Etapa 1. Clonar repositório de código e criar o recurso de computação
Consulte o repositório do GitHub para obter o código de exemplo nesta seção. Você também pode usar o código do repositório como um modelo para criar seus próprios aplicativos de IA.
Siga estas etapas para carregar o código de exemplo para o seu workspace do Databricks e definir as configurações globais do aplicativo.
Requisitos
- Um workspace do Azure Databricks com computação sem servidor e o Catálogo do Unity habilitados.
- Um ponto de extremidade existente do Mosaic AI Vector Search ou permissões para criar um novo ponto de extremidade de busca em vetores (o notebook de instalação cria um para você nesse caso).
- Acesso para gravação a um esquema do Catálogo do Unity existente, onde as tabelas Delta de saída que incluem os documentos analisados e segmentados e os índices de busca em vetores são armazenados, ou permissões para criar um novo catálogo e esquema (o notebook de configuração cria um para você, neste caso).
- Um único cluster de usuário executando o DBR 14.3 ou superior que tem acesso à Internet. O acesso à Internet é necessário para baixar os pacotes Python e de sistema necessários. Não use um cluster executando o Databricks Runtime para Machine Learning, pois esses tutoriais têm conflitos de pacotes Python com o Databricks Runtime ML.
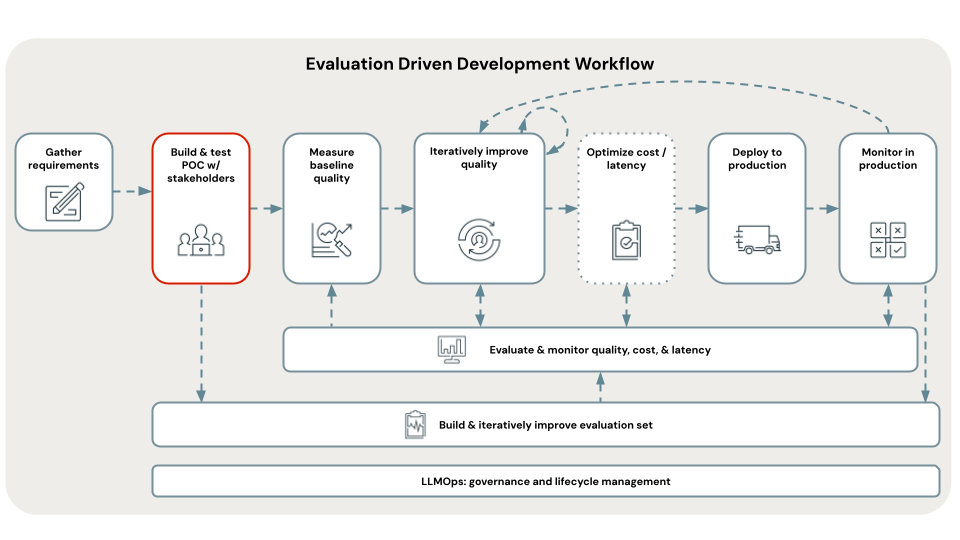
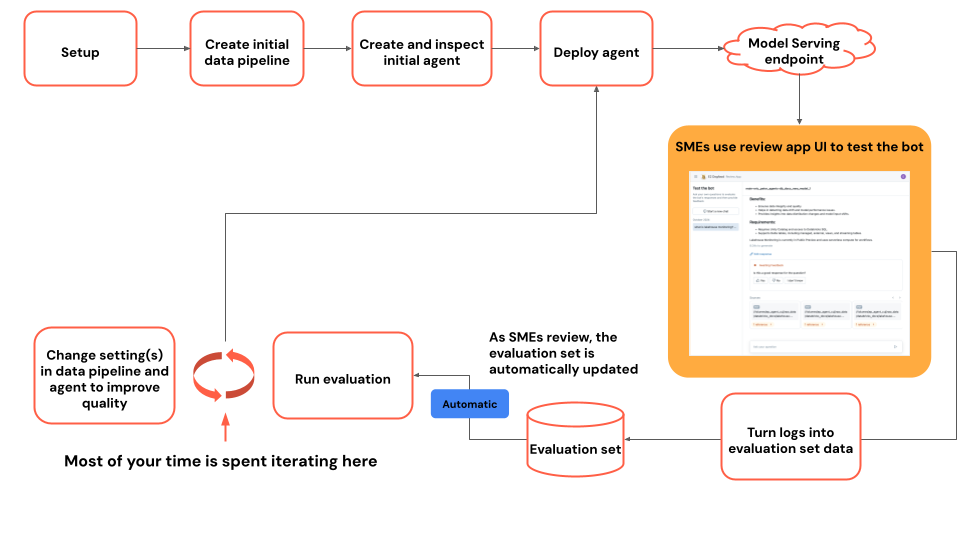
Diagrama de fluxo do tutorial
O diagrama mostra o fluxo de etapas usadas neste tutorial.
Instruções
Clone esse repositório em seu workspace usando pastas Git.
Abra o notebook rag_app_sample_code/00_global_config e ajuste as configurações nele.
# The name of the RAG application. This is used to name the chain's model in Unity Catalog and prepended to the output Delta tables and vector indexes RAG_APP_NAME = 'my_agent_app' # Unity Catalog catalog and schema where outputs tables and indexes are saved # If this catalog/schema does not exist, you need create catalog/schema permissions. UC_CATALOG = f'{user_name}_catalog' UC_SCHEMA = f'rag_{user_name}' ## Name of model in Unity Catalog where the POC chain is logged UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{RAG_APP_NAME}" # Vector Search endpoint where index is loaded # If this does not exist, it will be created VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search' # Source location for documents # You need to create this location and add files SOURCE_PATH = f"/Volumes/{UC_CATALOG}/{UC_SCHEMA}/source_docs"Abra e execute o notebook 01_validate_config_and_create_resources.
Próxima etapa
Continue com Implantar POC.