Transformar dados executando uma atividade de Python no Azure Databricks
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
A atividade de Python do Azure Databricks em um pipeline executa um arquivo Python no cluster do Azure Databricks. Este artigo se baseia no artigo sobre atividades de transformação de dados que apresenta uma visão geral da transformação de dados e as atividades de transformação permitidas. O Azure Databricks é uma plataforma gerenciada para executar o Apache Spark.
Para ver uma introdução de 11 minutos e uma demonstração desse recurso, assista ao seguinte vídeo:
Adicionar uma atividade do Python do Azure Databricks a um pipeline com a interface do usuário
Para usar uma atividade do Python do Azure Databricks em um pipeline, realize as seguintes etapas:
Procure Python no painel Atividades do pipeline e arraste uma atividade do Python para a tela do pipeline.
Selecione a nova atividade Python na tela se ela ainda não estiver selecionada.
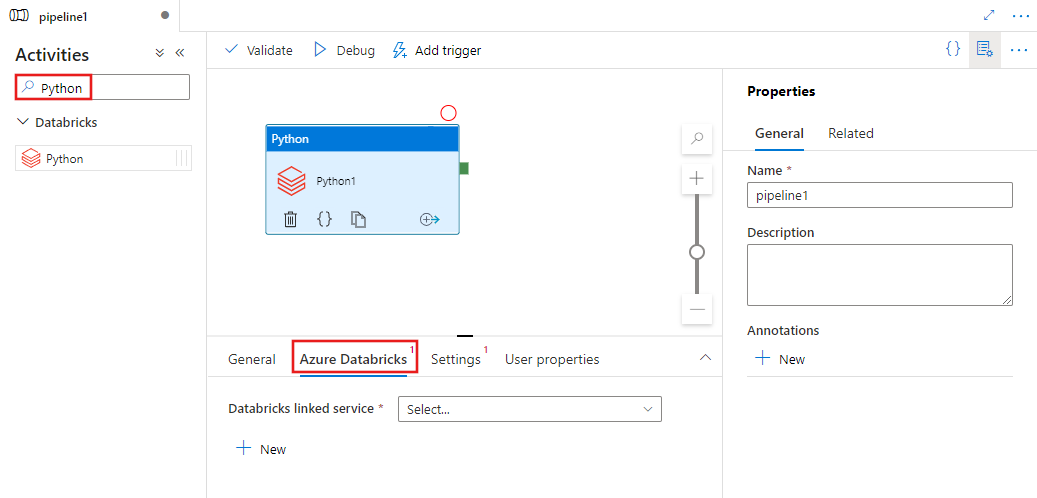
Selecione a guia Azure Databricks para escolher ou criar um serviço vinculado do Azure Databricks que executará a atividade do Python.
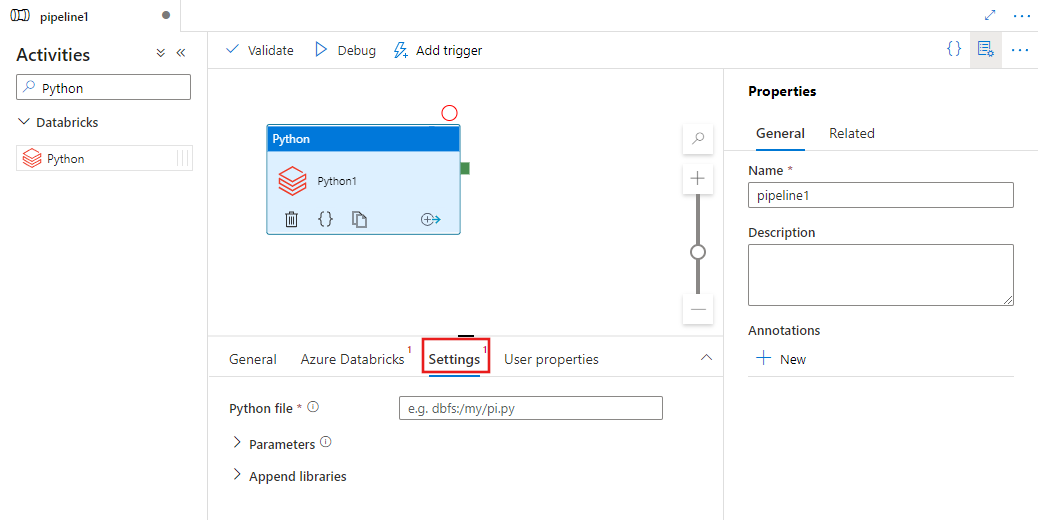
Selecione a guia Configurações e especifique o caminho no Azure Databricks para um arquivo Python a ser executado, os parâmetros opcionais a serem passados e as bibliotecas adicionais a serem instaladas no cluster para executar o trabalho.
Definição de atividade do Databricks Python
A seguir está a definição JSON de exemplo de uma Atividade de Python do Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Propriedades de atividade do Databricks Python
A tabela a seguir descreve as propriedades JSON usadas na definição de JSON:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| name | Nome da atividade no pipeline. | Sim |
| descrição | Texto que descreve o que a atividade faz. | Não |
| type | Para a Atividade Python do Databricks, o tipo de atividade é DatabricksSparkPython. | Sim |
| linkedServiceName | Nome do serviço vinculado ao Databricks no qual a atividade de Python é executado. Para saber mais sobre esse serviço vinculado, consulte o artigo Compute linked services (Serviços de computação vinculados). | Sim |
| pythonFile | O URI do arquivo Python a ser executado. Há suporte para apenas os caminhos DBFS. | Sim |
| parameters | Parâmetros de linha de comando que serão passados para o arquivo Python. Isto é uma matriz de cadeias de caracteres. | Não |
| bibliotecas | Uma lista de bibliotecas a serem instaladas no cluster, que executará o trabalho. Pode ser uma matriz de <cadeia de caracteres, objeto> | Não |
Bibliotecas com suporte para atividades do databricks
Na definição da atividade acima do Databricks você especifica esses tipos de biblioteca: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Para obter mais detalhes, consulte documentação do Databricks para tipos de biblioteca.
Como carregar uma biblioteca no Databricks
Você pode usar a interface do usuário do Workspace:
Para obter o caminho dbfs da biblioteca adicionada usando a interface do usuário, você pode usar a CLI do Databricks.
Normalmente, as bibliotecas Jar são armazenadas em dbfs:/FileStore/jars ao usar a interface do usuário. Você pode listar todos os por meio da CLI: databricks fs ls dbfs:/FileStore/job-jars
Ou você pode usar a CLI do Databricks:
Usar a CLI do Databricks (etapas de instalação)
Por exemplo, para copiar um JAR para dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar