Processar dados executando U-SQL scripts em Azure Data Lake Analytics com Azure Data Factory e Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Um pipeline no espaço de trabalho do Azure Data Factory ou Synapse Analytics processa dados nos serviços de armazenamento vinculados utilizando serviços de computação vinculados. Ela contém uma sequência de atividades em que cada atividade executa uma operação de processamento específica. Este artigo descreve a Atividade do U-SQL do Data Lake Analytics que executa um script U-SQL em um serviço vinculado de computação do Azure Data Lake Analytics.
Crie uma conta do Azure Data Lake Analytics antes de criar um pipeline com uma atividade do U-SQL do Data Lake Analytics. Para saber mais sobre o Azure Data Lake Analytics, veja Introdução ao Azure Data Lake Analytics.
Adicionar uma atividade U-SQL do Azure Data Lake Analytics a um pipeline com interface do usuário
Para usar uma atividade U-SQL do Azure Data Lake Analytics em um pipeline, conclua as seguintes etapas:
Procure Data Lake no painel Atividades do pipeline e arraste uma atividade U-SQL para a tela do pipeline.
Selecione a nova atividade U-SQL na tela se ela ainda não estiver selecionada.
Selecione a guia Conta ADLA para selecionar ou criar um serviço vinculado do Azure Data Lake Analytics que será usado para executar a atividade U-SQL.
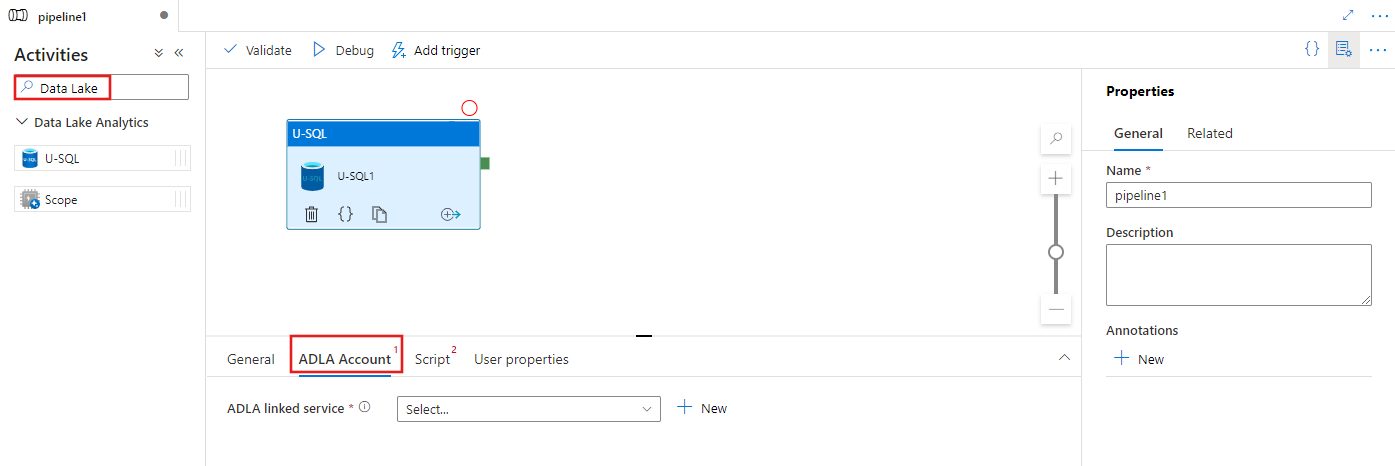
Selecione a guia Script para selecionar ou criar um serviço vinculado de armazenamento e um caminho dentro do local de armazenamento que hospedará o script.
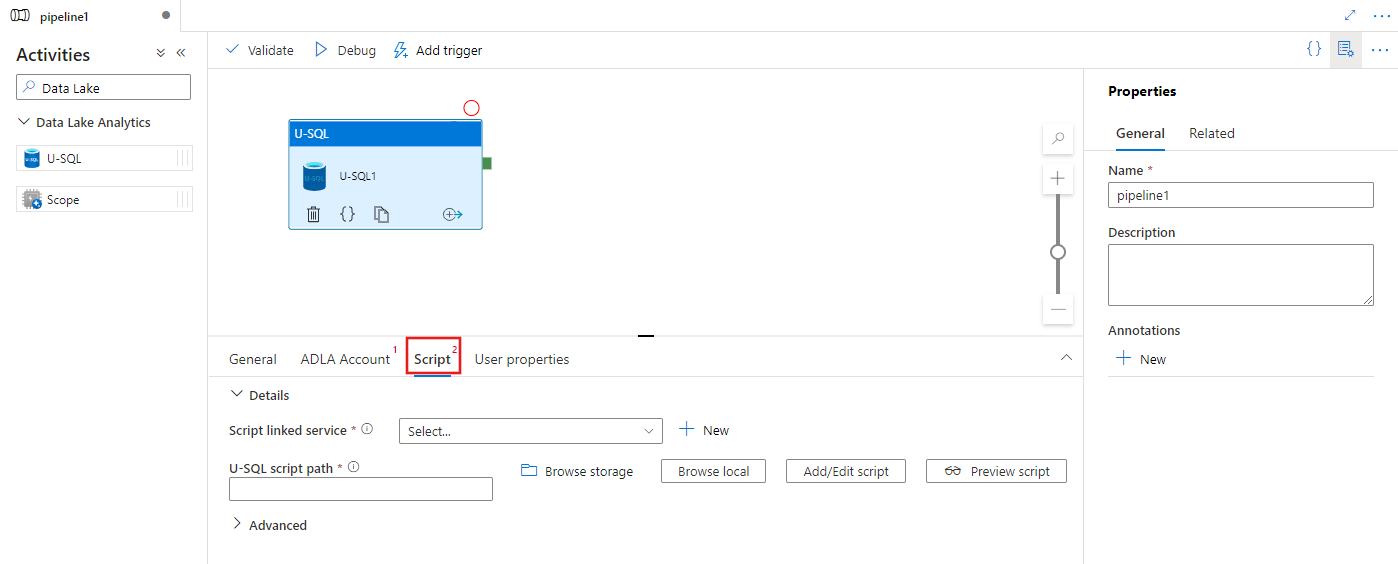
Serviço vinculado do Azure Data Lake Analytics
Você cria um serviço vinculado do Azure Data Lake Analytics para vincular um serviço de computação do Azure Data Lake Analytics a um espeço de trabalho do Azure Data Factory ou Synapse Analytics. A atividade de U-SQL do Data Lake Analytics no pipeline se refere a esse serviço vinculado.
A tabela a seguir apresenta as descrições das propriedades genéricas usadas na definição JSON.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade de tipo deve ser configurada como: AzureDataLakeAnalytics. | Sim |
| accountName | Nome da conta da Análise Azure Data Lake. | Sim |
| dataLakeAnalyticsUri | URI da Análise Azure Data Lake. | Não |
| subscriptionId | ID de assinatura do Azure | Não |
| resourceGroupName | Nome do grupo de recursos do Azure | Não |
Autenticação de entidade de serviço
O serviço vinculado do Azure Data Lake Analytics requer uma autenticação de entidade de serviço para conectar-se ao serviço do Azure Data Lake Analytics. Para usar a autenticação da entidade de serviço, registre uma entidade de aplicativo no Microsoft Entra ID e conceda acesso ao Data Lake Analytics e ao Data Lake Store que ele usa. Para encontrar as etapas detalhadas, consulte Autenticação de serviço a serviço. Anote os seguintes valores, que são usados para definir o serviço vinculado:
- ID do aplicativo
- Chave do aplicativo
- ID do locatário
Conceder permissão de entidade de serviço para o seu Azure Data Lake Anatlyics usando o Assistente de Adição de Usuário.
Use a autenticação de entidade de serviço especificando as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| servicePrincipalId | Especifique a ID do cliente do aplicativo. | Sim |
| servicePrincipalKey | Especifique a chave do aplicativo. | Sim |
| tenant | Especifique as informações de locatário (domínio nome ou ID do Locatário) em que o aplicativo reside. É possível recuperá-las focalizando o mouse no canto superior direito do Portal do Azure. | Sim |
Exemplo: Autenticação de entidade de serviço
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Para saber mais sobre o serviço vinculado, consulte Compute linked services (Serviços de computação vinculados).
Atividade do U-SQL da Análise Data Lake
O seguinte snippet de código JSON define um pipeline com uma Atividade do U-SQL da Análise Data Lake. A definição de atividade tem uma referência para o serviço vinculado da Análise Azure Data Lake criado anteriormente. Para executar um script U-SQL do Data Lake Analytics, o serviço envia o script especificado ao Data Lake Analytics e as entradas e saídas necessárias são definidas no script do Data Lake Analytics para efetuar fetch e emitir a saída.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
A tabela a seguir descreve os nomes e as descrições de propriedades que são específicas a esta atividade.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| name | Nome da atividade no pipeline | Sim |
| descrição | Texto que descreve o que a atividade faz. | Não |
| type | Para a atividade de U-SQL do Data Lake Analytics, o tipo de atividade é DataLakeAnalyticsU-SQL. | Sim |
| linkedServiceName | Serviço vinculado ao Azure Data Lake Analytics. Para saber mais sobre esse serviço vinculado, consulte o artigo Compute linked services (Serviços de computação vinculados). | Sim |
| scriptPath | Caminho para a pasta que contém o script U-SQL. O nome do arquivo diferencia maiúsculas de minúsculas. | Sim |
| scriptLinkedService | Serviço vinculado que vincula o Azure Data Lake Store ou Armazenamento do Azure que contém o script | Sim |
| degreeOfParallelism | O número máximo de nós usados simultaneamente para executar o trabalho. | Não |
| priority | Determina quais trabalhos de todos os que estão na fila devem ser selecionados para serem executados primeiro. Quanto menor o número, maior a prioridade. | Não |
| parâmetros | Parâmetros para passar para o script U-SQL. | Não |
| runtimeVersion | Versão de runtime do mecanismo U-SQL a ser usado. | Não |
| compilationMode | Modo de compilação do U-SQL. Deve ser um destes valores: Semantic: realiza apenas as verificações de semântica e as verificações de integridade necessárias; Full: realiza a compilação completa, incluindo verificação de sintaxe, otimização, geração de código, etc.; SingleBox: executa a compilação completa com a configuração TargetType como SingleBox. Se você não especificar um valor para essa propriedade, o servidor determinará o modo de compilação ideal. |
Não |
Consulte SearchLogProcessing.txt para ver a definição do script.
Exemplo de script U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
No exemplo de script acima, a entrada e a saída do script são definidas nos parâmetros @in e @out. Os valores dos parâmetros @in and @out no script U-SQL são passados dinamicamente pelo serviço usando a seção 'parâmetros'.
Você pode especificar outras propriedades, por exemplo, degreeOfParallelism e prioridade, bem como em sua definição de pipeline para os trabalhos executados no serviço Data Lake Analytics.
Parâmetros dinâmicos
Na definição de pipeline de exemplo, os parâmetros in e out são atribuídos com valores embutidos em código.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
É possível usar parâmetros dinâmicos em vez disso. Por exemplo:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
Nesse caso, os arquivos de entrada ainda são obtidos da pasta /datalake/input e os arquivos de saída são gerados na pasta /datalake/output. Os nomes de arquivo são dinâmicos com base na hora de início de janela que está sendo passada quando o pipeline é disparado.
Conteúdo relacionado
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras:
- Hive activity (Atividade do Hive)
- Pig activity (Atividade do Pig)
- MapReduce activity (Atividade do MapReduce)
- Hadoop Streaming activity (Atividade de streaming do Hadoop)
- Spark activity (Atividade do Spark)
- Atividade personalizada do .NET
- Stored procedure activity (Atividade de procedimento armazenado)