Migrar dados do Amazon S3 para o Azure Data Lake Storage Gen2
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Use os modelos para migrar petabytes de dados que consistem em centenas de milhões de arquivos do Amazon S3 para o Azure Data Lake Storage Gen2.
Observação
Se você quiser copiar pequenos volumes de dados pequenos do AWS S3 para o Azure (por exemplo, menos de 10 TB), será mais eficiente e fácil usar a ferramenta Copiar Dados do Azure Data Factory. O modelo descrito neste artigo é mais do que o necessário.
Sobre os modelos de solução
A partição de dados é recomendada especialmente ao migrar mais de 10 TB de dados. Para particionar os dados, aproveite a configuração de ‘prefixo’ para filtrar as pastas e os arquivos no Amazon S3 por nome e, em seguida, cada trabalho de cópia do ADF pode copiar uma partição de cada vez. Você pode executar vários trabalhos de cópia do ADF simultaneamente para obter uma melhor taxa de transferência.
A migração de dados normalmente exige uma migração de dados históricos única, além de sincronizar periodicamente as alterações do AWS S3 para o Azure. Há dois modelos abaixo, em que um modelo aborda a migração de dados históricos única e outro modelo aborda a sincronização das alterações do AWS S3 para o Azure.
Para o modelo migrar dados históricos do Amazon S3 para Azure Data Lake Storage Gen2
Este modelo (nome do modelo: migrar dados históricos do AWS S3 para o Azure Data Lake Storage Gen2) pressupõe que você gravou uma lista de partições em uma tabela de controle externa no banco de dados SQL do Azure. Portanto, ele usará uma atividade Pesquisa para recuperar a lista de partições da tabela de controle externa, iterar em cada partição e fazer com que cada trabalho de cópia do ADF copie uma partição por vez. Após a conclusão de qualquer trabalho de cópia, o modelo usará a atividade Procedimento armazenado para atualizar o status da cópia de cada partição na tabela de controle.
O modelo contém cinco atividades:
- Pesquisa recupera as partições que não foram copiadas de uma tabela de controle externa para o Azure Data Lake Storage Gen2. O nome da tabela é s3_partition_control_table e a consulta para carregar dados da tabela é "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0" .
- ForEach obtém a lista de partições da atividade Pesquisa e itera cada partição para a atividade TriggerCopy. Você pode definir a batchCount para executar vários trabalhos de cópia do ADF simultaneamente. Definimos como 2 neste modelo.
- ExecutePipeline executa o pipeline CopyFolderPartitionFromS3. O motivo pelo qual criamos outro pipeline para fazer cada trabalho de cópia copiar uma partição é porque ele facilitará a nova execução do trabalho de cópia com falha para recarregar essa partição específica novamente do AWS S3. Todos os outros trabalhos de cópia que carregam outras partições não serão afetados.
- Copy copia cada partição do AWS S3 para o Azure Data Lake Storage Gen2.
- SqlServerStoredProcedure atualiza o status da cópia de cada partição na tabela de controle.
O modelo contém dois parâmetros:
- AWS_S3_bucketName é o nome do bucket no AWS S3 do qual você quer migrar dados. Se você quiser migrar dados de vários buckets no AWS S3, poderá adicionar mais uma coluna em sua tabela de controle externa para armazenar o nome do bucket para cada partição e também atualizar seu pipeline para recuperar dados dessa coluna adequadamente.
- Azure_Storage_fileSystem é o nome do sistema de arquivos no Azure Data Lake Storage Gen2 para o qual você quer migrar dados.
Para o modelo copiar somente arquivos alterados do Amazon S3 para o Azure Data Lake Storage Gen2
Este modelo (nome do modelo: copiar dados delta do AWS S3 para Azure Data Lake Storage Gen2) usa a propriedade LastModifiedTime de cada arquivo para copiar somente os arquivos novos ou atualizados do AWS S3 para o Azure. Lembre-se de que se os arquivos ou pastas já foram particionados com as informações da fração de tempo como parte do nome do arquivo ou da pasta no AWS S3 (por exemplo, /yyyy/mm/dd/file.csv), você pode acessar este tutorial para obter a abordagem mais eficaz para o carregamento incremental de arquivos novos. Este modelo pressupõe que você gravou uma lista de partições em uma tabela de controle externa no Banco de Dados SQL do Azure. Portanto, ele usará uma atividade Pesquisa para recuperar a lista de partições da tabela de controle externa, iterar em cada partição e fazer com que cada trabalho de cópia do ADF copie uma partição por vez. Quando cada trabalho de cópia começa a copiar os arquivos do AWS S3, ele se baseia na propriedade LastModifiedtime para identificar e copiar somente os arquivos novos ou atualizados. Após a conclusão de qualquer trabalho de cópia, o modelo usará a atividade Procedimento armazenado para atualizar o status da cópia de cada partição na tabela de controle.
O modelo contém sete atividades:
- Pesquisa recupera as partições de uma tabela de controle externa. O nome da tabela é s3_partition_delta_control_table e a consulta para carregar dados da tabela é "select distinct PartitionPrefix from s3_partition_delta_control_table" .
- ForEach obtém a lista de partições da atividade Pesquisa e itera cada partição para a atividade TriggerDeltaCopy. Você pode definir a batchCount para executar vários trabalhos de cópia do ADF simultaneamente. Definimos como 2 neste modelo.
- ExecutePipeline executa o pipeline DeltaCopyFolderPartitionFromS3. O motivo pelo qual criamos outro pipeline para fazer cada trabalho de cópia copiar uma partição é porque ele facilitará a nova execução do trabalho de cópia com falha para recarregar essa partição específica novamente do AWS S3. Todos os outros trabalhos de cópia que carregam outras partições não serão afetados.
