Princípios orientadores para o lakehouse
Princípios orientadores são regras de nível zero que definem e influenciam sua arquitetura. Para criar um data lakehouse que ajude sua empresa a ter sucesso agora e no futuro, o consenso entre as partes interessadas em sua organização é fundamental.
Coletar dados e oferecer dados como produtos confiáveis
A coleta de dados é essencial para criar um data lake de alto valor para BI e ML/IA. Trate dados como um produto com uma definição clara, esquema e ciclo de vida. Verifique a consistência semântica e se a qualidade dos dados melhora de camada em camada para que os usuários empresariais possam confiar totalmente nos dados.
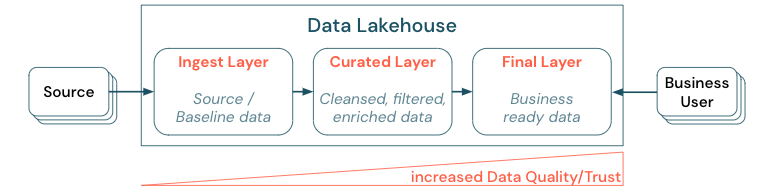
A curadoria de dados estabelecendo uma arquitetura em camadas (ou de vários saltos) é uma prática recomendada crítica para o lakehouse, pois permite que as equipes de dados estruturem os dados de acordo com os níveis de qualidade e definam funções e responsabilidades por camada. Uma abordagem comum de camadas é:
- Camada de ingestão: os dados de origem são ingeridos no lakehouse na primeira camada e devem ser mantidos lá. Quando todos os dados downstream são criados a partir da Camada de ingestão, é possível recompilar as camadas subsequentes dessa camada, se necessário.
- Camada coletada: a finalidade da segunda camada é manter dados limpos, refinados, filtrados e agregados. O objetivo dessa camada é fornecer uma base sólida e confiável para análises e relatórios em todas as funções.
- Camada final: a terceira camada é criada em relação às necessidades de negócios ou de projeto; ele fornece uma exibição diferente como produtos de dados para outras unidades de negócios ou projetos, preparando dados em relação às necessidades de segurança (por exemplo, dados anônimos) ou otimizando o desempenho (com exibições pré-agregadas). Os produtos de dados nessa camada são vistos como verdadeiros para os negócios.
Os pipelines em todas as camadas precisam garantir que as restrições de qualidade de dados sejam atendidas, o que significa que os dados são precisos, completos, acessíveis e consistentes o tempo todo, mesmo durante leituras e gravações simultâneas. A validação de novos dados ocorre no momento da entrada de dados na camada selecionada e as etapas de ETL a seguir funcionam para melhorar a qualidade desses dados. A qualidade dos dados deve melhorar à medida que os dados avançam pelas camadas e, como tal, a confiança nos dados aumenta posteriormente do ponto de vista comercial.
Eliminar silos de dados e minimizar a movimentação de dados
Não crie cópias de um conjunto de dados com processos empresariais que dependem dessas cópias diferentes. As cópias podem se tornar silos de dados que saem da sincronização, levando à menor qualidade do data lake e, por fim, a insights desatualizados ou incorretos. Além disso, para compartilhar dados com parceiros externos, use um mecanismo de compartilhamento corporativo que permita o acesso direto aos dados de maneira segura.
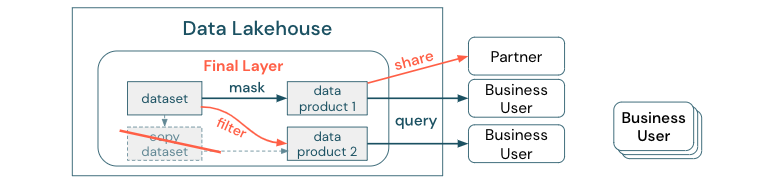
Para deixar clara a distinção entre uma cópia de dados versus um silo de dados: uma cópia autônoma ou descartável de dados não é prejudicial por si só. Às vezes, é necessário aumentar a agilidade, a experimentação e a inovação. No entanto, se essas cópias se tornarem operacionais com produtos de dados de negócios downstream dependentes deles, elas se tornarão silos de dados.
Para evitar silos de dados, as equipes de dados geralmente tentam criar um mecanismo ou pipeline de dados para manter todas as cópias em sincronia com o original. Como é improvável que isso aconteça de forma consistente, a qualidade dos dados acaba degradando. Isso também pode levar a custos mais altos e uma perda significativa de confiança por parte dos usuários. Por outro lado, vários casos de uso de negócios exigem o compartilhamento de dados com parceiros ou fornecedores.
Um aspecto importante é compartilhar de forma segura e confiável a versão mais recente do conjunto de dados. As cópias do conjunto de dados geralmente não são suficientes, pois podem sair da sincronização rapidamente. Em vez disso, os dados devem ser compartilhados por meio de ferramentas de compartilhamento de dados corporativos.
Democratizar a criação de valor por meio do autoatendimento
O melhor data lake não poderá fornecer valor suficiente se os usuários não puderem acessar a plataforma ou os dados para suas tarefas de BI e ML/IA facilmente. Reduza as barreiras para acessar dados e plataformas para todas as unidades de negócios. Considere processos de gerenciamento de dados lean e forneça acesso de autoatendimento para a plataforma e os dados subjacentes.
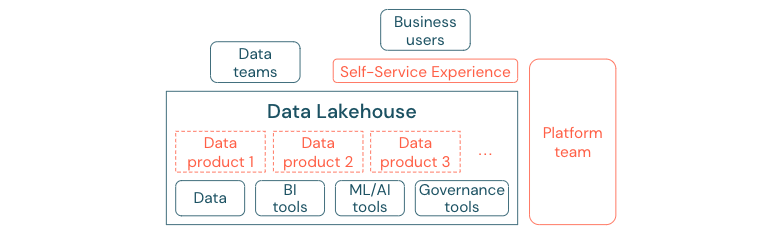
As empresas que migraram com êxito para uma cultura controlada por dados prosperarão. Isso significa que cada unidade de negócios deriva suas decisões de modelos analíticos ou de analisar seus próprios dados ou fornecidos centralmente. Para os consumidores, os dados devem ser facilmente detectáveis e acessíveis com segurança.
Um bom conceito para os produtores de dados é "dados como um produto": os dados são oferecidos e mantidos por uma unidade de negócios ou parceiro de negócios como um produto e consumidos por outras partes com controle de permissão adequado. Em vez de depender de uma equipe central e processos de solicitação potencialmente lentos, esses produtos de dados devem ser criados, oferecidos, descobertos e consumidos em uma experiência de autoatendimento.
No entanto, não são apenas os dados que importam. A democratização dos dados requer as ferramentas certas para permitir que todos produzam ou consumam e entendam os dados. Para isso, você precisa que o data lakehouse seja uma plataforma moderna de dados e IA que forneça a infraestrutura e as ferramentas para a criação de produtos de dados sem duplicar o esforço de configurar outra pilha de ferramentas.
Adotar uma estratégia de governança de dados em toda a organização
Os dados são um ativo crítico de qualquer organização, mas você não pode conceder a todos acesso a todos os dados. O acesso a dados deve ser gerenciado ativamente. Controle de acesso, auditoria e acompanhamento de linhagem são fundamentais para o uso correto e seguro dos dados.
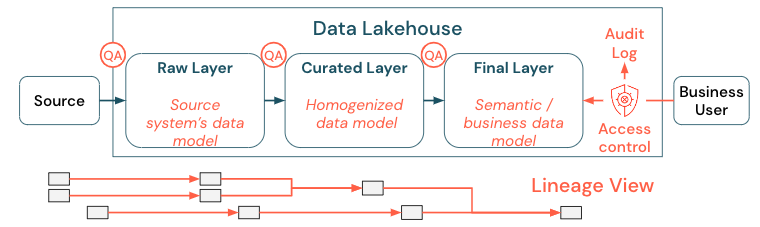
A governança de dados é um tópico amplo. A lakehouse abrange as seguintes dimensões:
Qualidade dos dados
O pré-requisito mais importante para relatórios corretos e significativos, resultados de análise e modelos são dados de alta qualidade. A garantia de qualidade (QA) precisa existir em todas as etapas do pipeline. Exemplos de como implementar isso incluem ter contratos de dados, atender a SLAs, manter os esquemas estáveis e evoluí-los de forma controlada.
Catálogo de dados
Outro aspecto importante é a descoberta de dados: os usuários de todas as áreas de negócios, especialmente em um modelo de autoatendimento, devem ser capazes de descobrir dados relevantes facilmente. Portanto, um lakehouse precisa de um catálogo de dados que abrange todos os dados relevantes para os negócios. As principais metas de um catálogo de dados são as seguintes:
- Verifique se o mesmo conceito de negócio é chamado e declarado uniformemente em toda a empresa. Você pode pensar nisso como um modelo semântico na camada curada e final.
- Acompanhe a linhagem de dados precisamente para que os usuários possam explicar como esses dados chegaram à forma e ao formulário atuais.
- Mantenha metadados de alta qualidade, que são tão importantes quanto os próprios dados para uso adequado dos dados.
Controle de acesso
Como a criação de valor a partir dos dados na lakehouse acontece em todas as áreas de negócios, a casa do lago deve ser construída com segurança como um cidadão de primeira classe. As empresas podem ter uma política de acesso a dados mais aberta ou seguir estritamente o princípio de privilégios mínimos. Independentemente disso, os controles de acesso a dados devem estar em vigor em todas as camadas. É importante implementar esquemas de permissão de nível fino desde o início (controle de acesso em nível de coluna e linha, controle de acesso baseado em função ou atributo). As empresas podem começar com regras menos rígidas. Mas à medida que a plataforma lakehouse cresce, todos os mecanismos e processos para um regime de segurança mais sofisticado já devem estar em vigor. Além disso, todo o acesso aos dados no lakehouse deve ser regido por logs de auditoria desde o início.
Incentivar interfaces abertas e formatos abertos
Interfaces abertas e formatos de dados são cruciais para interoperabilidade entre o lakehouse e outras ferramentas. Simplifica a integração com sistemas existentes e também abre um ecossistema de parceiros que integraram suas ferramentas à plataforma.
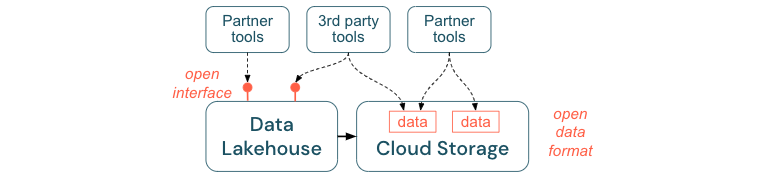
As interfaces abertas são essenciais para habilitar a interoperabilidade e impedir a dependência de qualquer fornecedor único. Tradicionalmente, os fornecedores criaram tecnologias proprietárias e interfaces fechadas que limitavam as empresas da maneira como podem armazenar, processar e compartilhar dados.
A criação de interfaces abertas ajuda você a criar para o futuro:
- Ele aumenta a longevidade e a portabilidade dos dados para que você possa usá-los com mais aplicativos e para mais casos de uso.
- Ele abre um ecossistema de parceiros que podem aproveitar rapidamente as interfaces abertas para integrar suas ferramentas à plataforma lakehouse.
Por fim, ao padronizar em formatos abertos para dados, os custos totais serão significativamente menores; é possível acessar os dados diretamente no armazenamento em nuvem sem a necessidade de redirecioná-los por meio de uma plataforma proprietária que pode incorrer em altos custos de saída e computação.
Compilar para dimensionar e otimizar para desempenho e custo
Os dados inevitavelmente continuam crescendo e se tornando mais complexos. Para equipar sua organização para necessidades futuras, seu lakehouse deve ser capaz de dimensionar. Por exemplo, você deve ser capaz de adicionar novos recursos facilmente sob demanda. Os custos devem ser limitados ao consumo real.
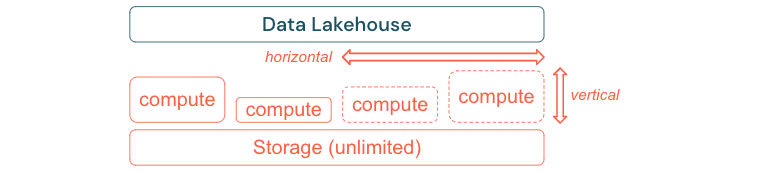
Processos de ETL padrão, relatórios de negócios e dashboards geralmente têm uma necessidade previsível de recursos de uma perspectiva de memória e computação. No entanto, novos projetos, tarefas sazonais ou abordagens modernas, como treinamento de modelo (variação, previsão, manutenção) geram picos de necessidade de recursos. Para permitir que uma empresa execute todas essas cargas de trabalho, é necessária uma plataforma escalonável para memória e computação. Novos recursos devem ser adicionados facilmente sob demanda e somente o consumo real deve gerar custos. Assim que o pico terminar, os recursos poderão ser liberados novamente e os custos serão reduzidos adequadamente. Geralmente, isso é chamado de dimensionamento horizontal (menos ou mais nós) e dimensionamento vertical (nós maiores ou menores).
O dimensionamento também permite que as empresas melhorem o desempenho das consultas selecionando nós com mais recursos ou clusters com mais nós. Mas, em vez de fornecer permanentemente grandes computadores e clusters, eles podem ser provisionados sob demanda apenas pelo tempo necessário para otimizar o desempenho geral para a taxa de custo. Outro aspecto da otimização é armazenamento versus recursos de computação. Como não há uma relação clara entre o volume de dados e cargas de trabalho que usam esses dados (por exemplo, usando apenas partes dos dados ou fazendo cálculos intensivos em dados pequenos), é uma boa prática resolver em uma plataforma de infraestrutura que desacopla recursos de armazenamento e computação.