Início rápido: Introdução ao Azure Data Factory
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Boas-vindas ao Azure Data Factory! Este artigo de introdução apresenta como você criará seu primeiro data factory e pipeline em 5 minutos. O modelo do ARM abaixo criará e configurará tudo o que for necessário para experimentar. Em seguida, você somente precisará navegar até o data factory de demonstração e clicar mais uma vez para disparar o pipeline, que moverá alguns dados de exemplo de um armazenamento de blobs do Azure para outro.
Pré-requisitos
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Resumo do vídeo
O seguinte vídeo fornece instruções passo a passo para o exemplo:
Experimente a sua primeira demonstração com um clique
No primeiro cenário de demonstração, você usará a atividade Copy em um data factory para copiar um blob do Azure nomeado moviesDB2.csv de uma pasta de entrada em um Armazenamento de Blobs do Azure para uma pasta de saída. Em um cenário do mundo real, essa operação de cópia poderá ser entre qualquer uma das muitas fontes de dados e coletores com suporte disponíveis no serviço. Isso também poderá envolver transformações nos dados.
Experimente agora com um clique! Após clicar no botão abaixo, os seguintes objetos serão criados no Azure:
- Uma conta do data factory
- Um pipeline dentro do data factory com uma atividade Copy
- Um armazenamento de blobs do Azure com moviesDB2.csv carregado em uma pasta de entrada como origem
- Um serviço vinculado para conectar o data factory ao armazenamento de blobs do Azure
Etapa 1: clicar no botão para iniciar
Selecione o botão abaixo para experimentar. (Se você já clicou no botão acima, não será necessário clicar novamente.)

Você será redirecionado para a página de configuração mostrada na imagem abaixo para implantar o modelo. Aqui, será necessário apenas criar um novo grupo de recursos. (Você poderá deixar todos os outros valores com os respectivos padrões.) Em seguida, clique em Revisar + criar e clique em Criar para implantar os recursos.
Observação
O usuário que está implantando o modelo precisará atribuir uma função a uma identidade gerenciada. Isso requer permissões que podem ser concedidas por meio das funções Proprietário, Administrador de Acesso do Usuário ou Operador de Identidade Gerenciada.
Todos os recursos referenciados acima serão criados no novo grupo de recursos, para que você possa limpá-los facilmente após experimentar a demonstração.
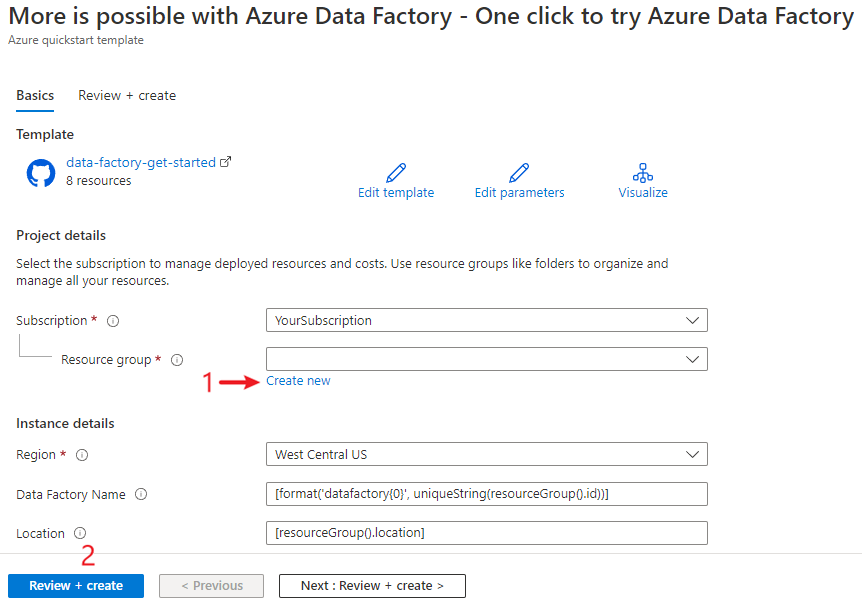
Etapa 2: revisar os recursos implantados
Selecione Ir para o grupo de recursos após concluir a implantação.
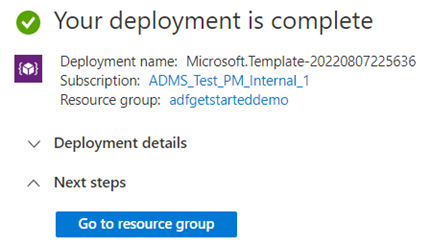
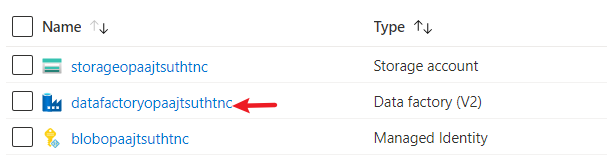
No grupo de recursos, você verá um novo data factory, a conta de armazenamento de blobs do Azure e a identidade gerenciada criados pela implantação.
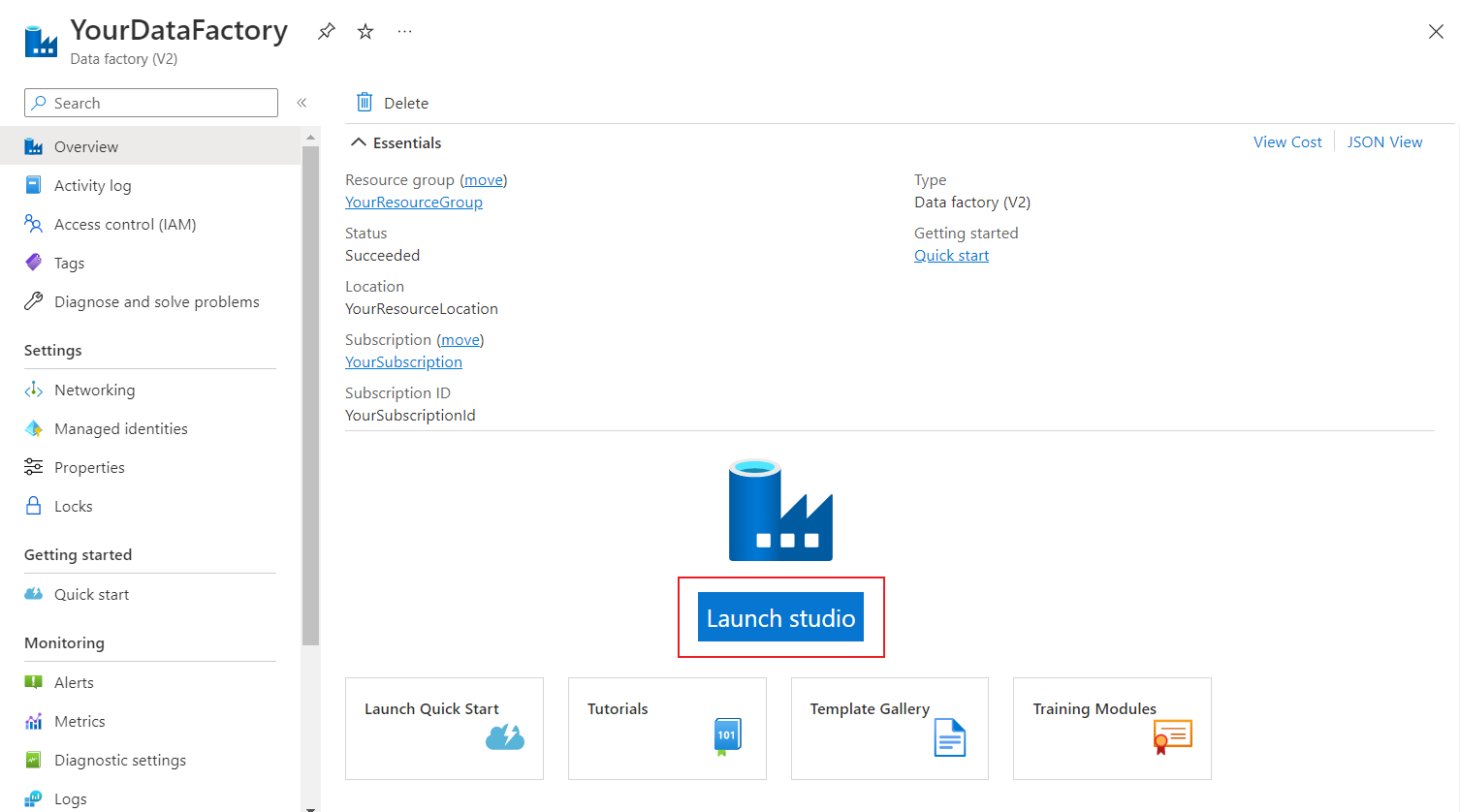
Selecione o data factory no grupo de recursos para exibi-lo. Em seguida, selecione o botão Iniciar Estúdio para continuar.
Selecione a guia Criador
 e, em seguida, o Pipeline criado pelo modelo. Em seguida, verifique os dados de origem selecionando Abrir.
e, em seguida, o Pipeline criado pelo modelo. Em seguida, verifique os dados de origem selecionando Abrir.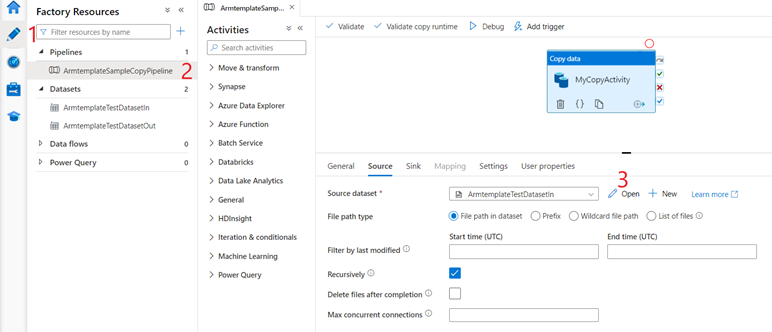
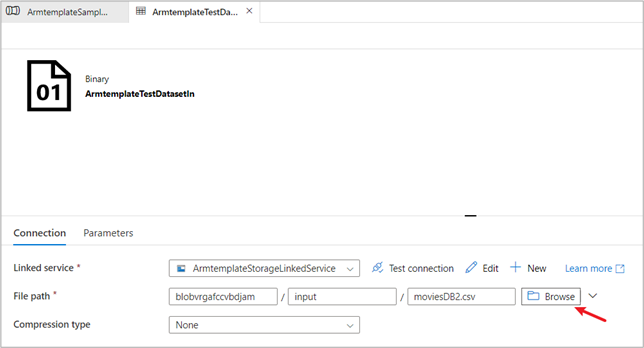
No conjunto de dados de origem que você verá, selecione Procurar e anote o arquivo moviesDB2.csv que já foi carregado na pasta de entrada.
Etapa 3: disparar o pipeline de demonstração para executar
- Selecione Adicionar Gatilho e, em seguida, Disparar Agora.

- No painel direito, em Execução do pipeline, selecione OK.
Monitorar o Pipeline
Selecione a guia Monitor
 .
.Na guia Monitor, é possível visualizar uma visão geral das execuções de pipeline como, por exemplo, a hora de início da execução, o status, etc.
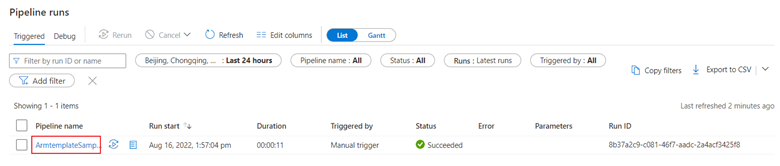
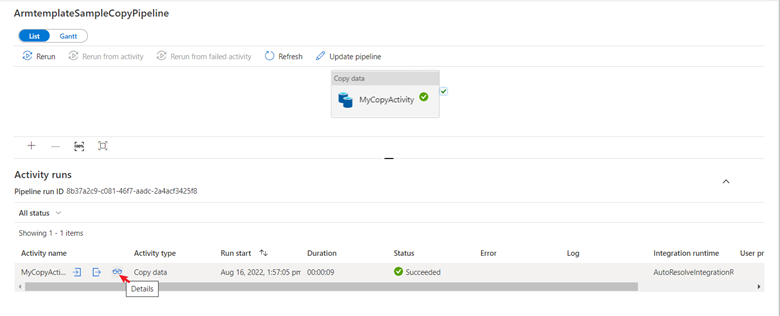
Neste início rápido, o pipeline tem apenas um tipo de atividade: cópia. Clique no nome do pipeline e você poderá ver os detalhes dos resultados da execução da atividade de cópia.
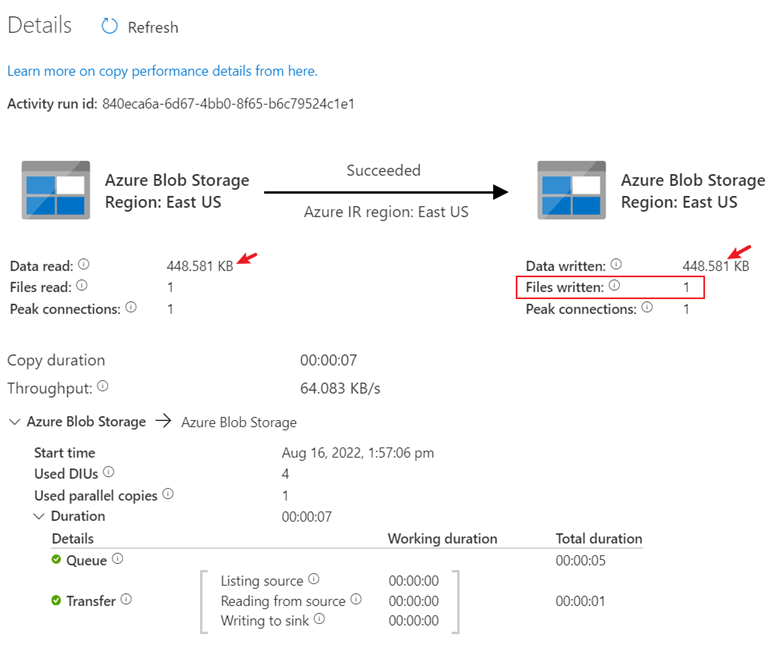
Clique em detalhes e o processo de cópia detalhado será exibido. Nos resultados, os dados lidos e o tamanho gravado serão os mesmos, e um arquivo foi lido e gravado, o que também provará que todos os dados foram copiados com êxito para o destino.
Limpar os recursos
É possível limpar todos os recursos criados neste início rápido de duas maneiras. Você pode excluir todo o grupo de recursos do Azure, que inclui todos os recursos criados nele. Ou, se você quiser manter alguns recursos intactos, navegue até o grupo de recursos e exclua apenas os recursos específicos desejados, mantendo os outros. Por exemplo, se estiver usando este modelo para criar um data factory para uso em outro tutorial, poderá excluir os outros recursos mas manter apenas o data factory.
Conteúdo relacionado
Neste início rápido, você criou um Azure Data Factory contendo um pipeline com uma atividade de cópia. Para saber mais sobre o Azure Data Factory, continue no artigo e no módulo do Learn abaixo.