RAG (Geração Aumentada de Recuperação) no Azure Databricks
Importante
Esse recurso está em uma versão prévia.
A estrutura do agente compreende um conjunto de ferramentas no Databricks projetadas para ajudar os desenvolvedores a construir, implantar e avaliar a qualidade de produção de agentes de IA, como aplicativos RAG (geração aumentada de recuperação).
Este artigo aborda o que é a RAG e os benefícios do desenvolvimento de aplicativos RAG no Azure Databricks.
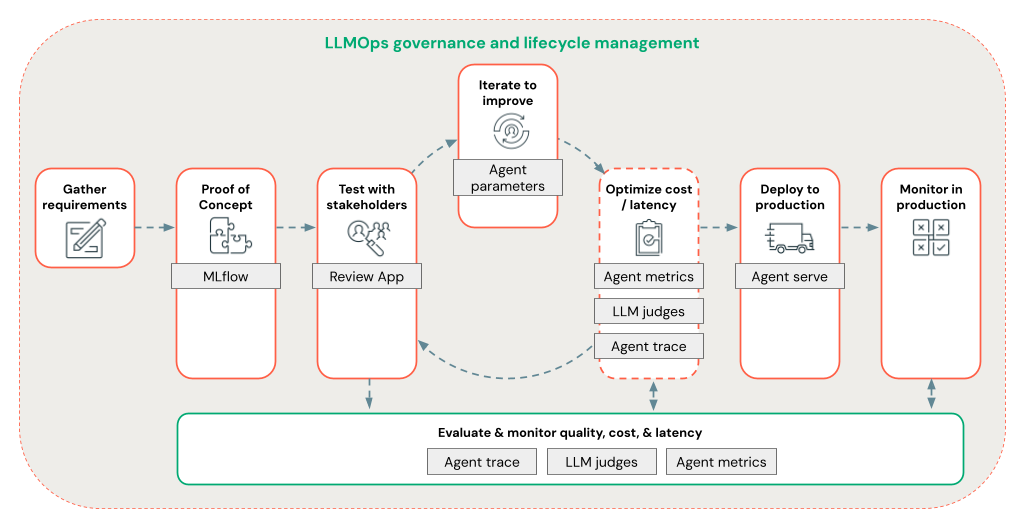
A Estrutura do Agente permite que os desenvolvedores iterem rapidamente em todos os aspectos do desenvolvimento de RAG usando um fluxo de trabalho LLMOps de ponta a ponta.
Requisitos
- Os recursos assistenciais de IA da plataforma AI Azure devem ser habilitados para seu espaço de trabalho.
- Todos os componentes de um aplicativo agente devem estar em um único workspace. Por exemplo, no caso de um aplicativo RAG, o modelo de serviço e a instância de pesquisa de vetor precisam estar no mesmo workspace.
O que é a RAG?
O RAG é uma técnica de design de IA generativa que aprimora os modelos de linguagem grande (LLM) com conhecimento externo. Essa técnica melhora as LLMs das seguintes maneiras:
- Conhecimento proprietário: RAG pode incluir informações proprietárias não usadas inicialmente para treinar o LLM, como memorandos, emails e documentos para responder a perguntas específicas do domínio.
- Informações atualizadas: um aplicativo RAG pode fornecer ao LLM informações de fontes de dados atualizadas.
- Citando fontes: o RAG permite que os LLMs citem fontes específicas, permitindo que os usuários verifiquem a precisão factual das respostas.
- ACL (listas de controle de acesso) e segurança de dados: a etapa de recuperação pode ser projetada para recuperar seletivamente informações pessoais ou proprietárias com base nas credenciais do usuário.
Sistemas compostos de IA
Um aplicativo RAG é um exemplo de um sistema de IA composto: ele se expande sobre os recursos de linguagem LLM combinando-o com outras ferramentas e procedimentos.
No formulário mais simples, um aplicativo RAG faz o seguinte:
- Recuperação: a solicitação do usuário é usada para consultar um armazenamento de dados externo, como um repositório de vetores, uma pesquisa de palavra-chave de texto ou um banco de dados SQL. A meta é obter dados de suporte para a resposta do LLM.
- Aumento: os dados recuperados são combinados com a solicitação do usuário, geralmente usando um modelo com formatação e instruções adicionais, para criar um prompt.
- Geração: o prompt é passado para o LLM, que gera uma resposta à consulta.
Dados RAG não estruturados versus estruturados
A arquitetura RAG pode funcionar com dados de suporte não estruturados ou estruturados. Os dados usados com o RAG dependem do caso de uso.
Dados não estruturados: dados sem uma estrutura ou organização específica. Documentos que incluem texto e imagens ou conteúdo multimídia, como áudio ou vídeos.
- PDFs
- Documentos do Google/Office
- Wikis
- Imagens
- Vídeos
Dados estruturados: dados tabulares organizados em linhas e colunas com um esquema específico, como tabelas em um banco de dados.
- Registros de clientes em um sistema de BI ou Data Warehouse
- Dados de transação de um banco de dados SQL
- Dados de APIs de aplicativo (por exemplo, SAP, Salesforce etc.)
As seções a seguir descrevem um aplicativo RAG para dados não estruturados.
Pipeline de dados RAG
O pipeline de dados RAG pré-processa e indexa documentos para recuperação rápida e precisa.
O diagrama abaixo mostra um pipeline de dados de exemplo para um conjunto de dados não estruturado usando um algoritmo de pesquisa semântica. Os trabalhos do Databricks orquestram cada etapa.
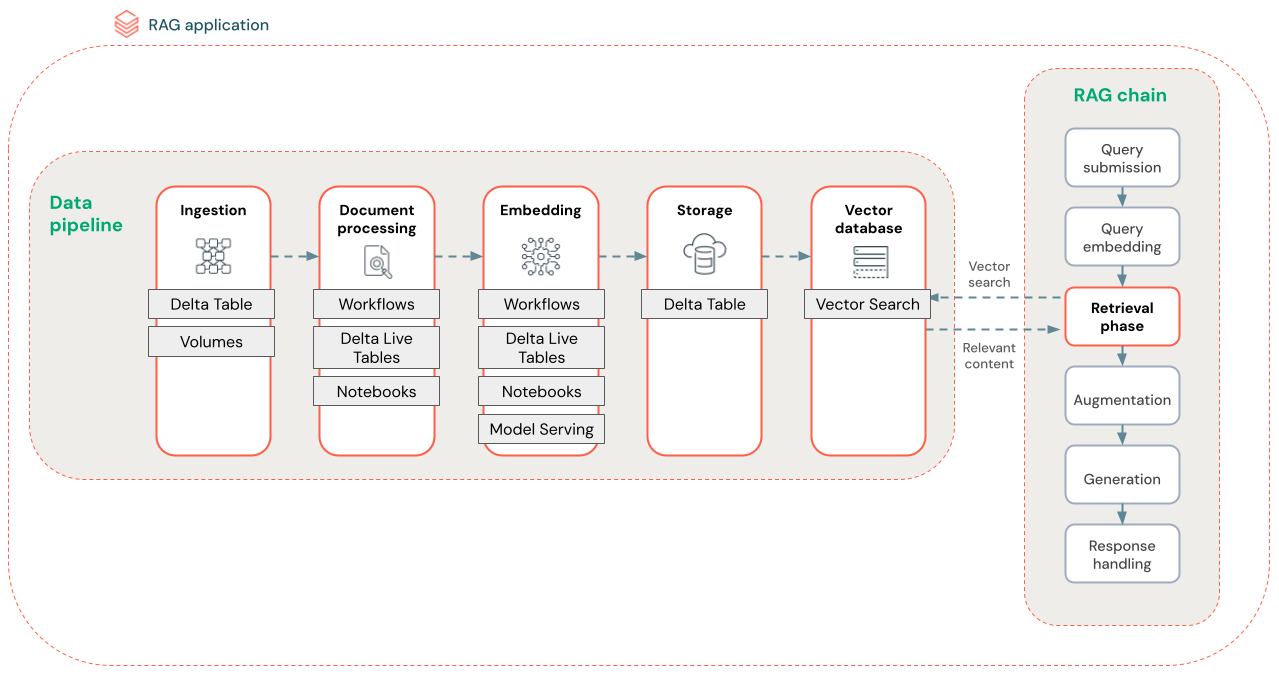
- Ingestão de dados – Ingere dados de sua fonte proprietária. Armazenar esses dados em uma tabela Delta ou no Volume do Catálogo do Unity.
- Processamento de documentos: você pode executar essas tarefas usando trabalhos do Databricks, notebooks do Databricks e Tabelas Dinâmicas Delta.
- Analisar documentos brutos: Transforma os dados brutos em um formato utilizável. Por exemplo, extrair o texto, tabelas e imagens de uma coleção de PDFs ou usar técnicas de reconhecimento óptico de caracteres para extrair texto de imagens.
- Extrair metadados: extrai metadados do documento, como títulos de documento, números de página e URLs, para ajudar na consulta da etapa de recuperação com mais precisão.
- Partir documentos: dividir os dados em partes que se encaixam na janela de contexto do LLM. A recuperação dessas partes em destaque, em vez de documentos inteiros, fornece ao LLM mais conteúdo direcionado para gerar respostas.
- Inserção de partes – Um modelo de inserção consome as partes para criar representações numéricas das informações chamadas inserções de vetor. Os vetores representam o significado semântico do texto, não apenas palavras-chave no nível da superfície. Nesse cenário, você calcula as inserções e usa o Serviço de Modelo para fornecer um modelo de inserção.
- Armazenamento de inserção – Armazene as inserções de vetor e o texto da parte em uma tabela Delta sincronizada com a Busca em Vetores.
- Banco de dados vetorial – como parte da Busca em Vetores, as inserções e os metadados são indexados e armazenados em um banco de dados vetorial para facilitar a consulta pelo agente RAG. Quando um usuário faz uma consulta, sua solicitação é inserida em um vetor. Em seguida, o banco de dados usa o índice de vetor para localizar e retornar as partes mais semelhantes.
Cada etapa envolve decisões de engenharia que afetam a qualidade do aplicativo RAG. Por exemplo, a escolha do tamanho da parte certa na etapa (3) garante que o LLM receba informações específicas, mas contextualizadas, enquanto a seleção de um modelo de inserção apropriado na etapa (4) determina a precisão das partes retornadas durante a recuperação.
Busca em Vetores do Dados
A similaridade de computação geralmente é computacionalmente cara, mas índices vetoriais como a Busca em Vetores do Databricks otimizam isso organizando inserções com eficiência. Buscas em vetor classificam rapidamente os resultados mais relevantes sem comparar cada inserção com a consulta do usuário individualmente.
A Busca em Vetores sincroniza automaticamente novas inserções adicionadas à tabela Delta e atualiza o índice de busca em vetores.
O que é um agente RAG?
Um agente RAG (Recuperação Aumentada de Geração) é uma parte fundamental de um aplicativo RAG que aprimora os recursos de LLMs (modelos de linguagem grande) integrando a recuperação de dados externos. O agente RAG processa consultas de usuário, recupera dados relevantes de um banco de dados vetorial e passa esses dados para um LLM para gerar uma resposta.
Ferramentas como LangChain ou Pyfunc vinculam essas etapas conectando suas entradas e saídas.
O diagrama a seguir mostra um agente RAG para um chatbot e os recursos do Databricks usados para criar cada agente.
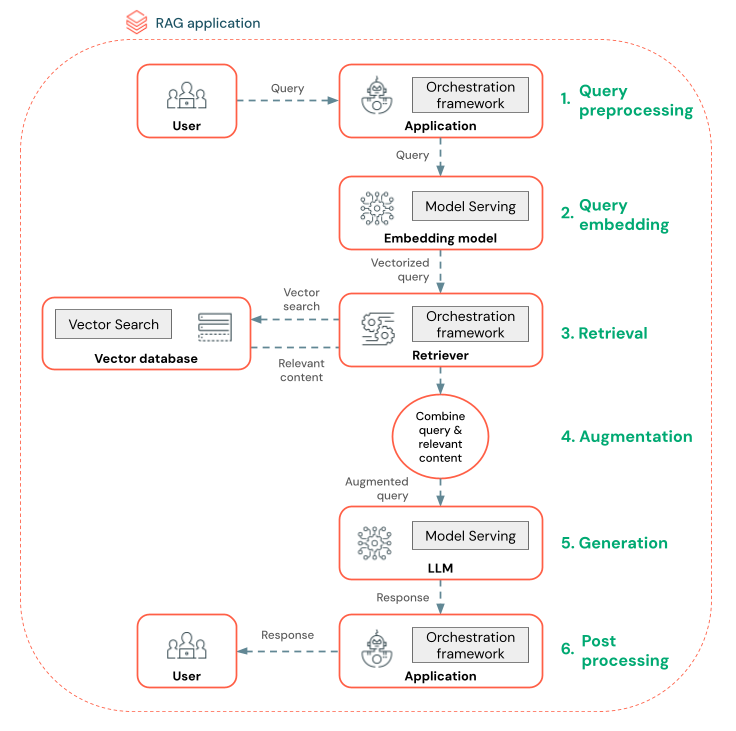
- Pré-processamento de consulta – um usuário envia uma consulta, que é pré-processada para torná-la adequada para consultar o banco de dados vetorial. Isso pode envolver colocar a solicitação em um modelo ou extrair palavras-chave.
- Vetorização de consulta – use o Serviço de Modelo para inserir a solicitação usando o mesmo modelo de inserção usado para inserir as partes no pipeline de dados. Essas inserções permitem a comparação da similaridade semântica entre a solicitação e as partes pré-processadas.
- Fase de recuperação – O recuperador, um aplicativo responsável por buscar informações relevantes, usa a consulta vetorizada e executa uma pesquisa de similaridade de vetor usando a Busca em Vetores. As partes de dados mais relevantes são classificadas e recuperadas com base em sua similaridade com a consulta.
- Aumento de prompt – O recuperador combina as partes de dados recuperadas com a consulta original para fornecer contexto adicional ao LLM. O prompt é cuidadosamente estruturado para garantir que o LLM entenda o contexto da consulta. Muitas vezes, o LLM tem um modelo para formatar a resposta. Esse processo de ajuste do prompt é conhecido como engenharia de prompt.
- Fase de Geração de LLM – O LLM gera uma resposta usando a consulta aumentada enriquecida pelos resultados de recuperação. O LLM pode ser um modelo personalizado ou um modelo de base.
- Pós-processamento – A resposta do LLM pode ser processada para aplicar lógica de negócios adicional, adicionar citações ou refinar o texto gerado com base em regras ou restrições predefinidas
Várias proteções podem ser aplicadas ao longo desse processo para garantir a conformidade com as políticas empresariais. Isso pode envolver filtragem para solicitações apropriadas, verificação de permissões do usuário antes de acessar fontes de dados e uso de técnicas de moderação de conteúdo nas respostas geradas.
Desenvolvimento de agente de RAG no nível de produção
Itere rapidamente no desenvolvimento do agente usando os seguintes recursos:
Crie e registre agentes usando qualquer biblioteca e MLflow. Parametrize seus agentes para experimentar e iterar rapidamente no desenvolvimento do agente.
Implante agentes para produção com suporte nativo para streaming de token e registro em log de solicitação/resposta, além de um aplicativo de revisão interno para obter comentários do usuário para seu agente.
O rastreamento do agente permite registrar, analisar e comparar rastreamentos no código do agente para depurar e entender como o agente responde às solicitações.
Avaliação e monitoramento
A avaliação e o monitoramento ajudam a determinar se o aplicativo RAG atende aos requisitos de qualidade, custo e latência. A avaliação ocorre durante o desenvolvimento, enquanto o monitoramento ocorre quando o aplicativo é implantado em produção.
O RAG sobre dados não estruturados tem muitos componentes que afetam a qualidade. Por exemplo, as alterações de formatação de dados podem influenciar as partes recuperadas e a capacidade do LLM de gerar respostas relevantes. Portanto, é importante avaliar componentes individuais além do aplicativo geral.
Para obter mais informações, consulte O que é Avaliação do Agente do Mosaic AI?.
Disponibilidade de região
Para ver a disponibilidade regional do Agent Framework, confira Recursos com disponibilidade regional limitada