- Pesquisa recupera o último tempo de execução do trabalho de cópia da tabela de controle externa para que os arquivos novos ou atualizados possam ser identificados por meio da propriedade LastModifiedTime. O nome da tabela é s3_partition_delta_control_table e a consulta para carregar dados da tabela é "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1" .
- Copy copia somente arquivos novos ou alterados para cada partição do AWS S3 para o Azure Data Lake Storage Gen2. A propriedade modifiedDatetimeStart é definida como o tempo de execução do último trabalho de cópia. A propriedade modifiedDatetimeEnd é definida como o tempo de execução do trabalho de cópia atual. Lembre-se de que o horário é aplicado ao fuso horário UTC.
- SqlServerStoredProcedure atualiza o status da cópia de cada partição e o tempo de execução da cópia na tabela de controle quando ela tiver êxito. A coluna de SuccessOrFailure é definida como 1.
- SqlServerStoredProcedure atualiza o status da cópia de cada partição e o tempo de execução da cópia na tabela de controle quando ela falhar. A coluna de SuccessOrFailure é definida como 0.
O modelo contém dois parâmetros:
- AWS_S3_bucketName é o nome do bucket no AWS S3 do qual você quer migrar dados. Se você quiser migrar dados de vários buckets no AWS S3, poderá adicionar mais uma coluna em sua tabela de controle externa para armazenar o nome do bucket para cada partição e também atualizar seu pipeline para recuperar dados dessa coluna adequadamente.
- Azure_Storage_fileSystem é o nome do sistema de arquivos no Azure Data Lake Storage Gen2 para o qual você quer migrar dados.
Como usar estes dois modelos de solução
Para o modelo migrar dados históricos do Amazon S3 para Azure Data Lake Storage Gen2
Criar uma tabela de controle no Banco de Dados SQL do Azure para armazenar a lista de partições do AWS S3.
Observação
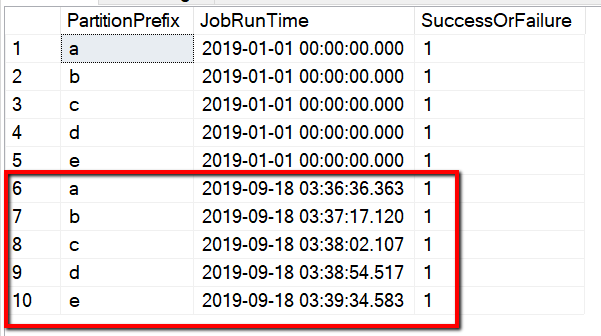
O nome da tabela é s3_partition_control_table. O esquema da tabela de controle é PartitionPrefix e SuccessOrFailure, em que PartitionPrefix é a configuração de prefixo em S3 para filtrar as pastas e os arquivos no Amazon S3 por nome, e SuccessOrFailure é o status da cópia de cada partição: 0 significa que essa partição não foi copiada para o Azure e 1 significa que essa partição foi copiada para o Azure com êxito. Há 5 partições definidas na tabela de controle e o status padrão da cópia de cada partição é 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Crie um procedimento armazenado no mesmo Banco de Dados SQL do Azure para a tabela de controle.
Observação
O nome do procedimento armazenado é sp_update_partition_success. Ele será invocado pela atividade SqlServerStoredProcedure no pipeline do ADF.
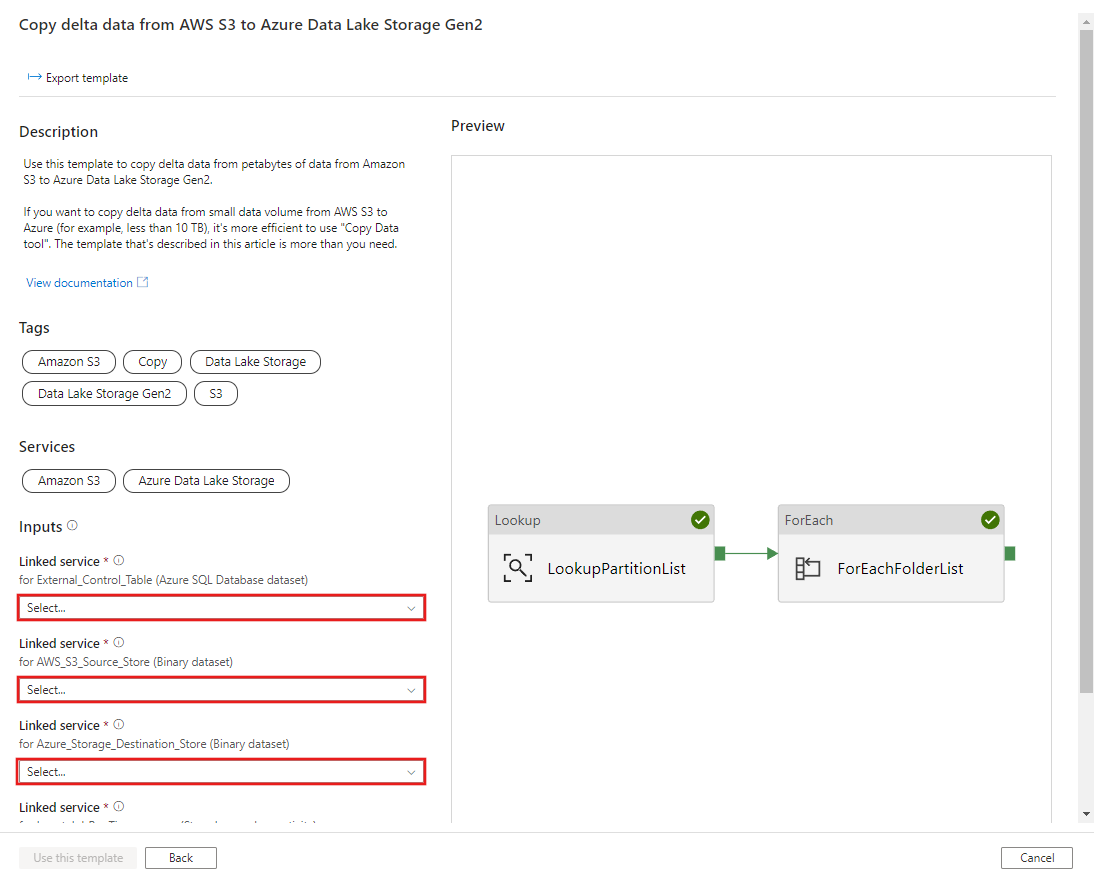
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOVá para o modelo Migrar dados históricos do AWS S3 para o Azure Data Lake Storage Gen2. Insira as conexões na tabela de controle externa, AWS S3 como o armazenamento de fonte de dados e Azure Data Lake Storage Gen2 como o armazenamento de destino. Lembre-se de que a tabela de controle externa e o procedimento armazenado são referência para a mesma conexão.
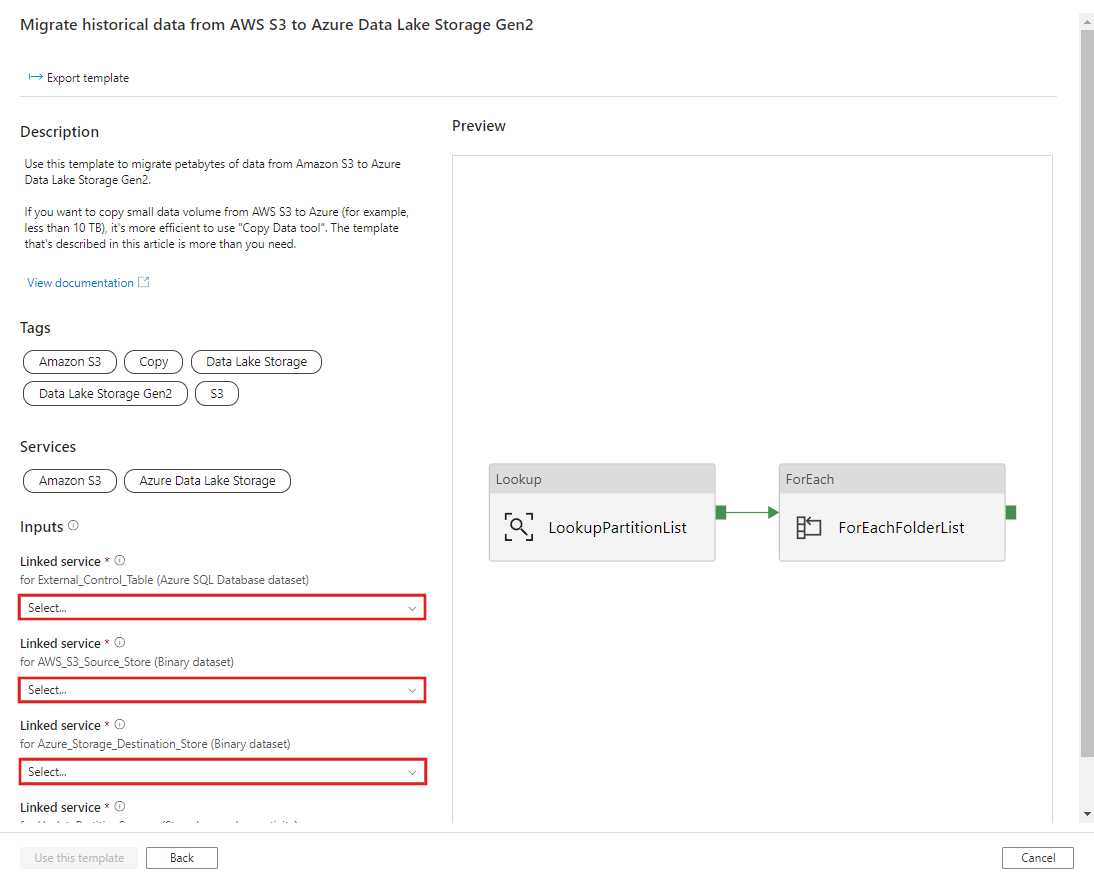
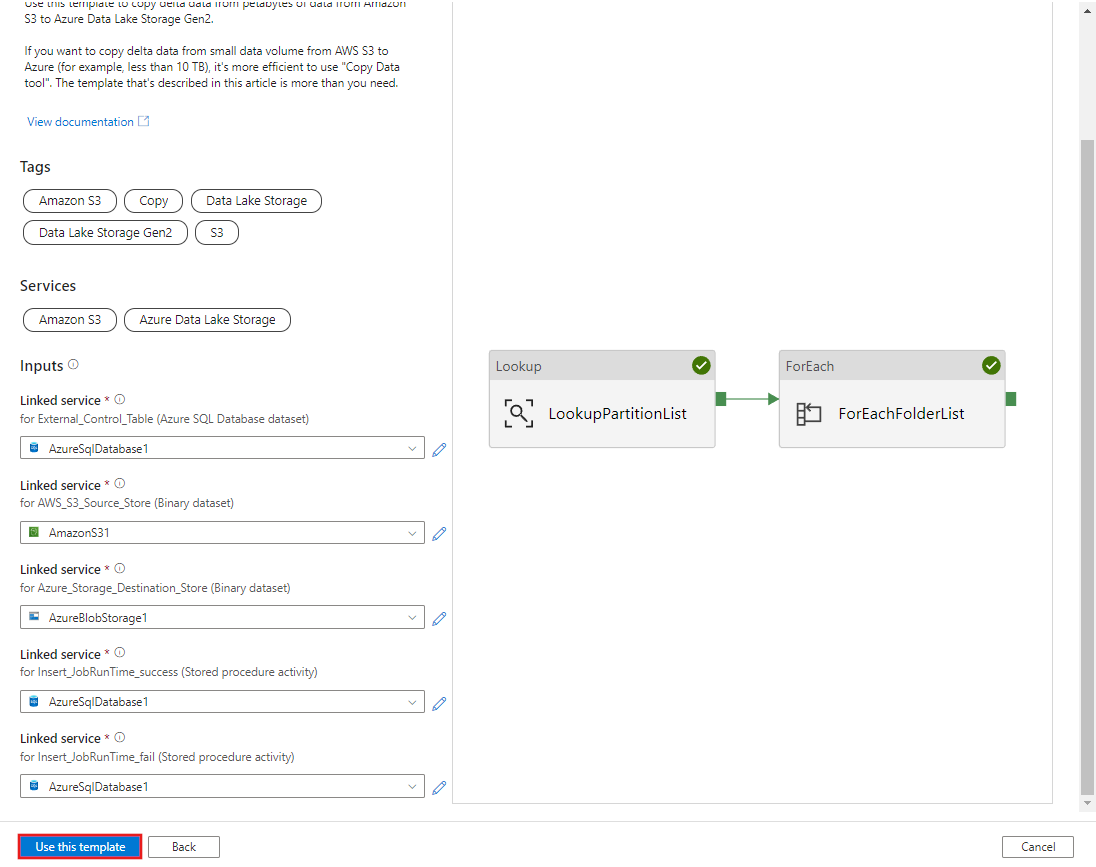
Selecione Usar este modelo.
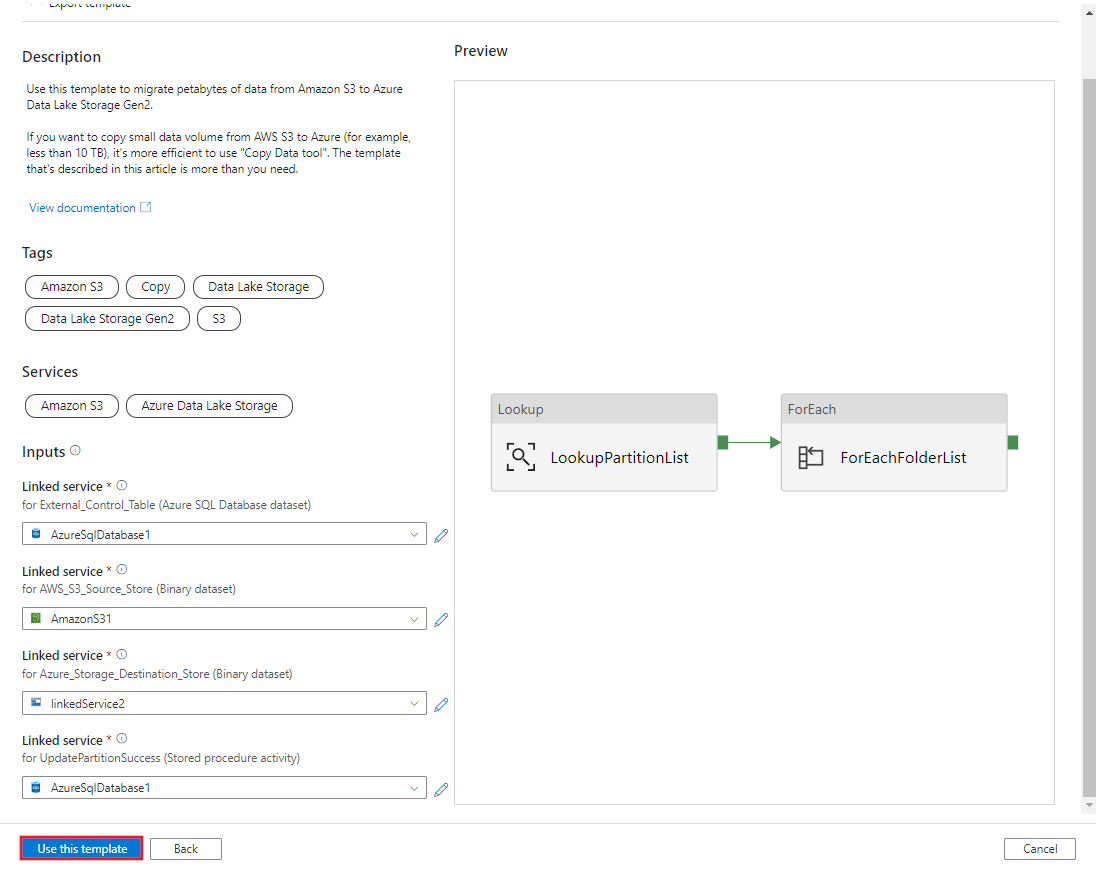
Você verá os 2 pipelines e 3 conjuntos de valores que foram criados, conforme mostrado no exemplo a seguir:
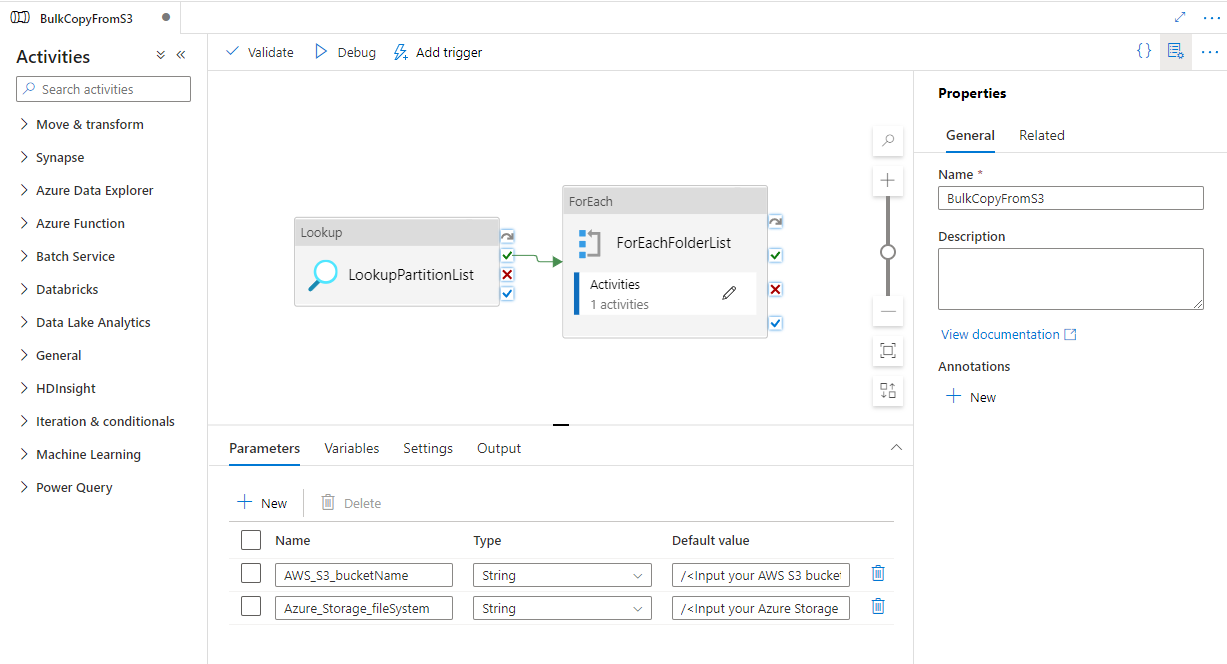
Vá para o pipeline "BulkCopyFromS3", selecione Depurar e insira os Parâmetros. Em seguida, selecione Concluir.
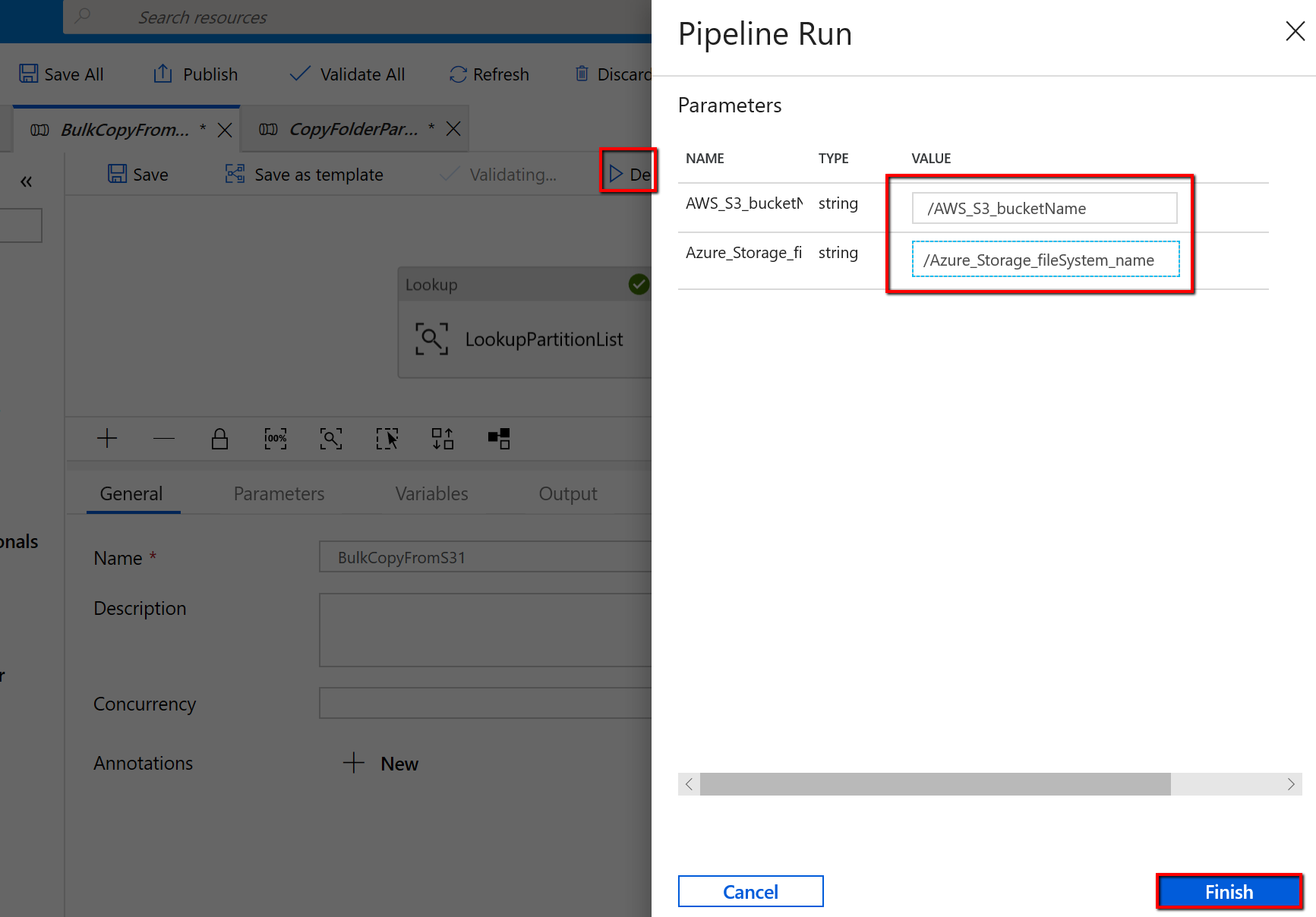
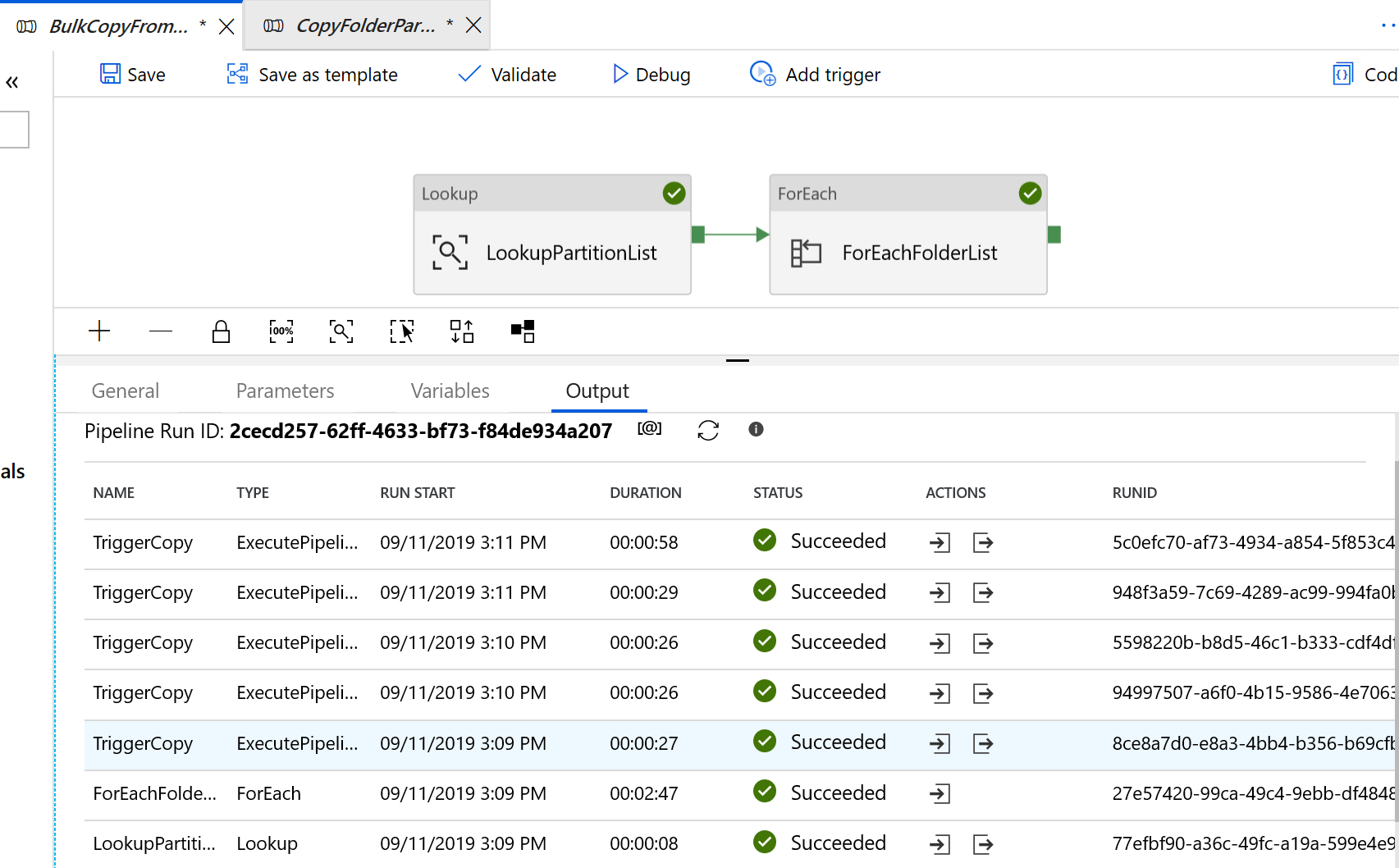
Você vê resultados semelhantes ao exemplo a seguir:
Para o modelo copiar somente arquivos alterados do Amazon S3 para o Azure Data Lake Storage Gen2
Criar uma tabela de controle no Banco de Dados SQL do Azure para armazenar a lista de partições do AWS S3.
Observação
O nome da tabela é s3_partition_delta_control_table. O esquema da tabela de controle é PartitionPrefix, JobRunTime e SuccessOrFailure, em que PartitionPrefix é a configuração de prefixo no S3 para filtrar as pastas e os arquivos no Amazon S3 por nome, JobRunTime é o valor de data e hora quando os trabalhos de cópia são executados e SuccessOrFailure é o status da cópia de cada partição: 0 significa que essa partição não foi copiada no Azure e 1 significa que a partição foi copiada para o Azure com êxito. Há 5 partições definidas na tabela de controle. O valor padrão de JobRunTime pode ser o horário do início da migração de dados históricos única. A atividade de cópia do ADF copiará os arquivos no AWS S3 que foram modificados pela última vez após esse horário. O status padrão da cópia de cada partição é 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Crie um procedimento armazenado no mesmo Banco de Dados SQL do Azure para a tabela de controle.
Observação
O nome do procedimento armazenado é sp_insert_partition_JobRunTime_success. Ele será invocado pela atividade SqlServerStoredProcedure no pipeline do ADF.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOVá para o modelo Copiar dados delta do AWS S3 para o Azure Data Lake Storage Gen2. Insira as conexões na tabela de controle externa, AWS S3 como o armazenamento de fonte de dados e Azure Data Lake Storage Gen2 como o armazenamento de destino. Lembre-se de que a tabela de controle externa e o procedimento armazenado são referência para a mesma conexão.
Selecione Usar este modelo.
Você verá os 2 pipelines e 3 conjuntos de valores que foram criados, conforme mostrado no exemplo a seguir:
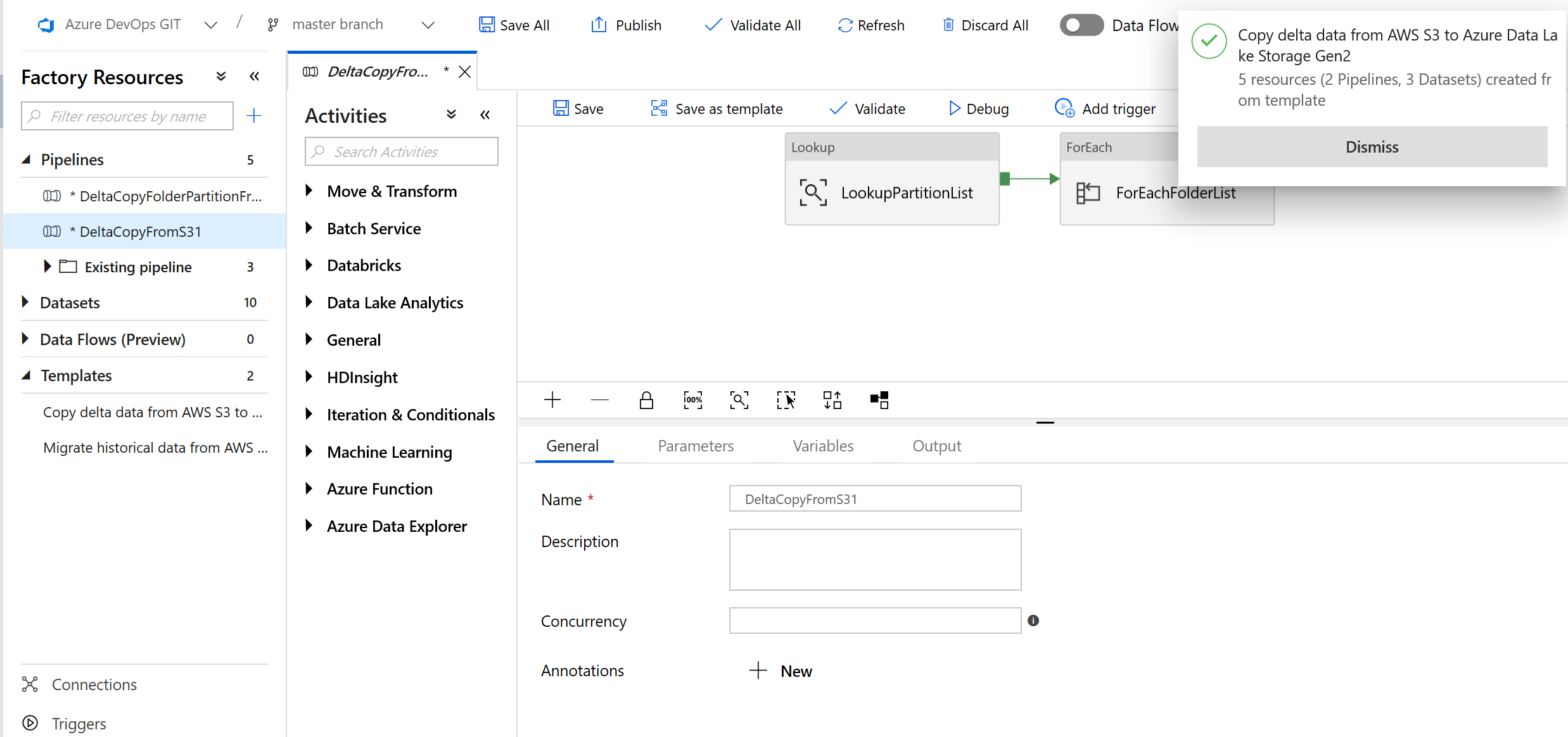
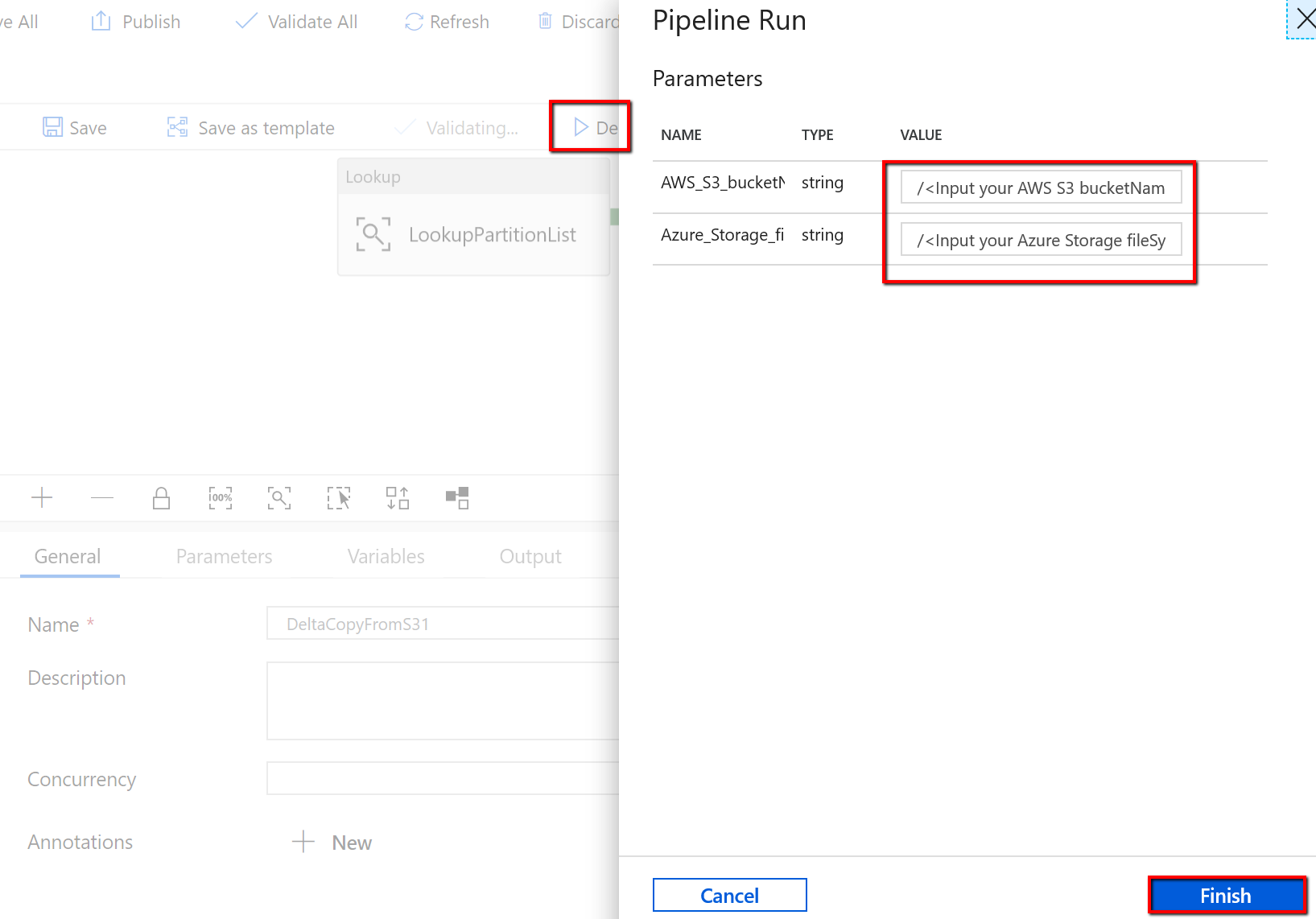
Acesse o pipeline "DeltaCopyFromS3", selecione Depurar e insira os Parâmetros. Em seguida, selecione Concluir.
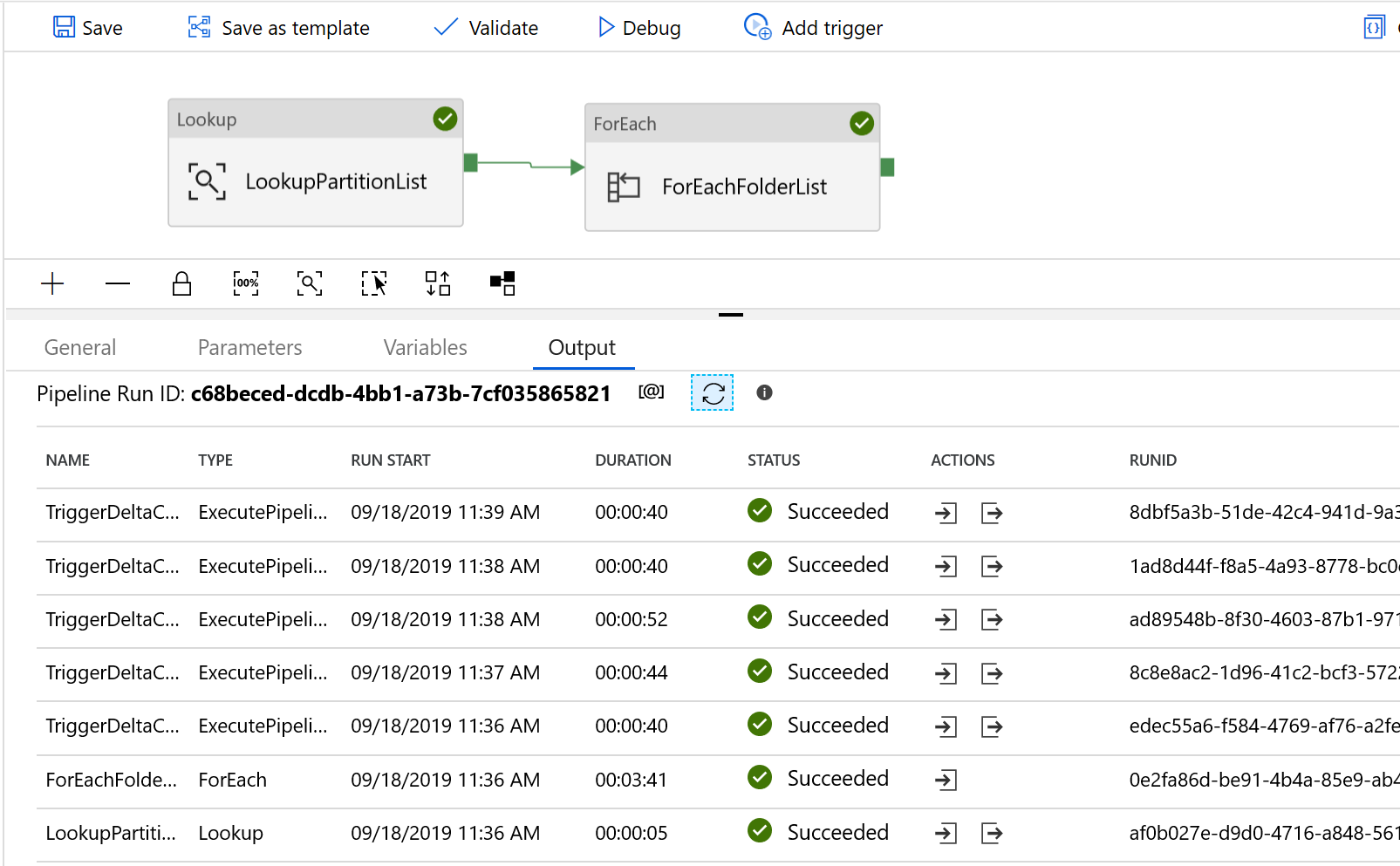
Você vê resultados semelhantes ao exemplo a seguir:
Também é possível verificar os resultados da tabela de controle por uma consulta "select * from s3_partition_delta_control_table" , e você verá a saída semelhante ao exemplo a seguir: