Criar pipelines de cópia de dados em grande escala com abordagem controlada por metadados na ferramenta de cópia de dados
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Quando você deseja copiar grandes quantidades de objetos (por exemplo, milhares de tabelas) ou carregar dados de uma grande variedade de fontes, a abordagem apropriada é inserir a lista de nomes dos objetos com os comportamentos de cópia necessários em uma tabela de controle e, em seguida, usar pipelines parametrizados para ler os mesmos da tabela de controle e aplicá-los aos trabalhos adequadamente. Ao fazer isso, você poderá manter facilmente (por exemplo, adicionar/remover) a lista de objetos a ser copiada apenas atualizando os nomes de objeto na tabela de controle em vez de reimplantar os pipelines. Além disso, você terá um único lugar para verificar rapidamente quais objetos foram copiados por quais pipelines/gatilhos com comportamentos de cópia definidos.
A ferramenta de cópia de dados no ADF facilita o percurso de criação desses pipelines de cópia de dados orientados a metadados. Depois de passar por um fluxo intuitivo na experiência baseada em assistente, a ferramenta poderá gerar pipelines parametrizados e scripts SQL para criar tabelas de controle externos adequadamente. Após executar os scripts gerados para criar a tabela de controle no banco de dados SQL, os pipelines lerão os metadados da tabela de controle e os aplicarão automaticamente aos trabalhos de cópia.
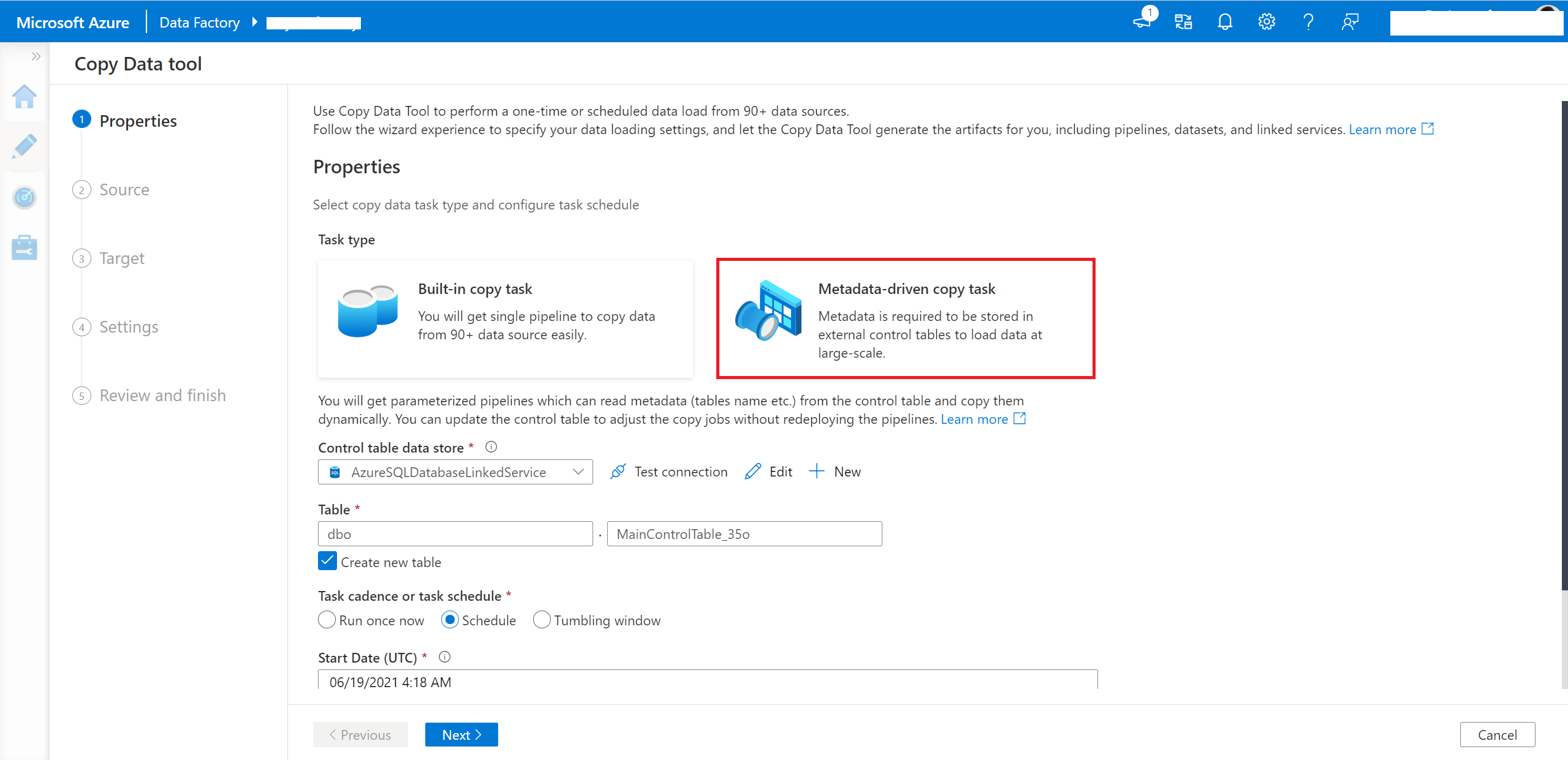
Criar trabalhos de cópia orientados a metadados na ferramenta de cópia de dados
Selecione Tarefa de cópia orientada por metadados na ferramenta de cópia de dados.
Você precisa inserir o nome da conexão e da tabela de controle para que o pipeline gerado leia os metadados dela.
