Visão geral de continuidade dos negócios e recuperação de desastres
A continuidade dos negócios e recuperação de desastres no Azure Data Explorer permitem que sua empresa continue operando diante de uma interrupção. Este artigo discute a disponibilidade (intrarregional) e a recuperação de desastre. Ele detalha as funcionalidades nativas e as considerações de arquitetura para uma implantação resiliente do Azure Data Explorer. Ele detalha a recuperação de erros humanos, a alta disponibilidade, bem como várias configurações de recuperação de desastre. Essas configurações dependem de requisitos de resiliência, como RPO (objetivo de ponto de recuperação) e RTO (objetivo de tempo de recuperação), esforço necessário e custo.
Atenuar eventos de interrupção
- Erro humano
- Alta disponibilidade do Azure Data Explorer
- Paralisação de uma zona de disponibilidade do Azure
- Paralisação de um datacenter do Azure
- Paralisação de uma região do Azure
Erro humano
Erros humanos são inevitáveis. Os usuários podem acidentalmente remover um cluster, um banco de dados ou uma tabela.
Exclusão acidental de cluster ou banco de dados
A exclusão acidental de um cluster ou banco de dados é uma ação irrecuperável. Como o proprietário do recurso do Azure Data Explorer, você pode evitar a perda de dados habilitando a funcionalidade de bloqueio de exclusão, disponível no nível de recurso do Azure.
Exclusão acidental de tabela
Os usuários com permissões de administrador de tabela ou superior têm permissão para remover tabelas. Se um desses usuários remove acidentalmente uma tabela, você pode recuperá-la usando o comando .undo drop table. Para que esse comando seja bem-sucedido, você deve primeiro habilitar a propriedade capacidade de recuperação na política de retenção.
Exclusão acidental de tabela externa
Tabelas externas são entidades do esquema de consulta do Azure Data Explorer que fazem referência a dados armazenados fora do banco de dados. A exclusão de uma tabela externa exclui apenas os metadados da tabela. Você pode recuperá-la executando novamente o comando de criação de tabela. Use a funcionalidade de exclusão temporária para proteger contra exclusão acidental ou sobrescrever um arquivo/blob por um período de tempo configurado pelo usuário.
Alta disponibilidade do Azure Data Explorer
Alta disponibilidade refere-se à tolerância do Azure Data Explorer a falhas, aos componentes dele e às dependências subjacentes em uma região do Azure. Essa tolerância a falhas evita SPOF (pontos individuais de falha) na implementação. No Azure Data Explorer, a alta disponibilidade inclui a camada de persistência, a camada de computação e uma configuração de líder/seguidor.
Camada de persistência
O Azure Data Explorer aproveita o Armazenamento do Azure como a própria camada de persistência durável. O Armazenamento do Azure fornece automaticamente tolerância a falhas, com a configuração padrão oferecendo LRS (armazenamento com redundância local) em um data center. Três réplicas são persistentes. Se uma réplica for perdida durante o uso, outra será implantada sem interrupção. É possível obter mais resiliência com o ZRS (armazenamento com redundância de zona), que coloca réplicas de maneira inteligente entre zonas de disponibilidade regionais do Azure, proporcionando tolerância máxima a falhas a um custo adicional. O armazenamento habilitado para ZRS é configurado automaticamente quando o cluster do Azure Data Explorer é implantado em Zonas de Disponibilidade.
Camada de computação
O Azure Data Explorer é uma plataforma de computação distribuída e pode ter de dois a muitos nós, dependendo do tipo de função de nó e escala. No momento do provisionamento, selecione zonas de disponibilidade para distribuir a implantação do nó entre zonas, proporcionando o máximo de resiliência entre regiões. Uma falha de zona de disponibilidade não resultará em uma falha completa, mas na degradação do desempenho até a recuperação da zona.
Configuração de cluster de líder/seguidor
O Azure Data Explorer fornece uma funcionalidade opcional de seguidor para um cluster líder ser seguido por outros clusters seguidores para acesso somente leitura aos dados e metadados do líder. As alterações no líder, como create, append e drop, são sincronizadas automaticamente com o seguidor. Embora os líderes possam abranger regiões do Azure, os clusters seguidores devem ser hospedados nas mesmas regiões que o líder. Se o cluster líder estiver inativo ou bancos de dados ou tabelas forem removidas acidentalmente, os clusters seguidores perderão o acesso até que o acesso seja recuperado no líder.
Paralisação de uma zona de disponibilidade do Azure
As zonas de disponibilidade do Azure são localizações físicas exclusivas na mesma região do Azure. Elas podem proteger a computação e os dados de um cluster do Azure Data Explorer de falha parcial na região. A falha de zona é um cenário de disponibilidade, pois é dentro da região.
Fixe um cluster do Azure Data Explorer na mesma zona que outros recursos conectados do Azure. Para obter mais informações sobre como habilitar zonas de disponibilidade, confira criar um cluster.
Observação
A implantação em zonas de disponibilidade é possível ao criar um cluster ou pode ser migrada posteriormente.
Paralisação de um datacenter do Azure
As zonas de disponibilidade do Azure têm um custo e alguns clientes optam por implantar sem redundância zonal. Com essa implantação do Azure Data Explorer, uma paralisação do datacenter do Azure resultará em uma paralisação de cluster. Lidar com uma paralisação do datacenter do Azure é, portanto, idêntico a lidar com a paralisação de uma região do Azure.
Paralisação de uma região do Azure
O Azure Data Explorer não fornece proteção automática contra a paralisação de toda a região do Azure. Para minimizar o impacto nos negócios se houver essa paralisação, mantenha vários clusters do Azure Data Explorer entre regiões emparelhadas do Azure. Com base em seu RTO (objetivo de tempo de recuperação), RPO (objetivo de ponto de recuperação), bem como considerações sobre esforço e custo, há várias configurações de recuperação de desastre. Otimizações de custo e desempenho são possíveis com as recomendações do Assistente do Azure e a configuração de dimensionamento automático.
Configurações de recuperação de desastre
Esta seção detalha várias configurações de recuperação de desastre, dependendo dos requisitos de resiliência (RPO e RTO), esforço necessário e custo.
O RTO (objetivo de tempo de recuperação) refere-se ao tempo de recuperação de uma interrupção. Por exemplo, um RTO de duas horas significa que o aplicativo precisa estar em funcionamento dentro de duas horas após uma interrupção. RPO (objetivo de ponto de recuperação) refere-se ao intervalo de tempo que pode passar durante uma interrupção antes que a quantidade de dados perdidos durante esse período seja maior que o limite permitido. Por exemplo, se o RPO for de 24 horas e um aplicativo tiver dados gravados desde 15 anos atrás, eles ainda estarão dentro dos parâmetros do RPO combinado.
Os processos de ingestão, processamento e coleta precisam de design cuidadoso antecipado ao planejar para a recuperação de desastre. Ingestão refere-se a dados integrados ao Azure Data Explorer de várias fontes; processamento refere-se a transformações e atividades semelhantes; coleta refere-se a exibições materializadas, exportações para o data lake e assim por diante.
A seguir estão as configurações de recuperação de desastre populares, cada uma delas é descrita em detalhes abaixo.
- Configuração ativo/ativo/ativo (sempre ativo)
- Configuração ativo/ativo
- Configuração ativo/espera ativa
- Configuração de cluster de recuperação de dados sob demanda
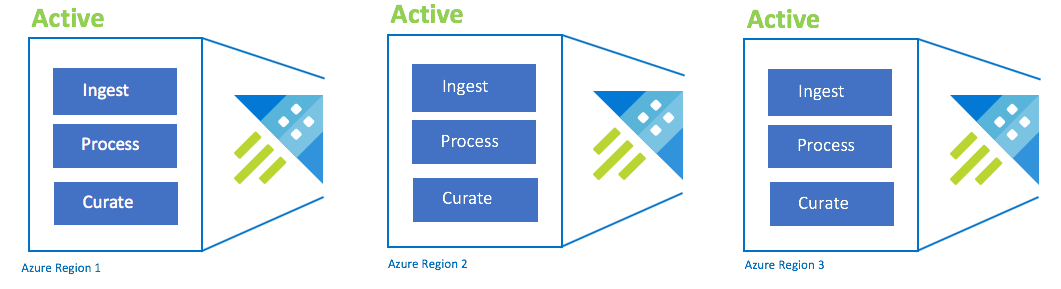
Configuração ativo/ativo/ativo
Essa configuração também é chamada de "always-on". Para implantações críticas de aplicativos sem tolerância a falhas, você deve usar vários clusters do Azure Data Explorer em regiões emparelhadas do Azure. Configure a ingestão, o processamento e a coleta em paralelo para todos os clusters. O SKU do cluster precisa ser o mesmo entre regiões. O Azure garantirá que as atualizações sejam distribuídas e escalonadas entre regiões emparelhadas do Azure. Uma paralisação de região do Azure não causará uma paralisação de aplicativo. Você poderá experimentar alguma latência ou degradação de desempenho.
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Ativo/ativo/ativo/n | 0 horas | 0 horas | Inferior | O mais alto |
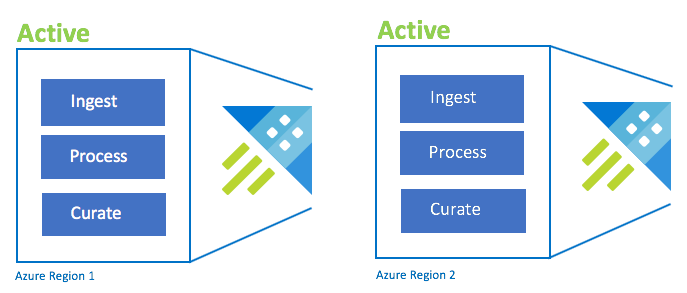
Configuração ativo/ativo
Essa configuração é idêntica à configuração ativo/ativo/ativo, mas envolve apenas duas regiões emparelhadas do Azure. Configure ingestão dupla, processamento e coleta. Os usuários são roteados para a região mais próxima. O SKU do cluster precisa ser o mesmo entre regiões.
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Ativo/ativo | 0 horas | 0 horas | Inferior | Alto |
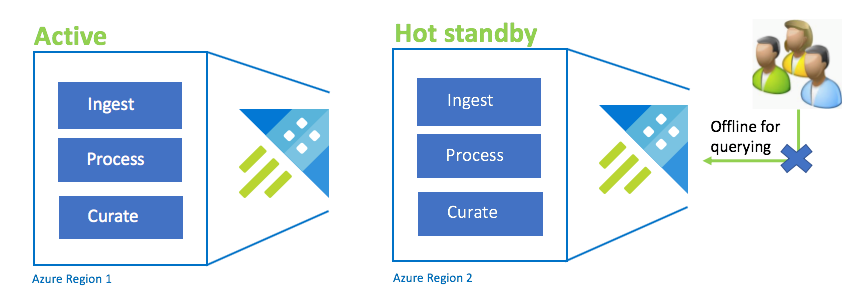
Configuração ativo/espera ativa
A configuração ativo/espera ativa é semelhante à configuração ativo/ativo em ingestão, processamento e coleta duplos. Embora o cluster em espera esteja online para ingestão, processo e curadoria, ele não está disponível para consulta. O cluster em espera não precisa estar no mesmo SKU que o cluster primário. Pode ser de SKU e escala menores, o que pode resultar em menos desempenho. Em um cenário de desastre, os usuários são redirecionados para o cluster em espera, que pode ser dimensionado opcionalmente para aumentar o desempenho.
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Ativo/espera ativa | 0 horas | Baixo | Médio | Médio |
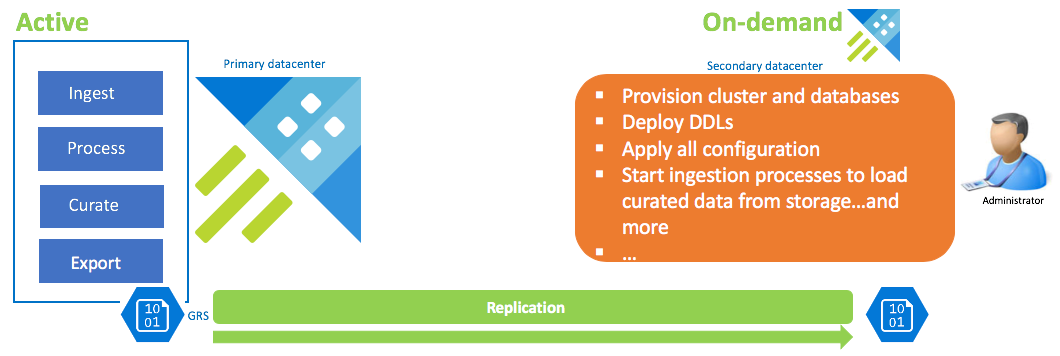
Configuração de recuperação de dados sob demanda
Essa solução oferece a menor resiliência (RPO e RTO mais altos), é a que tem o custo mais baixo e que exige o esforço mais alto. Nessa configuração, não há nenhum cluster de recuperação de dados. Configure a exportação contínua de dados coletados (a menos que os dados brutos e intermediários também sejam necessários) para uma conta de armazenamento configurada como GRS (armazenamento com redundância geográfica). Se houver um cenário de recuperação de desastre, um cluster de recuperação de dados será criado. Nesse momento, DDLs, configuração, políticas e processos são aplicados. Os dados são ingeridos do armazenamento com a propriedade de ingestão kustoCreationTime para substituir o tempo de ingestão, que usa a hora do sistema por padrão.
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Cluster de recuperação de dados sob demanda | O mais alto | O mais alto | O mais alto | O menor |
Resumo das opções de configuração de recuperação de desastre
| Configuração | Resiliência | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|---|
| Ativo/ativo/ativo/n | O mais alto | 0 horas | 0 horas | Inferior | O mais alto |
| Ativo/ativo | Alto | 0 horas | 0 horas | Inferior | Alto |
| Ativo/espera ativa | Médio | 0 horas | Baixo | Médio | Médio |
| Cluster de recuperação de dados sob demanda | O menor | O mais alto | O mais alto | O mais alto | O menor |
Práticas recomendadas
Independentemente de qual configuração de recuperação de desastre é escolhida, siga estas melhores práticas:
- Todos os objetos, políticas e configurações de banco de dados devem ser mantidos no controle do código-fonte para que possam ser liberados da ferramenta de automação de versão para o cluster. Para obter mais informações, confira o Suporte do Azure DevOps para o Azure Data Explorer.
- Projete, desenvolva e implemente rotinas de validação para garantir que todos os clusters estejam em sincronia desde uma determinada perspectiva de dados. O Azure Data Explorer dá suporte a ingressos entre clusters. Uma contagem simples ou linhas entre tabelas podem ajudar a validar.
- Os procedimentos de versão devem envolver verificações e saldos de governança que garantem o espelhamento dos clusters.
- Saiba tudo que é necessário para criar um cluster do zero.
- Crie uma lista de verificação das unidades de implantação. Sua lista será exclusiva de acordo com as suas necessidades, mas deverá incluir: scripts de implantação, conexões de ingestão, ferramentas de BI e outras configurações importantes.