Transformar dados na Rede Virtual do Azure usando a atividade do Hive no Azure Data Factory usando o portal do Azure
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você pode usar o portal do Azure para criar um pipeline do Data Factory que transforma dados usando a atividade Hive em um cluster HDInsight que está em uma Rede Virtual (VNet) do Azure. Neste tutorial, você realizará os seguintes procedimentos:
- Criar um data factory.
- Criar um Integration Runtime auto-hospedado
- Criar serviços vinculados do Armazenamento do Azure e do Azure HDInsight
- Criar um pipeline com atividade do Hive.
- Dispare uma execução de pipeline.
- Monitorar a execução de pipeline
- Verificar a saída
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Conta de Armazenamento do Azure. Você cria um script Hive e carrega-o no Armazenamento do Azure. A saída do script Hive é armazenada nessa conta de armazenamento. Nessa amostra, o cluster HDInsight usa essa conta de Armazenamento do Azure como o armazenamento primário.
Rede Virtual do Azure. Se você não tem uma Rede Virtual do Azure, crie-a seguindo estas instruções. Nessa amostra, o HDInsight está em uma Rede Virtual do Azure. Aqui está uma amostra de configuração de Rede Virtual do Azure.
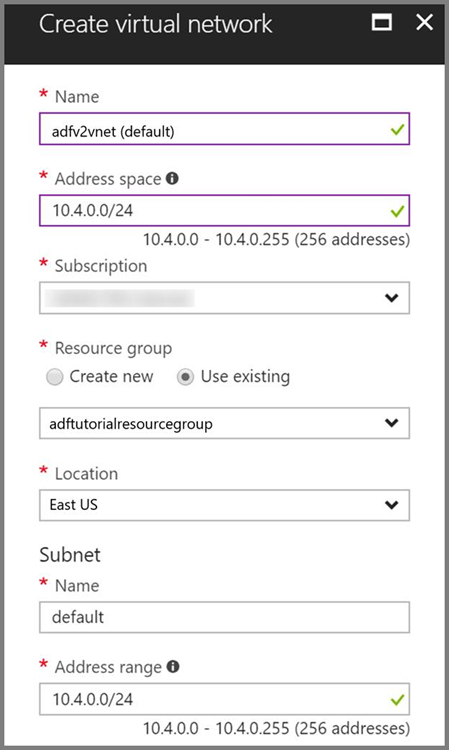
Cluster HDInsight. Crie um cluster HDInsight e ingresse-o na rede virtual criada na etapa anterior seguindo este artigo: Estender o Azure HDInsight usando uma Rede Virtual do Azure. Aqui está uma amostra de configuração do HDInsight em uma Rede Virtual do Azure.
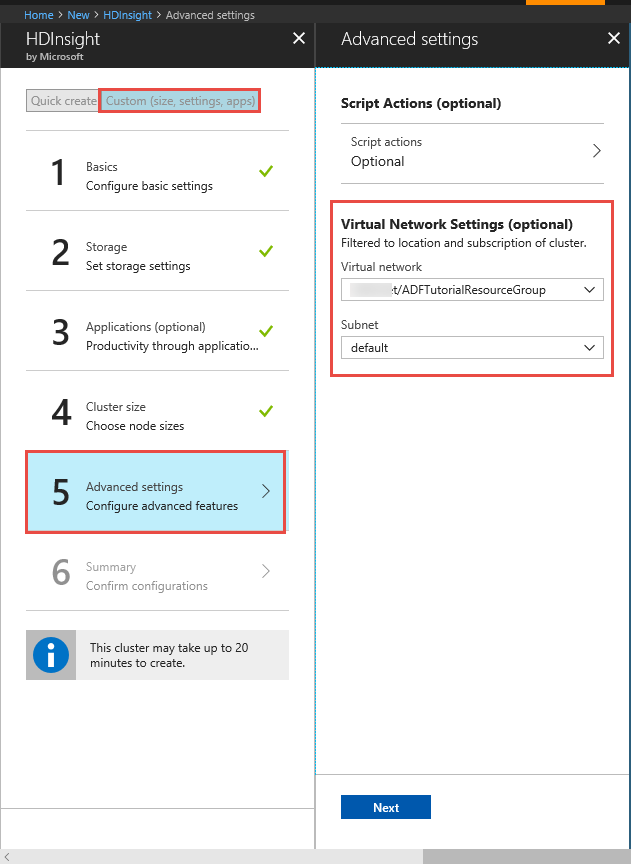
Azure PowerShell. Siga as instruções em Como instalar e configurar o Azure PowerShell.
Uma máquina virtual. Crie uma máquina virtual do Azure e ingresse-a na mesma rede virtual que contém seu cluster HDInsight. Para obter detalhes, consulte Como criar máquinas virtuais.
Carregar o script Hive em sua conta de Armazenamento de Blobs
Crie um arquivo Hive SQL chamado hivescript.hql com o seguinte conteúdo:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableNo seu Armazenamento de Blobs do Azure, crie um contêiner denominado adftutorial se ele não existir.
Crie uma pasta chamada hivescripts.
Carregar o arquivo hivescript.hql na subpasta hivescripts.
Criar uma data factory
Se você ainda não criou o data factory, siga as etapas no Início Rápido: crie um data factory usando o portal do Azure e o Estúdio do Azure Data Factory para criar um. Depois de criá-lo, navegue até o data factory no portal do Azure.

Selecione Abrir no bloco Abrir Estúdio do Azure Data Factory para iniciar o aplicativo Data Integration em uma guia separada.
Criar um Integration Runtime auto-hospedado
Como o cluster Hadoop está em uma rede virtual, você precisa instalar um runtime de integração auto-hospedada (IR) na mesma rede virtual. Nesta seção, crie uma nova VM, associe-a à mesma rede virtual e instale o IR auto-hospedado nela. O IR auto-hospedado permite que o serviço Data Factory distribua as solicitações de processamento para um serviço de computação como o HDInsight em uma rede virtual. Ele também permite mover dados para/de armazenamentos de dados de uma rede virtual para o Azure. Você usa um IR auto-hospedado quando a computação ou o armazenamento de dados estão em um ambiente local também.
Na interface do usuário do Azure Data Factory, clique em Conexões na parte inferior da janela, alterne para a guia Runtimes de integração e, em seguida, clique em + Novo na barra de ferramentas.
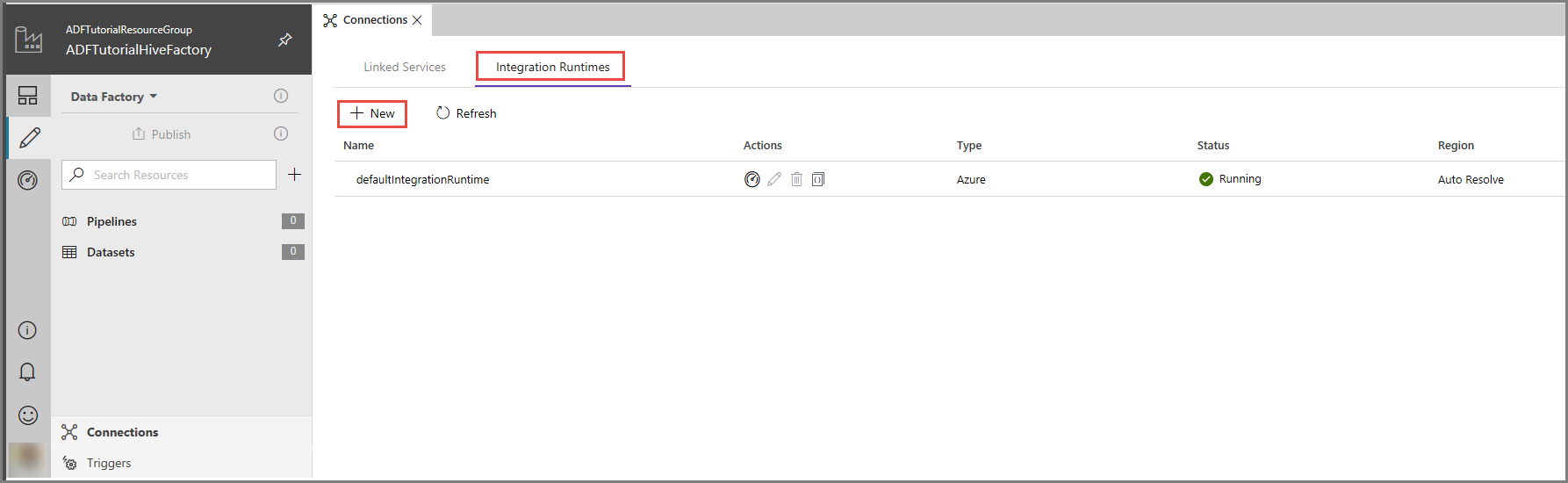
Na janela Instalação do Integration Runtime, selecione a opção Executar atividades de movimentação e distribuição de dados para cálculos externos e clique em Avançar.
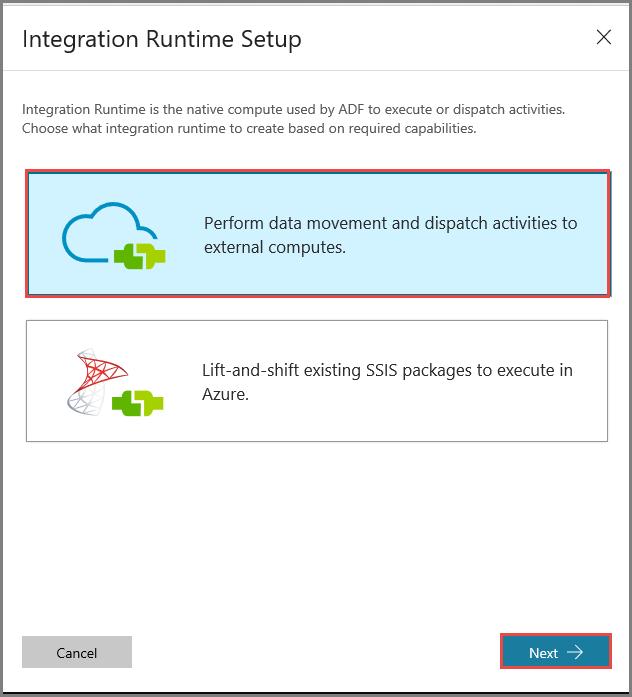
Selecione Rede Privada e clique em Avançar.
Insira MySelfHostedIR como Nome e clique em Avançar.
Copie a chave de autenticação do runtime de integração clicando no botão de cópia e salve-a. Mantenha a janela aberta. Você pode usar essa chave para registrar o IR instalado em uma máquina virtual.
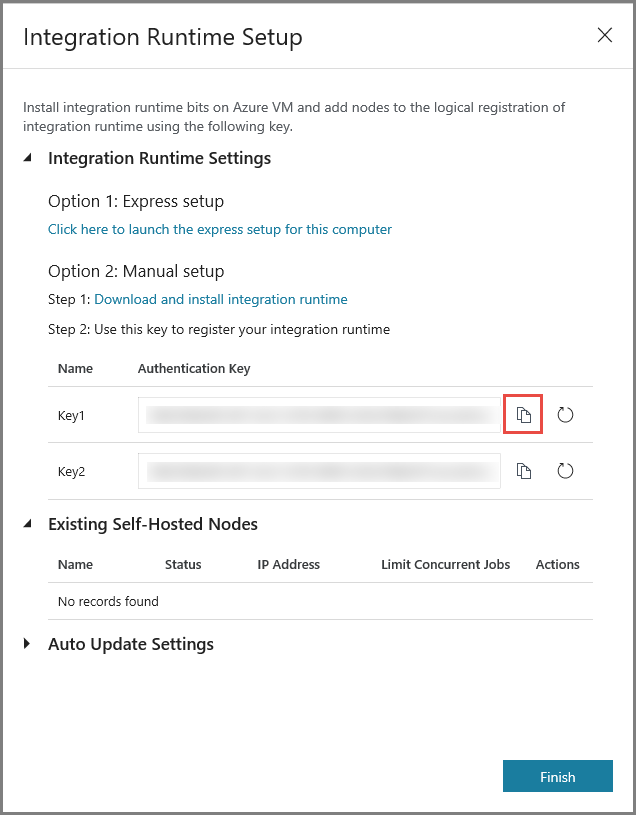
Instalar o IR em uma máquina virtual
Na VM do Azure, baixe o Integration Runtime auto-hospedado. Use a chave de autenticação obtida na etapa anterior para registrar manualmente o runtime de integração auto-hospedada.
Você verá a seguinte mensagem quando o runtime de integração auto-hospedada for registrado com êxito.
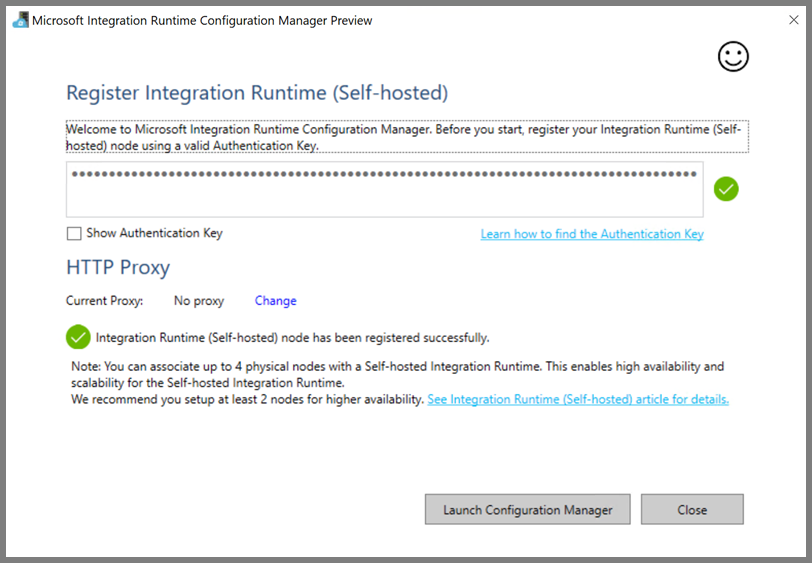
Clique em Iniciar Configuration Manager. Você verá a página a seguir quando o nó estiver conectado ao serviço de nuvem:
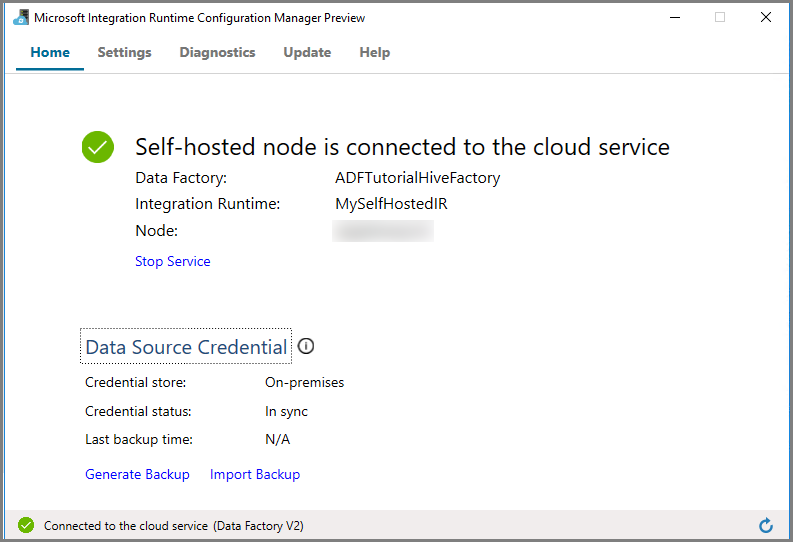
IR auto-hospedado na interface do usuário do Azure Data Factory
Na interface do usuário do Azure Data Factory, você deverá ver o nome do nome da VM auto-hospedada e seu status.
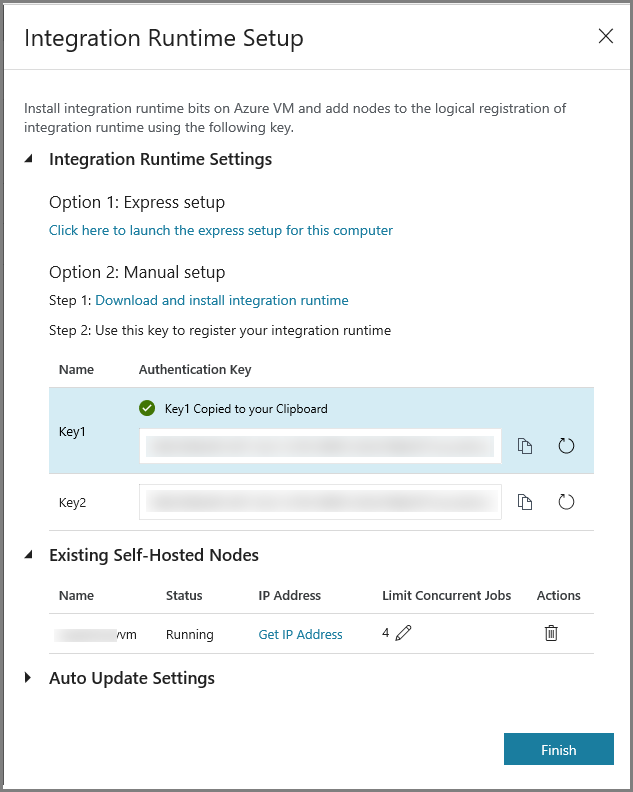
Clique em Concluir para fechar a janela Configuração do Integration Runtime. Você vê o IR auto-hospedado na lista de runtimes de integração.

Criar serviços vinculados
Você cria e implanta dois serviços vinculados nesta seção:
- Um serviço vinculado do Armazenamento do Azure que vincula uma conta de Armazenamento do Azure ao data factory. Esse armazenamento é o armazenamento primário usado por seu cluster HDInsight. Nesse caso, você também pode usar essa conta do Armazenamento do Azure para manter o script Hive e a saída do script.
- Um Serviço Vinculado do HDInsight. O Azure Data Factory envia o script do Hive a este cluster do HDInsight para execução.
Criar o serviço vinculado do armazenamento do Azure
Alterne para a guia Serviços Vinculados e, em seguida, clique em Novo.
Na janela Novo Serviço Vinculado, selecione Armazenamento de Blobs do Azure e clique em Continuar.
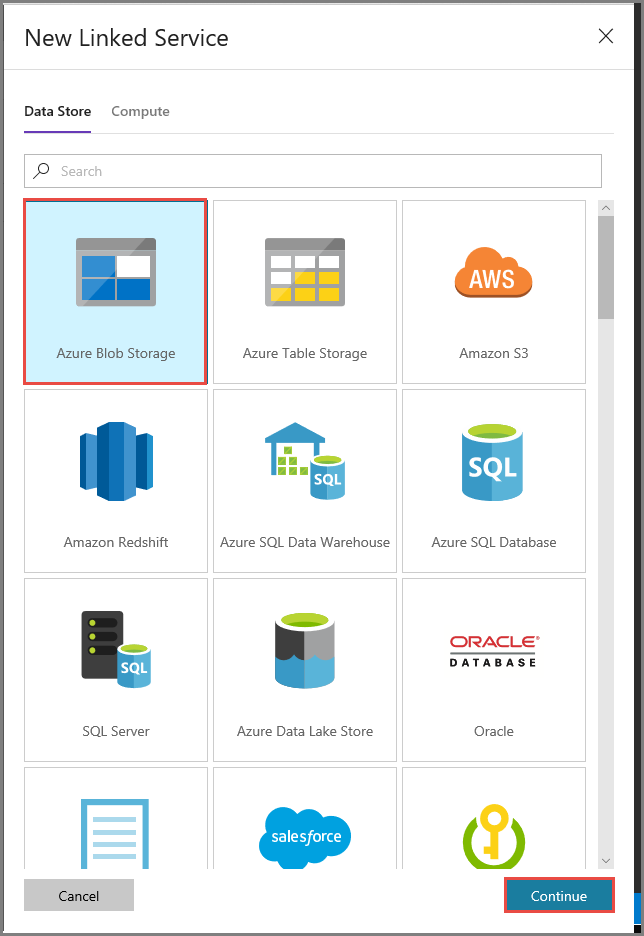
Na janela Novo Serviço Vinculado, execute estas etapas:
Insira AzureStorageLinkedService como o Nome.
Selecione MySelfHostedIR para Conectar por meio do runtime de integração.
Selecione sua conta de armazenamento do Azure como o Nome da conta de armazenamento.
Clique em Testar conectividade para testar a conexão à Conta do Armazenamento do Azure.
Clique em Save (Salvar).
Criar o serviço vinculado ao HDInsight
Clique em Novo outra vez para criar outro serviço vinculado.
Alterne para a guia Computação, selecione Azure HDInsight e clique em Continuar.
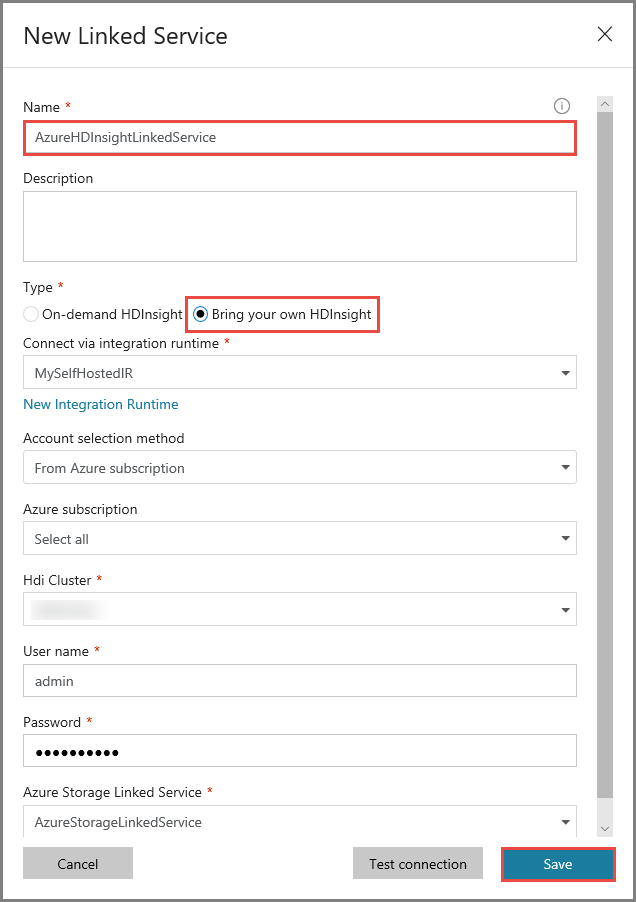
Na janela Novo Serviço Vinculado, execute estas etapas:
Insira AzureHDInsightLinkedService no Nome.
Selecione Traga seu próprio HDInsight.
Selecione o cluster HDInsight para Cluster Hdi.
Insira o nome de usuário para o cluster HDInsight.
Insira a senha para o usuário.
Este artigo pressupõe que você tenha acesso ao cluster via Internet. Por exemplo, que você possa se conectar ao cluster em https://clustername.azurehdinsight.net. Esse endereço usa o gateway público, que não estará disponível se você tiver usado NSGs (Grupos de Segurança de Rede) ou UDRs (rotas definidas pelo usuário) para restringir o acesso da Internet. Para que o Data Factory possa enviar trabalhos para o cluster HDInsight na Rede Virtual do Azure, você precisa configurar sua Rede Virtual do Azure de modo que a URL possa ser resolvida para o endereço IP do gateway usado pelo HDInsight.
No Portal do Azure, abra a Rede Virtual que contém o HDInsight. Abra o adaptador de rede cujo nome começa com
nic-gateway-0. Anote o endereço IP privado dela. Por exemplo, 10.6.0.15.Se sua Rede Virtual do Azure tem um servidor DNS, atualize o registro DNS de modo que a URL do cluster do HDInsight
https://<clustername>.azurehdinsight.netpossa ser resolvida para10.6.0.15. Se você não tiver um servidor DNS em sua Rede Virtual do Azure, você poderá usar uma solução alternativa temporária para isso editando o arquivo de hosts (C:\Windows\System32\drivers\etc.) de todas as VMs registradas como nós de runtime de integração auto-hospedada, adicionando uma entrada semelhante a esta:10.6.0.15 myHDIClusterName.azurehdinsight.net
Criar um pipeline
Nesta etapa, você cria um pipeline com uma atividade Hive. A atividade executa o script do Hive para retornar dados de uma tabela de exemplo e salvá-los em um caminho que você definiu.
Observe os seguintes pontos:
- scriptPath aponta para o caminho para o script Hive na conta de Armazenamento do Azure que você usou para MyStorageLinkedService. O caminho diferencia maiúsculas de minúsculas.
- Output é um argumento usado no script Hive. Use o formato de
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/para apontá-lo para uma pasta existente no seu Armazenamento do Azure. O caminho diferencia maiúsculas de minúsculas.
Na interface de usuário do Data Factory, clique em + (adição) no painel esquerdo e clique em Pipeline.
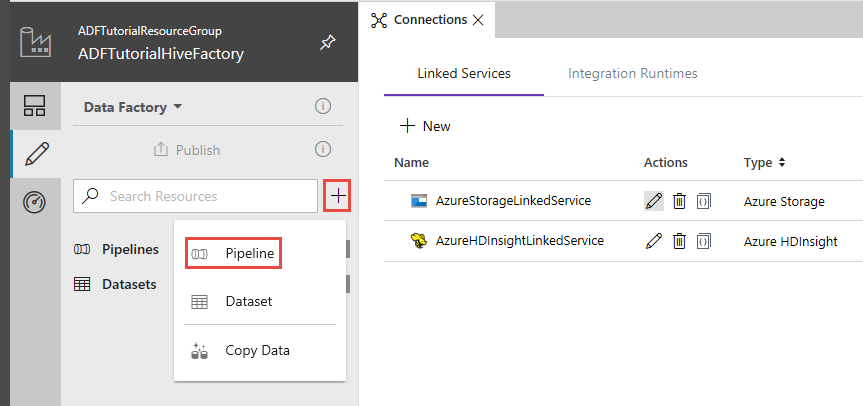
Na caixa de ferramentas Atividades, expanda HDInsighte arraste e solte a atividade Hive para a superfície do designer de pipeline.
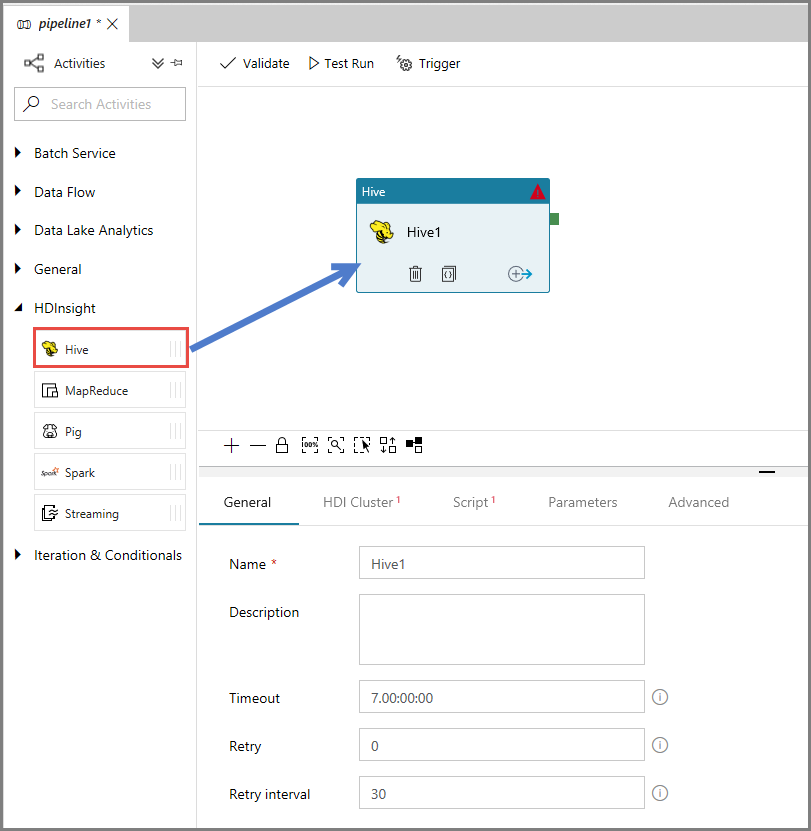
Na janela de propriedades, alterne para a guia Cluster HDI e selecione AzureHDInsightLinkedService para Serviço Vinculado do HDInsight.

Alterne para a guia Scripts e siga estas etapas:
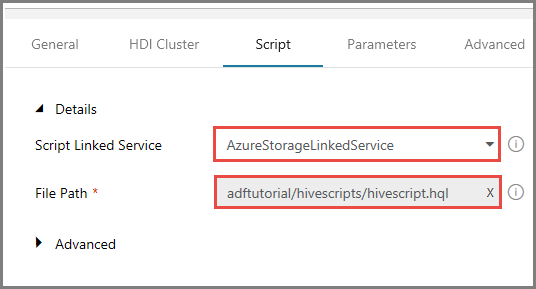
Selecione AzureStorageLinkedService como Serviço Vinculado de Script.
Para Caminho do Arquivo, clique em Procurar Armazenamento.
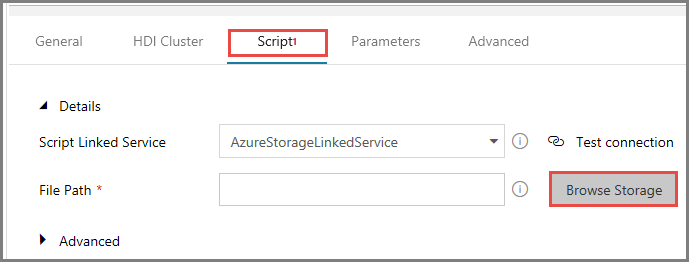
Na janela Escolher um arquivo ou uma pasta, navegue até a pasta hivescripts no contêiner adftutorial, selecione o arquivo hivescript.hql e clique em Concluir.
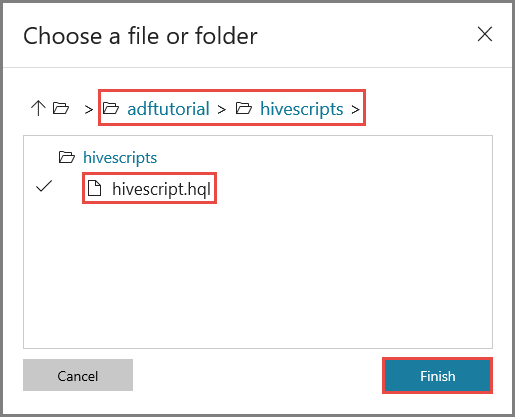
Confirme que você vê adftutorial/hivescripts/hivescript.hql em Caminho do arquivo.
Na guia Script, expanda a seção Avançado.
Clique em Preenchimento automático desde o script para Parâmetros.
Insira o valor para o parâmetro Output no seguinte formato:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Por exemplo:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.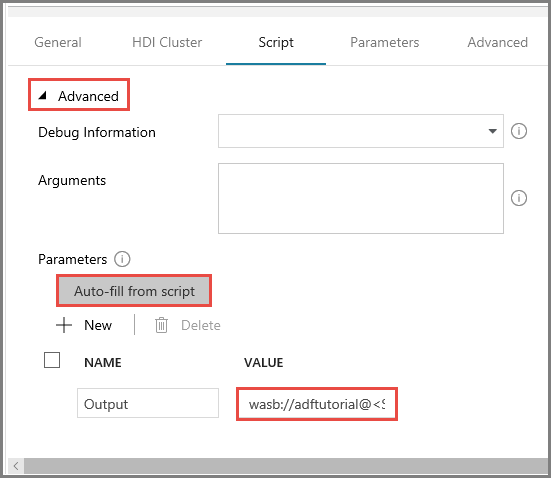
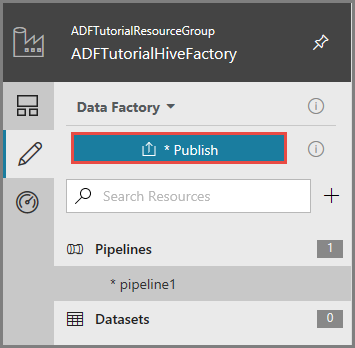
Para publicar artefatos no Data Factory, clique em Publicar.
Disparar uma execução de pipeline
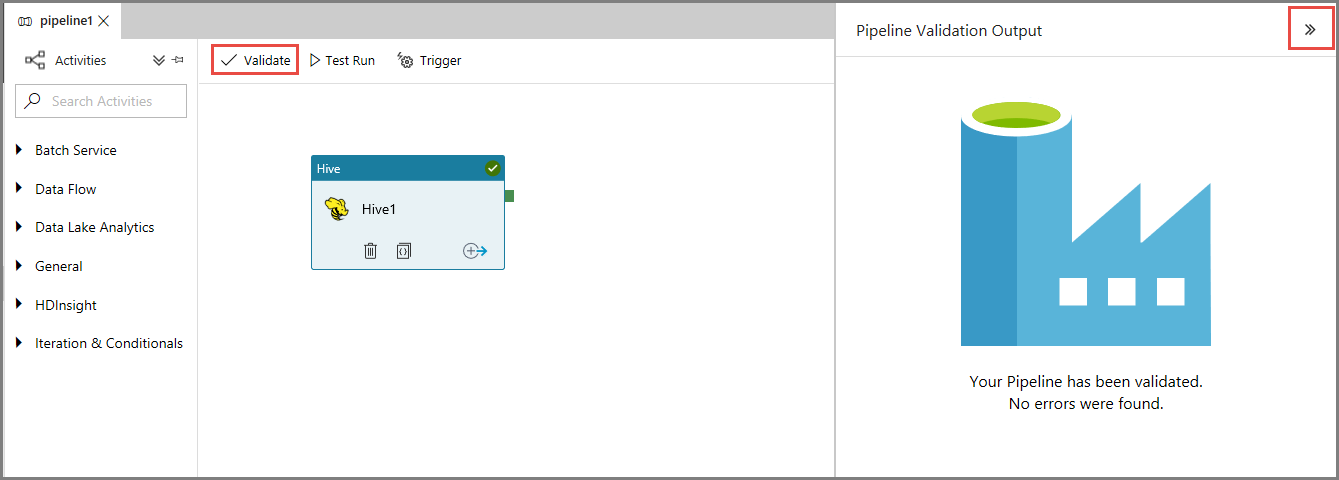
Primeiro, valide o pipeline clicando no botão Validar na barra de ferramentas. Feche a janela de Saída da Validação do Pipeline clicando na seta para a direita (>>).
Para disparar uma execução de pipeline, clique em Disparar na barra de ferramentas e em Disparar Agora.
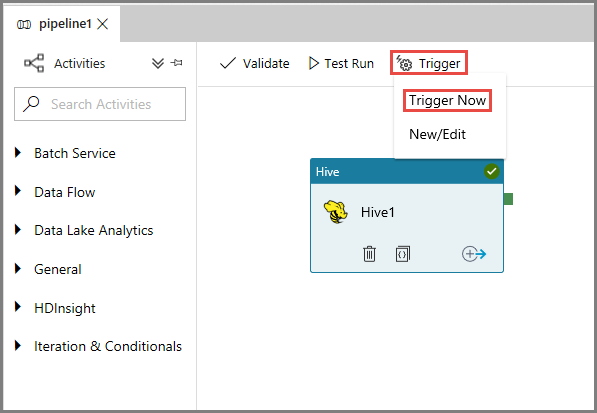
Monitorar a execução de pipeline
Alterne para a guia Monitorar à esquerda. Você vê uma execução de pipeline na lista Execuções de Pipeline.
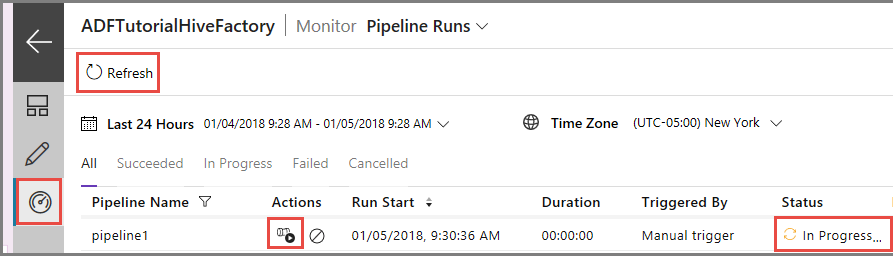
Para atualizar a lista, clique em Atualizar.
Para exibir execuções de atividade associadas com a execução do pipeline, clique em Exibir execuções de atividade na coluna Ação. Outros links de ação são para interromper/executar novamente o pipeline.
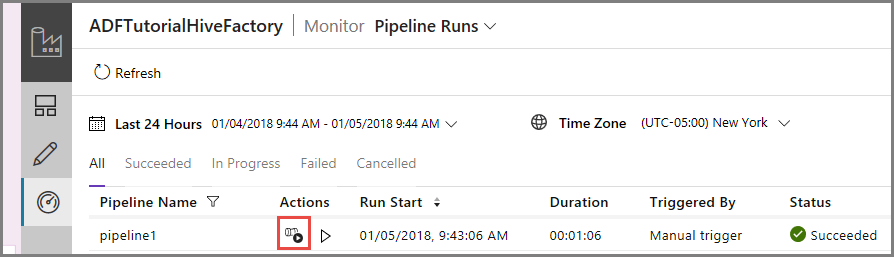
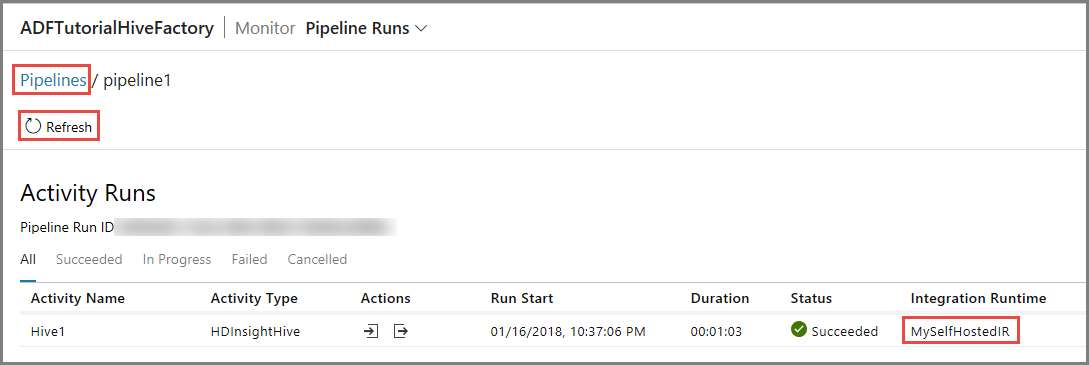
Você vê somente as execuções de atividade, já que há apenas uma atividade no pipeline do tipo HDInsightHive. Para voltar para o modo de exibição anterior, clique no link Pipelines na parte superior.
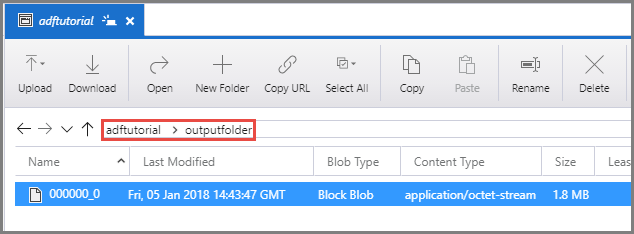
Confirme que você vê um arquivo de saída na pasta outputfolder do contêiner adftutorial.
Conteúdo relacionado
Neste tutorial, você realizará os seguintes procedimentos:
- Criar um data factory.
- Criar um Integration Runtime auto-hospedado
- Criar serviços vinculados do Armazenamento do Azure e do Azure HDInsight
- Criar um pipeline com atividade do Hive.
- Dispare uma execução de pipeline.
- Monitorar a execução de pipeline
- Verificar a saída
Avance para o tutorial a seguir para saber mais sobre como transformar dados usando um cluster Spark no Azure: