Analisar transformação em fluxo de dados de mapeamento
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Os fluxos de dados estão disponíveis nos pipelines do Azure Data Factory e do Azure Synapse. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for iniciante nas transformações, veja o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
Use a transformação Analisar para analisar colunas de texto em seus dados que são cadeias de caracteres em formato de documento. Os tipos atuais com suporte de documentos inseridos que podem ser analisados são texto JSON, XML e delimitado.
Configuração
No painel de configuração da transformação de análise, primeiro você deve escolher o tipo de dados contidos nas colunas que quer analisar embutidos. A transformação de análise também contém as seguintes definições de configuração.

Coluna
Semelhante às colunas e agregações derivadas, a propriedade Coluna é onde você modifica uma coluna existente selecionando-a no seletor suspenso. Ou você pode digitar o nome de uma nova coluna aqui. O ADF armazenará os dados de origem analisados nesta coluna. Na maioria dos casos, você quer definir uma nova coluna que analisa o campo da cadeia de caracteres do documento inserido de entrada.
Expression
Use o construtor de expressões para definir a origem da análise. Definir a origem pode ser tão simples quanto selecionar apenas a coluna de origem com os dados autocontidos que você quer analisar ou criar expressões complexas para analisar.
Expressões de exemplo
Dados da cadeia de caracteres de origem:
chrome|steel|plastic- Expressão:
(desc1 as string, desc2 as string, desc3 as string)
- Expressão:
Dados JSON de origem:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Expressão:
(level as string, registration as long)
- Expressão:
Dados JSON aninhados de origem:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Expressão:
(car as (model as string, year as integer), color as string, transmission as string)
- Expressão:
Dados XML de origem:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Expressão:
(Customers as (Customer as integer, CompanyName as string))
- Expressão:
XML de origem com os dados de atributo:
<cars><car model="camaro"><year>1989</year></car></cars>- Expressão:
(cars as (car as ({@model} as string, year as integer)))
- Expressão:
Expressões com caracteres reservados:
{ "best-score": { "section 1": 1234 } }- A expressão acima não funciona porque o caractere '-' em
best-scoreé interpretado como uma operação de subtração. Use uma variável com notação de colchetes nesses casos para dizer ao mecanismo JSON para interpretar o texto literalmente:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- A expressão acima não funciona porque o caractere '-' em
Observação: se você encontrar erros ao extrair atributos (especificamente, @model) de um tipo complexo, uma solução alternativa é converter o tipo complexo em uma cadeia de caracteres, remover o símbolo @ (especificamente, substituir(toString(toString(your_xml_string_parsed_column_name.cars.car),'@','') ) e usar a atividade de transformação JSON de análise.
Tipo de coluna de saída
Aqui é onde você configura o esquema de saída de destino da análise que é gravada em uma única coluna. A maneira mais fácil de definir um esquema para a saída da análise é selecionar o botão "Detectar tipo" no canto superior direito do construtor de expressões. O ADF tenta fazer a detecção automática do esquema do campo da cadeia de caracteres que você está analisando e definindo-o para você na expressão de saída.
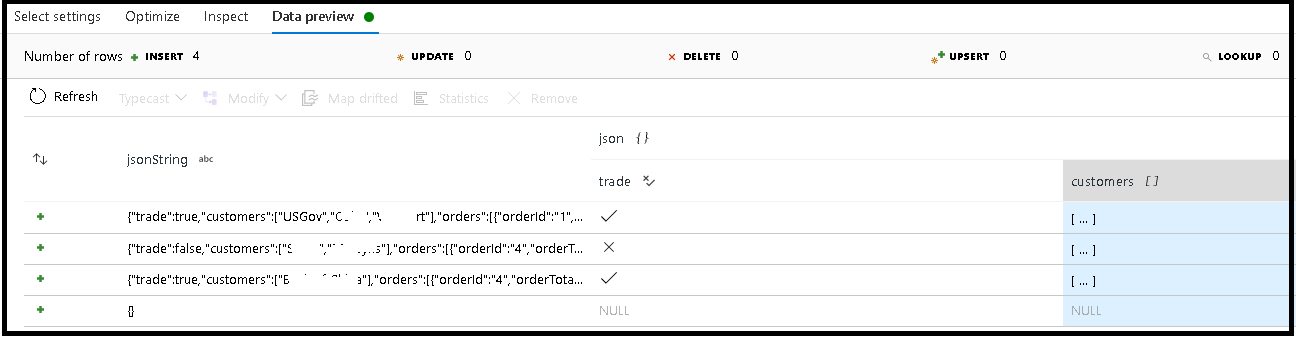
Neste exemplo, definimos a análise do campo de entrada "jsonString", que é texto sem formatação, mas formatado como uma estrutura JSON. Vamos armazenar os resultados analisados como JSON em uma nova coluna chamada "json" com este esquema:
(trade as boolean, customers as string[])
Consulte a guia de inspecionar e a visualização de dados para verificar se a saída está mapeada corretamente.
Use a atividade Coluna Derivada para extrair dados hierárquicos (ou seja, your_complex_column_name.car.model no campo de expressão)
Exemplos
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Script de fluxo de dados
Sintaxe
Exemplos
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Conteúdo relacionado
- Use a Transformação Flatten para dinamizar linhas para colunas.
- Use a Transformação de coluna derivada para transformar linhas.