Carregar incrementalmente dados da Instância Gerenciada de SQL do Azure para o Armazenamento do Azure usando CDA (captura de dados de alterações)
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você cria um Azure Data Factory com um pipeline que carrega dados delta com base em informações de CDA (captura de dados de alterações) no banco de dados de Instância Gerenciada de SQL do Azure de origem para um armazenamento de blobs do Azure.
Neste tutorial, você realizará os seguintes procedimentos:
- Prepare o armazenamento de dados de origem
- Criar um data factory.
- Criar serviços vinculados.
- Crie conjuntos de dados de origem e de coletor.
- Criar, depurar e executar o pipeline para verificar se há dados alterados
- Modificar dados na tabela de origem
- Concluir, executar e monitorar o pipeline de cópia incremental completo
Visão geral
A tecnologia de captura de dados de alterações compatível com armazenamentos de dados, como MI (instâncias gerenciadas) do Azure SQL e SQL Server, pode ser usada para identificar dados alterados. Este tutorial descreve como usar o Azure Data Factory com a tecnologia de Captura de Dados de Alterações do SQL para carregar incrementalmente os dados delta da Instância Gerenciada de SQL do Azure no Armazenamento de Blobs do Azure. Para obter informações mais concretas sobre a tecnologia de captura de dados de alterações do SQL, confira Captura de dados de alterações no SQL Server.
Fluxos de trabalho completos
Estas são as etapas normais de fluxo de trabalho de ponta a ponta para carregar incrementalmente os dados usando a tecnologia de Captura de Dados de Alterações.
Observação
A MI do Azure SQL e o SQL Server dão suporte à tecnologia de captura de dados de alterações. Este tutorial usa a Instância Gerenciada de SQL do Azure como o armazenamento de dados de origem. Você também pode usar um SQL Server local.
Solução de alto nível
Neste tutorial, você cria um pipeline que executa as seguintes operações:
- Crie uma atividade de procura para contar o número de registros alterados na tabela CDA do Banco de Dados SQL e passá-lo para uma atividade IF Condition.
- Crie uma If Condition para verificar se há registros alterados e, se houver, invocar a atividade de cópia.
- Crie uma atividade de cópia para copiar os dados inseridos/atualizados/excluídos entre a tabela do CDA para o armazenamento de Blobs do Azure.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Instância Gerenciada de SQL do Azure. Você usa o banco de dados como um armazenamento de dados de origem. Se você não tiver um Instância Gerenciada de SQL do Azure, confira o artigo Criar um Instância Gerenciada do Banco de Dados SQL do Azure para conhecer as etapas para criar uma.
- Conta de Armazenamento do Azure. Você usa o Armazenamento de Blobs como um armazenamento de dados de coletor. Se você não tiver uma conta de Armazenamento do Azure, veja o artigo Criar uma conta de armazenamento para conhecer as etapas para criar uma. Crie um contêiner chamado raw.
Criar uma tabela de fonte de dados no Banco de Dados SQL do Azure
Inicie o SQL Server Management Studio e conecte-se ao servidor de Instâncias Gerenciadas do SQL do Azure.
No Gerenciador de Servidores, clique com o botão direito do mouse no banco de dados e escolha Nova Consulta.
Execute o comando SQL a seguir no banco de dados de Instâncias Gerenciadas do SQL do Azure para criar uma tabela chamada
customerscomo o repositório de fonte de dados.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Habilite mecanismo de Captura de Dados de Alterações no banco de dados e na tabela de origem (clientes) executando a seguinte consulta SQL:
Observação
- Substitua <seu nome de esquema de origem> pelo esquema da MI do SQL do Azure que tem a tabela de clientes.
- A captura de dados de alterações não faz nada como parte das transações que alteram a tabela que está sendo controlada. Em vez disso, as operações de inserção, atualização e exclusão são gravadas no log de transações. Os dados depositados nas tabelas de alteração aumentam de modo não gerenciável se você não diminuir periódica e sistematicamente os dados. Para obter mais informações, confira Habilitar a Captura de Dados de Alterações para um banco de dados
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Insira dados na tabela de clientes executando o seguinte comando:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Observação
Nenhuma alteração histórica na tabela é capturada antes da habilitação da captura de dados de alterações.
Criar uma data factory
Siga as etapas do artigo Guia de Início Rápido: Criar um data factory usando o portal do Azure para criar um data factory, caso ainda não tenha um para usar.
Criar serviços vinculados
Os serviços vinculados são criados em um data factory para vincular seus armazenamentos de dados e serviços de computação ao data factory. Nesta seção, você cria serviços vinculados para sua conta de Armazenamento do Azure e a MI do SQL do Azure.
Crie um serviço vinculado do Armazenamento do Azure.
Nesta etapa, você vincula a Conta de Armazenamento do Azure ao data factory.
Clique em Conexões e clique em + Novo.
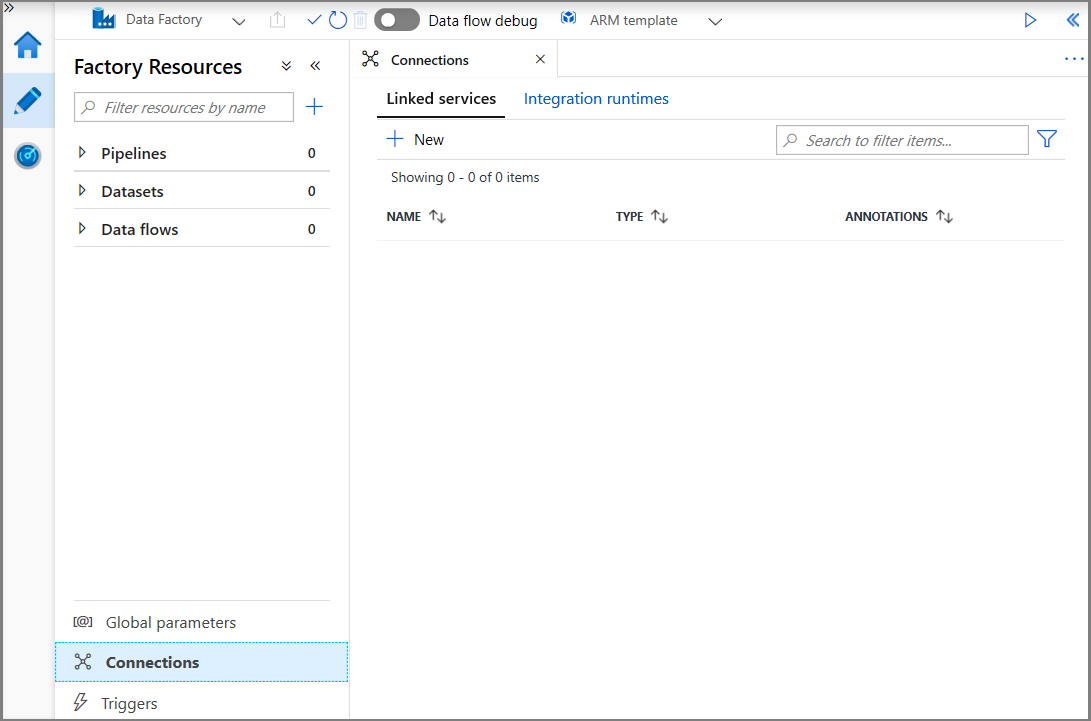
Na janela Novo Serviço Vinculado, selecione Armazenamento de Blobs do Azure e clique em Continuar.
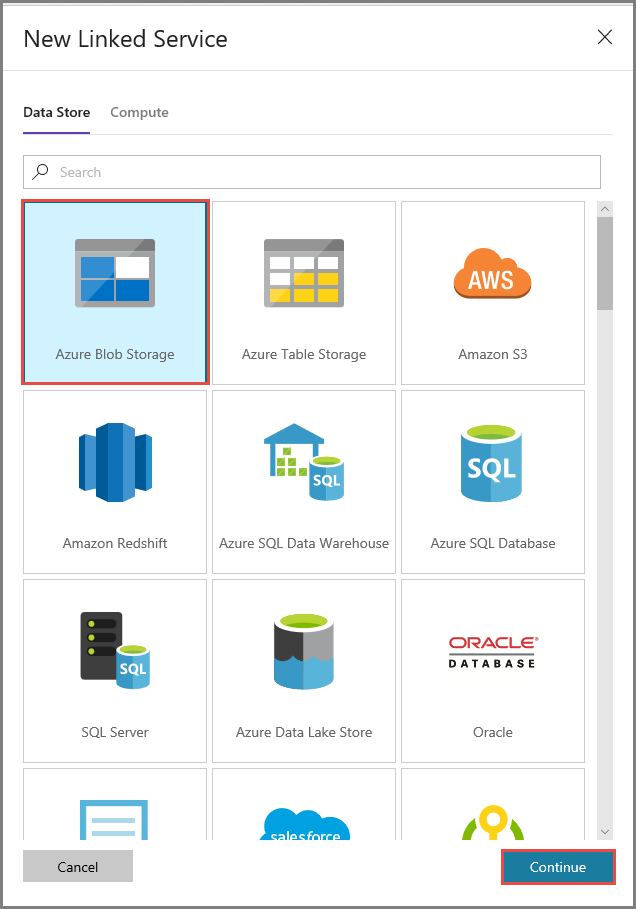
Na janela Novo Serviço Vinculado, execute estas etapas:
- Insira AzureStorageLinkedService como o Nome.
- Selecione sua conta de Armazenamento do Azure como o Nome da conta de armazenamento.
- Clique em Save (Salvar).
Crie um serviço vinculado do Banco de Dados de MI do SQL do Azure.
Nesta etapa, você vincula o banco de dados de MI SQL do Azure ao data factory.
Observação
Se você usa a MI do SQL, obtenha aqui informações sobre o acesso via ponto de extremidade público vs. privado. Se você estiver usando um ponto de extremidade privado, será necessário executar esse pipeline usando um runtime de integração auto-hospedada. O mesmo se aplica a quem executa o SQL Server nos cenários local, de VM ou de VNet.
Clique em Conexões e clique em + Novo.
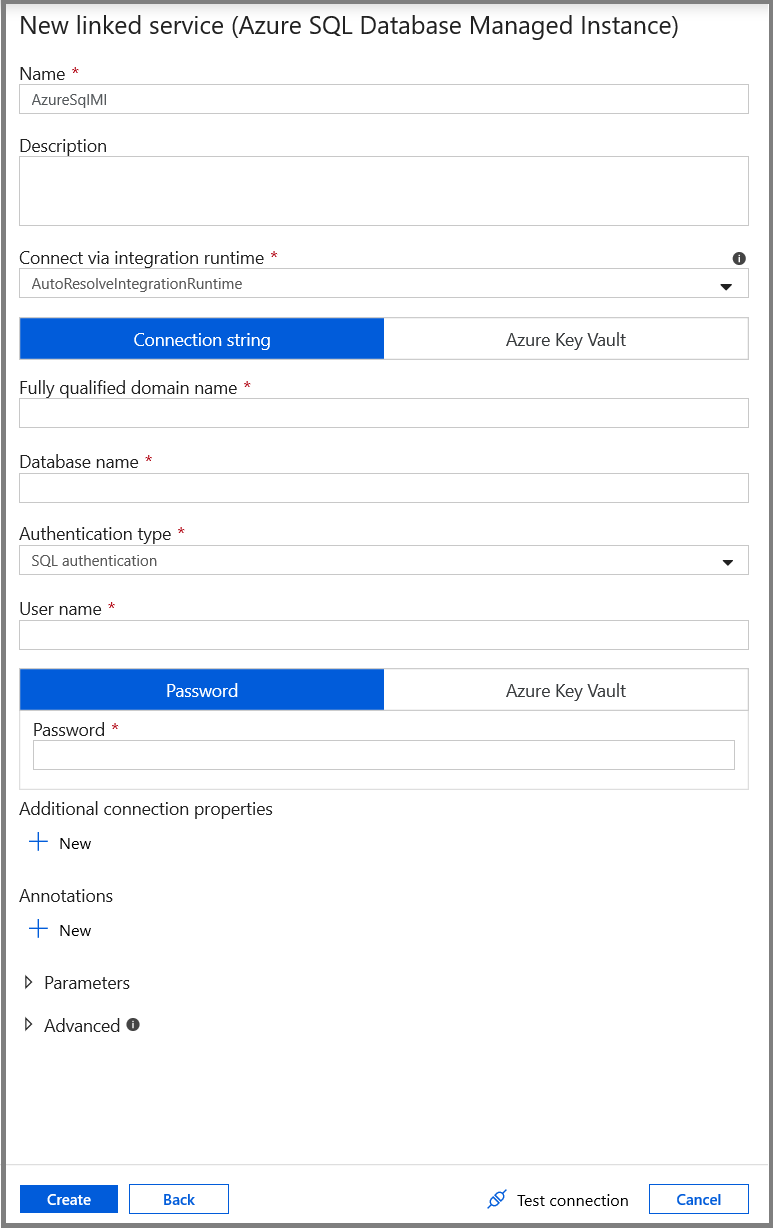
Na janela Novo Serviço Vinculado, selecione Instância Gerenciada do Banco de Dados SQL do Azure e clique em Continuar.
Na janela Novo Serviço Vinculado, execute estas etapas:
- Insira AzureSqlMI1 para o campo Nome.
- Selecione o SQL Server no campo Nome do servidor.
- Selecione o banco de dados SQL no campo Nome do banco de dados.
- Insira o nome do usuário no campo Nome de usuário.
- Insira a senha do usuário no campo Senha.
- Clique em Testar conectividade para testar a conexão.
- Clique em Salvar para salvar o serviço vinculado.
Criar conjuntos de dados
Nesta etapa, você criará conjuntos de dados para representar a fonte de dados e o destino dos dados.
Criar um conjunto de dados para representar dados de origem
Nesta etapa, você cria conjuntos de dados para representar os dados de origem.
No modo de exibição de árvore, clique em + (adição) e clique em Conjunto de dados.
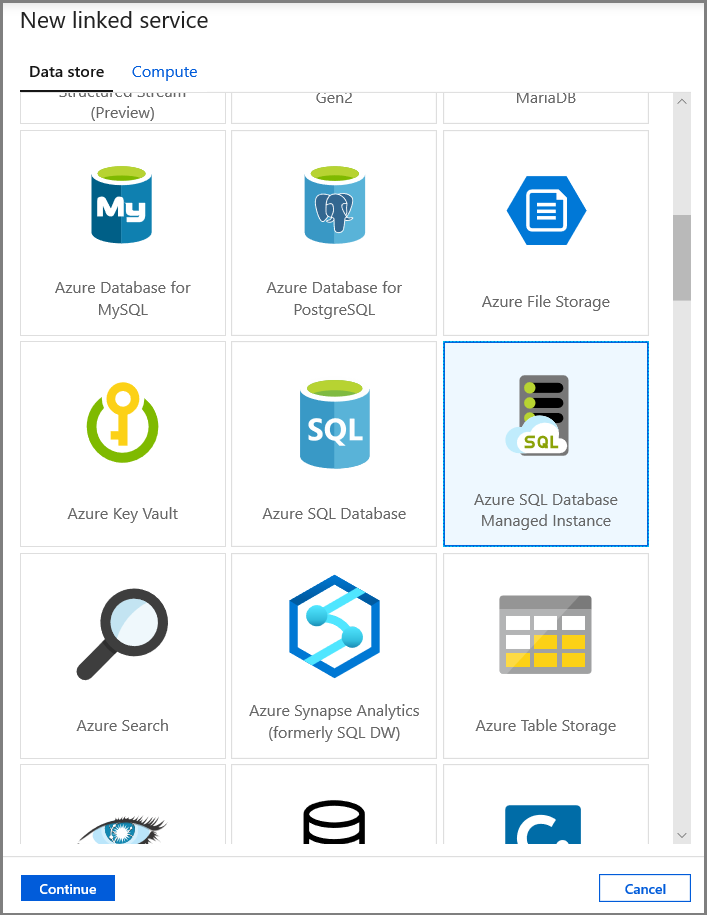
Selecione Instância Gerenciada do Banco de Dados SQL do Azure e clique em Continuar.
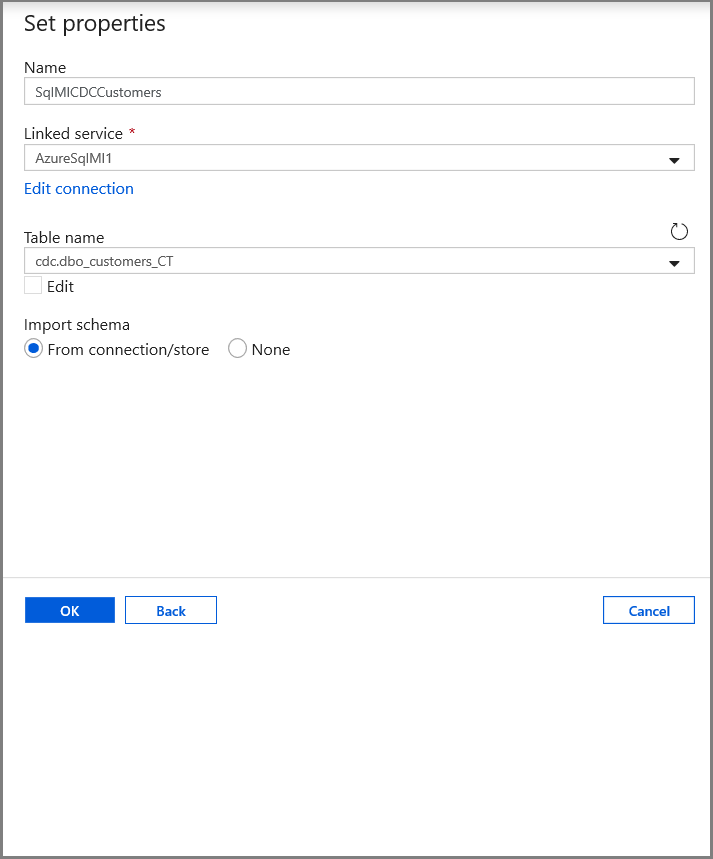
Na guia Definir propriedades, defina o nome do conjunto de dados e as informações de conexão:
- Selecione AzureSqlMI1 para Serviço vinculado.