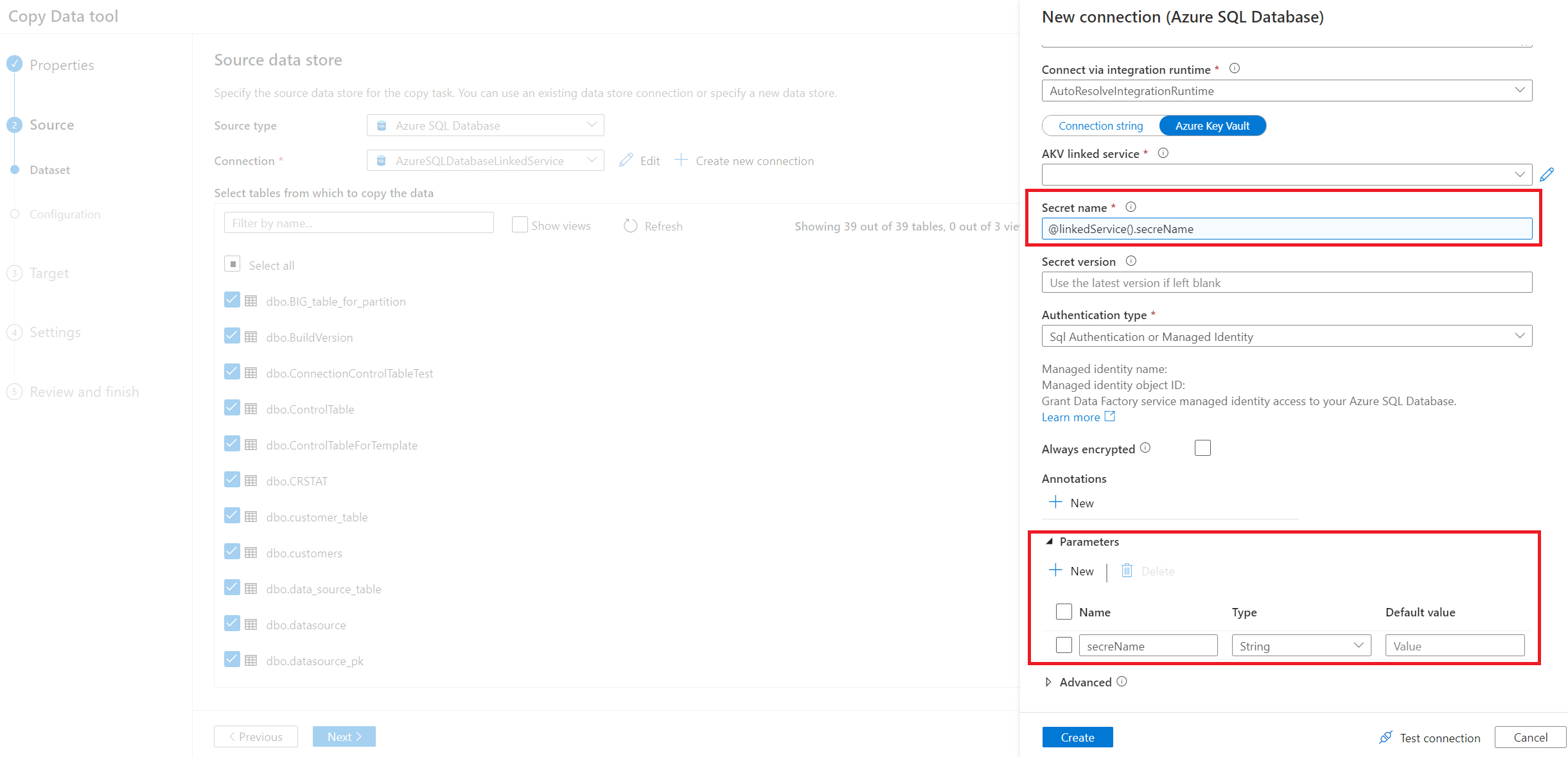
Insira a conexão do banco de dados de origem. Você também pode usar o serviço vinculado parametrizado.
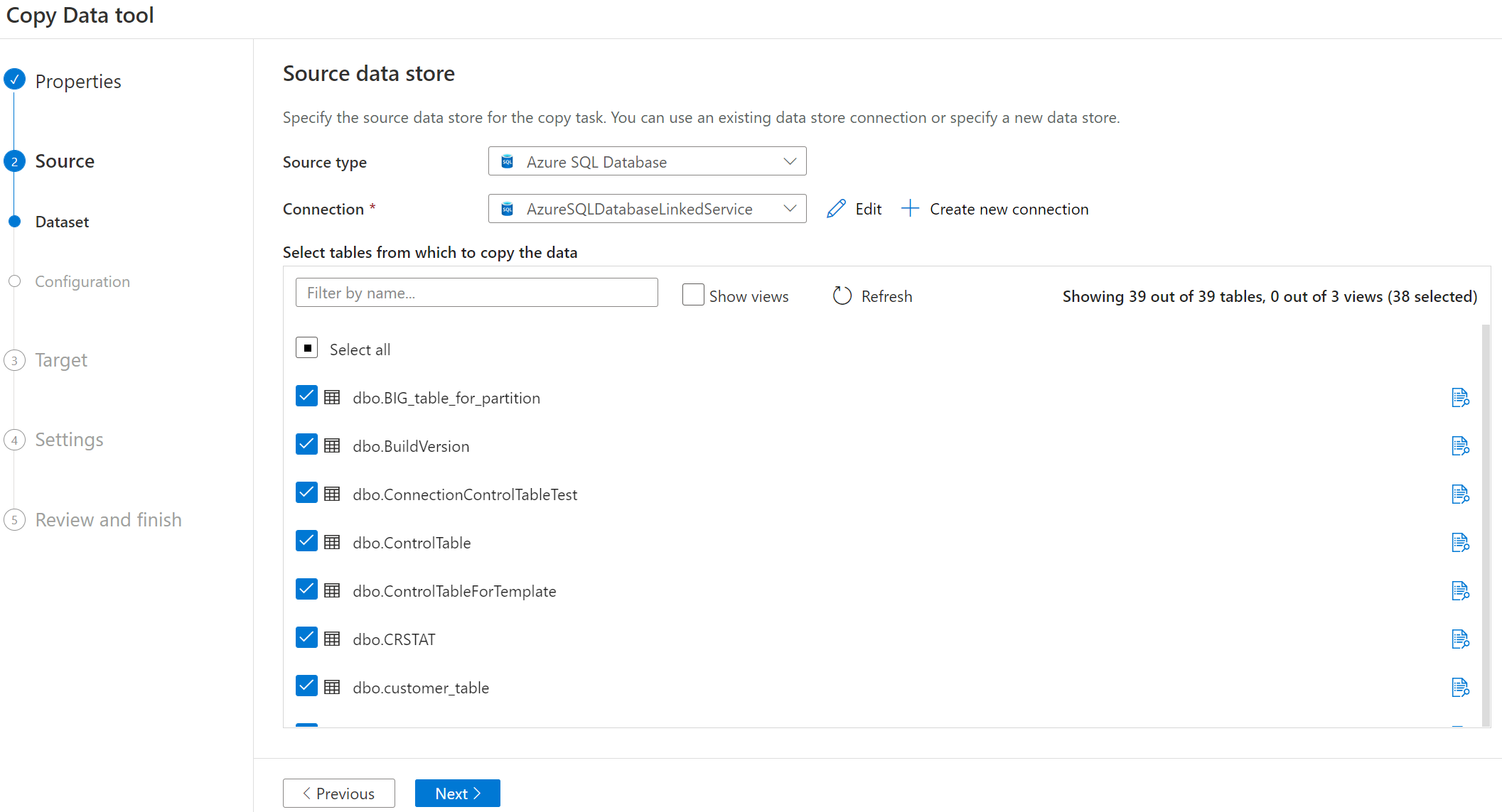
Selecione o nome da tabela a ser copiada.
Observação
Se você selecionar o armazenamento de dados tabular, ainda terá a chance de selecionar a carga completa ou a carga incremental na página seguinte. Se você selecionar o repositório de armazenamento, ainda poderá selecionar a carga completa somente na próxima página. No momento, não há suporte para o carregamento incremental de novos arquivos somente do repositório de armazenamento.
Escolha comportamento de carregamento.
Dica
Se você quiser fazer a cópia completa de todas as tabelas, selecione Carregamento completo de todas as tabelas. Se você quiser fazer uma cópia incremental, poderá selecionar configurar para cada tabela individualmente e selecionar Carga delta, bem como o nome e valor da coluna de marca d'água a ser iniciada para cada tabela.
Selecione Armazenamento de dados de destino.
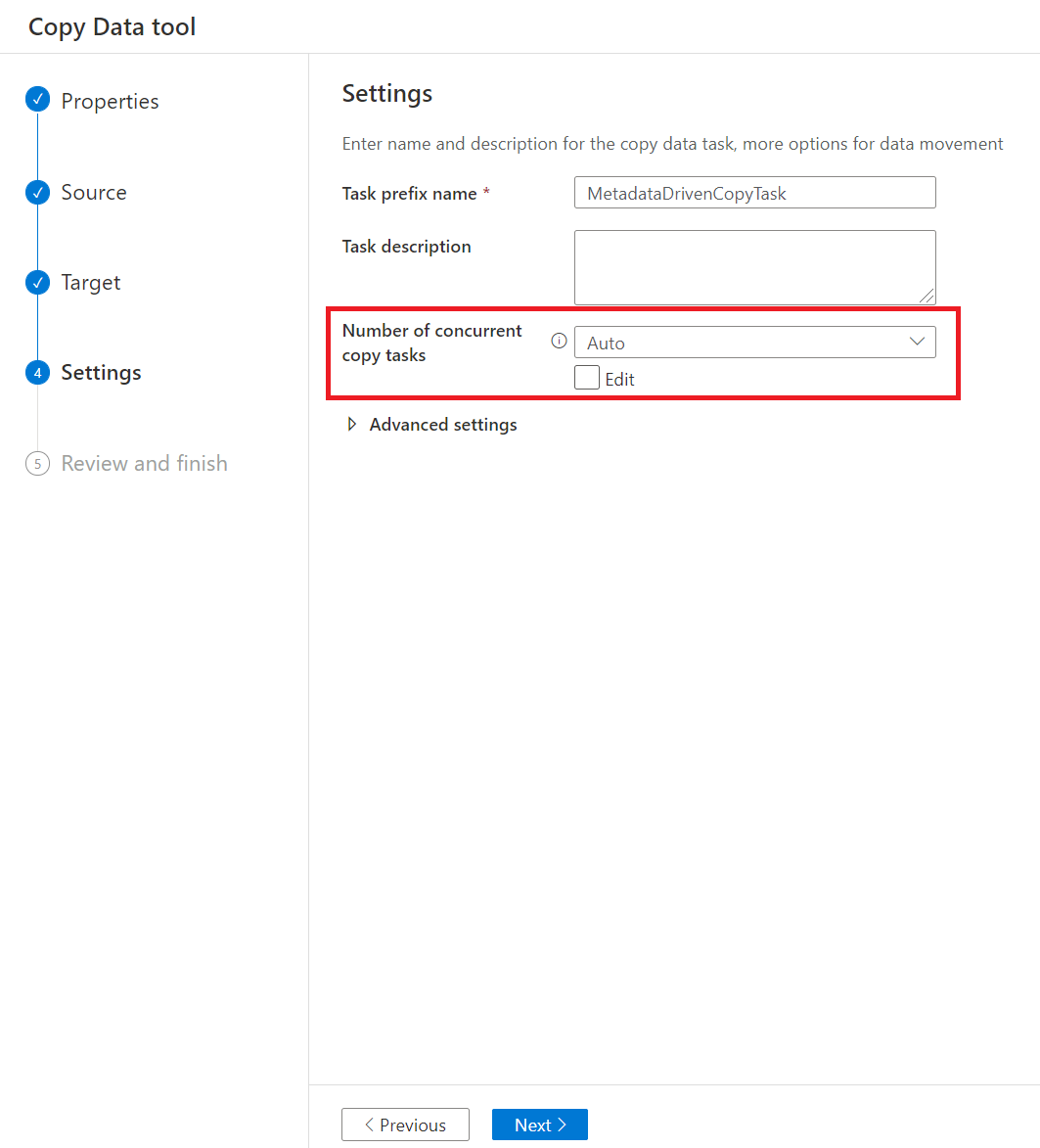
Na página Configurações, você pode decidir o número máximo de atividades de cópia para copiar dados do armazenamento de origem simultaneamente por meio do Número de tarefas de cópia simultâneas. O valor padrão é 20.
Após a implantação do pipeline, você pode copiar ou baixar os scripts SQL da interface do usuário para criar a tabela de controle e o procedimento de armazenamento.
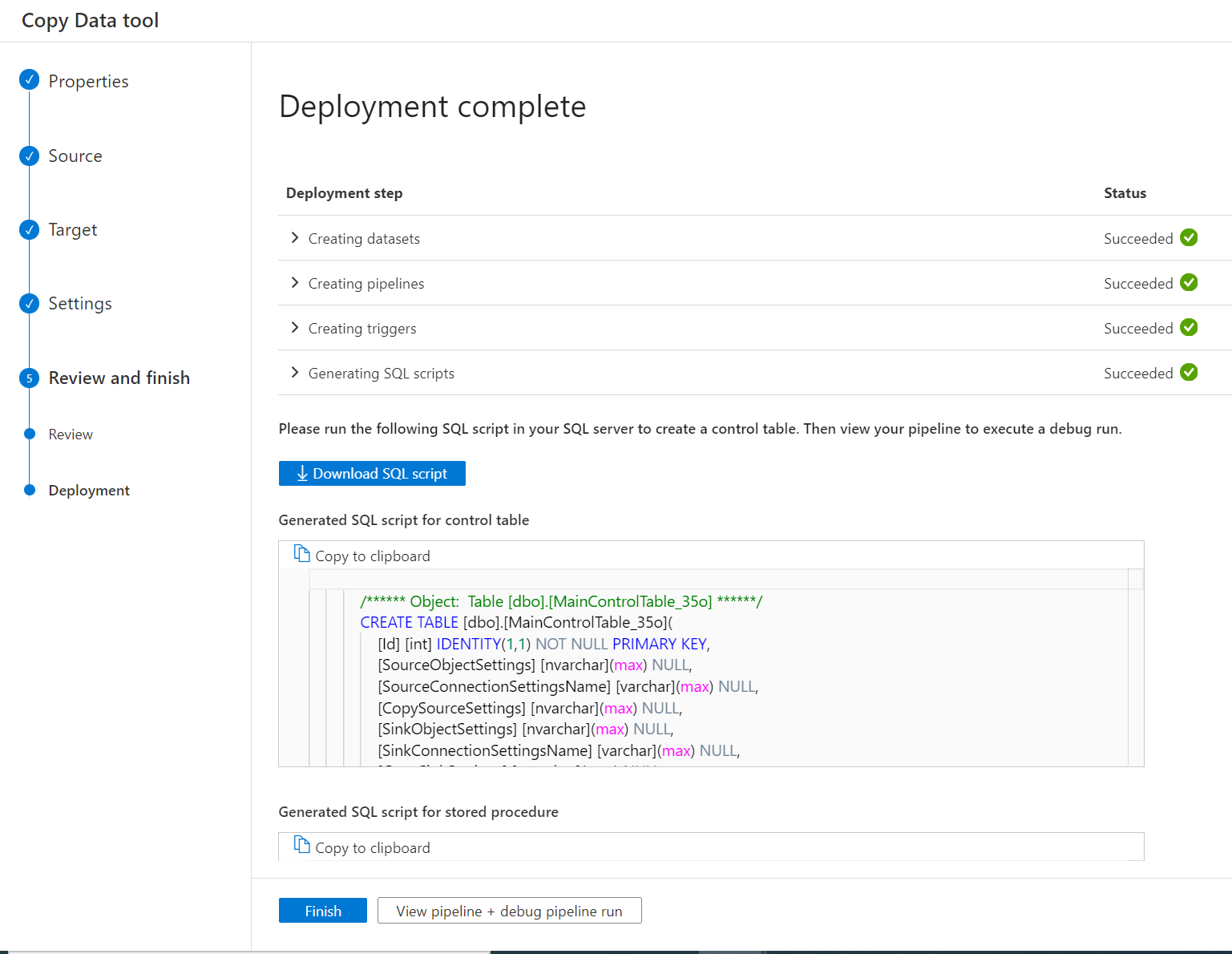
Você verá dois scripts SQL.
- O primeiro script SQL é usado para criar duas tabelas de controle. A tabela de controle principal armazena a lista de tabelas, o caminho do arquivo ou os comportamentos de cópia. A tabela de controle de conexão armazena o valor de conexão do armazenamento de dados, se você tiver usado o serviço vinculado com parâmetros.
- O segundo script SQL é usado para criar um procedimento de armazenamento. Ele será usado para atualizar o valor da marca-d'água na tabela de controle principal sempre que os trabalhos de cópia incremental forem concluídos.
Abra SSMS para se conectar ao servidor de tabela de controle e execute os dois scripts SQL para criar as tabelas de controle e o procedimento de armazenamento.
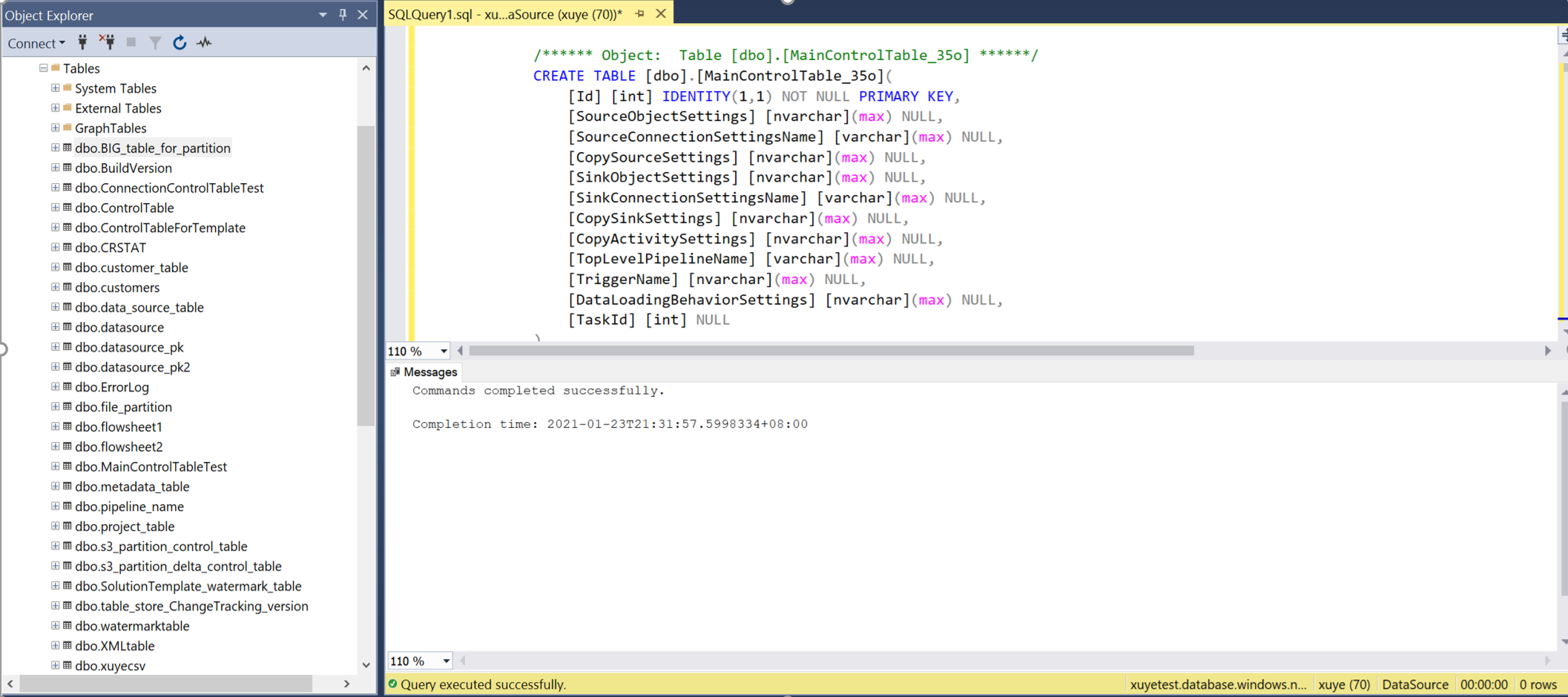
Consulte a tabela de controle principal e a tabela de controle de conexão para revisar os metadados nelas.
Tabela de controle principal
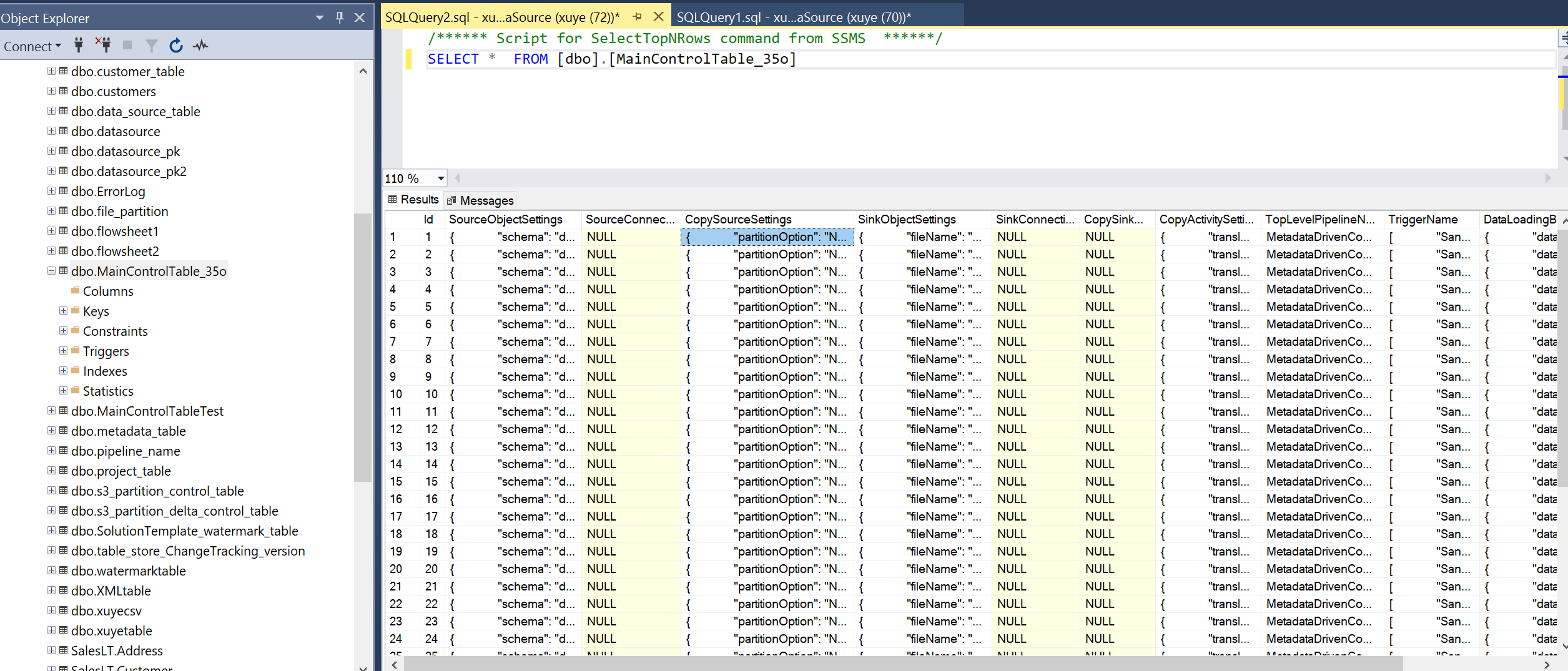
Tabela de controle de conexão

Volte ao portal do ADF para exibir e depurar os pipelines. Você verá uma pasta criada com o nome "MetadataDrivenCopyTask_### ######". Clique no pipeline e nomeie-o como "MetadataDrivenCopyTask###_TopLevel" e clique em depurar execução.
Você precisa inserir os seguintes parâmetros:
Nome dos parâmetros Description MaxNumberOfConcurrentTasks Você sempre poderá alterar o número máximo de execução de atividades de cópia simultâneas antes de executar o pipeline. O valor padrão será aquele que você inserir na ferramenta de cópia de dados. MainControlTableName Você sempre poderá alterar o nome da tabela de controle principal de modo que o pipeline obtenha os metadados dessa tabela antes da execução. ConnectionControlTableName Você sempre poderá alterar o nome da tabela de controle de conexão (opcional) de modo que o pipeline obtenha os metadados relacionados à conexão de armazenamento de dados antes da execução. MaxNumberOfObjectsReturnedFromLookupActivity Para evitar atingir o limite da atividade de pesquisa de saída, há uma maneira de definir o número máximo de objetos retornados pela atividade de pesquisa. Na maioria dos casos, o valor padrão não precisa ser alterado. windowStart Ao inserir o valor dinâmico (por exemplo, aaaa/mm/dd) como caminho da pasta, o parâmetro é usado para passar o tempo de gatilho atual do pipeline a fim de preencher o caminho da pasta dinâmica. Quando o pipeline é acionado por um gatilho de agendamento ou gatilho periódico, os usuários não precisam inserir o valor desse parâmetro. Valor de exemplo: 2021-01-25T01:49:28Z Habilite o gatilho para operacionalizar os pipelines.
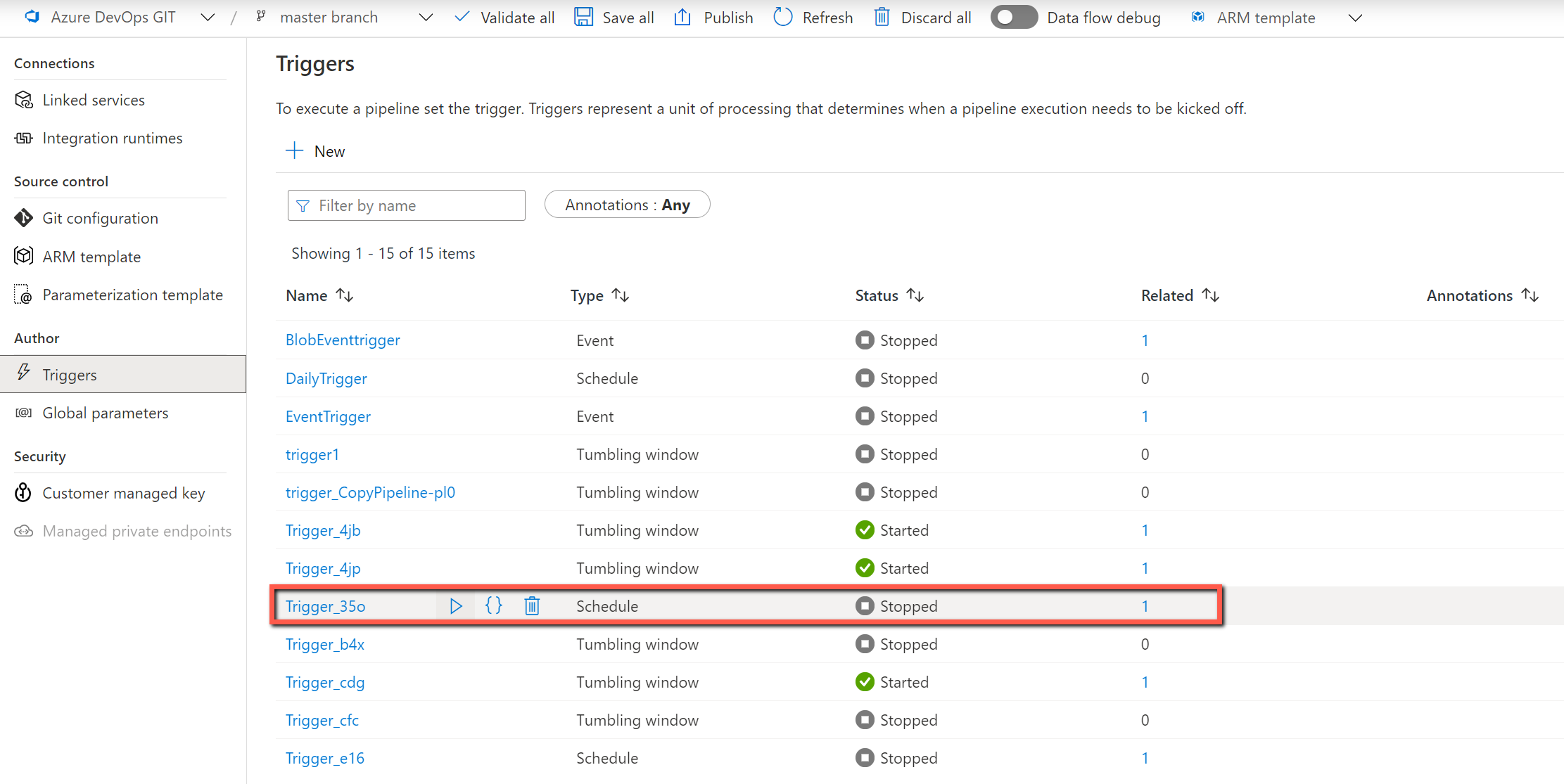
Atualizar a tabela de controle pela ferramenta de cópia de dados
Você sempre pode atualizar diretamente a tabela de controle adicionando ou removendo o objeto a ser copiado ou alterando o comportamento de cópia de cada tabela. Também criamos a experiência de interface do usuário na ferramenta de cópia de dados para facilitar o percurso de edição da tabela de controle.
Clique com o botão direito do mouse no pipeline de nível superior: MetadataDrivenCopyTask_xxx_TopLevel e selecione Editar tabela de controle.
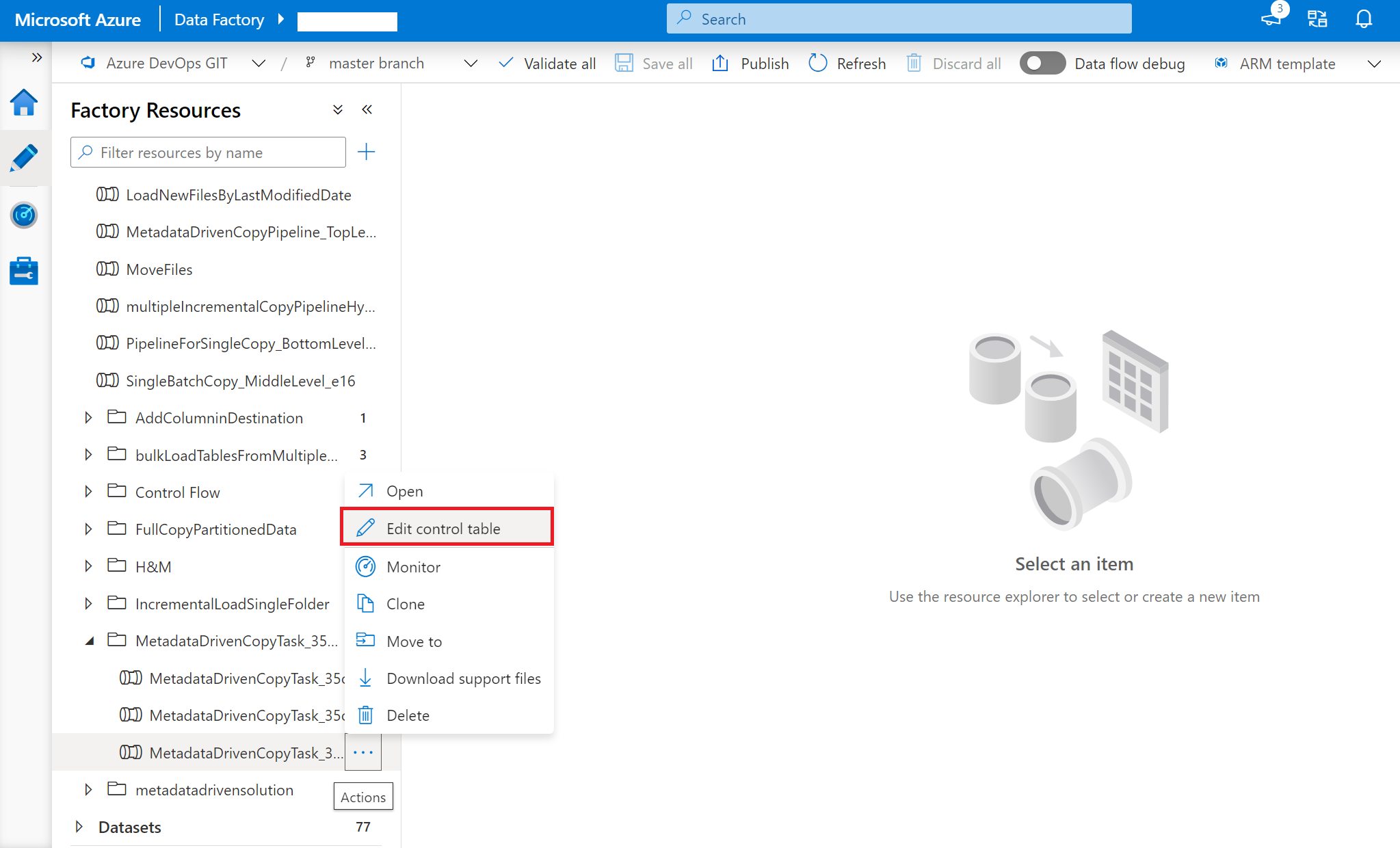
Selecione as linhas na tabela de controle a ser editada.
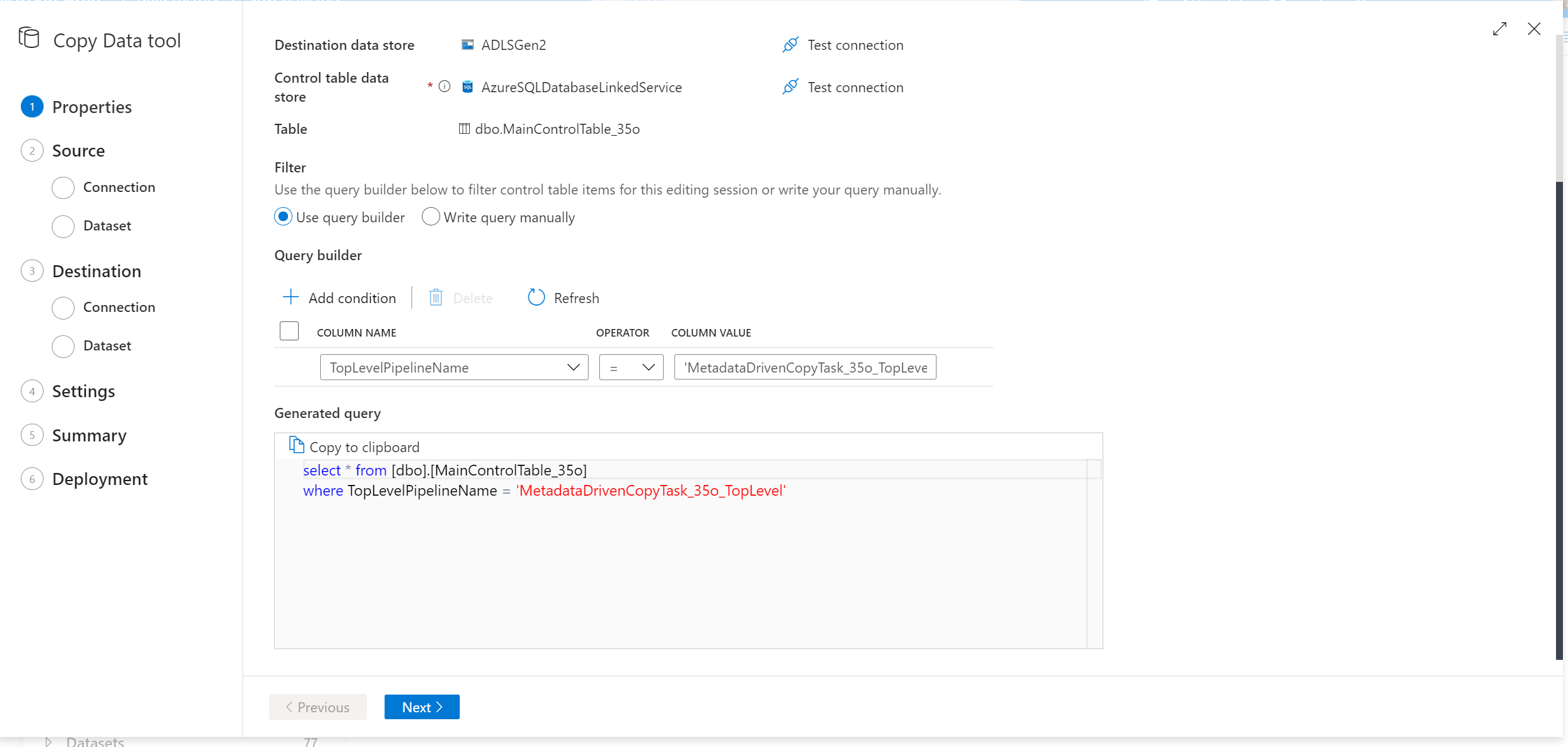
Acesse a taxa de transferência da ferramenta de cópia de dados e tenha um novo script SQL para você. Execute novamente o script SQL para atualizar a tabela de controle.
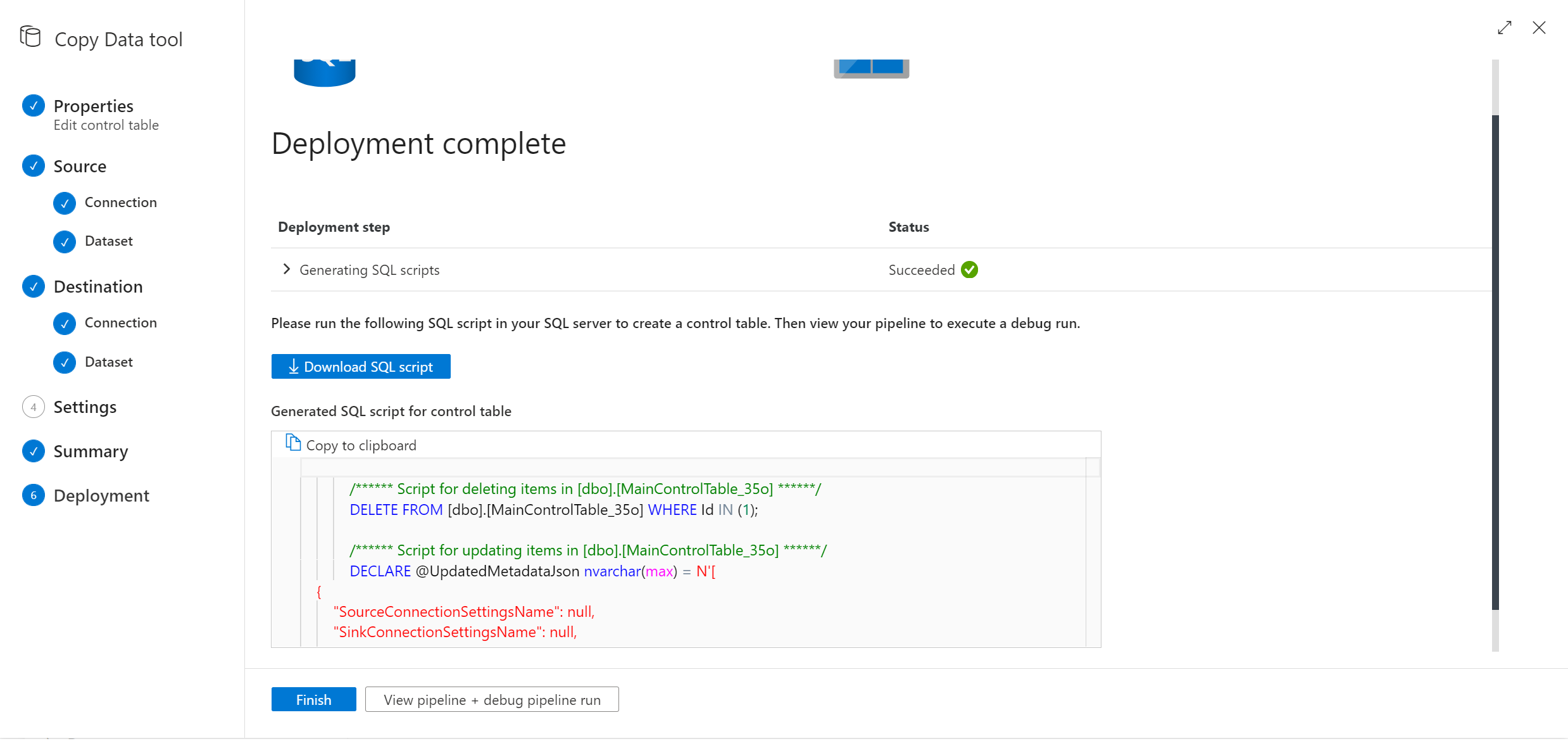
Observação
O pipeline NÃO será reimplantado. O novo script SQL criado ajuda você a atualizar somente a tabela de controle.
Tabelas de controle
Tabela de controle principal
Cada linha na tabela de controle contém os metadados de um objeto (por exemplo, uma tabela) a ser copiado.
| Nome da coluna | Descrição |
|---|---|
| ID | ID exclusiva do objeto a ser copiado. |
| SourceObjectSettings | Metadados do conjuntos de dados de origem. Pode ser um nome de esquema, nome de tabela etc. Aqui está um exemplo. |
| SourceConnectionSettingsName | O nome da configuração de conexão de origem na tabela de controle de conexão. É opcional. |
| CopySourceSettings | Metadados da propriedade de origem na atividade de cópia. Pode ser uma consulta, partições etc. Aqui está um exemplo. |
| SinkObjectSettings | Metadados do conjuntos de dados de destino. Pode ser um nome de arquivo, caminho da pasta, nome de tabela etc. Aqui está um exemplo. Se o caminho da pasta dinâmica for especificado, o valor da variável não será gravado aqui na tabela de controle. |
| SinkConnectionSettingsName | O nome da configuração de conexão de destino na tabela de controle de conexão. É opcional. |
| CopySinkSettings | Metadados da propriedade de coleta na atividade de cópia. Pode ser preCopyScript, tableOption etc. Aqui está um exemplo. |
| CopyActivitySettings | Metadados da propriedade de tradução na atividade de cópia. Ele é usado para definir o mapeamento da coluna. |
| TopLevelPipelineName | O nome do pipeline superior que pode copiar esse objeto. |
| TriggerName | O nome do gatilho que pode acionar o pipeline para copiar esse objeto. Se a depuração for executada, o nome será Área restrita. Se a execução for manual, o nome será Manual. Se a execução for agendada, o nome será associado ao nome do gatilho. Ele pode receber vários nomes. |
| DataLoadingBehaviorSettings | Carga completa versus carga delta. |
| TaskId | A ordem dos objetos a serem copiados após a TaskId na tabela de controle (ORDER BY [TaskId] DESC). Se você tiver uma grande quantidade de objetos a serem copiados, mas apenas um número limitado de cópias simultâneas permitidas, você poderá alterar o TaskId de cada objeto para decidir quais objetos podem ser copiados mais cedo. O valor padrão é 0. |
| CopyEnabled | Especifique se o item está habilitado no processo de ingestão de dados. Valores permitidos: 1 (habilitado), 0 (desabilitado). O valor padrão é 1. |
Tabela de controle de conexão
Cada linha na tabela de controle contém uma configuração de conexão para o armazenamento de dados.
| Nome da coluna | Descrição |
|---|---|
| Name | Nome da conexão parametrizada na tabela de controle principal. |
| ConnectionSettings | As configurações de conexão. Pode ser Nome do BD, Nome do servidor e assim por diante. |
Pipelines
Você verá que três níveis de pipelines são gerados pela ferramenta de cópia de dados.
MetadataDrivenCopyTask_xxx_TopLevel
Esse pipeline calculará o número total de objetos (tabelas etc.) necessários a serem copiado nesta execução, apresentará o número de lotes sequenciais com base na tarefa de cópia simultânea máxima permitida e, em seguida, executará outro pipeline para copiar lotes diferentes em sequência.
Parâmetros
| Nome dos parâmetros | Description |
|---|---|
| MaxNumberOfConcurrentTasks | Você sempre poderá alterar o número máximo de execução de atividades de cópia simultâneas antes de executar o pipeline. O valor padrão será aquele que você inserir na ferramenta de cópia de dados. |
| MainControlTableName | O nome da tabela de controle principal. O pipeline obterá os metadados desta tabela antes da execução |
| ConnectionControlTableName | O nome da tabela de controle de conexão (opcional). O pipeline obterá os metadados relacionados à conexão do armazenamento de dados antes da execução |
| MaxNumberOfObjectsReturnedFromLookupActivity | Para evitar atingir o limite da atividade de pesquisa de saída, há uma maneira de definir o número máximo de objetos retornados pela atividade de pesquisa. Na maioria dos casos, o valor padrão não precisa ser alterado. |
| windowStart | Ao inserir o valor dinâmico (por exemplo, aaaa/mm/dd) como caminho da pasta, o parâmetro é usado para passar o tempo de gatilho atual do pipeline a fim de preencher o caminho da pasta dinâmica. Quando o pipeline é acionado por um gatilho de agendamento ou gatilho periódico, os usuários não precisam inserir o valor desse parâmetro. Valor de exemplo: 2021-01-25T01:49:28Z |
Atividades
| Nome da atividade | Tipo de atividade | Descrição |
|---|---|---|
| GetSumOfObjectsToCopy | Pesquisa | Calcula o número total de objetos (tabelas etc.) necessários para serem copiados nesta execução. |
| CopyBatchesOfObjectsSequentially | ForEach | Apresenta o número de lotes sequenciais com base no máximo permitido de tarefas de cópia simultâneas e executa outro pipeline para copiar lotes diferentes em sequência. |
| CopyObjectsInOneBtach | Execute Pipeline | Execute outro pipeline para copiar um lote de objetos. Os objetos pertencentes a esse lote serão copiados em paralelo. |
MetadataDrivenCopyTask_xxx_ MiddleLevel
Esse pipeline copiará um lote de objetos. Os objetos pertencentes a esse lote serão copiados em paralelo.
Parâmetros
| Nome dos parâmetros | Description |
|---|---|
| MaxNumberOfObjectsReturnedFromLookupActivity | Para evitar atingir o limite da atividade de pesquisa de saída, há uma maneira de definir o número máximo de objetos retornados pela atividade de pesquisa. Na maioria dos casos, o valor padrão não precisa ser alterado. |
| TopLevelPipelineName | O nome do pipeline da camada superior. |
| TriggerName | O nome do gatilho. |
| CurrentSequentialNumberOfBatch | A ID do lote sequencial. |
| SumOfObjectsToCopy | O número total de objetos a serem copiados. |
| SumOfObjectsToCopyForCurrentBatch | O número de objetos a serem copiados no lote atual. |
| MainControlTableName | O nome da tabela de controle principal. |
| ConnectionControlTableName | O nome da tabela de controle de conexão. |
Atividades
| Nome da atividade | Tipo de atividade | Descrição |
|---|---|---|
| DivideOneBatchIntoMultipleGroups | ForEach | Divide os objetos de um único lote em vários grupos paralelos para evitar atingir o limite de saída da atividade de pesquisa. |
| GetObjectsPerGroupToCopy | Pesquisa | Obtém objetos (tabelas etc.) da tabela de controle necessários para serem copiados nesse grupo. A ordem dos objetos a serem copiados após a TaskId na tabela de controle (ORDER BY [TaskId] DESC). |
| CopyObjectsInOneGroup | Execute Pipeline | Executa outro pipeline para copiar os objetos de um grupo. Os objetos que pertencem a esse grupo serão copiados em paralelo. |
MetadataDrivenCopyTask_xxx_ BottomLevel
Esse pipeline copiará objetos de um grupo. Os objetos que pertencem a esse grupo serão copiados em paralelo.
Parâmetros
| Nome dos parâmetros | Description |
|---|---|
| ObjectsPerGroupToCopy | O número de objetos a serem copiados no grupo atual. |
| ConnectionControlTableName | O nome da tabela de controle de conexão. |
| windowStart | Ele costumava enviar o tempo de gatilho atual para o pipeline para preencher o caminho da pasta dinâmica, se configurado pelo usuário. |
Atividades
| Nome da atividade | Tipo de atividade | Descrição |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | Lista os objetos de um grupo e faz a iteração de cada um deles para atividades downstream. |
| RouteJobsBasedOnLoadingBehavior | Comutador | Verifica o comportamento de carregamento de cada objeto. Se for o caso padrão ou FullLoad, faça a carga completa. Se for o caso DeltaLoad, faça a carga incremental por meio da coluna de marca-d'água para identificar as alterações |
| FullLoadOneObject | Copiar | Tira um instantâneo completo nesse objeto e o copia para o destino. |
| DeltaLoadOneObject | Copiar | Copia os dados alterados somente da última vez comparando o valor na coluna de marca-d'água para identificar as alterações. |
| GetMaxWatermarkValue | Pesquisa | Consulta o objeto de origem para obter o valor máximo da coluna de marca-d'água. |
| UpdateWatermarkColumnValue | StoreProcedure | Escreve novamente o novo valor de marca-d'água n tabela de controle a ser usada na próxima vez. |
Limitações conhecidas
- O nome do IR, tipo de banco de dados, tipo de formato de arquivo não podem ser parametrizados no ADF. Por exemplo, se você quiser ingerir dados do Oracle Server e SQL Server, precisará de dois pipelines parametrizados diferentes. Mas a tabela de controle única pode ser compartilhada por dois conjuntos de pipelines.
- O OPENJSON é usado nos scripts SQL gerados pela ferramenta de cópia de dados. Se você estiver usando o SQL Server para hospedar a tabela de controle, deve ser o SQL Server 2016 (13.x) e posterior para dar suporte à função OPENJSON.
Conteúdo relacionado
Experimente estes tutoriais que usam a ferramenta Copiar Dados: