Otimização de fontes
Para cada origem, exceto o Banco de Dados SQL do Azure, é recomendável continuar a Usar o particionamento atual como o valor selecionado. Ao realizar leituras de todos os outros sistemas de origem, os fluxos de dados realizam a partição automática e uniforme dos dados com base no tamanho dos dados. Uma nova partição é criada para aproximadamente cada 128 MB de dados. À medida que o tamanho dos dados aumenta, aumenta o número de partições.
Um particionamento personalizado acontece depois que o Spark faz a leitura dos dados e afeta negativamente o desempenho do fluxo de dados. Como os dados são particionados uniformemente na leitura, isso não é recomendável, a menos que antes você entenda a forma e a cardinalidade dos dados.
Observação
As velocidades de leitura podem ser limitadas pela taxa de transferência do sistema de origem.
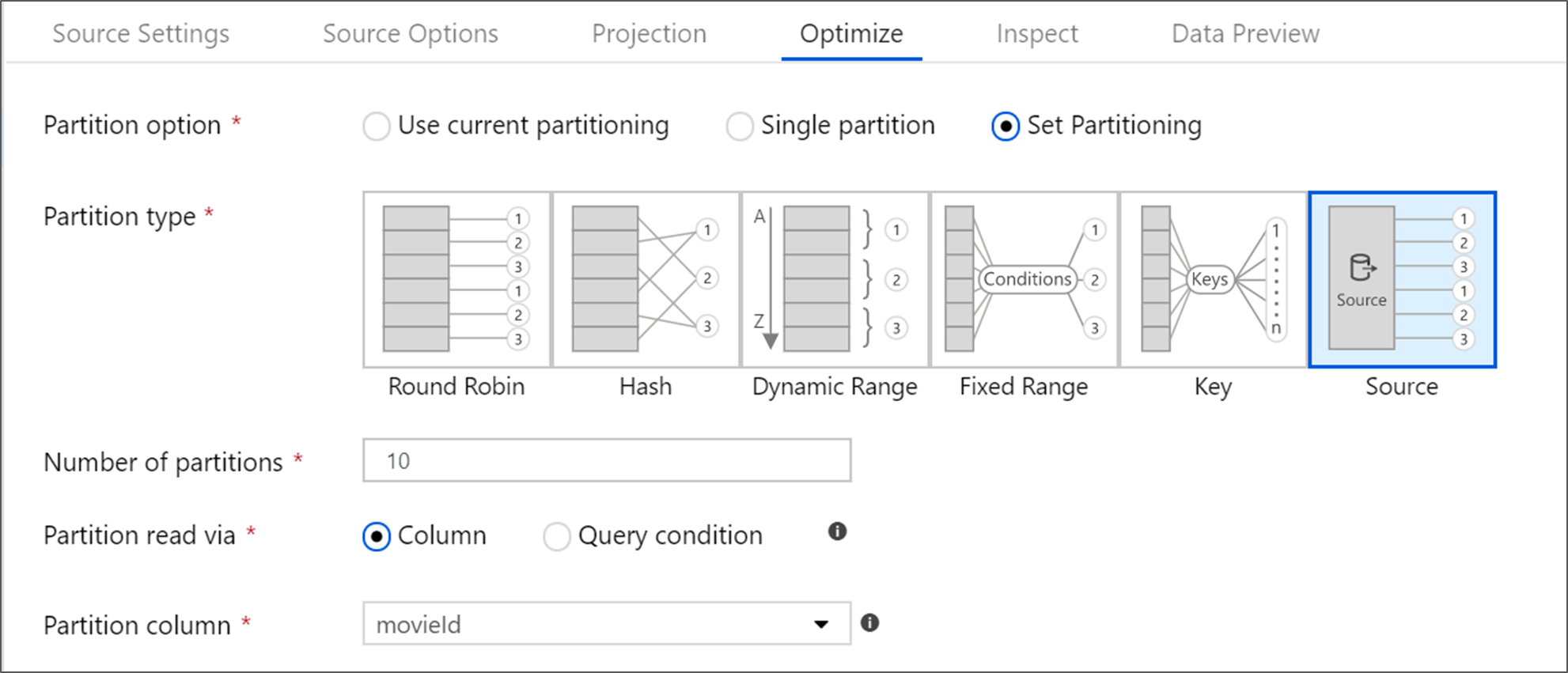
Fontes do Banco de Dados SQL do Azure
O Banco de Dados SQL do Azure tem uma opção de particionamento exclusiva, chamada particionamento de "Origem". Habilitar o particionamento de origem pode melhorar seu tempo de leitura do Banco de dados SQL do Azure, habilitando conexões paralelas no sistema de origem. Especifique o número de partições e como particionar seus dados. Use uma coluna de partição com alta cardinalidade. Você também pode inserir uma consulta que corresponda ao esquema de particionamento da tabela de origem.
Dica
Para o particionamento de origem, a E/S do SQL Server é o gargalo. Adicionar muitas partições pode saturar o banco de dados de origem. Geralmente, o ideal ao usar essa opção são quatro ou cinco partições.
Nível de Isolamento
O nível de isolamento da leitura em um sistema de origem do SQL do Azure impacta no desempenho. Selecionar "Leitura não confirmada" fornece o desempenho mais rápido e evita um bloqueio de banco de dados. Para saber mais sobre os níveis de isolamento do SQL, consulte Noções básicas sobre níveis de isolamento.
Leitura usando consulta
Você pode ler no Banco de Dados SQL do Azure usando uma tabela ou uma consulta SQL. Se você estiver executando uma consulta SQL, ela deverá ser concluída antes que a transformação possa ser iniciada. As consultas SQL podem ser úteis para aplicar operações que podem ser executadas mais rapidamente e reduzir a quantidade de dados lidos de um SQL Server como as instruções SELECT, WHERE e JOIN. Ao transferir operações, você perde a capacidade de controlar a linhagem e o desempenho das transformações antes que os dados cheguem ao fluxo de dados.
Origens do Azure Synapse Analytics
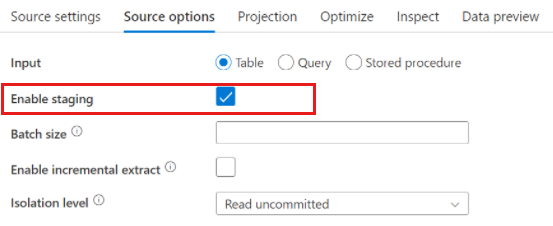
Ao usar o Azure Synapse Analytics, as opções de origem apresentam uma configuração chamada Habilitar preparo. Isso permite que o serviço leia o Synapse usando o Staging, que melhora muito o desempenho de leitura usando a funcionalidade de carregamento em massa de melhor desempenho, como os comandos CETAS e COPY. Habilitar Staging requer que você especifique um Armazenamento de Blobs do Azure ou uma localização de preparo do Azure Data Lake Storage gen2 nas configurações de atividade do fluxo de dados.
Origens baseadas em arquivo
Parquet versus texto delimitado
Embora os fluxos de dados ofereçam suporte a uma variedade de tipos de arquivo, o formato Parquet nativo do Spark é recomendado para obter tempos ideais de leitura e gravação.
Ao executar o mesmo fluxo de dados em um conjunto de arquivos, recomendamos a leitura de uma pasta, o uso de um caminho curinga ou a leitura de uma lista de arquivos. Uma execução de atividade de fluxo de dados única pode processar todos os arquivos do lote. Mais informações sobre como definir essas configurações podem ser encontradas na seção Transformação da fonte da documentação do Conector do Armazenamento de Blobs do Azure.
Se possível, evite usar a atividade For-Each para executar fluxos de dados em um conjunto de arquivos. Isso faz com que cada iteração do for-each crie o próprio cluster Spark, que geralmente não é necessário e pode ser caro.
Conjuntos de dados embutidos versus conjuntos de dados compartilhados
Os conjuntos de dados do ADF e do Synapse são recursos compartilhados em suas fábricas e workspaces. No entanto, ao ler um grande número de pastas e arquivos de origem com texto delimitado e fontes JSON, você pode melhorar o desempenho da descoberta de arquivos de fluxo de dados definindo a opção "Esquema projetado pelo usuário" dentro da Projeção | Caixa de diálogo opções de esquema. Essa opção desativa a descoberta automática de esquema padrão do ADF e melhora muito o desempenho da descoberta de arquivo. Antes de definir essa opção, importe a projeção para que o ADF tenha um esquema existente para projeção. Essa opção não funciona com descompasso de esquema.
Conteúdo relacionado
- Visão geral do desempenho do fluxo de dados
- Otimização de coletores
- Otimização de transformações
- Uso de fluxos de dados nos pipelines
Consulte outros artigos sobre Fluxo de Dados relacionados ao desempenho: