Referência de tabela do sistema Jobs
Observação
O esquema lakeflow antigamente era conhecido como workflow. O conteúdo dos dois esquemas é idêntico. Para tornar o esquema do lakeflow visível, você deve habilitá-lo separadamente.
Este artigo é uma referência de como usar as tabelas do sistema lakeflow para monitorar trabalhos em sua conta. Essas tabelas incluem registros de todos os espaços de trabalho na sua conta implantados na mesma região de nuvem. Para ver registros de outra região, você deve exibir as tabelas de um workspace implantado nessa região.
Requisitos
- O esquema
system.lakeflowdeve ser habilitado por um administrador de conta. Consulte Habilitar esquemas de tabelas do sistema. - Para acessar essas tabelas do sistema, os usuários devem:
- Ser um administrador do metastore e um administrador de conta ou
- Tenha permissões de
USEeSELECTnos esquemas do sistema. Veja Conceder acesso às tabelas do sistema.
Tabelas de trabalhos disponíveis
Todas as tabelas de sistema relacionadas a trabalhos residem no esquema system.lakeflow. Atualmente, o esquema hospeda quatro tabelas:
| Tabela | Descrição | Dá suporte ao streaming | Período de retenção gratuito | Inclui dados globais ou regionais |
|---|---|---|---|---|
| trabalhos (Visualização Pública) | Controla todos os trabalhos criados na conta | Sim | 365 dias | Regional |
| job_tasks (Visualização Pública) | Controla todas as tarefas de trabalho executadas na conta | Sim | 365 dias | Regional |
| job_run_timeline (Visualização Pública) | Rastrea as execuções de tarefas e os metadados relacionados | Sim | 365 dias | Regional |
| job_task_run_timeline (Visualização Pública) | Controla execuções de tarefa de trabalho e metadados relacionados | Sim | 365 dias | Regional |
Referência de esquema detalhada
As seções a seguir fornecem referências de esquema para cada uma das tabelas do sistema relacionadas a trabalhos.
Esquema da tabela de trabalhos
A tabela jobs é uma SCD2 (tabela de dimensões de alteração lenta). Quando uma linha é alterada, uma nova linha é emitida, substituindo logicamente a anterior.
Caminho da tabela: system.lakeflow.jobs
| Nome da coluna | Tipo de dados | Descrição | Observações |
|---|---|---|---|
account_id |
cadeia de caracteres | O ID da conta à qual esta tarefa pertence | |
workspace_id |
cadeia de caracteres | O ID do espaço de trabalho ao qual este trabalho pertence | |
job_id |
cadeia de caracteres | A ID do trabalho | Somente único em um único espaço de trabalho |
name |
cadeia | O nome do trabalho fornecido pelo usuário | |
description |
cadeia | A descrição fornecida pelo usuário do trabalho | Esse campo estará vazio se você tiver chaves gerenciadas pelo cliente configuradas. Não preenchido para linhas emitidas antes do final de agosto de 2024 |
creator_id |
cadeia | A ID da entidade de segurança que criou o trabalho | |
tags |
cadeia | As tags personalizadas fornecidas pelo usuário associadas a este trabalho | |
change_time |
carimbo de data/hora | A hora da última modificação do trabalho | Fuso horário registrado como +00:00 (UTC) |
delete_time |
carimbo de data/hora | A hora em que o trabalho foi excluído pelo usuário | Fuso horário registrado como +00:00 (UTC) |
run_as |
cadeia | A ID do usuário ou entidade de serviço cujas permissões são usadas para a execução do trabalho |
Consulta de exemplo
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Esquema da tabela da tarefa de trabalho
A tabela de tarefas de trabalho é uma SCD2 (tabela de dimensões de alteração lenta). Quando uma linha é alterada, uma nova linha é emitida, substituindo logicamente a anterior.
Caminho da tabela: system.lakeflow.job_tasks
| Nome da coluna | Tipo de dados | Descrição | Observações |
|---|---|---|---|
account_id |
cadeia de caracteres | O ID da conta à qual esta tarefa pertence | |
workspace_id |
cadeia de caracteres | O ID do espaço de trabalho ao qual este trabalho pertence | |
job_id |
cadeia de caracteres | A ID do trabalho | Exclusivo em uma única área de trabalho |
task_key |
cadeia | A chave de referência para uma tarefa em um trabalho | Somente exclusivo em um único trabalho |
depends_on_keys |
matriz | As chaves de tarefa de todas as dependências upstream dessa tarefa | |
change_time |
carimbo de data/hora | A hora em que a tarefa foi modificada pela última vez | Fuso horário registrado como +00:00 (UTC) |
delete_time |
carimbo de data/hora | A hora em que uma tarefa foi excluída pelo usuário | Fuso horário registrado como +00:00 (UTC) |
Consulta de exemplo
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
Esquema da tabela da linha do tempo de execução do trabalho
A tabela de linha do tempo de execução do trabalho é imutável e completa no momento em que é produzida.
Caminho da tabela: system.lakeflow.job_run_timeline
| Nome da coluna | Tipo de dados | Descrição | Observações |
|---|---|---|---|
account_id |
cadeia | A ID da conta à qual esse trabalho pertence | |
workspace_id |
cadeia | O ID do espaço de trabalho ao qual este trabalho pertence | |
job_id |
cadeia de caracteres | A ID do trabalho | Essa chave só é exclusiva em um único workspace |
run_id |
cadeia | A ID da execução do trabalho | |
period_start_time |
carimbo de data/hora | A hora de início da corrida ou do período de tempo | As informações de fuso horário são registradas no final do valor com +00:00 representando UTC |
period_end_time |
carimbo de data/hora | A hora de término da execução ou do período | As informações de fuso horário são registradas no final do valor com +00:00 representando UTC |
trigger_type |
cadeia | O tipo de gatilho que pode disparar uma execução | Para obter valores possíveis, consulte Valores do tipo de gatilho |
run_type |
cadeia | Tipo de execução do trabalho | Para obter valores possíveis, consulte valores do tipo de execução |
run_name |
cadeia | O nome de execução fornecido pelo usuário associado a esta execução de trabalho | |
compute_ids |
matriz | Matriz que contém as IDs de computação de trabalhos para a execução do trabalho pai | Use para identificar o cluster de tarefas usado por tipos de execução WORKFLOW_RUN. Para obter outras informações de computação, consulte a job_task_run_timeline tabela.Não preenchido para linhas emitidas antes do final de agosto de 2024 |
result_state |
cadeia | O resultado da execução do trabalho | Para possíveis valores, consulte Valores de estado de resultado |
termination_code |
cadeia | O código de encerramento da execução do trabalho | Para obter os valores possíveis, consulte Valores do código de término. Não preenchido para linhas emitidas antes do final de agosto de 2024 |
job_parameters |
mapa | Os parâmetros de nível de trabalho usados na execução do trabalho | As configurações de notebook_params preteridas não estão incluídas neste campo. Não preenchido para linhas emitidas antes do final de agosto de 2024 |
Consulta de exemplo
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
Esquema da tabela da linha do tempo de execução da tarefa de trabalho
A tabela de linha do tempo de execução de tarefa de trabalho é imutável e concluída no momento em que é produzida.
Caminho da tabela: system.lakeflow.job_task_run_timeline
| Nome da coluna | Tipo de dados | Descrição | Observações |
|---|---|---|---|
account_id |
cadeia de caracteres | O ID da conta à qual esta tarefa pertence | |
workspace_id |
cadeia de caracteres | O ID do espaço de trabalho ao qual este trabalho pertence | |
job_id |
cadeia de caracteres | A ID do trabalho | Exclusivo em um único espaço de trabalho |
run_id |
cadeia | A ID da execução da tarefa | |
job_run_id |
cadeia | A ID da execução do trabalho | Não preenchido para linhas emitidas antes do final de agosto de 2024 |
parent_run_id |
cadeia | A ID da execução pai | Não preenchido para linhas emitidas antes do final de agosto de 2024 |
period_start_time |
carimbo de data/hora | A hora de início da tarefa ou do período de tempo | As informações de fuso horário são registradas no final do valor com +00:00 representando UTC |
period_end_time |
carimbo de data/hora | A hora de término da tarefa ou do período de tempo | As informações de fuso horário são registradas no final do valor com +00:00 representando UTC |
task_key |
cadeia | A chave de referência para uma tarefa em um trabalho | Essa chave só é exclusiva em um único trabalho |
compute_ids |
matriz | A matriz compute_ids contém IDs de clusters de trabalho, clusters interativos e sql warehouses usados pela tarefa de trabalho | |
result_state |
cadeia | O resultado da execução da tarefa de trabalho | Para possíveis valores, consulte Valores de estado de resultado |
termination_code |
cadeia | O código de encerramento da execução da tarefa | Para obter os valores possíveis, consulte Valores do código de término. Não preenchido para linhas emitidas antes do final de agosto de 2024 |
Padrões de junção comuns
As seções a seguir fornecem consultas de exemplo que realçam padrões de junção comumente usados para tabelas do sistema de trabalhos.
