Capturar dados alterados do Azure Data Lake Storage Gen2 para Banco de Dados SQL do Azure usando um recurso de captura de dados de alteração
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste artigo, você usa a interface do usuário do Azure Data Factory para criar um recurso de CDA (captura de dados de alteração). O recurso coleta dados alterados de uma fonte do Azure Data Lake Storage Gen2 e os adiciona ao Banco de Dados SQL do Azure em tempo real.
Neste artigo, você aprenderá como:
- Crie um recurso de CDA.
- Monitore a atividade de CDA.
Você pode modificar e expandir o padrão de configuração neste artigo.
Pré-requisitos
Antes de iniciar os procedimentos deste artigo, certifique-se de ter estes recursos:
- Assinatura do Azure. Caso não tenha uma assinatura do Azure, crie uma conta gratuita do Azure.
- Banco de dados SQL. Use o Banco de Dados SQL do Azure como armazenamento de dados de origem. Se você não tiver um banco de dados SQL, crie um no portal do Azure.
- Conta de armazenamento. Use o Delta Lake armazenado no Azure Data Lake Storage Gen2 como um armazenamento de dados de destino. Se você não tiver uma conta de armazenamento, confira Criar uma conta de armazenamento para obter as etapas para criar uma.
Criar um artefato de CDA
Vá para o painel Autor em seu data factory. Abaixo de Pipelines, um novo artefato de nível superior chamado Captura de Dados de Alterações (versão prévia) é exibido.

Passe o mouse sobre a Captura de Dados de Alterações (versão prévia) até que três pontos apareçam. Em seguida, selecione Ações da Captura de Dados de Alterações (versão prévia).

Selecione o Novo CDA (versão prévia). Essa etapa abre um submenu para iniciar o processo guiado.

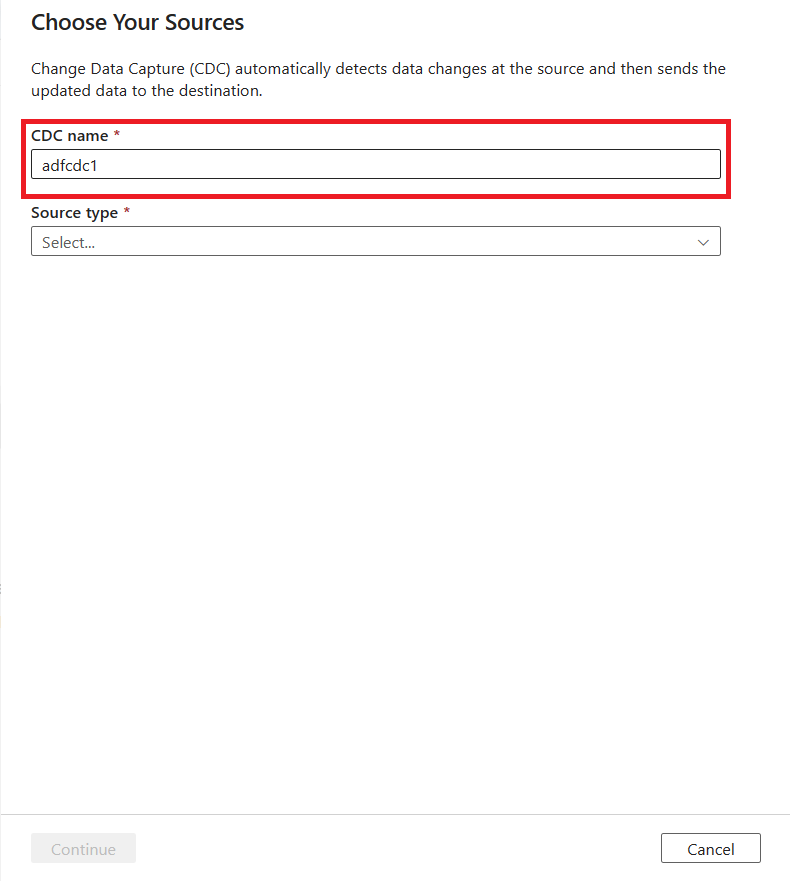
Você será solicitado a nomear o recurso de CDA. Por padrão, o nome é "adfcdc" com um número incrementado em 1. Você pode substituir esse nome padrão por um nome escolhido.
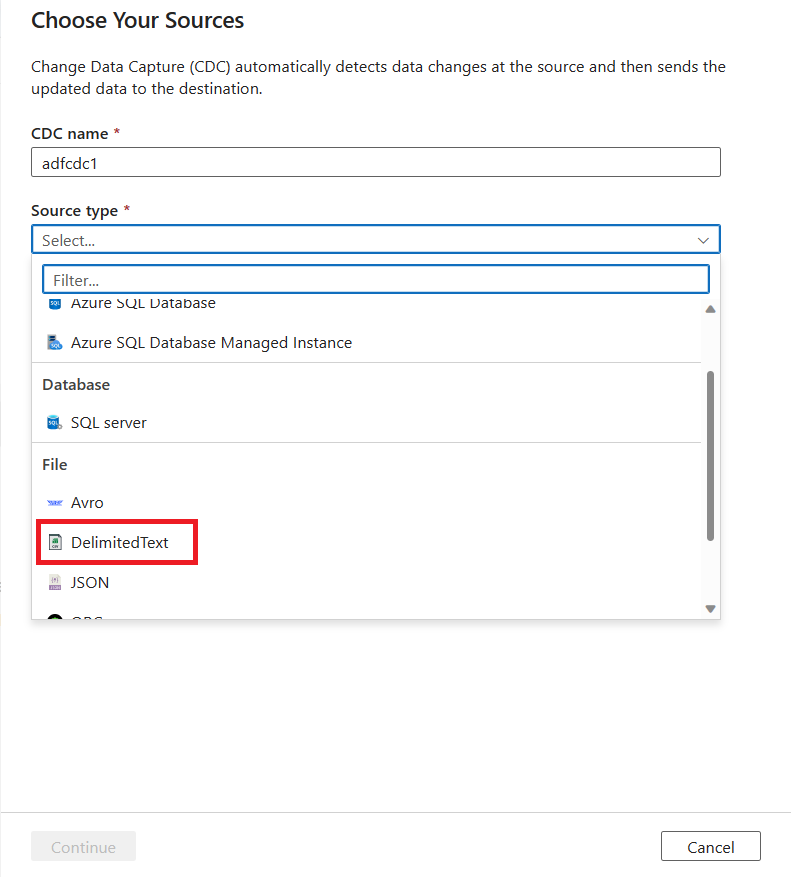
Use a lista de seleção para escolher sua fonte de dados. Para este artigo, selecione DelimitedText.
Em seguida, você será solicitado a selecionar um serviço vinculado. Crie um serviço vinculado ou selecione um existente.
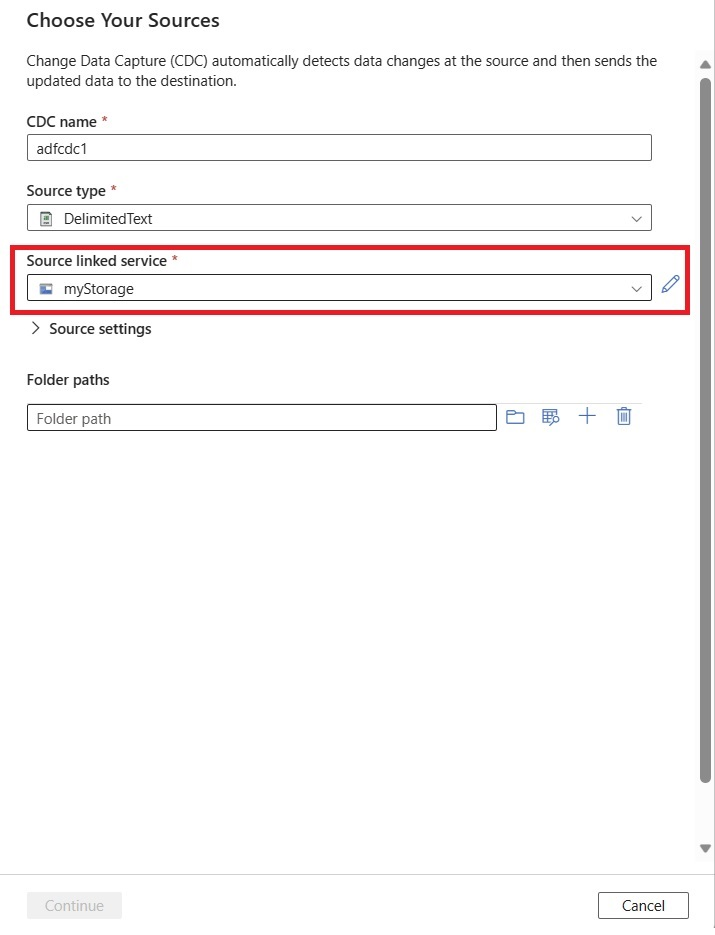
Use a área Configurações de origem para definir opcionalmente as configurações avançadas de origem, incluindo delimitadores de coluna e de linha.
Se você não editar manualmente essas configurações de origem, elas serão definidas como padrões.
Use o botão Procurar para selecionar sua pasta de dados de origem.
Depois de selecionar um caminho da pasta, selecione Continuar para definir seu destino de dados.
Você pode optar por adicionar várias pastas de origem usando o botão de adição (+). As outras origens também devem usar o mesmo serviço vinculado que você já selecionou.
Selecione um valor de Tipo de destino usando a lista de seleção. Para este artigo, selecione Banco de Dados SQL do Azure.
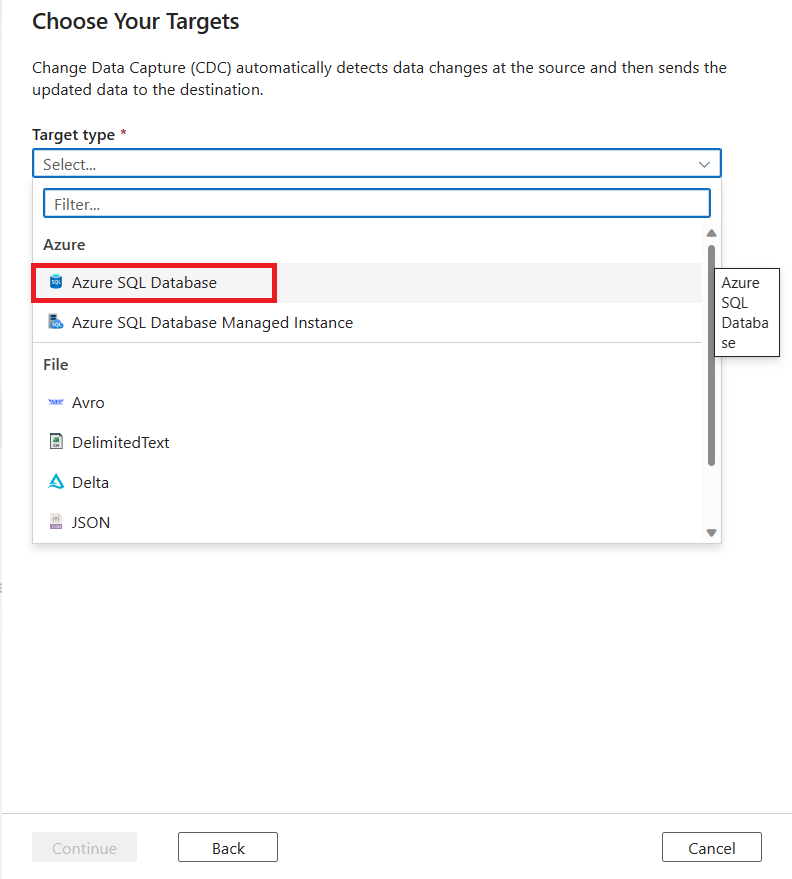
Em seguida, você será solicitado a selecionar um serviço vinculado. Crie um serviço vinculado ou selecione um existente.
Para Tabelas de destino, você pode criar uma nova tabela de destino ou selecionar uma existente:
Para criar uma tabela de destino, selecione a guia Novas entidades e, em seguida, selecione Editar novas tabelas.
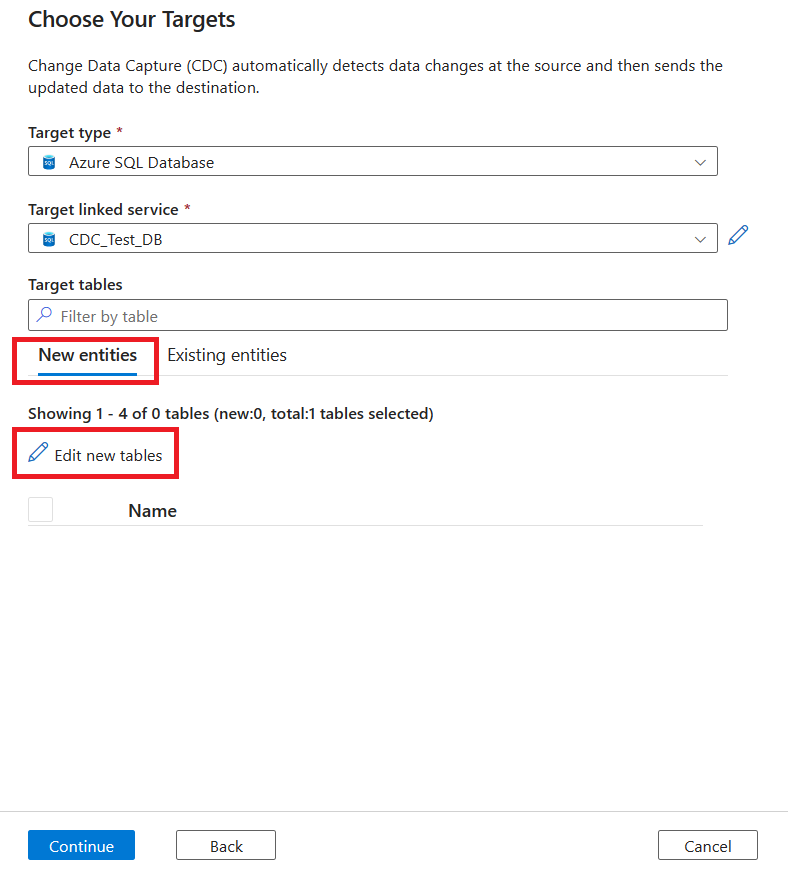
Para selecionar uma tabela existente, selecione a guia Entidades existentes e use a caixa de seleção para escolher uma tabela. Use botão Visualizar permite exibir os dados da tabela.
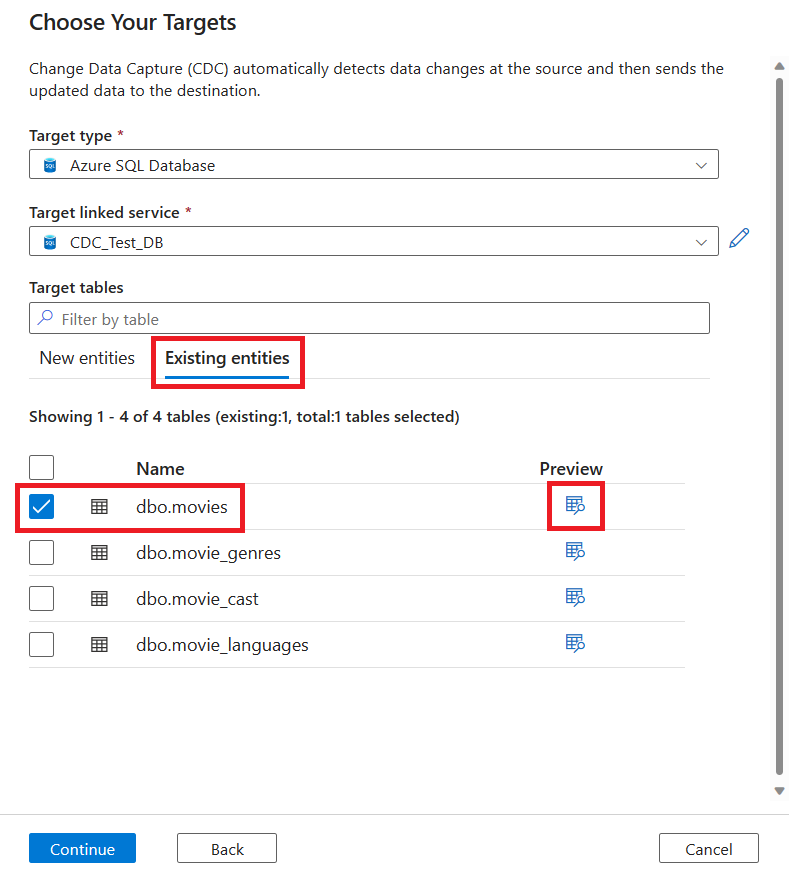
Se as tabelas existentes no destino tiverem nomes correspondentes, elas serão selecionadas por padrão em Entidades existentes. Caso contrário, novas tabelas com nomes correspondentes serão criadas em Novas entidades. Além disso, você pode editar novas tabelas usando o botão Editar novas tabelas.
Você pode usar as caixas de seleção para escolher várias tabelas de destino do banco de dados SQL. Depois de concluir a escolha das tabelas de destino, selecione Continuar.
Uma nova guia para capturar dados de alteração será exibida. Essa guia é o estúdio de CDA, no qual você pode configurar seu novo recurso.

Um novo mapeamento é criado automaticamente para você. Você pode atualizar as seleções Tabela de Origem e Tabela de Destino para seu mapeamento usando as listas de seleção.
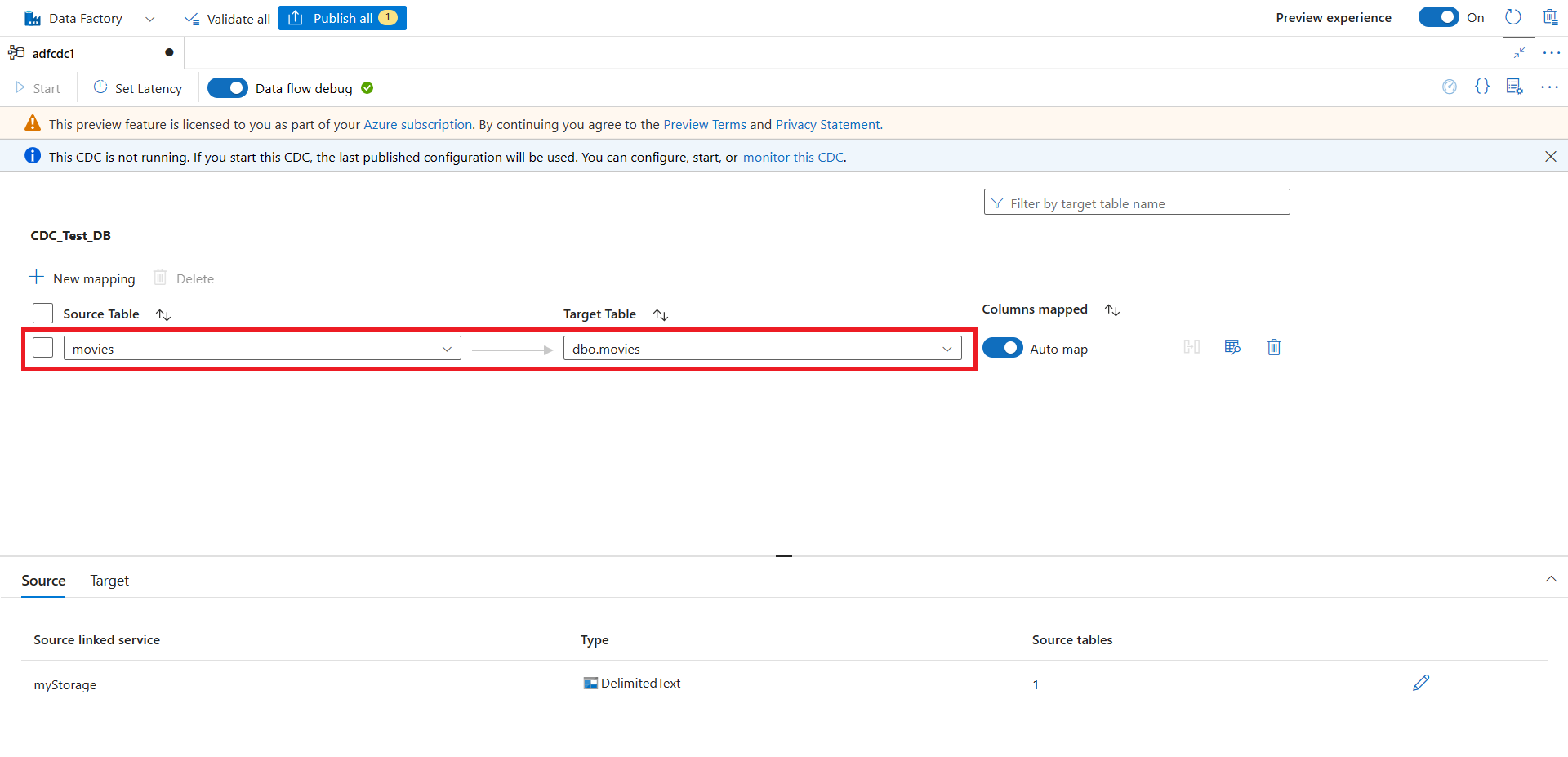
Depois de selecionar suas tabelas, suas colunas são mapeadas por padrão com a alternância Mapeamento automático ativada. O Mapeamento automático mapeia automaticamente as colunas por nome no coletor, seleciona novas alterações de coluna quando o esquema de origem evolui e flui essas informações para os tipos de coletores suportados.
Se você quiser usar oMapeamento automático e não alterar nenhum mapeamento de coluna, vá diretamente para a etapa 18.

Se você quiser habilitar os mapeamentos de coluna, selecione os mapeamentos e desative a alternância Mapeamento automático. Em seguida, selecione o botão Mapeamentos de coluna para visualizar os mapeamentos.

Você pode voltar para o mapeamento automático a qualquer momento ativando a alternância Mapeamento automático.
Exiba seus mapeamentos de coluna. Use as listas de seleção para editar os mapeamentos de coluna para Método de mapeamento, Coluna de origem e Coluna de destino.

Nesta página, você pode:
- Adicione mais mapeamentos de coluna usando o botão Novo mapeamento. Use as listas de seleção para selecionar Método de mapeamento, Coluna de origem e Coluna de destino.
- Selecione a coluna Chaves se quiser rastrear a operação de exclusão dos tipos de coletor com suporte.
- Selecione o botão Atualizar em Visualização de dados para visualizar a aparência dos dados no destino.
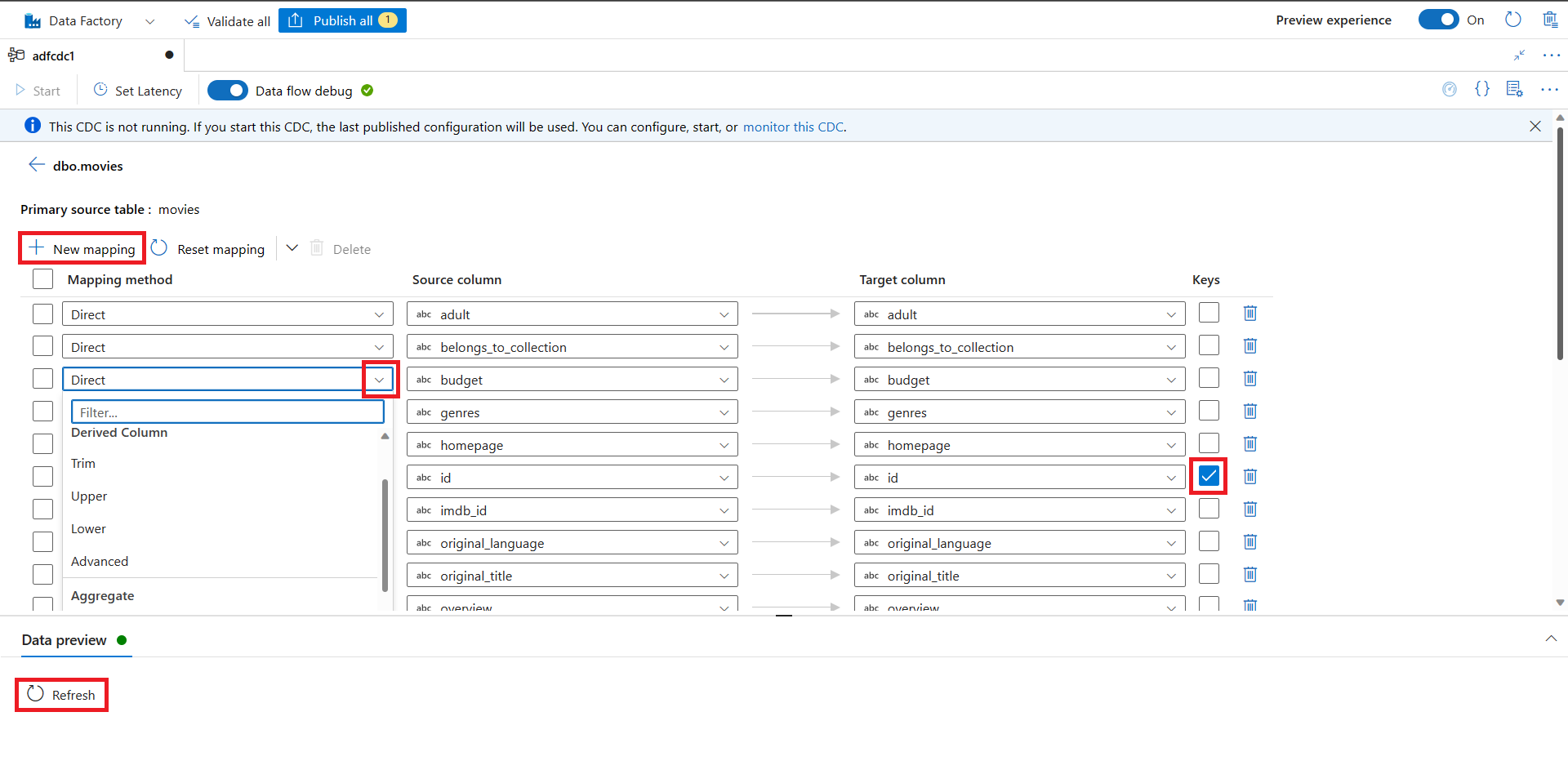
Quando o mapeamento estiver concluído, selecione o botão de seta para retornar à tela principal de CDA.

Você pode adicionar mais mapeamentos de origem para destino em um artefato de CDA. Use o botão Editar para adicionar mais fontes de dados e destinos. Em seguida, selecione Novo mapeamento e use as listas suspensas para definir uma nova origem e destino. Você pode ativar ou desativar o Mapeamento automático para cada um desses mapeamentos independentemente.

Ao concluir os mapeamentos, defina a latência de CDA usando o botão Definir Latência.
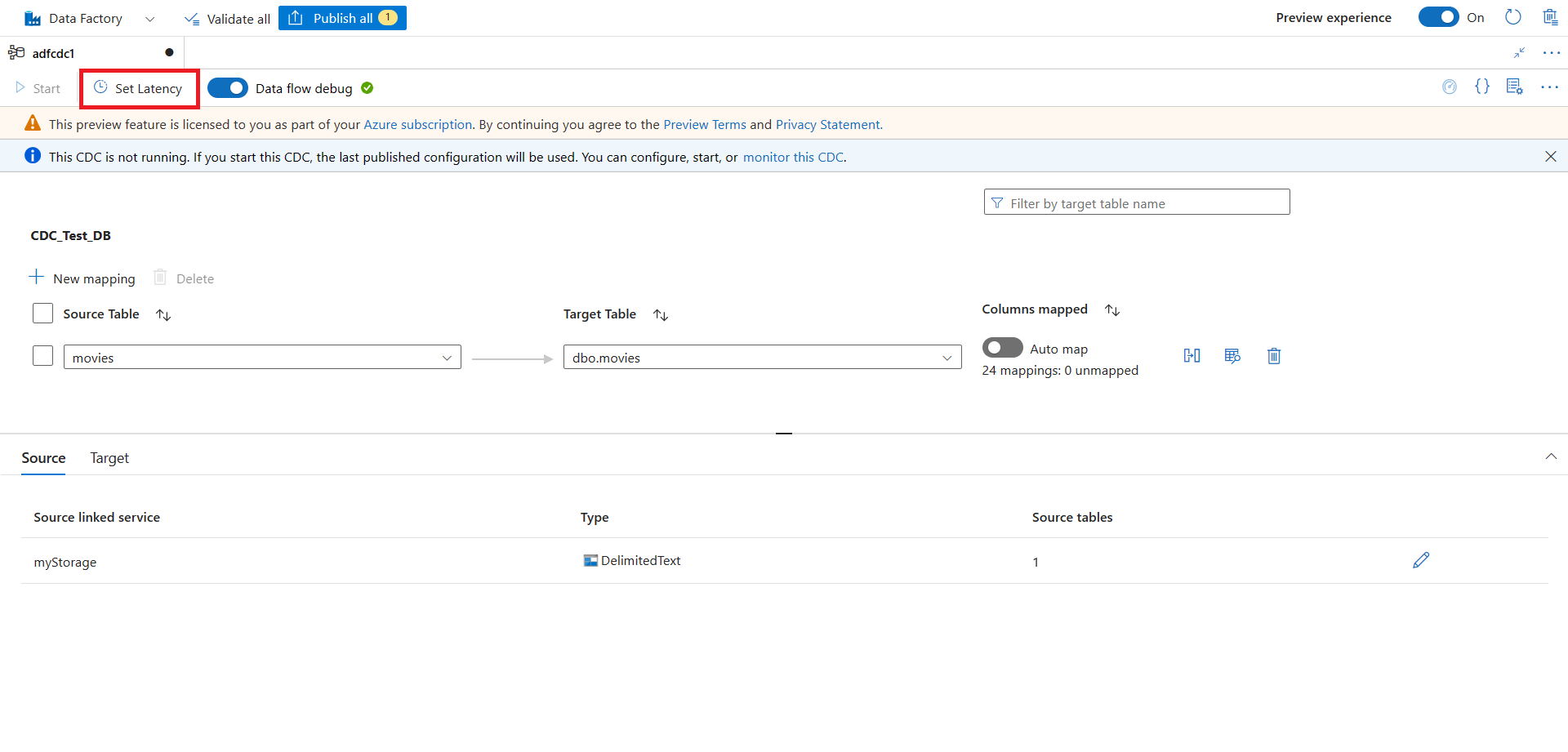
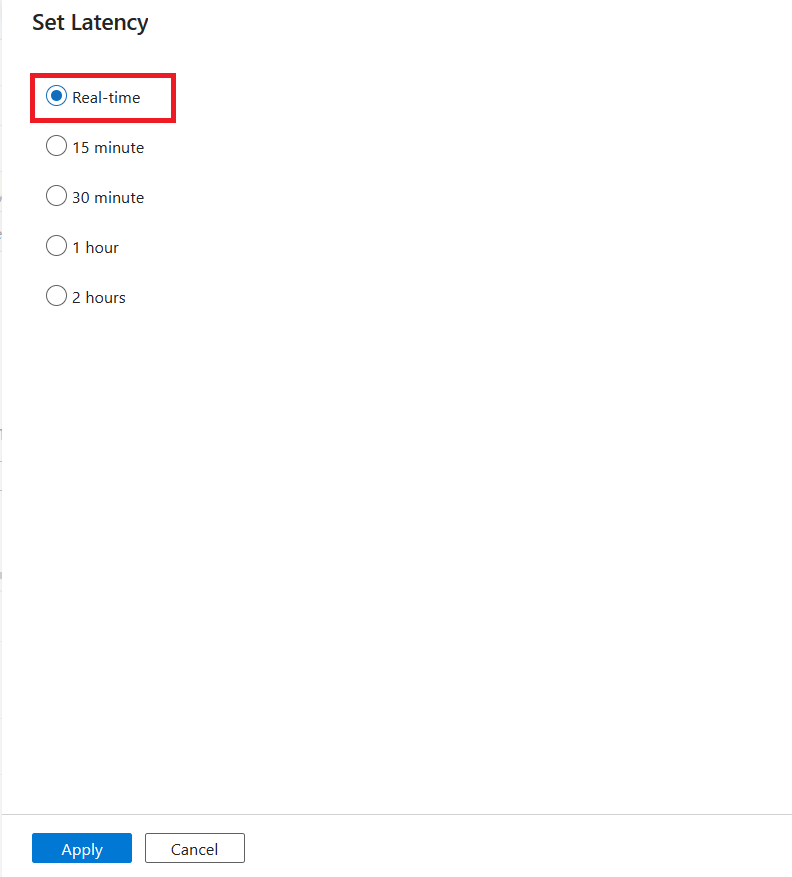
Selecione a latência de CDA e selecione Aplicar para fazer as alterações.
Por padrão, a latência é definida como 15 minutos. O exemplo neste artigo usa a opção Em tempo real para latência. A latência em tempo real capta continuamente as alterações nos dados de origem em intervalos de menos de 1 minuto.
Para outras latências (por exemplo, se você selecionar 15 minutos), sua captura de dados de alterações processará seus dados de origem e selecionará todos os dados alterados desde o último horário processado.
Observação
Se o suporte for estendido para integração de dados de streaming (fontes de dados dos Hubs de Eventos do Azure e do Kafka), a latência será definida como Tempo real por padrão.
Depois de concluir a configuração de CDA, selecione Publicar tudo para publicar suas alterações.
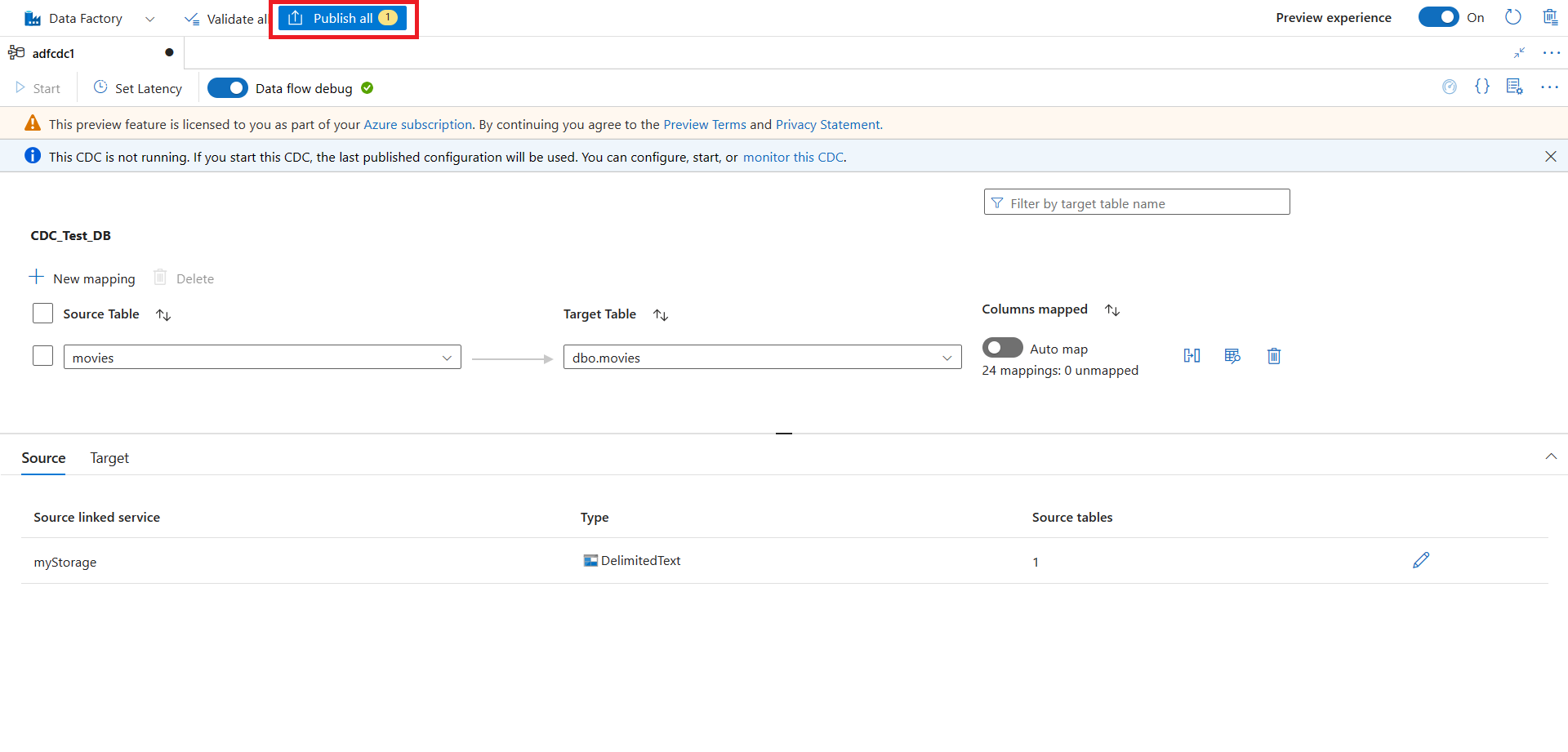
Observação
Se você não publicar suas alterações, não poderá iniciar seu recurso de CDA. O botão Iniciar na próxima etapa não estará disponível.
Selecione Iniciar para começar a executar a captura de dados de alterações.
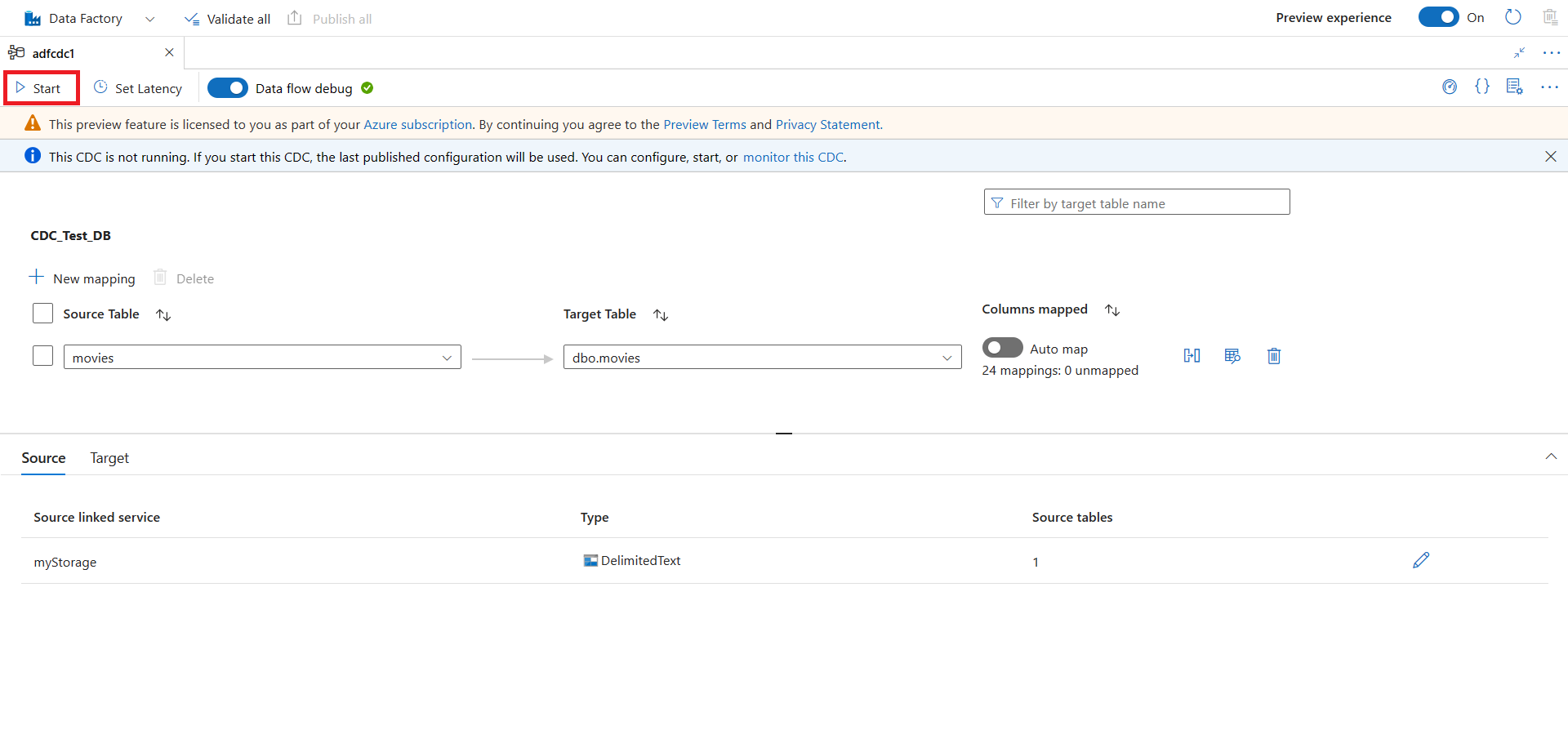














Monitorar a captura de dados de alterações
Abra o painel Monitorar usando um destes métodos:
No portal do Azure, selecione Monitorar.
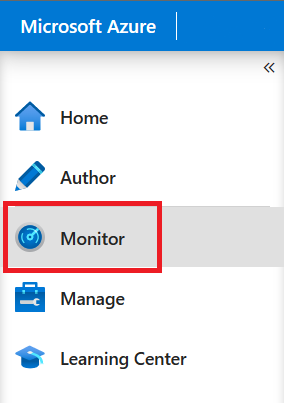
Selecione o ícone de monitoramento no designer de CDA.

Selecione Captura de Dados de Alterações (versão prévia) para exibir seus recursos da CDA.
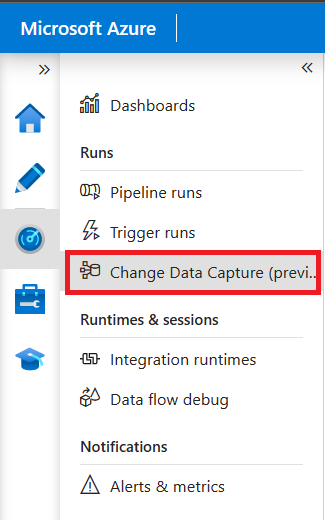
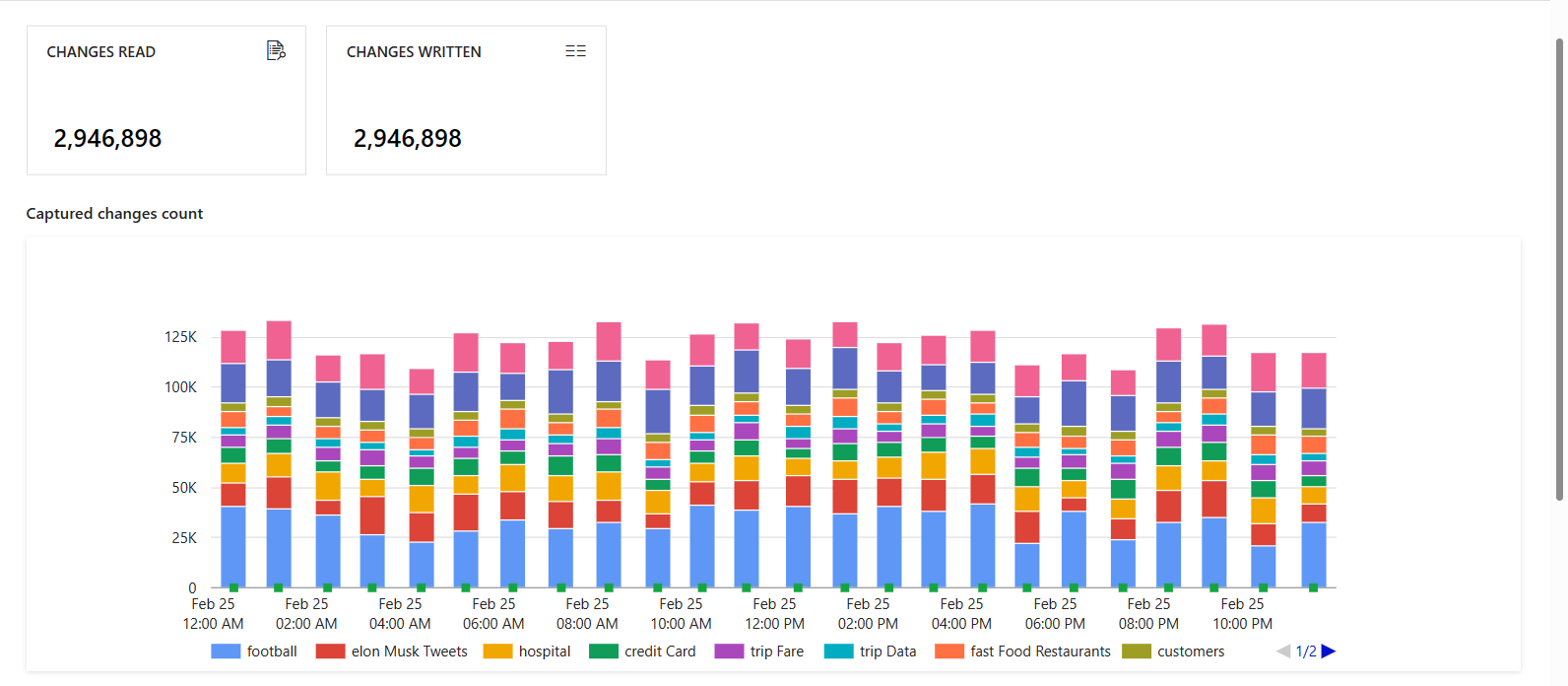
O painel Captura de Dados de Alterações mostra a Origem, o Destino, o Status e as informações Processadas pela última vez para a captura de dados de alterações.

Selecione o nome da CDA para ver mais detalhes. Você pode ver quantas alterações (inserir, atualizar ou excluir) foram lidas e gravadas, juntamente com outras informações de diagnóstico.

Se você configurar vários mapeamentos em sua captura de dados de alterações, cada mapeamento aparecerá com uma cor diferente. Selecione a barra para ver os detalhes específicos de cada mapeamento ou use as informações de diagnóstico na parte inferior do painel.