- Selecione [dbo].[dbo_customers_CT] para Nome da tabela. Observação: essa tabela foi criada automaticamente quando o CDA foi habilitado na tabela clientes. Os dados alterados nunca são consultados dessa tabela diretamente, mas, em vez disso, são extraídos por meio das funções de CDA.
Criar um conjunto de dados para representar dados copiados para o armazenamento de dados do coletor.
Nesta etapa, você cria um conjunto de dados para representar os dados copiados do armazenamento de dados de origem. Você cria o contêiner de data lake em seu Armazenamento de Blobs do Azure como parte dos pré-requisitos. Crie o contêiner caso ele não exista ou defina-o para o nome de um contêiner existente. Neste tutorial, o nome do arquivo de saída é gerado dinamicamente usando o tempo de disparo, que será configurado posteriormente.
No modo de exibição de árvore, clique em + (adição) e clique em Conjunto de dados.
Selecione Armazenamento de Blobs do Azure e clique em Continuar.

Selecione DelimitedText e clique em Continuar.

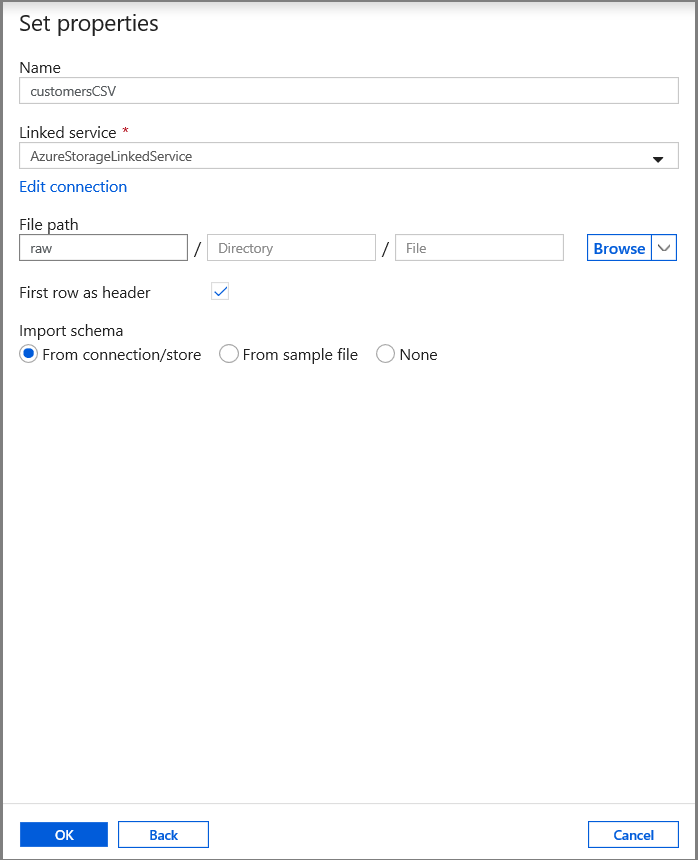
Na guia Definir Propriedades, defina o nome do conjunto de dados e as informações de conexão:
- Selecione AzureStorageLinkedService para Serviço vinculado.
- Insira raw para a parte contêiner do filePath.
- Habilitar Usar primeira linha como cabeçalho
- Clique em Ok
Criar um pipeline para copiar os dados alterados
Nesta etapa, você cria um pipeline, que primeiro verifica o número de registros alterados presentes na tabela de alteração usando uma atividade de pesquisa. Uma atividade IF Condition verifica se o número de registros alterados é maior que zero e executa uma atividade de cópia para copiar os dados inseridos/atualizados/excluídos do Banco de Dados SQL do Azure para o Armazenamento de Blobs do Azure. Por fim, um gatilho de janela em cascata é configurado e os horários de início e término serão passados para as atividades como os parâmetros de janela inicial e final.
Na interface de usuário do Data Factory, alterne para a guia Editar. Clique em + (adição) no painel esquerdo e clique em Pipeline.
Você verá uma nova guia para configuração do pipeline. Você também verá o pipeline no modo de exibição de árvore. Na janela Propriedades, altere o nome do pipeline para IncrementalCopyPipeline.
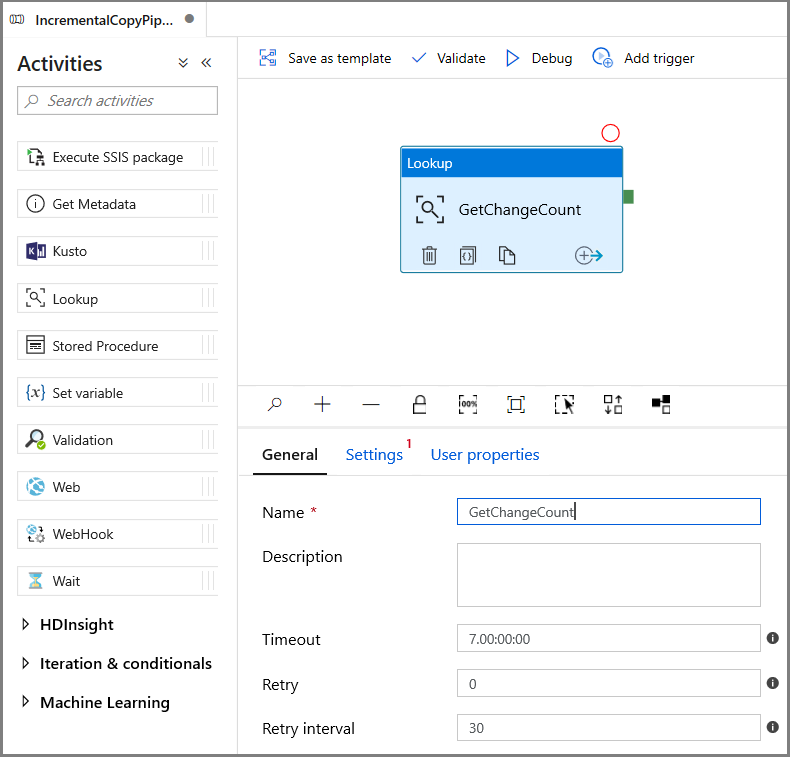
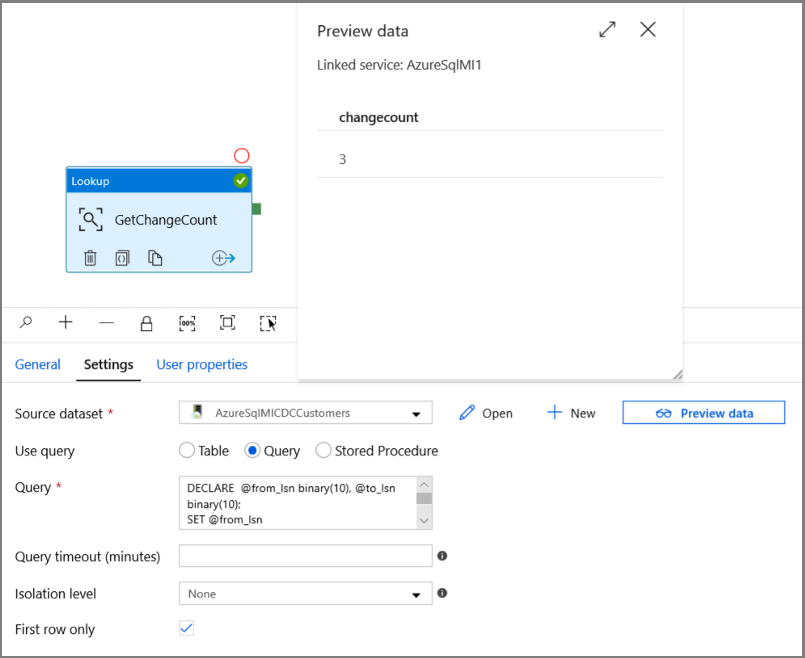
Expanda Geral na caixa de ferramentas Atividades e arraste e solte a atividade de Pesquisa para a superfície do designer de pipeline. Defina o nome da atividade como GetChangeCount. Essa atividade obtém o número de registros na tabela de alteração de uma determinada janela de tempo.
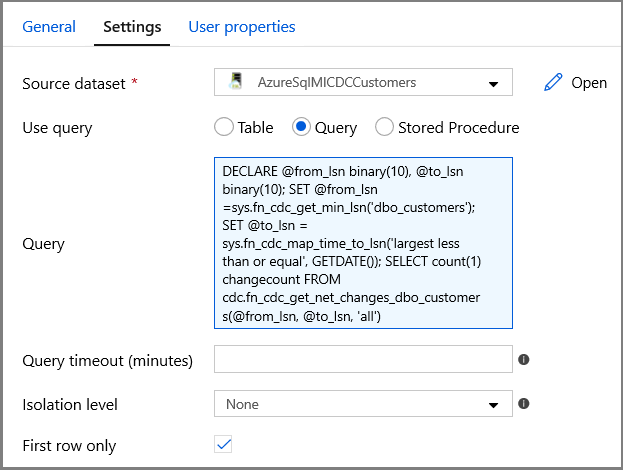
Alterne para a guia Configurações na janela Propriedades:
Especifique o nome do conjunto de dados de MI do SQL para o campo Conjunto de Dados de Origem.
Selecione a opção de consulta e insira o seguinte na caixa de consulta:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Habilitar Primeira linha somente
Clique no botão Visualizar dados para garantir que uma saída válida seja obtida pela atividade de pesquisa
Expanda Iteração e condicionais na caixa de ferramenta Atividades e arraste e solte a atividade If Condition para a superfície de designer do pipeline. Defina o nome da atividade como HasChangedRows.
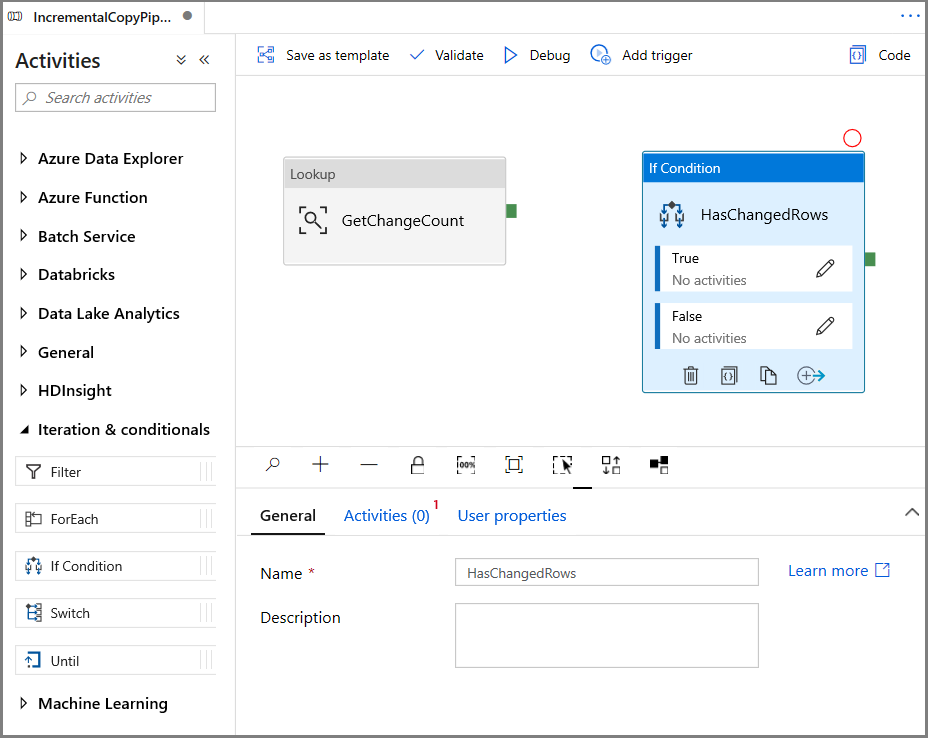
Alterne para a Atividades na janela Propriedades:
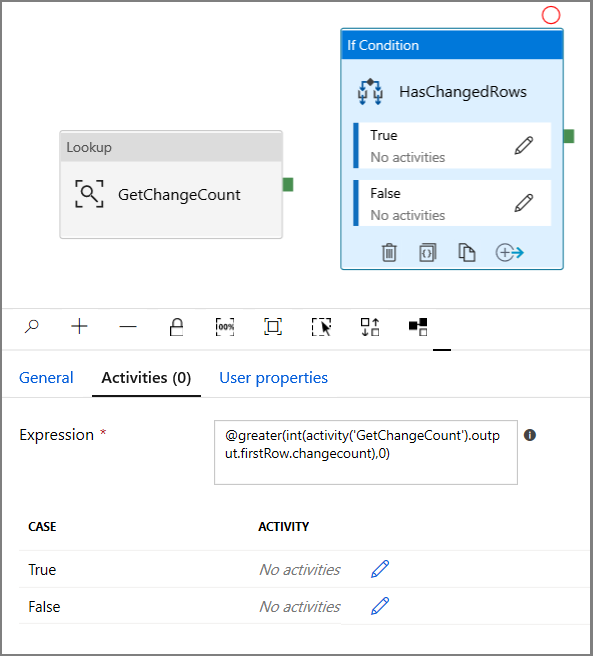
- Insira a Expressão a seguir
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Clique no ícone de lápis para editar a condição True.
- Expanda Geral na caixa de ferramentas Atividades e arraste e solte uma atividade Wait para a superfície do designer do pipeline. Essa é uma atividade temporária para depurar a If Condition e será alterada posteriormente no tutorial.
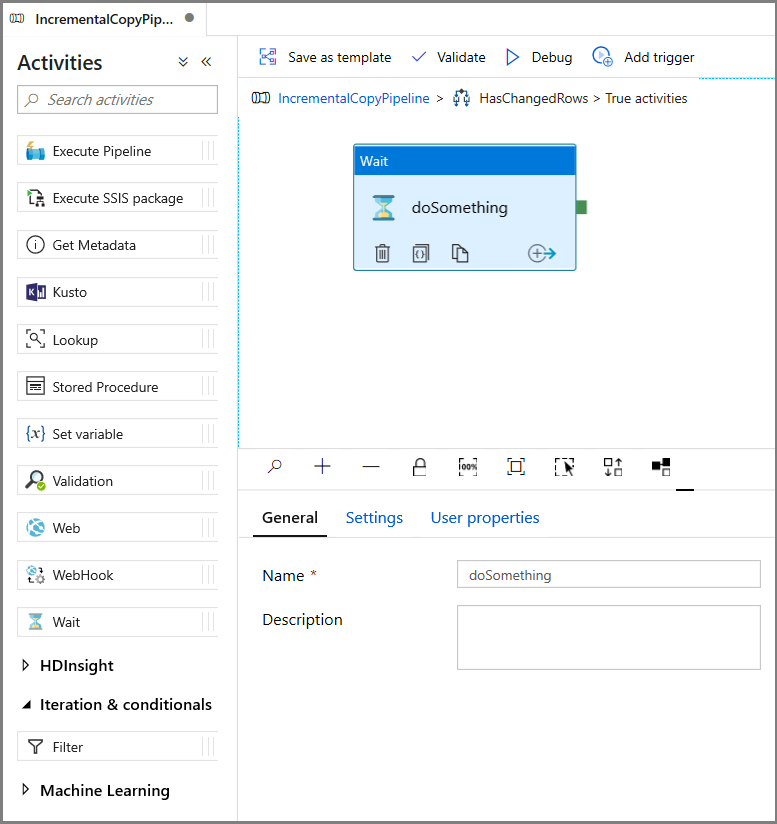
- Clique na trilha IncrementalCopyPipeline para voltar ao pipeline principal.
Execute o pipeline no modo Depuração para verificar se o pipeline é executado com êxito.
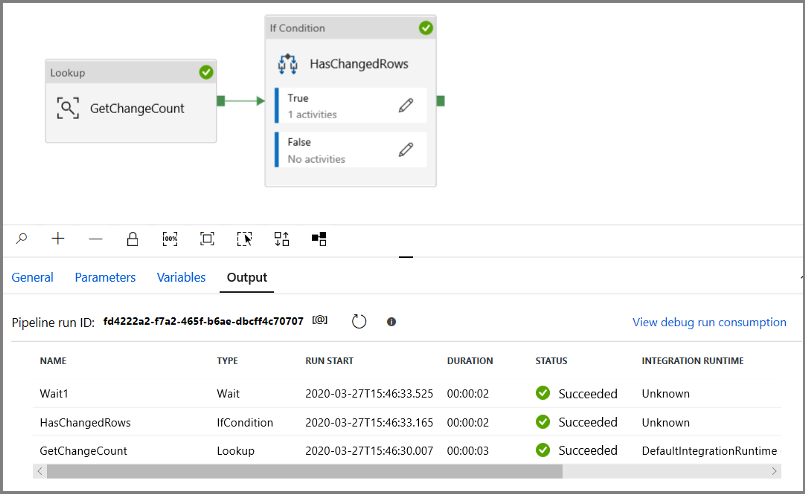
Em seguida, retorne à etapa da condição True e exclua a atividade Esperar. Na caixa de ferramentas Atividades, expanda Mover e Transformar e arraste e solte a atividade Copy para a superfície do designer de pipeline. Defina o nome da atividade como IncrementalCopyActivity.
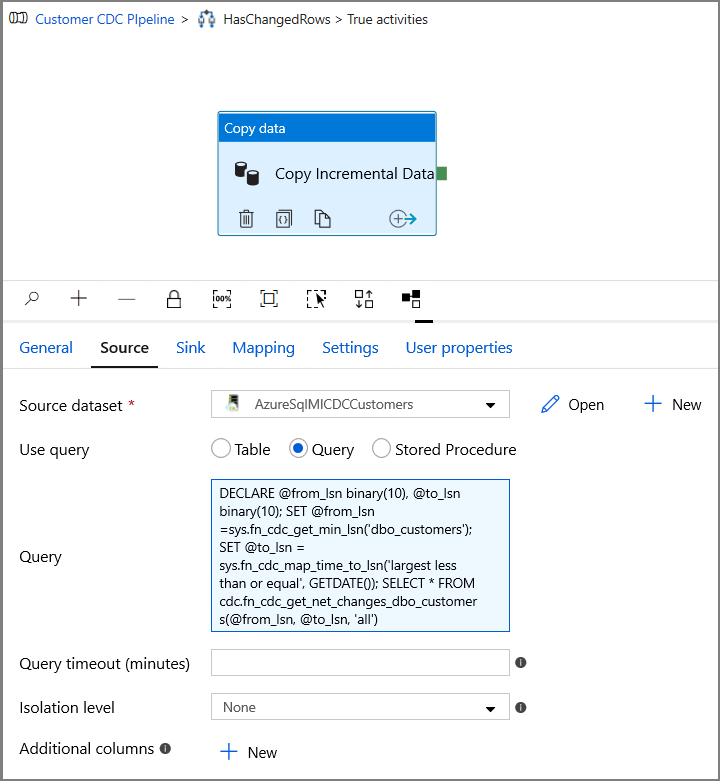
Alterne para a guia Fonte na janela Propriedades e execute as seguintes etapas:
Especifique o nome do conjunto de dados de MI do SQL para o campo Conjunto de Dados de Origem.
Selecione Consulta para Usar consulta.
Insira o seguinte para Consulta.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
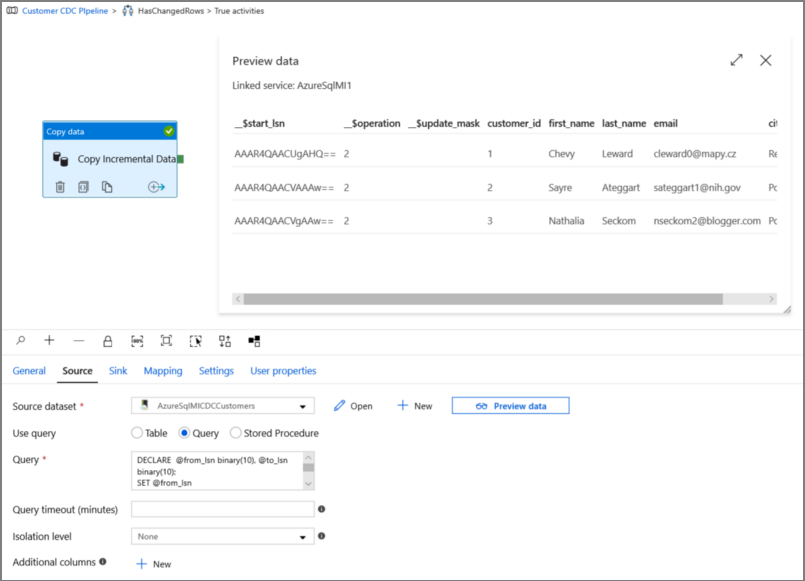
Clique em visualizar para verificar se a consulta retorna as linhas alteradas corretamente.
Alterne para a guia Coletor e especifique o conjunto de dados de Armazenamento do Azure para o campo Conjunto de Dados do Coletor.

Clique em voltar à tela do pipeline principal e conecte a atividade de Procurar à atividade If Condition uma a uma. Arraste o botão verde anexado à atividade de Pesquisa para a atividade de If Condition.
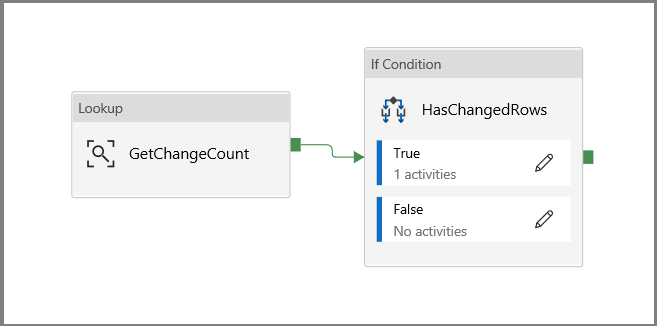
Clique em Validar na barra de ferramentas. Confirme se não houver nenhum erro de validação. Feche a janela Relatório de validação do pipeline clicando em >>.
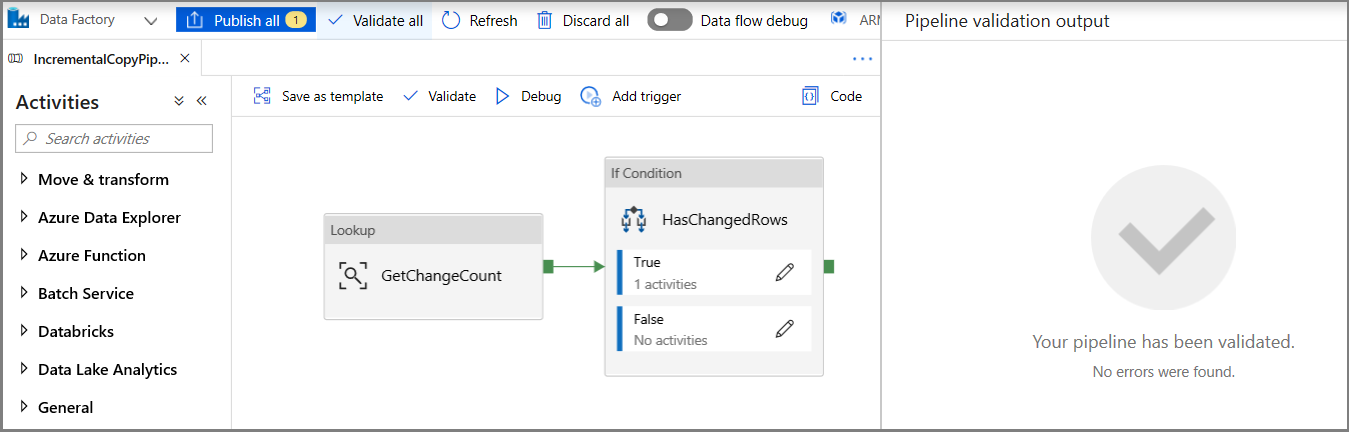
Clique em Depurar para testar o pipeline e verificar se um arquivo é gerado no local de armazenamento.
Publique as entidades (serviços vinculados, conjuntos de dados e pipelines) para o serviço de Data Factory clicando no botão Publicar tudo. Aguarde até que você veja a mensagem Publicado com êxito.
Configurar o gatilho da janela em cascata e os parâmetros da janela do CDA
Nesta etapa, você cria um gatilho de janela em cascata para executar o trabalho conforme um agendamento frequente. Você usará as variáveis de sistema WindowStart e WindowEnd do gatilho de janela em cascata e as passará como parâmetros para o pipeline a ser usado na consulta do CDA.
Navegue até a guia Parâmetros do pipeline IncrementalCopyPipeline e, usando o botão + Novo, adicione dois parâmetros (triggerStartTime e triggerEndTime) ao pipeline, que representarão a hora de início e de término da janela em cascata. Para depuração, adicione valores padrão no formato YYYY-MM-DD HH24:MI:SS.FFF, verificando se triggerStartTime não é anterior ao CDA que está sendo habilitado na tabela. Caso contrário, isso resultará em um erro.
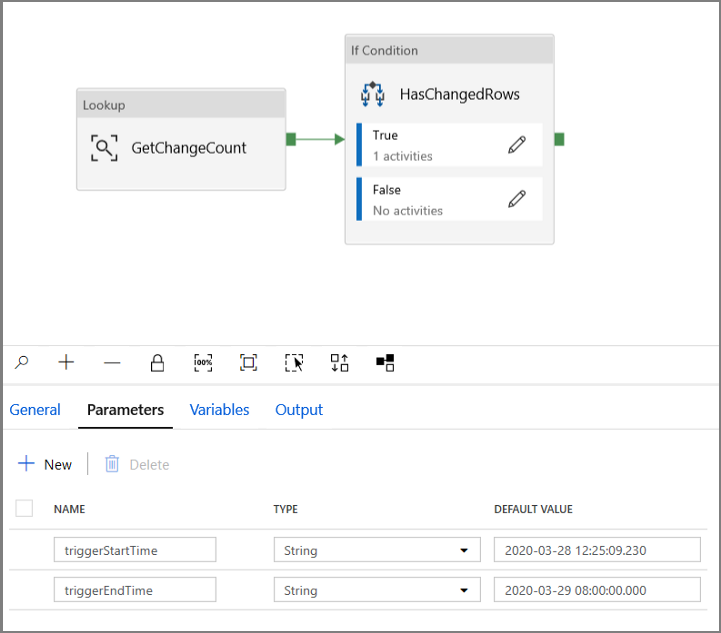
Clique na guia configurações da atividade Procurar e configure a consulta para usar os parâmetros de início e término. Copie o seguinte para a consulta:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Navegue até a atividade Copiar no caso True da atividade If Condition e clique na guia Origem. Copie o seguinte para a consulta:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Clique na guia Coletor da atividade Copiar e clique em Abrir para editar as propriedades do conjunto de dados. Clique na guia Parâmetros e adicione um novo parâmetro chamado triggerStart
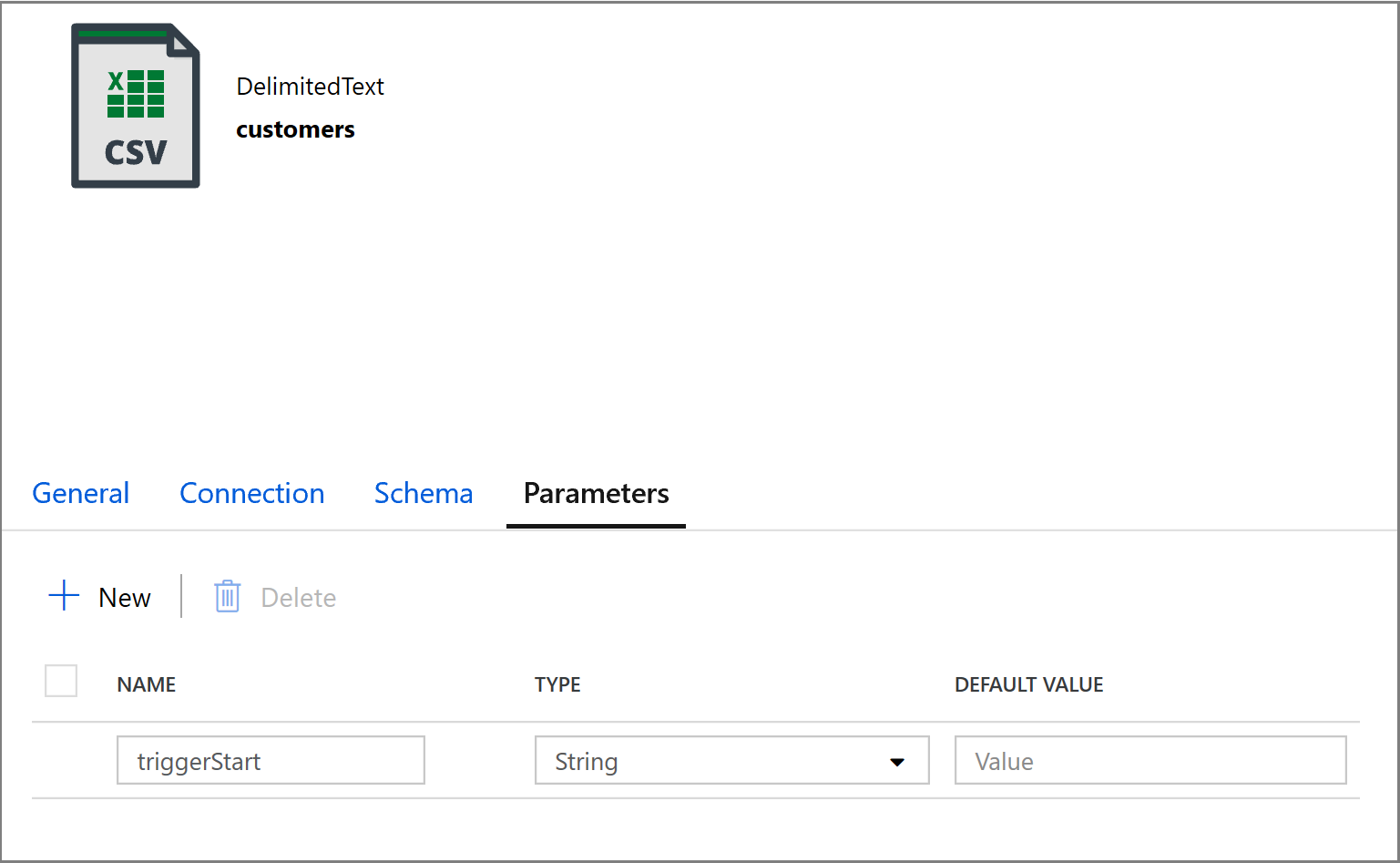
Em seguida, configure as propriedades do conjunto de dados para armazená-lo em um subdiretório clientes/incremental com partições baseadas em data.
Clique na guia Conexão das propriedades do conjunto de dados e adicione conteúdo dinâmico às seções Diretório e Arquivo.
Insira a expressão a seguir na seção Diretório clicando no link de conteúdo dinâmico na caixa de texto:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Insira a expressão a seguir na seção Arquivo. Isso criará nomes de arquivo com base na data e hora de início do gatilho, com o sufixo da extensão CSV:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')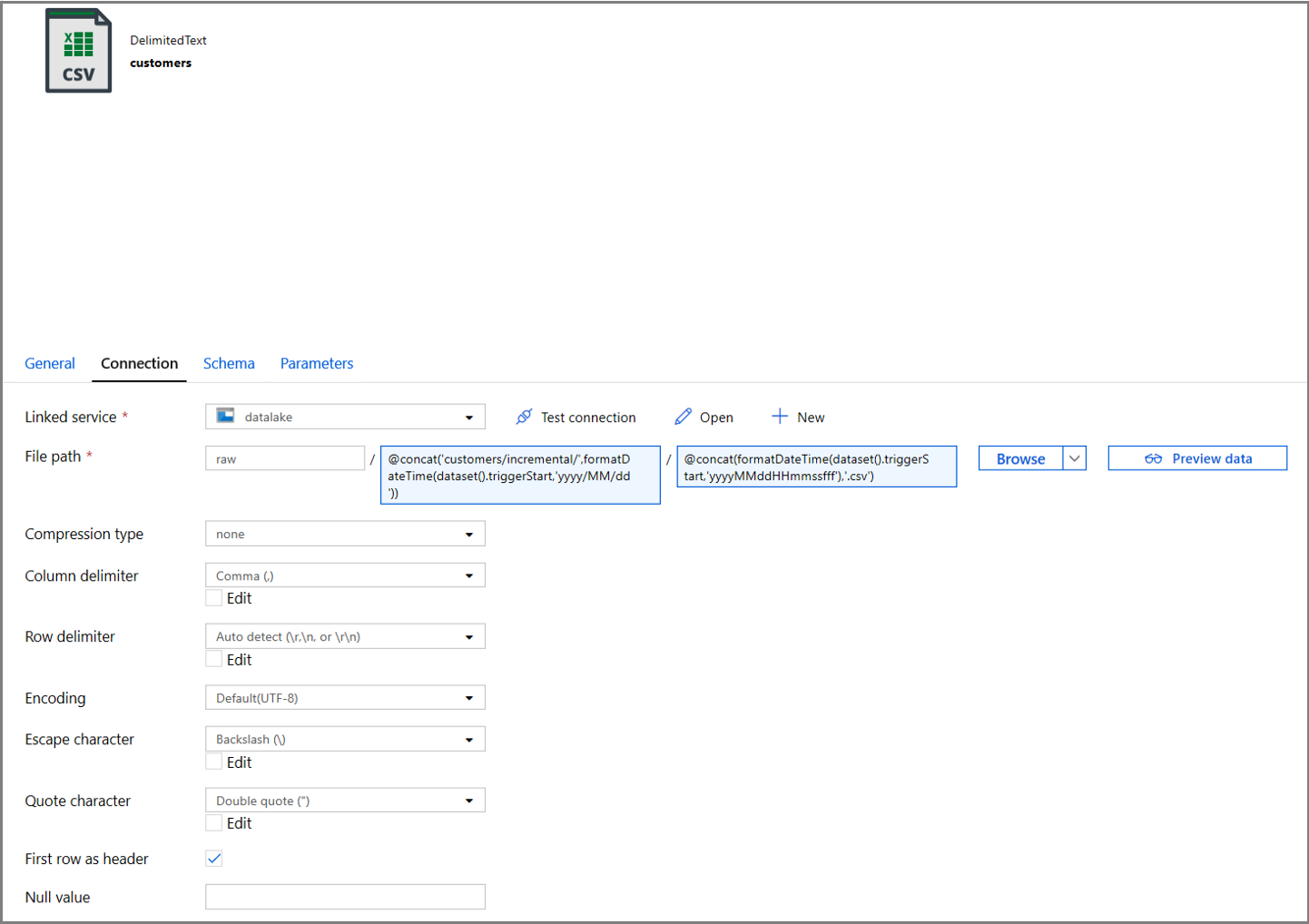
Navegue de volta para as configurações do Coletor na atividade Copiar clicando na guia IncrementalCopyPipeline.
Expanda as propriedades do conjunto de dados e insira o conteúdo dinâmico no valor do parâmetro triggerStart com a seguinte expressão:
@pipeline().parameters.triggerStartTime
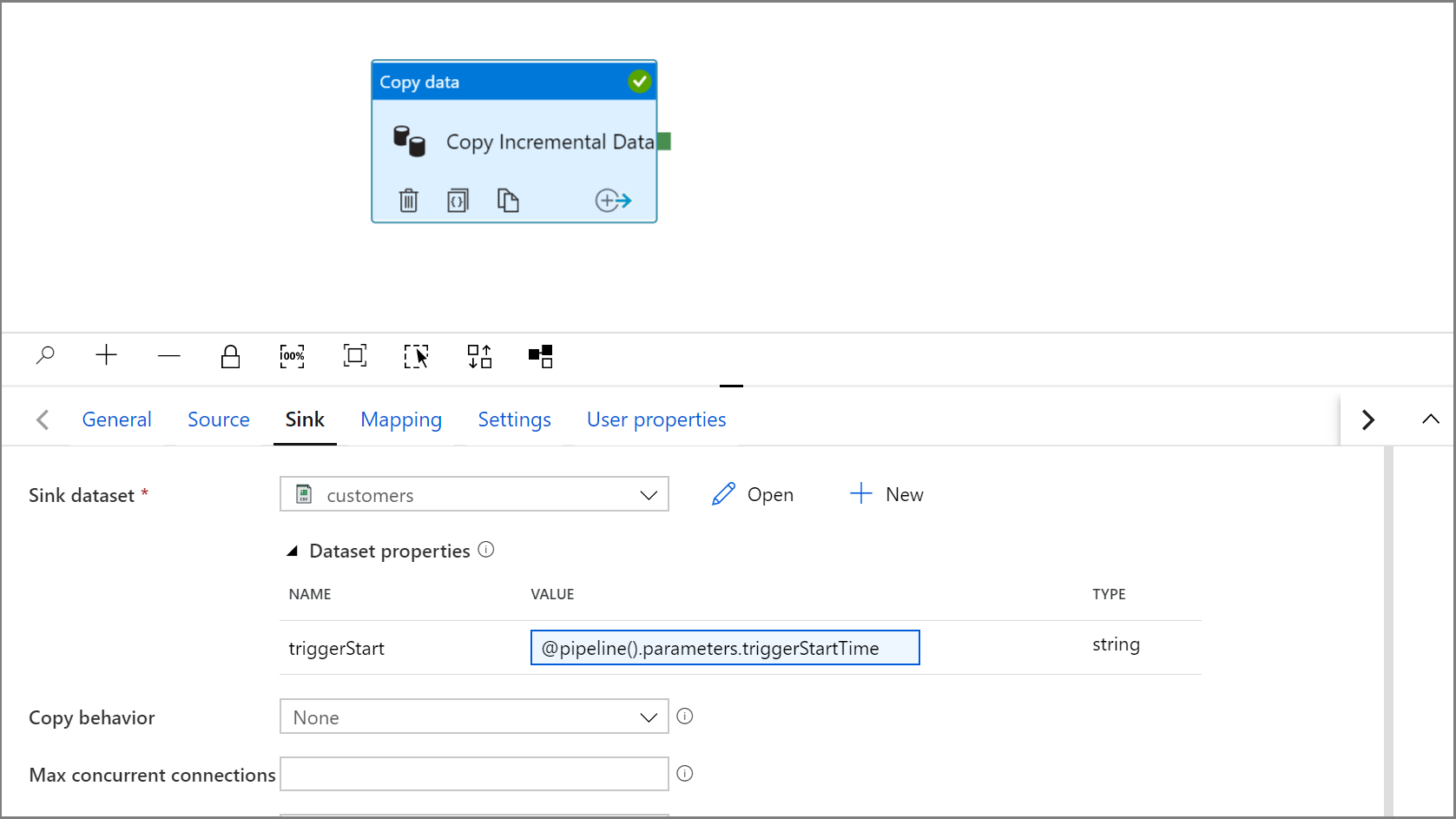
Clique em Depurar para testar o pipeline e garantir que a estrutura de pastas e o arquivo de saída sejam gerados conforme o esperado. Baixe e abra o arquivo para verificar o conteúdo.
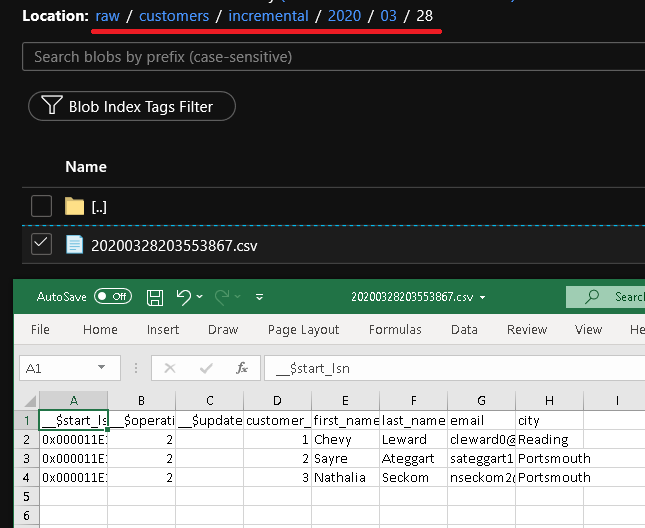
Verifique se os parâmetros estão sendo injetados na consulta examinando os parâmetros de entrada da execução do pipeline.
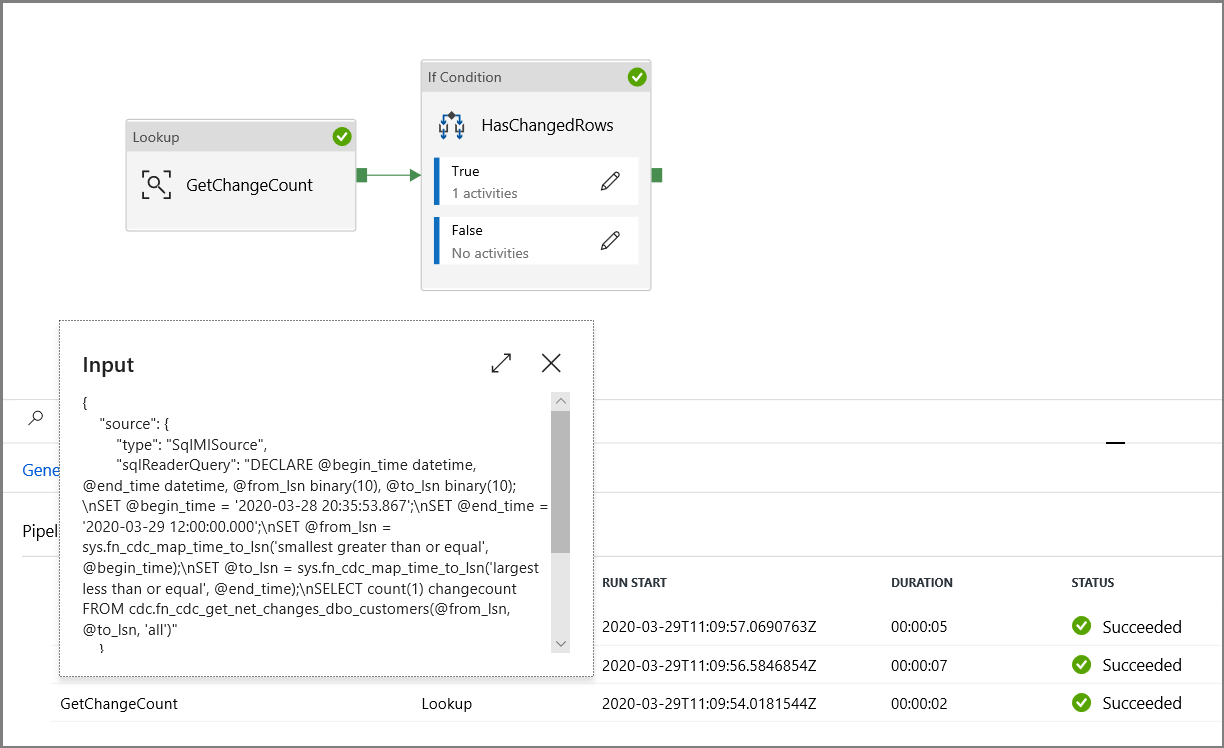
Publique as entidades (serviços vinculados, conjuntos de dados e pipelines) para o serviço de Data Factory clicando no botão Publicar tudo. Aguarde até que você veja a mensagem Publicado com êxito.
Por fim, configure um gatilho de janela em cascata para executar o pipeline a intervalos regulares e definir os parâmetros de hora de início e término.
- Clique no botão Adicionar gatilho e selecione Novo/Editar
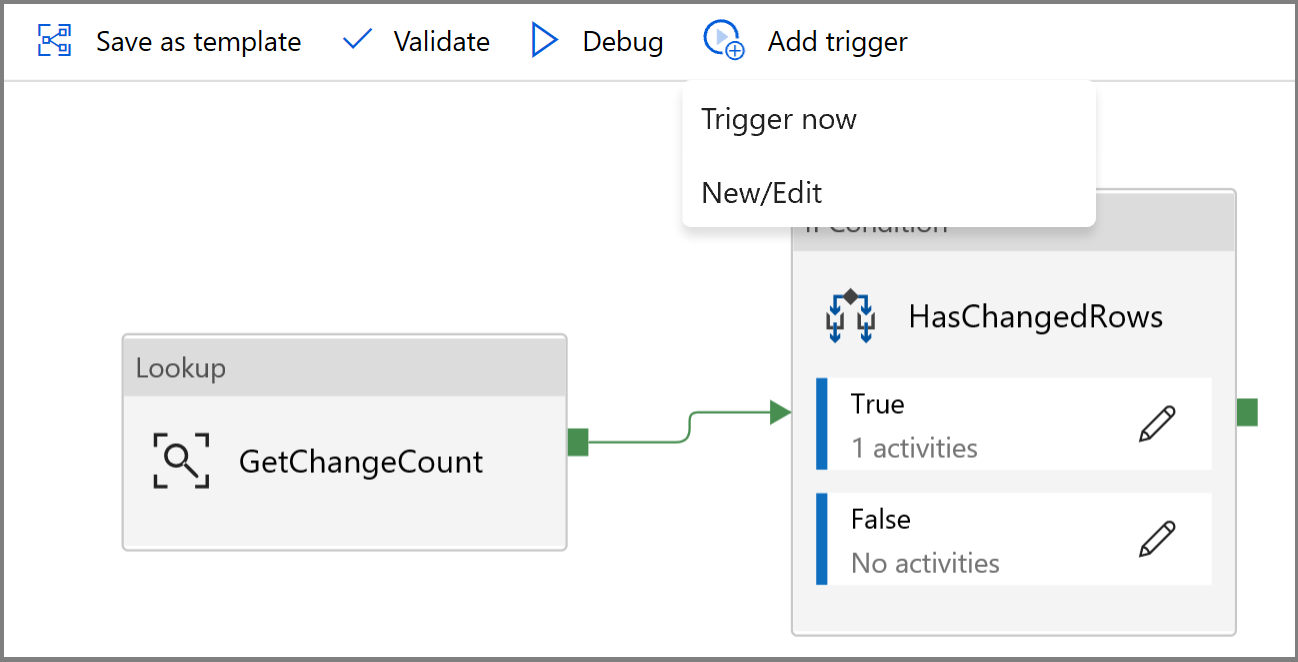
- Insira um nome de gatilho e especifique uma hora de início, que é igual à hora de término da janela de depuração acima.
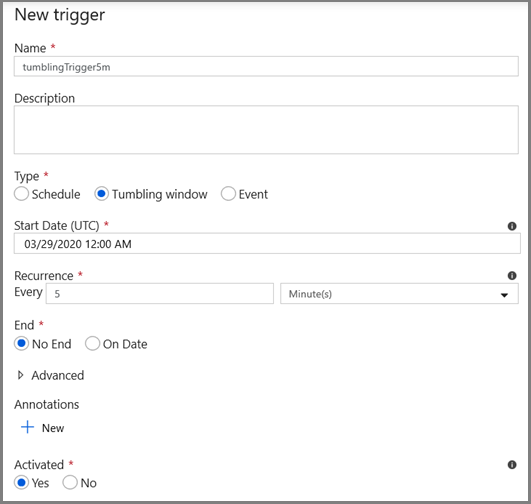
Na próxima tela, especifique os valores a seguir para os parâmetros de início e término, respectivamente.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')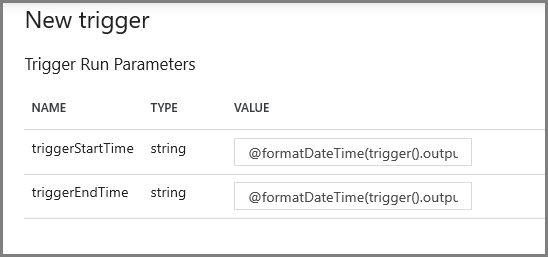
Observação
O gatilho só será executado depois que tiver sido publicado. Além disso, o comportamento esperado da janela em cascata é executar todos os intervalos históricos da data de início até agora. Mais informações sobre os gatilhos de janela em cascata podem ser encontradas aqui.
Usando o SQL Server Management Studio, faça algumas alterações adicionais à tabela cliente executando o seguinte SQL:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Clique no botão Publicar tudo. Aguarde até que você veja a mensagem Publicado com êxito.
Depois de alguns minutos, o pipeline será disparado e um novo arquivo será carregado no Armazenamento do Azure
Monitorar o pipeline de cópia incremental
Clique na guia Monitorar à esquerda. Você verá a execução do pipeline na lista e o seu respectivo status. Para atualizar a lista, clique em Atualizar. Passe o mouse perto do nome do pipeline para acessar a ação executar novamente e o relatório de consumo.
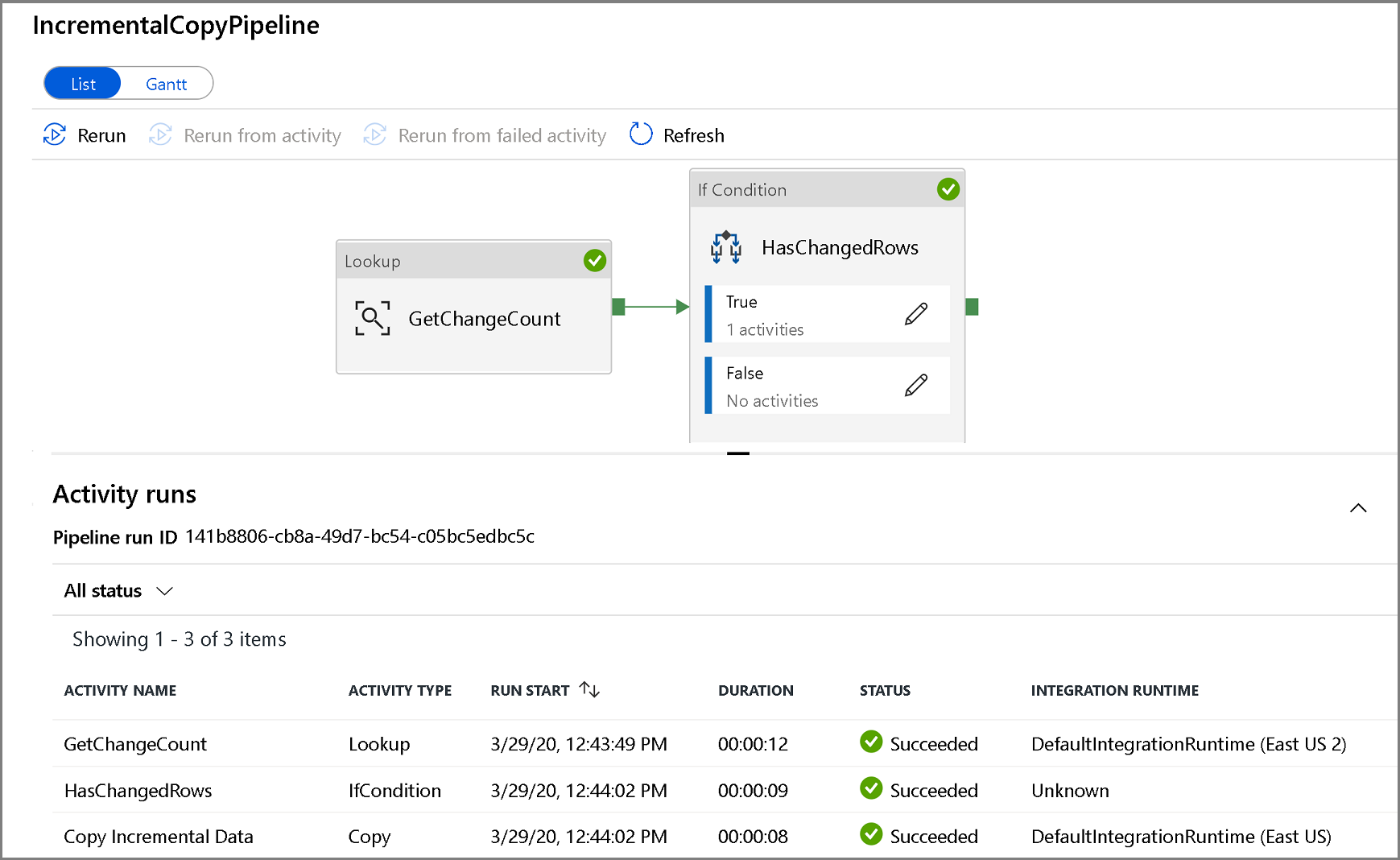
Para exibir as execuções de atividade associadas à execução do pipeline, clique no nome do pipeline. Se forem detectados dados alterados, haverá três atividades, incluindo a atividade de cópia; caso contrário, haverá apenas duas entradas na lista. Para alternar novamente para a exibição de execuções de pipeline, clique no link Todos os Pipelines na parte superior.
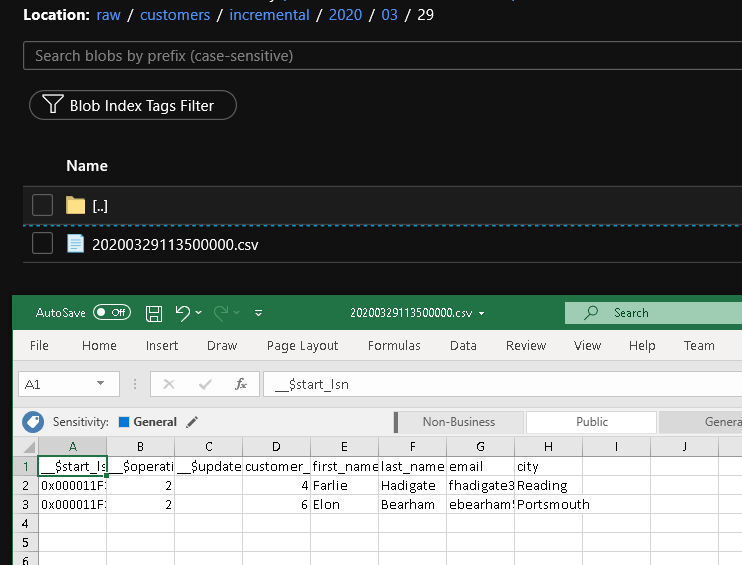
Revise os resultados
Você verá o segundo arquivo na pasta customers/incremental/YYYY/MM/DD do contêiner raw.
Conteúdo relacionado
Avance para o tutorial seguinte para saber mais sobre como copiar arquivos novos e alterados somente com base na LastModifiedDate: