Cópia em massa de um banco de dados com uma tabela de controle
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Para copiar dados de um data warehouse no Oracle Server, Netezza, Teradata ou SQL Server para o Azure Synapse Analytics, é preciso carregar uma enorme quantidade de dados de várias tabelas em fontes de dados. Normalmente, os dados precisam ser particionados em cada tabela para que seja possível carregar linhas com vários threads paralelamente de uma só tabela. Este artigo descreve um modelo a ser usado nesses cenários.
Observação
Se você quiser copiar dados de um pequeno número de tabelas com volume de dados relativamente pequeno para o Azure Synapse Analytics, será mais eficiente usar a Ferramenta Copiar Dados do Azure Data Factory. O modelo descrito neste artigo é mais do que o necessário para esse cenário.
Sobre o modelo de solução
Este modelo recupera uma lista de partições do banco de dados de origem para copiar de uma tabela de controle externa. Em seguida, ele itera em cada partição no banco de dados de origem e copia os dados para o destino.
O modelo contém três atividades:
- Lookup recupera a lista de partições de banco de dados de uma tabela de controle externa.
- ForEach obtém a lista de partições da atividade Lookup e itera cada partição para a atividade Copy.
- Copy copia cada partição do armazenamento de banco de dados de origem para o de destino.
O modelo define os seguintes parâmetros:
- Control_Table_Name é a tabela de controle externa, que armazena a lista de partições do banco de dados de origem.
- Control_Table_Schema_PartitionID é o nome da coluna em sua tabela de controle externa que armazena cada ID da partição. Verifique se a ID da partição é exclusiva para cada partição no banco de dados de origem.
- Control_Table_Schema_SourceTableName é a tabela de controle externa que armazena cada nome de tabela do banco de dados de origem.
- Control_Table_Schema_FilterQuery é o nome da coluna em sua tabela de controle externa que armazena a consulta de filtro a fim de obter os dados de cada partição no banco de dados de origem. Por exemplo, se você particionou os dados por ano, a consulta armazenada em cada linha pode ser semelhante a ‘select * from datasource where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''.
- Data_Destination_Folder_Path é o caminho em que os dados são copiados no armazenamento de destino (aplicável quando o destino escolhido é o "Sistema de Arquivos" ou o "Azure Data Lake Storage Gen1").
- Data_Destination_Container é o caminho da pasta raiz para a qual os dados são copiados em seu armazenamento de destino.
- Data_Destination_Directory é o caminho do diretório na raiz para a qual os dados são copiados para o armazenamento de destino.
Os últimos três parâmetros que definem o caminho no armazenamento de destino ficam visíveis apenas quando o destino escolhido é um armazenamento baseado em arquivos. Se você escolher “Azure Synapse Analytics” como o armazenamento de destino, esses parâmetros não serão necessários. Porém, os nomes de tabela e o esquema no Azure Synapse Analytics devem ser os mesmos que os do banco de dados de origem.
Como usar este modelo de solução
Crie uma tabela de controle em um SQL Server ou Banco de Dados SQL do Azure para armazenar a lista de partições do banco de dados de origem para a cópia em massa. No exemplo a seguir, há cinco partições no banco de dados de origem. Três partições são para datasource_table e duas são para project_table. A coluna LastModifytime é usada para particionar os dados na tabela datasource_table do banco de dados de origem. A consulta usada para ler a primeira partição é 'select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''. Você pode usar uma consulta semelhante para ler dados de outras partições.
Create table ControlTableForTemplate ( PartitionID int, SourceTableName varchar(255), FilterQuery varchar(255) ); INSERT INTO ControlTableForTemplate (PartitionID, SourceTableName, FilterQuery) VALUES (1, 'datasource_table','select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''), (2, 'datasource_table','select * from datasource_table where LastModifytime >= ''2016-01-01 00:00:00'' and LastModifytime <= ''2016-12-31 23:59:59.999'''), (3, 'datasource_table','select * from datasource_table where LastModifytime >= ''2017-01-01 00:00:00'' and LastModifytime <= ''2017-12-31 23:59:59.999'''), (4, 'project_table','select * from project_table where ID >= 0 and ID < 1000'), (5, 'project_table','select * from project_table where ID >= 1000 and ID < 2000');Vá até o modelo Cópia em massa do banco de dados. Crie uma Conexão com a tabela de controle externa criada na etapa 1.
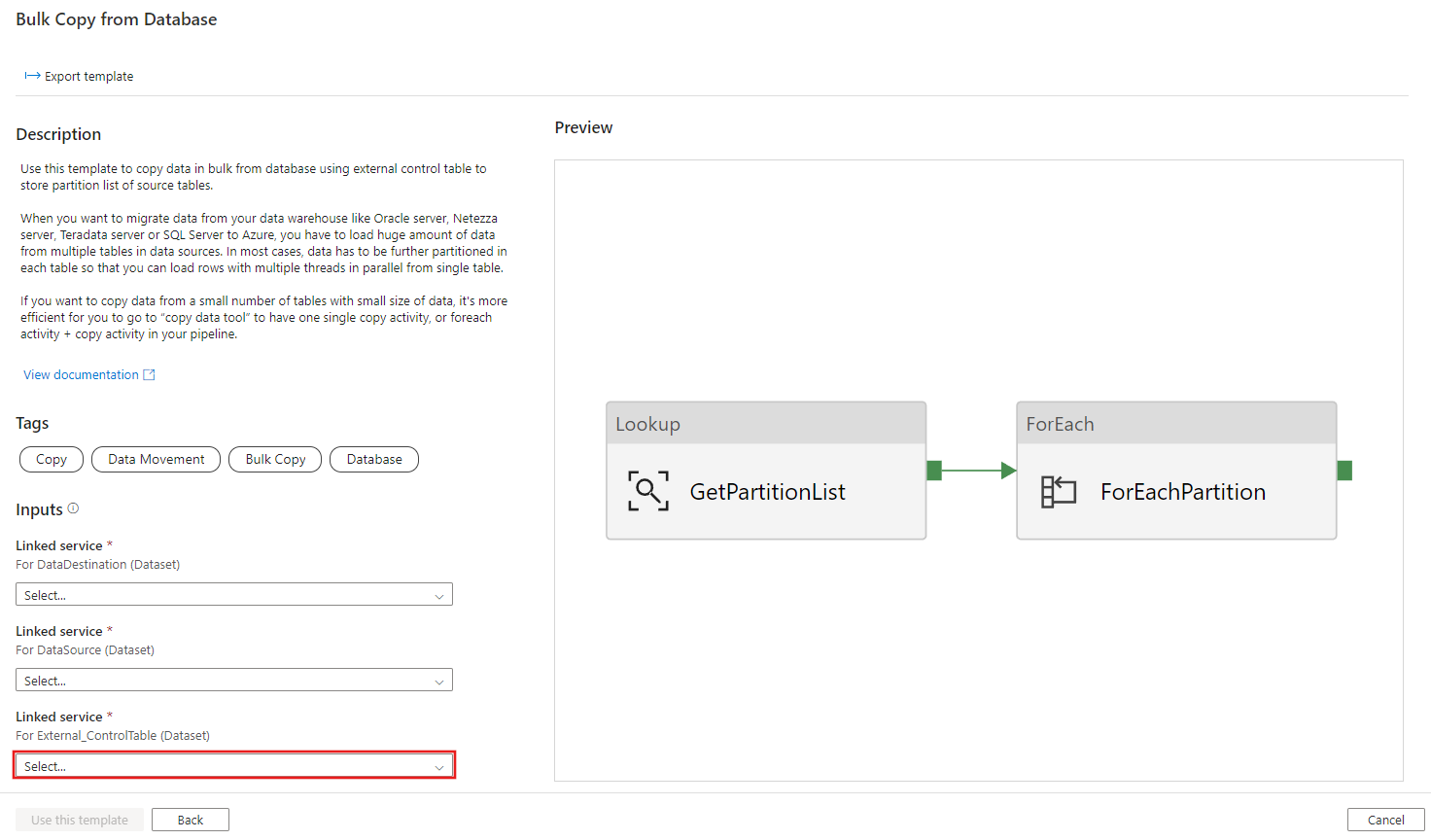
Crie uma Conexão com o banco de dados de origem do qual você está copiando dados.
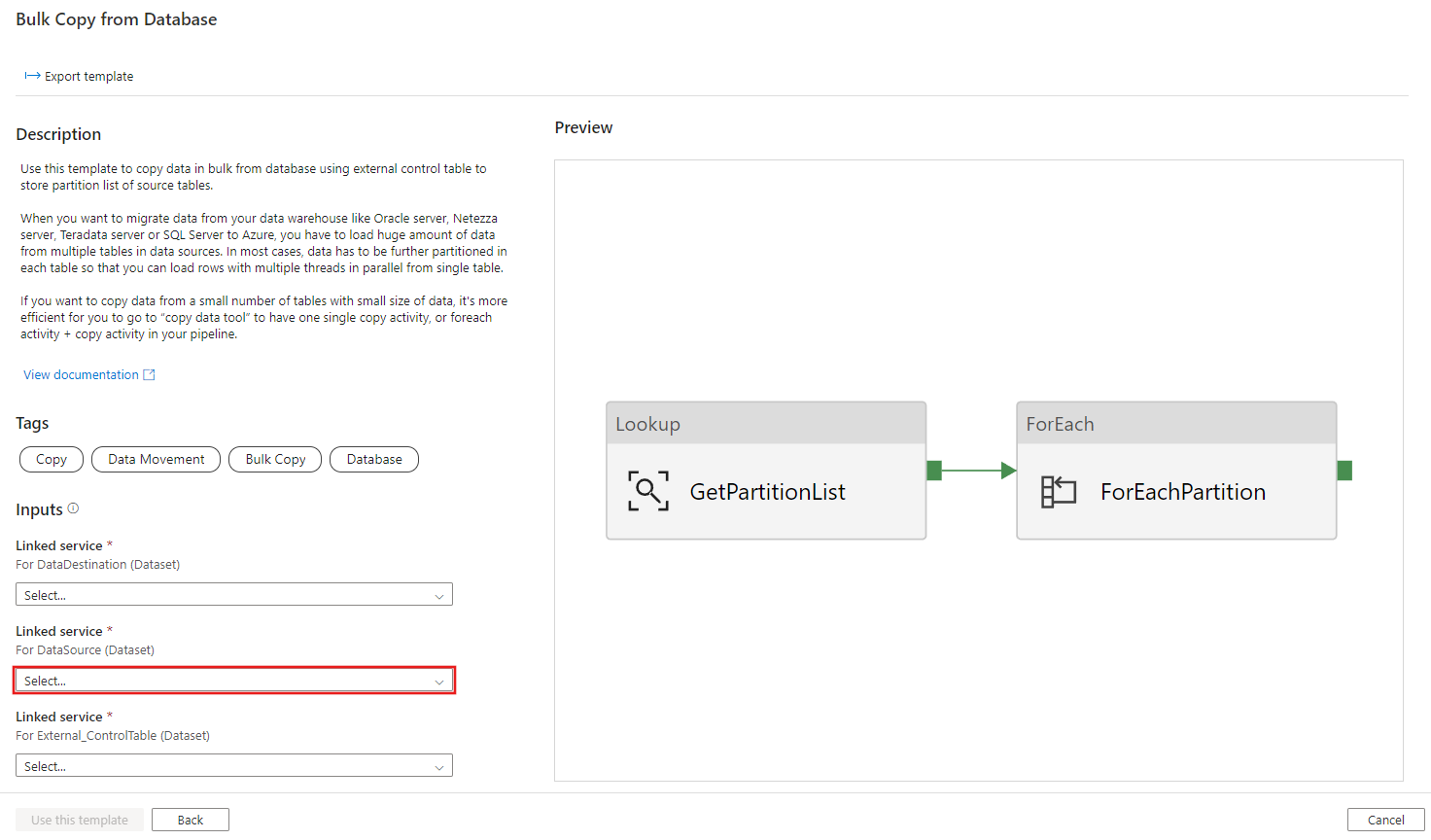
Crie uma Conexão com o armazenamento de dados de destino para o qual você está copiando dados.
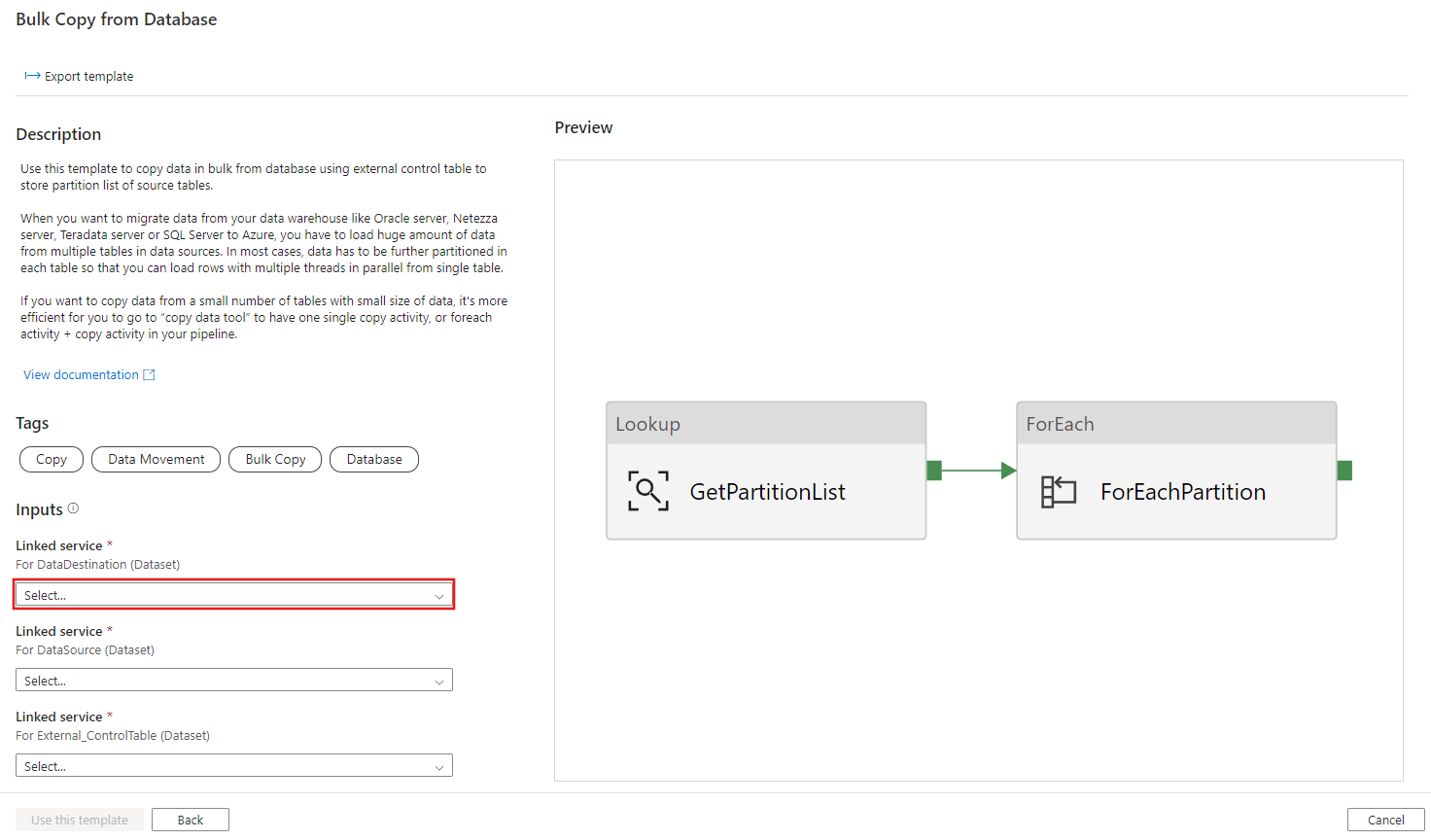
Selecione Usar este modelo.
Você verá o pipeline, conforme mostrado no seguinte exemplo:
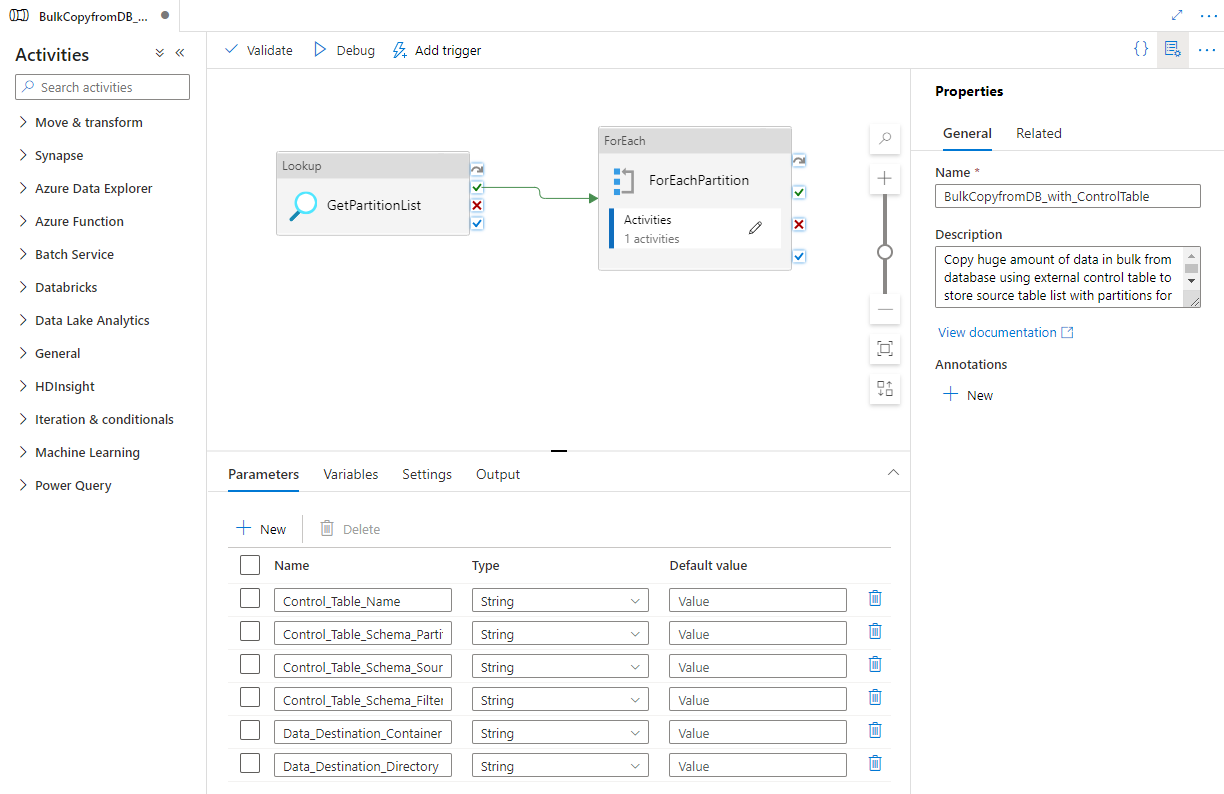
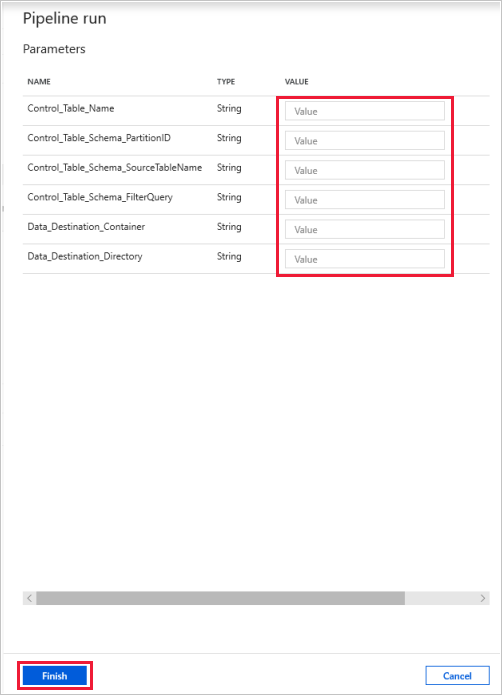
Selecione Depurar, insira os Parâmetros e, em seguida, selecione Concluir.
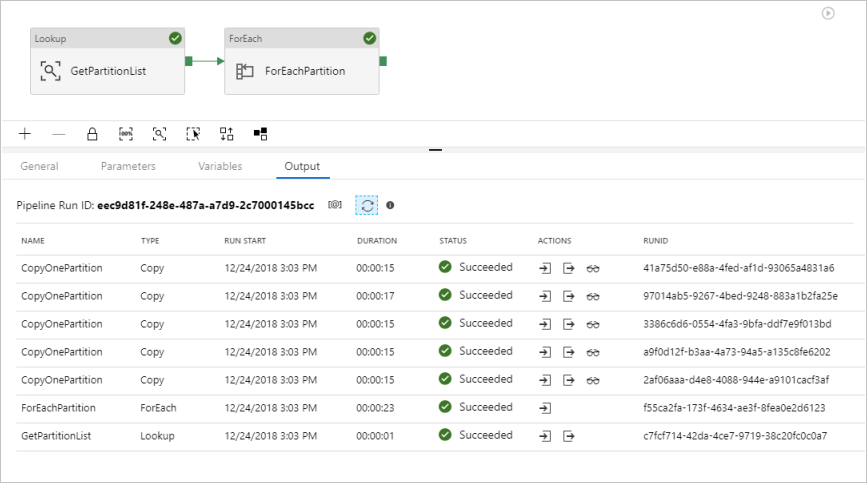
Você vê resultados semelhantes ao exemplo a seguir:
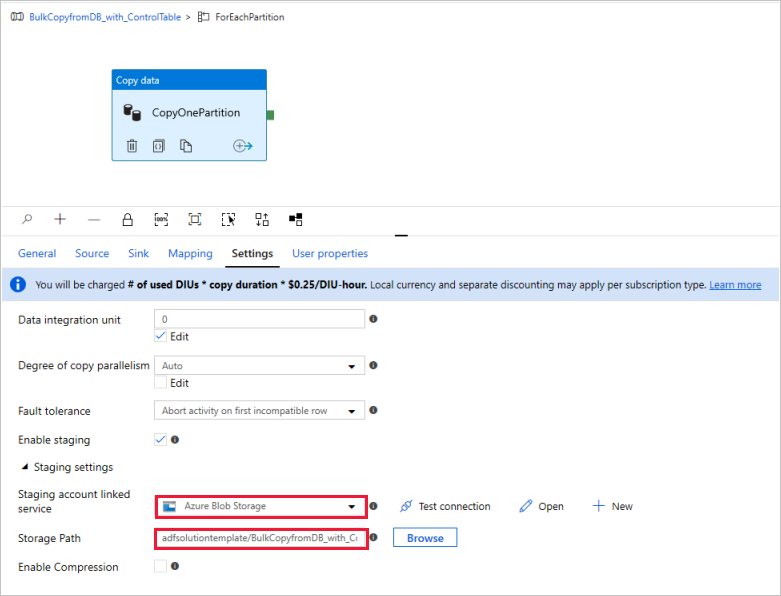
(Opcional) Se você escolheu “Azure Synapse Analytics” como destino de dados, insira uma conexão com o armazenamento de Blobs do Azure para o processo de preparo, conforme exigido pelo Azure Synapse Analytics Polybase. O modelo gera automaticamente um caminho de contêiner para o Armazenamento de Blobs. Verifique se o contêiner foi criado após a execução do pipeline.