Otimize a utilização de clusters de pipelines DLT com dimensionamento automático aprimorado
Este artigo descreve como usar o dimensionamento automático avançado para otimizar seus pipelines de DLT no Azure Databricks.
O dimensionamento automático melhorado é ativado por predefinição para todos os novos pipelines.
Para pipelines sem servidor, o dimensionamento automático aprimorado está sempre ativo e não pode ser desativado. Consulte Configurar um pipeline DLT sem servidor.
O que é o dimensionamento automático avançado?
O dimensionamento automático aprimorado do Databricks otimiza a utilização do cluster alocando automaticamente os recursos do cluster com base no volume da carga de trabalho, com impacto mínimo na latência de processamento de dados de seus pipelines.
O dimensionamento automático aprimorado melhora a funcionalidade de dimensionamento automático de cluster do Azure Databricks com os seguintes recursos:
- O dimensionamento automático aprimorado implementa a otimização de cargas de trabalho de streaming e adiciona aprimoramentos para melhorar o desempenho de cargas de trabalho em lote. O dimensionamento automático aprimorado otimiza os custos adicionando ou removendo máquinas à medida que a carga de trabalho muda.
- O dimensionamento automático aprimorado desliga proativamente os nós subutilizados, garantindo que não haja falhas nas tarefas durante o desligamento. A funcionalidade de dimensionamento automático do cluster existente reduz os nós apenas se eles estiverem ociosos.
O dimensionamento automático avançado é o modo de dimensionamento automático padrão quando você cria um novo pipeline na interface do usuário DLT. Você pode habilitar o dimensionamento automático aprimorado para pipelines existentes editando as configurações de pipeline na interface do usuário. Você também pode ativar o dimensionamento automático avançado ao criar ou editar pipelines com a DLT API .
Quais métricas o dimensionamento automático aprimorado usa para tomar uma decisão de aumento ou redução de escala?
O dimensionamento automático aprimorado usa duas métricas para decidir sobre o aumento ou a redução:
- Utilização de slots de tarefas: Esta é a proporção média entre o número de slots de tarefas ocupados e o total de slots de tarefas disponíveis no cluster.
- Tamanho da fila de tarefas: Este é o número de tarefas aguardando para serem executadas em slots de tarefas.
Ative o dimensionamento automático aprimorado para um pipeline DLT
O dimensionamento automático avançado é o modo de dimensionamento automático padrão quando você cria um novo pipeline na interface do usuário DLT. Você pode habilitar o dimensionamento automático aprimorado para pipelines existentes editando as configurações de pipeline na interface do usuário. Você também pode habilitar o dimensionamento automático aprimorado ao criar ou editar um pipeline com a API DLT.
Para usar o dimensionamento automático avançado, siga um destes procedimentos:
- Defina do modo Cluster como de dimensionamento automático avançado ao criar ou editar um pipeline na interface do usuário DLT.
- Adicione a configuração
autoscaleà configuração do cluster de pipeline e defina o campomodecomoENHANCED. Consulte Configurar computação para um pipeline DLT.
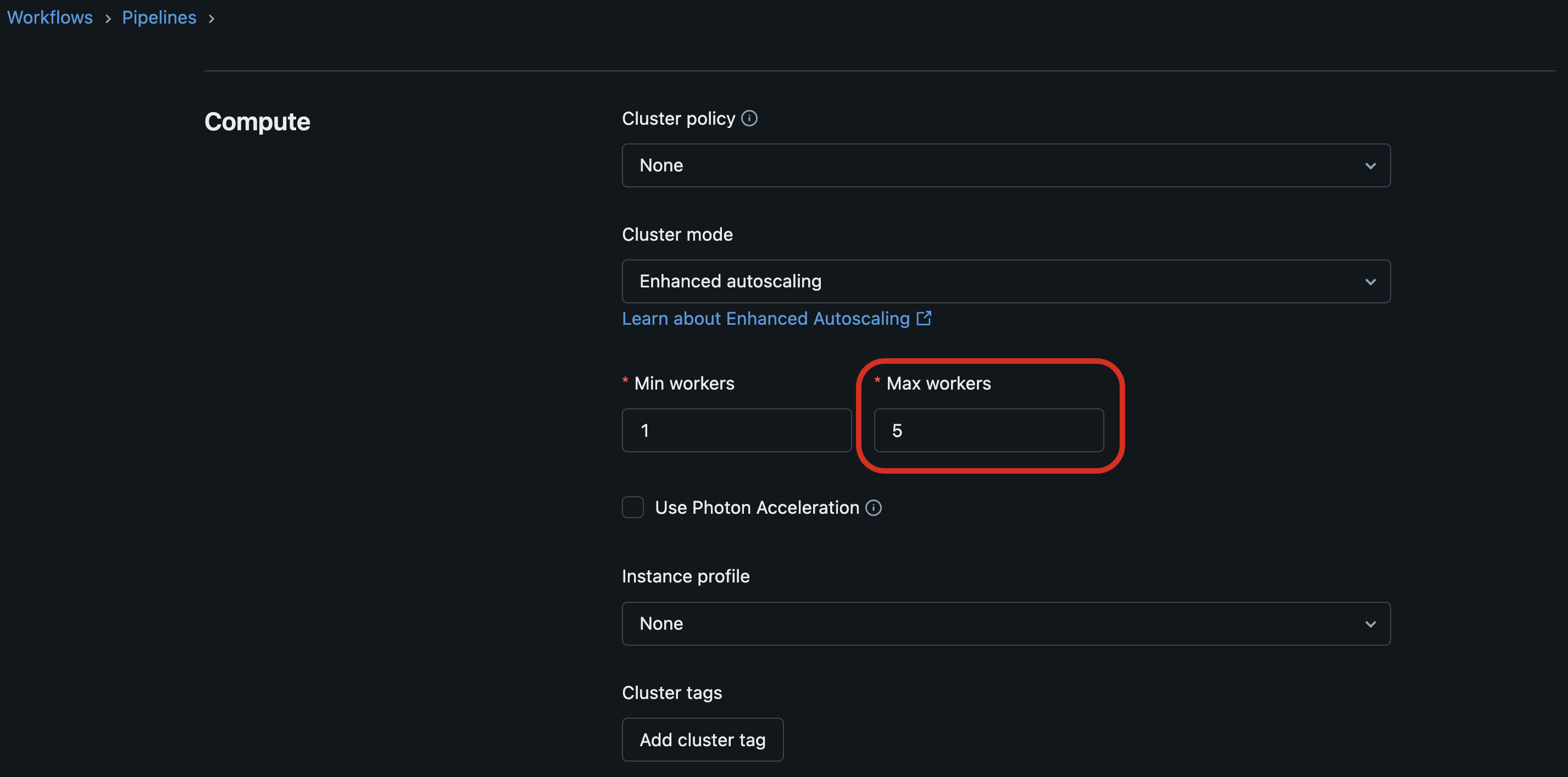
Use as seguintes diretrizes ao configurar o dimensionamento automático aprimorado para pipelines de produção:
- Deixe a configuração
Min workersno padrão. - Defina a configuração
Max workerspara um valor baseado no orçamento e na prioridade do pipeline.
O exemplo a seguir configura um cluster de dimensionamento automático aprimorado com um mínimo de 5 trabalhadores e um máximo de 10 trabalhadores.
max_workers deve ser maior ou igual a min_workers.
Observação
- O dimensionamento automático avançado está disponível apenas para clusters
updates. O escalonamento automático legado é usado para clustersmaintenance. - A configuração
autoscaletem dois modos:
{
"clusters": [
{
"autoscale": {
"min_workers": 5,
"max_workers": 10,
"mode": "ENHANCED"
}
}
]
}
Se o pipeline estiver configurado para execução contínua, ele será reiniciado automaticamente após as alterações na configuração de dimensionamento automático. Após o reinício, espere um curto período de maior latência. Após esse breve período de latência aumentada, o tamanho do cluster deve ser atualizado com base na configuração do autoscale e a latência do pipeline deve retornar às suas características de latência anteriores.
Limite os custos dos pipelines que utilizam aprimorado dimensionamento automático
Observação
Não é possível configurar operadores para pipelines sem servidor.
A definição do parâmetro Max workers nos pipelines painel Compute define um limite superior para dimensionamento automático. A redução do número de trabalhadores disponíveis pode aumentar a latência de algumas cargas de trabalho, mas evita que os custos dos recursos de computação aumentem durante operações de computação intensiva.
A Databricks recomenda ajustar as configurações de dos trabalhadores do Max para equilibrar a compensação custo-latência para suas necessidades específicas.
Monitore pipelines clássicos habilitados para dimensionamento automático aprimorado
Você pode usar o log de eventos na interface do usuário DLT para monitorar métricas aprimoradas de dimensionamento automático para pipelines clássicos. Os eventos de dimensionamento automático aprimorado têm o tipo de evento autoscale. Seguem-se exemplos de eventos:
| Evento | Mensagem |
|---|---|
| Solicitação de redimensionamento de cluster iniciada | Scaling [up or down] to <y> executors from current cluster size of <x> |
| Solicitação de redimensionamento de cluster bem-sucedida | Achieved cluster size <x> for cluster <cluster-id> with status SUCCEEDED |
| Solicitação de redimensionamento de cluster parcialmente bem-sucedida | Achieved cluster size <x> for cluster <cluster-id> with status PARTIALLY_SUCCEEDED |
| Falha na solicitação de redimensionamento de cluster | Achieved cluster size <x> for cluster <cluster-id> with status FAILED |
Você também pode exibir eventos de dimensionamento automático aprimorados consultando diretamente o log de eventos :
- Para consultar o log de eventos em busca de métricas de lista de pendências, veja Monitorizar a lista de pendências de dados ao consultar o log de eventos.
- Para monitorizar solicitações e respostas de redimensionamento de cluster durante operações de escalamento automático melhorado, consulte Monitorizar eventos de escalamento automático melhorado no registo de eventos para pipelines sem servidorhabilitado.