Modelo de aplicativos analíticos em tempo real no Azure Cosmos DB for PostgreSQL
APLICA-SE AO: ![]() Azure Cosmos DB for PostgreSQL (da plataforma da extensão de dados Citus para PostgreSQL)
Azure Cosmos DB for PostgreSQL (da plataforma da extensão de dados Citus para PostgreSQL)
Colocar tabelas grandes com chave de fragmento
Para escolher a chave de fragmento para um aplicativo de análise operacional em tempo real, siga estas diretrizes:
- Escolher uma coluna comum nas tabelas grandes
- Escolha uma coluna que seja uma dimensão natural nos dados ou uma parte central do aplicativo. Alguns exemplos:
- No mundo financeiro, um aplicativo que analisa tendências de segurança provavelmente usaria
security_id. - Em uma carga de trabalho de análise de usuário em que você deseja analisar as métricas de uso do site,
user_idseria uma coluna de distribuição adequada
- No mundo financeiro, um aplicativo que analisa tendências de segurança provavelmente usaria
Ao colocar tabelas grandes, você pode enviar as consultas SQL para os nós de trabalho paralelamente. Enviar as consultas evita o embaralhamento de dados entre nós na rede. Operações como JOINs, agregações, rollups, filtros e LIMITs podem ser executadas com eficiência.
Para visualizar as consultas paralelas distribuídas nas tabelas colocadas, considere este diagrama:
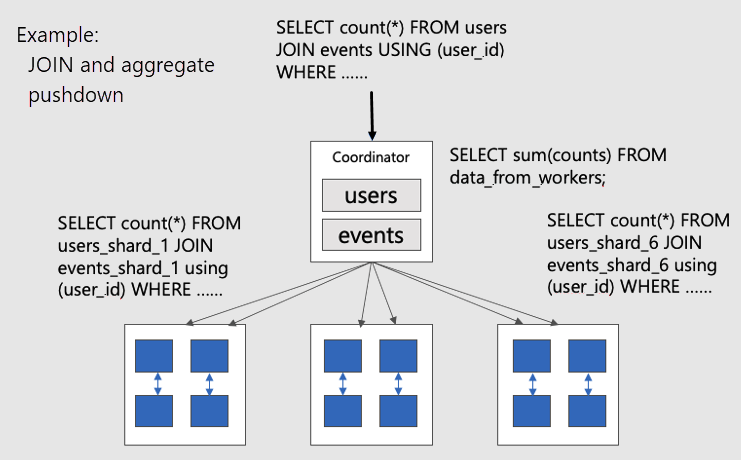
As tabelas users e events são fragmentadas por user_id, portanto, as linhas relacionadas da mesma ID do usuário são unidas no mesmo nó de trabalho. Os JOINs do SQL podem ser executados sem obter informações entre os trabalhos.
Modelo de dados ideal para aplicativos em tempo real
Vamos continuar com o exemplo de um aplicativo que analisa as visitas ao site do usuário e as métricas. Há duas tabelas de "fatos", usuários e eventos, e outras tabelas de "dimensões" menores.
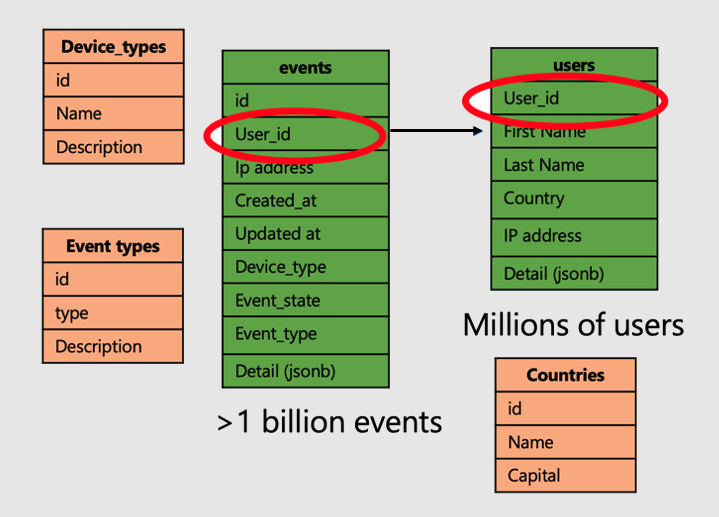
Para aplicar a superpotência das tabelas distribuídas no Azure Cosmos DB for PostgreSQL, siga estas etapas:
- Distribua as tabelas de fatos grandes em uma coluna comum. Em nosso caso, os usuários e eventos são distribuídos em
user_id. - Marque as tabelas de dimensões/pequenas (
device_types,countriese `event_types) como tabelas de referência. - Inclua a coluna de distribuição nas restrições de chaves primárias, exclusivas e estrangeiras das tabelas distribuídas. A inclusão da coluna pode exigir uma chave composta. É necessário atualizar as chaves para as tabelas de referência.
- Ao ingressar nas tabelas distribuídas grandes, faça-o usando a chave de fragmento.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Próximas etapas
Agora terminamos de explorar a modelagem de dados para aplicativos escalonáveis. A próxima etapa é conectar e consultar o banco de dados com a linguagem de programação de sua escolha.