo registrado inclua a versão de dependência apropriada pandas : pandas==1.5.3
- Modifique o script para incluir o
run_idda execução do MLflow em que o modelo foi registrado. - Registrar novamente o modelo no registro de modelo do MLflow.
- Tente fornecer a nova versão do modelo MLflow.