Unir as tabelas de trabalhos e linha do tempo de execução de trabalhos
aprimorar a execução do trabalho com um nome de trabalho
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Unir as tabelas de linha do tempo de execução de trabalhos e uso
Enriquecer cada log de faturamento com metadados de execução de tarefas
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Calcular custo por execução de trabalho
Essa consulta une-se à tabela do sistema billing.usage para calcular um custo por execução de trabalho.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Obter os logs de uso para trabalhos SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Unir as tabelas de linha do tempo de execução de tarefas de trabalho e clusters
Enriquecer a execução das tarefas de trabalho com metadados de clusters
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Encontre trabalhos em execução na computação de uso geral
Essa consulta une-se à tabela do sistema compute.clusters para retornar trabalhos recentes que estão em execução na computação para todas as finalidades em vez da computação de trabalhos.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Painel de acompanhamento de tarefas
O painel a seguir usa tabelas do sistema para ajudá-lo a começar a monitorar seus trabalhos e integridade operacional. Ele inclui casos de uso comuns, como acompanhamento de desempenho do trabalho, monitoramento de falhas e utilização de recursos.
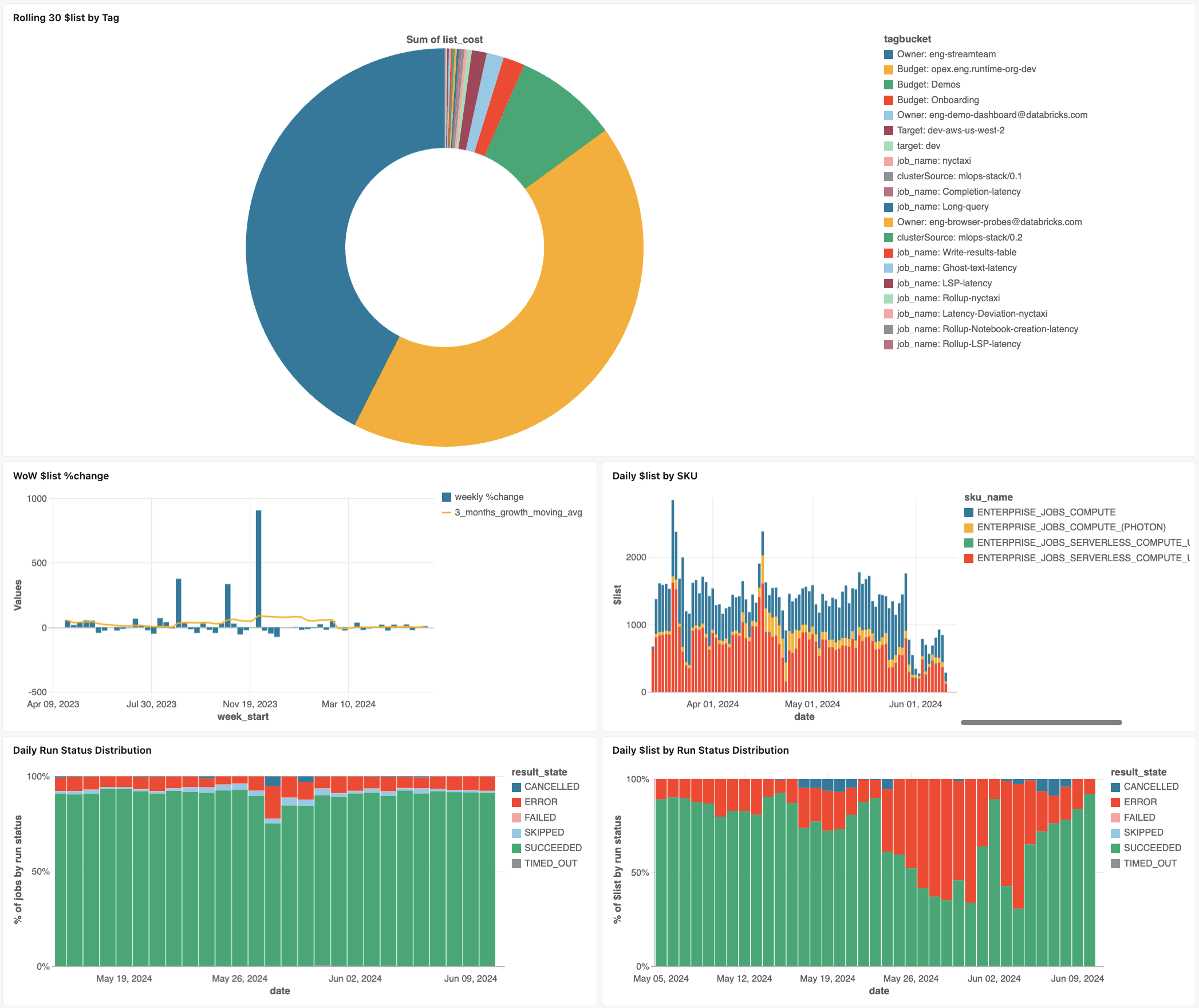
Para obter informações sobre como baixar o painel, consulte Monitorar custos de trabalho & desempenho com tabelas do sistema
Resolução de problemas
Trabalho não está registrado na tabela lakeflow.jobs
Se um trabalho não estiver visível nas tabelas do sistema:
- O trabalho não foi modificado nos últimos 365 dias
- Modifique qualquer um dos campos do trabalho presentes no esquema para emitir um novo registro.
- O trabalho foi criado em uma região diferente
- Criação recente de trabalhos (atraso da tabela)
Não consigo encontrar um trabalho visto na tabela job_run_timeline
Nem todas as execuções de tarefas são visíveis em todos os lugares. Embora as entradas JOB_RUN apareçam em todas as tabelas relacionadas ao trabalho, WORKFLOW_RUN (execuções de fluxo de trabalho do notebook) são registradas apenas em job_run_timeline e SUBMIT_RUN (execuções enviadas uma vez) são registradas apenas em ambas as tabelas da linha do tempo. Essas execuções não são preenchidas em outras tabelas do sistema de trabalho, como jobs ou job_tasks.
Consulte a tabela tipos de execução abaixo para obter um detalhamento de onde cada tipo de execução é visível e acessível.
Execução de tarefa não visível na tabela billing.usage
Em system.billing.usage, o usage_metadata.job_id só é preenchido para trabalhos executados em computação de trabalho ou computação sem servidor.
Além disso, os trabalhos WORKFLOW_RUN não têm sua própria atribuição de usage_metadata.job_id ou usage_metadata.job_run_id em system.billing.usage.
Em vez disso, o uso de computação deles é atribuído ao notebook pai que os acionou.
Isso significa que, quando um notebook inicia uma execução de fluxo de trabalho, todos os custos de computação aparecem sob o uso do notebook principal, e não como um trabalho de fluxo de trabalho separado.
Consulte a referência de metadados de uso para mais informações.
Calcular o custo de um trabalho em execução em uma computação de uso geral
Não é possível calcular o custo exato de trabalhos em execução na computação para todas as finalidades com 100% de precisão. Quando um trabalho é executado em uma computação interativa (para todos os fins), várias cargas de trabalho, como notebooks, consultas SQL ou outros trabalhos, geralmente são executadas simultaneamente no mesmo recurso de computação. Como os recursos do cluster são compartilhados, não há nenhum mapeamento direto 1:1 entre os custos de computação e as execuções de trabalho individuais.
Para um acompanhamento preciso de custos de trabalho, o Databricks recomenda a execução de trabalhos em computação de trabalho dedicada ou computação sem servidor, em que o usage_metadata.job_id e usage_metadata.job_run_id permitem a atribuição de custo precisa.
Se você precisar usar a computação de todas as finalidades, poderá:
- Monitore o uso e os custos gerais do cluster em
system.billing.usagecom base emusage_metadata.cluster_id. - Acompanhe as métricas de tempo de execução da tarefa separadamente.
- Considere que qualquer estimativa de custo será aproximada devido aos recursos compartilhados.
Consulte Referência de metadados de uso para obter mais informações sobre a atribuição de custo.
Valores de referência
A seção a seguir inclui referências para colunas selecionadas em tabelas relacionadas a trabalhos.
Valores do tipo de gatilho
Os valores possíveis para a coluna trigger_type são:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Valores do tipo de execução
Os valores possíveis para a coluna run_type são:
| Type | Descrição | Localização da interface do usuário | Ponto de Extremidade de API | Tabelas do sistema |
|---|---|---|---|---|
JOB_RUN |
Execução de trabalho padrão | Interface do usuário de Trabalhos e Execuções de Trabalho | pontos de extremidade /jobs e /jobs/runs | jobs, job_tasks, job_run_timeline, job_task_run_timeline |
SUBMIT_RUN |
Execução única via POST /jobs/runs/submit | Somente Interface do Usuário de Execuções de Trabalho | Somente pontos de extremidade /jobs/runs | job_run_timeline, job_task_run_timeline |
WORKFLOW_RUN |
Execução iniciada a partir do fluxo de trabalho do notebook | Não visível | Não acessível | cronograma_de_execução_do_trabalho |
Valores do estado do resultado
Os valores possíveis para a coluna result_state são:
| Estado | Descrição |
|---|---|
SUCCEEDED |
A execução foi concluída com êxito |
FAILED |
A execução foi concluída com um erro |
SKIPPED |
A execução nunca ocorreu porque uma condição não foi atendida |
CANCELLED |
A execução foi cancelada a pedido do usuário |
TIMED_OUT |
A execução foi interrompida após atingir o tempo limite |
ERROR |
A execução foi concluída com um erro |
BLOCKED |
A execução foi bloqueada em uma dependência upstream |
Valores do código de encerramento
Os valores possíveis para a coluna termination_code são:
| Código de encerramento | Descrição |
|---|---|
SUCCESS |
A execução foi concluída com sucesso |
CANCELLED |
A execução foi cancelada durante a execução pela plataforma Databricks; por exemplo, se a duração máxima da execução foi excedida |
SKIPPED |
A execução nunca ocorreu, por exemplo, se a execução da tarefa anterior falhou, a condição do tipo de dependência não foi atendida ou não havia tarefas concretas a serem executadas |
DRIVER_ERROR |
A execução encontrou um erro ao se comunicar com o Spark Driver. |
CLUSTER_ERROR |
Falha na execução devido a um erro de cluster |
REPOSITORY_CHECKOUT_FAILED |
Falha ao concluir a finalização da compra devido a um erro ao se comunicar com o serviço de terceiros |
INVALID_CLUSTER_REQUEST |
A execução falhou porque emitiu uma solicitação inválida para iniciar o cluster |
WORKSPACE_RUN_LIMIT_EXCEEDED |
O workspace atingiu o limite para o número máximo de executações simultâneas ativas. Considere agendar as execuções em um período maior |
FEATURE_DISABLED |
A execução falhou porque tentou acessar um recurso indisponível para o workspace |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
O número de solicitações de criação, inicialização e aumento de capacidade de cluster excedeu o limite de taxa permitido. Considere distribuir a execução do processo em um período maior |
STORAGE_ACCESS_ERROR |
A execução falhou devido a um erro ao acessar o armazenamento de blobs do cliente |
RUN_EXECUTION_ERROR |
A execução foi concluída com falhas de tarefa |
UNAUTHORIZED_ERROR |
A execução falhou devido a um problema de permissão ao acessar um recurso |
LIBRARY_INSTALLATION_ERROR |
A execução falhou durante a instalação da biblioteca solicitada pelo usuário. As causas podem incluir, mas não se limitam a: a biblioteca fornecida é inválida, não há permissões suficientes para instalar a biblioteca e assim por diante |
MAX_CONCURRENT_RUNS_EXCEEDED |
A execução agendada excede o limite máximo de execuções simultâneas definidas para o trabalho |
MAX_SPARK_CONTEXTS_EXCEEDED |
A execução é agendada em um cluster que já atingiu o número máximo de contextos que está configurado para criar |
RESOURCE_NOT_FOUND |
Um recurso necessário para execução não existe |
INVALID_RUN_CONFIGURATION |
Falha na execução devido a uma configuração inválida |
CLOUD_FAILURE |
A execução falhou devido a um problema de provedor de nuvem |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
A execução foi ignorada devido ao alcance do limite de tamanho da fila no nível do trabalho |