Visão geral de indexação no Azure Cosmos DB
APLICA-SE AO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
O Azure Cosmos DB é um banco de dados independente de esquema que permite fazer uma iteração no aplicativo sem a necessidade de gerenciamento de índices ou esquema. Por padrão, o Azure Cosmos DB indexa automaticamente cada propriedade para todos os itens no contêiner sem precisar definir esquema nem configurar índices secundários.
O objetivo deste artigo é explicar como o Azure Cosmos DB indexa os dados e como ele usa índices para melhorar o desempenho da consulta. É recomendável ler esta seção com atenção antes de explorar como personalizar políticas de indexação.
De itens para árvores
Sempre que um item é armazenado em um contêiner, seu conteúdo é projetado como um documento JSON e, depois, convertido em uma representação de árvore. Essa conversão significa que todas as propriedades do item em questão são representadas como um nó em uma árvore. Um pseudo nó raiz é criado como um pai para todas as propriedades de primeiro nível do item. Os nós folha contêm os valores escalares reais que um item transporta.
Por exemplo, considere este item:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Essa árvore representa o exemplo de item JSON:
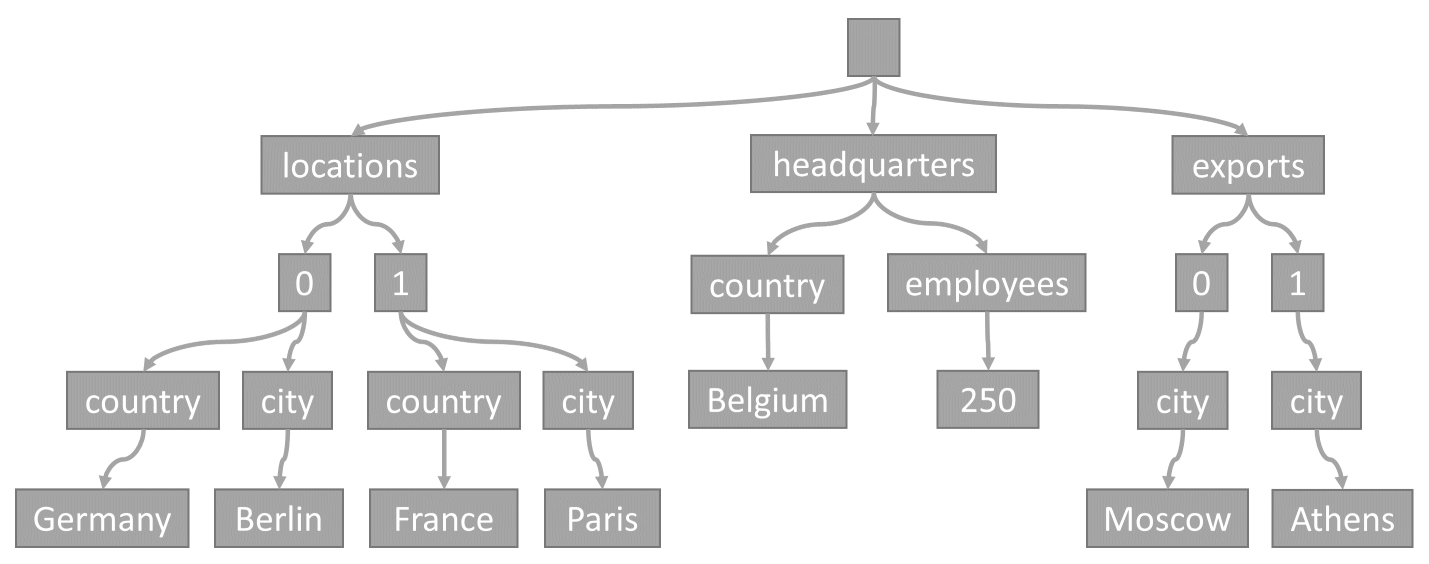
Observe como as matrizes são codificadas na árvore: toda entrada em uma matriz obtém um nó intermediário rotulado com o índice dessa entrada na matriz (0, 1 etc.).
De árvores para caminhos de propriedade
O motivo pelo qual o Azure Cosmos DB transforma itens em árvores é que isso permite que o sistema mencione propriedades usando seus caminhos dentro dessas árvores. Para obter o caminho para uma propriedade, podemos percorrer a árvore do nó raiz para essa propriedade e concatenar os rótulos de cada nó atravessado.
Vejamos os caminhos para cada propriedade do exemplo de item descrito acima:
/locations/0/country: "Alemanha"/locations/0/city: "Berlim"/locations/1/country: "França"/locations/1/city: "Paris"/headquarters/country: "Bélgica"/headquarters/employees: 250/exports/0/city: "Moscou"/exports/1/city: "Atenas"
O Azure Cosmos DB efetivamente indexa o caminho de cada propriedade e seu respectivo valor quando um item é gravado.
Tipos de índices
No momento, o Azure Cosmos DB é compatível com três tipos de índices. Você pode configurar esses tipos de índice ao definir a política de indexação.
Índice de intervalo
O índice de intervalo se baseia em uma estrutura ordenada de árvore. O tipo de índice de intervalo é usado para:
Consultas de igualdade:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Correspondência de igualdade em um elemento de matriz
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Consultas de intervalo:
SELECT * FROM container c WHERE c.property > 'value'Observação
(funciona para
>,<,>=,<=,!=)Verificando a presença de uma propriedade:
SELECT * FROM c WHERE IS_DEFINED(c.property)Funções do sistema de cadeia de caracteres:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")Consultas
ORDER BY:SELECT * FROM container c ORDER BY c.propertyConsultas
JOIN:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Os índices de intervalo podem ser usados em valores escalares (cadeia de caracteres ou número). A política de indexação padrão para contêineres recém-criados impõe os índices de intervalo para qualquer cadeia de caracteres ou número. Para saber como configurar índices de intervalo, consulte Exemplos de política de indexação de intervalo
Observação
Uma cláusula ORDER BY ordenada por uma única propriedade sempre precisa de um índice de intervalo e falhará se o caminho que ele referencia não tiver um. Da mesma forma, uma consulta ORDER BY ordenada por várias propriedades sempre precisa de um índice composto.
Índice espacial
Os índices espaciais permitem consultas eficientes em objetos geoespaciais, como pontos, linhas, polígonos e multipolígono. Essas consultas usam as palavras-chave ST_DISTANCE, ST_WITHIN, ST_INTERSECTS. Veja a seguir alguns exemplos que usam o tipo de índice espacial:
Consultas de distância geoespaciais:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Geoespacial em consultas:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Consultas de interseção geoespacial:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Os índices espaciais podem ser usados em objetos do GeoJSON formatados corretamente. Pontos, LineStrings, polígonos e multipolígonos atualmente têm suporte. Para saber como configurar índices espaciais, consulte Exemplos de política de indexação espacial
Índices compostos
Os índices compostos aumentam a eficiência quando você está executando operações em diversos campos. O tipo de índice composto é usado para:
Consultas
ORDER BYem várias propriedades:SELECT * FROM container c ORDER BY c.property1, c.property2Consultas com um filtro e
ORDER BY. Essas consultas poderão utilizar um índice composto se a propriedade de filtro for adicionada à cláusulaORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Consultas com um filtro em duas ou mais propriedades em que pelo menos uma propriedade é um filtro de igualdade
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Na medida em que um predicado de filtro usar um dos tipos de índice, o mecanismo de consulta irá avaliá-lo primeiro antes de verificar o restante. Por exemplo, se você tiver uma consulta SQL como SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Usando o índice, a consulta acima primeiro filtrará as entradas em que firstName = "Andrew". Em seguida, ela passa todas as entradas firstName = "Andrew" por meio de um pipeline subsequente para avaliar o predicado de filtro CONTAINS.
Você pode acelerar as consultas e evitar verificações completas de contêiner ao usar funções que executam uma verificação completa, como CONTAINS. Você pode adicionar mais predicados de filtro que usam o índice para acelerar essas consultas. A ordem das cláusulas de filtro não é importante. O mecanismo de consulta entende quais predicados são mais seletivos e executa a consulta de acordo.
Para saber como configurar índices compostos, consulte Exemplos de política de indexação composta
Índices de vetor
Os índices de vetor aumentam a eficiência ao realizar buscas em vetores usando a função do sistema VectorDistance. As buscas em vetores terão latência significativamente menor, maior taxa de transferência e menor consumo de RU ao aproveitar um índice de vetor.
Para saber como configurar índices de vetor, consulte exemplos de política de indexação de vetor
ORDER BYconsultas de busca em vetores:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Projeção da pontuação de similaridade em consultas de busca em vetores:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filtros de intervalo na pontuação de similaridade.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Importante
Atualmente, as políticas de vetor e os índices de vetor são imutáveis após a criação. Para fazer alterações, crie uma coleção.
Uso do índice
Há cinco maneiras pelas quais o mecanismo de consulta pode avaliar filtros de consulta, classificados dos mais eficientes para os menos eficientes:
- Busca de índice
- Verificação de índice amplificada
- Verificação de índice expandida
- Verificação de índice completa
- Verificação completa
Quando você indexa caminhos de propriedade, o mecanismo de consulta automaticamente usa o índice da maneira mais eficiente possível. Além de indexar novos caminhos de propriedade, você não precisa configurar nada para otimizar como as consultas usam o índice. O preço da RU de uma consulta é uma combinação do preço da RU do uso do índice e do preço da RU do carregamento de itens.
Aqui está uma tabela que resume as diferentes maneiras com que os índices são usados no Azure Cosmos DB:
| Tipo de pesquisa de índice | Descrição | Exemplos comuns | Preço da RU do uso do índice | Cobranças da RU pelo carregamento de itens do armazenamento de dados transacionais |
|---|---|---|---|---|
| Busca de índice | Lê somente os valores indexados necessários e carrega somente itens correspondentes do armazenamento de dados transacional | Filtros de igualdade, IN | Filtro de constante por igualdade | Aumenta com base no número de itens nos resultados da consulta |
| Verificação de índice amplificada | Pesquisa binária de valores indexados que carrega somente itens correspondentes do armazenamento de dados transacional | Comparações de intervalo (>, <, <=, ou >=), StartsWith | Comparável à busca de índice, aumenta ligeiramente com base na cardinalidade das propriedades indexadas | Aumenta com base no número de itens nos resultados da consulta |
| Verificação de índice expandida | Pesquisa otimizada (mas menos eficiente do que uma pesquisa binária) de valores indexados que carrega apenas itens correspondentes do armazenamento de dados transacional | StartsWith (não diferencia maiúsculas de minúsculas), StringEquals (não diferencia maiúsculas de minúsculas) | Aumenta ligeiramente com base na cardinalidade das propriedades indexadas | Aumenta com base no número de itens nos resultados da consulta |
| Verificação de índice completa | Lê o conjunto distinto de valores indexados e carrega somente itens correspondentes do armazenamento de dados transacional | Contains, EndsWith, RegexMatch, LIKE | Aumenta linearmente com base na cardinalidade de propriedades indexadas | Aumenta com base no número de itens nos resultados da consulta |
| Verificação completa | Carregar todos os itens do armazenamento de dados transacionais | Superior, inferior | N/D | Aumenta com base no número de itens no contêiner |
Ao preparar consultas, você deve usar o predicado de filtro que usa o índice da maneira mais eficiente possível. Por exemplo, se StartsWith ou Contains funcionar para o seu caso de uso, você deverá optar por StartsWith, já que isso fará uma verificação de índice precisa em vez de uma verificação de índice completa.
Detalhes de uso do índice
Nesta seção, abordaremos mais detalhes sobre como as consultas usam índices. Esse nível de detalhe não é necessário para você aprender como começar a usar o Azure Cosmos DB, mas está documentado nos mínimos detalhes para os usuários mais curiosos. Vamos mencionar o exemplo de item compartilhado no início deste documento:
Itens de exemplo:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
O Azure Cosmos DB usa um índice invertido. O índice funciona mapeando cada caminho JSON para o conjunto de itens que contêm esse valor. O mapeamento de ID do item é representado em várias páginas de índice diferentes para o contêiner. Aqui está uma amostra de diagrama de um índice invertido para um contêiner que inclui os dois exemplos de item:
| Caminho | Valor | Lista de IDs de item |
|---|---|---|
| /locations/0/country | Alemanha | 1 |
| /locations/0/country | Irlanda | 2 |
| /locations/0/city | Berlim | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | França | 1 |
| /locations/1/city | Paris | 1 |
| /headquarters/country | Bélgica | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
O índice invertido tem dois atributos importantes:
- Para um determinado caminho, os valores são classificação em ordem crescente. Portanto, o mecanismo de consulta pode facilmente servir
ORDER BYdo índice. - Para um determinado caminho, o mecanismo de consulta pode examinar o conjunto distinto de valores possíveis para identificar as páginas de índice em que há resultados.
O mecanismo de consulta pode utilizar o índice invertido de quatro maneiras diferentes:
Busca de índice
Considere a consulta a seguir:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
O predicado de consulta (filtragem em itens nos quais o país/região de todos os locais seja "França") corresponderia ao caminho realçado em vermelho nesse diagrama:
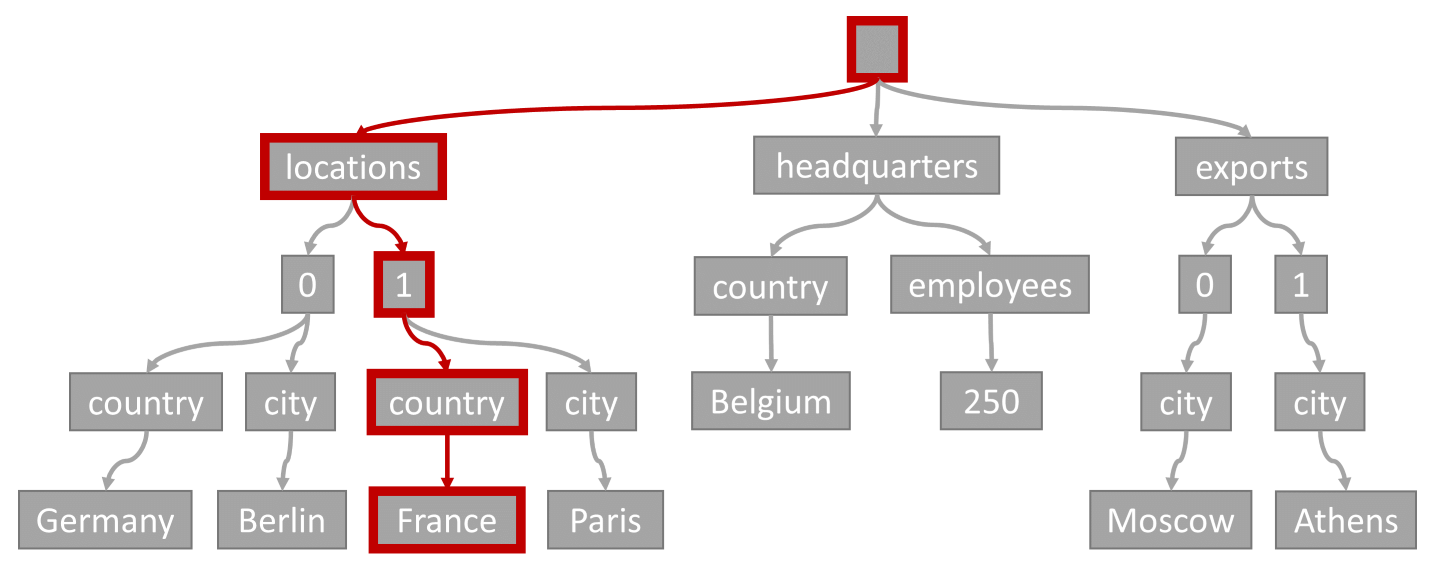
Como essa consulta tem um filtro de igualdade, depois de percorrer essa árvore, podemos identificar rapidamente as páginas de índice que contêm os resultados da consulta. Nesse caso, o mecanismo de consulta leria páginas de índice que contêm o Item 1. Uma busca de índice é a maneira mais eficiente de usar o índice. Com uma busca de índice, lemos apenas as páginas de índice necessárias e carregamos apenas os itens nos resultados da consulta. Portanto, o tempo de pesquisa de índice e o preço da RU da pesquisa de índice são incrivelmente baixos, independentemente do volume total de dados.
Verificação de índice amplificada
Considere a consulta a seguir:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
O predicado de consulta (filtragem em itens em que há mais de 200 funcionários) pode ser avaliado com uma verificação de índice precisa do caminho headquarters/employees. Ao fazer uma verificação de índice precisa, o mecanismo de consulta começa fazendo uma pesquisa binária do conjunto distinto de valores possíveis para encontrar a localização do valor 200 do caminho headquarters/employees. Como os valores de cada caminho são classificação em ordem crescente, é fácil para o mecanismo de consulta fazer uma pesquisa binária. Depois que o mecanismo de consulta encontra o valor 200, ele começa a ler todas as páginas de índice restantes (seguindo na direção crescente).
Como o mecanismo de consulta pode fazer uma pesquisa binária para evitar a verificação de páginas de índice desnecessárias, as verificações de índice precisas tendem a ter latência e preço de RU comparáveis em operações de busca de índice.
Verificação de índice expandida
Considere a consulta a seguir:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
O predicado de consulta (filtrar itens cuja sede principal fica em um local cujo nome começa com "United" sem diferenciar maiúsculas de minúsculas) pode ser avaliado com uma verificação de índice expandida do caminho headquarters/country. As operações que fazem uma verificação de índice expandida têm otimizações que podem ajudar a evitar as necessidades de verificação de cada página de índice, mas são um pouco mais caras do que uma pesquisa binária de Verificação de índice amplificada.
Por exemplo, ao avaliar StartsWith sem diferenciar maiúsculas de minúsculas, o mecanismo de consulta irá verificar o índice quanto a diferentes combinações possíveis de valores de letra maiúscula e minúscula. Essa otimização permite que o mecanismo de consulta evite ler a maioria das páginas de índice. Diferentes funções do sistema têm otimizações diferentes que podem ser usadas para evitar a leitura de cada página de índice, de modo que sejam categorizadas de forma mais ampla como uma verificação de índice expandida.
Verificação de índice completa
Considere a consulta a seguir:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
O predicado de consulta (filtrar itens cuja sede principal fica em um local cujo nome começa com "United") pode ser avaliado com uma verificação de índice do caminho headquarters/country. Ao contrário de uma verificação de índice precisa, uma verificação de índice completa sempre irá verificar o conjunto distinto de valores possíveis para identificar as páginas de índice nas quais existam resultados. Nesse caso, Contains é executado no índice. O tempo de pesquisa de índice e o preço da RU para verificações de índice aumenta à medida que a cardinalidade do caminho aumenta. Em outras palavras, quanto mais valores distintos possíveis o mecanismo de consulta precisa verificar, maior a latência e o preço da RU envolvidos na realização de uma verificação de índice completa.
Por exemplo, considere duas propriedades: town e country. A cardinalidade da cidade é 5.000 e a cardinalidade do country é 200. Aqui estão dois exemplos de consultas com a função de sistema Contém que fazem uma verificação de índice completa na propriedade town. A primeira consulta usa mais RUs do que a segunda consulta, devido ao fato de que a cardinalidade da cidade é mais alta do que a do country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Verificação completa
Em alguns casos, o mecanismo de consulta pode não conseguir avaliar um filtro de consulta usando o índice. Nesse caso, o mecanismo de consulta precisa carregar todos os itens do armazenamento transacional para avaliar o filtro da consulta. As verificações completas não usam o índice e têm uma cobrança de RU que aumenta linearmente com o tamanho total dos dados. Felizmente, as operações que exigem verificações completas são raras.
Consultas de busca em vetores sem um índice de vetor definido
Se você não definir uma política de índice de vetor e usar a função do sistema VectorDistance em um cláusula ORDER BY, isso resultará em uma verificação completa e terá uma cobrança de RU maior do que se você tiver definido uma política de índice de vetor. Da mesma forma, se você usar VectorDistance com o valor booliano de força bruta definido como true e não tiver um índice flat definido para o caminho do vetor, ocorrerá uma verificação completa.
Consultas com expressões de filtro complexas
Nos exemplos anteriores, só consideramos consultas que tinham expressões de filtro simples (por exemplo, consultas com apenas um único filtro de igualdade ou intervalo). Na realidade, a maioria das consultas tem expressões de filtro muito mais complexas.
Considere a consulta a seguir:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Para executar essa consulta, o mecanismo de consulta deve fazer uma busca de índice em headquarters/employees e uma verificação de índice completo em headquarters/country. O mecanismo de consulta tem um heurística interna que ele usa para avaliar a expressão de filtro de consulta da maneira mais eficiente possível. Nesse caso, o mecanismo de consulta evitaria a necessidade de ler páginas de índice desnecessárias ao fazer a busca de índice primeiro. Por exemplo, se apenas 50 itens correspondessem ao filtro de igualdade, o mecanismo de consulta só precisaria avaliar Contains nas páginas de índice que contivessem esses 50 itens. Uma verificação de índice completa de todo o contêiner não seria necessária.
Utilização de índice para funções de agregação escalares
As consultas com funções de agregação devem depender exclusivamente do índice para usá-lo.
Em alguns casos, o índice pode retornar falsos positivos. Por exemplo, ao avaliar Contains no índice, o número de correspondências no índice pode exceder o número de resultados da consulta. O mecanismo de consulta carrega todas as correspondências de índice, avalia o filtro nos itens carregados e retorna apenas os resultados corretos.
Para a maioria das consultas, carregar as correspondências de índice com falsos positivos não exercerá nenhum impacto perceptível sobre a utilização do índice.
Por exemplo, considere a seguinte consulta:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
A função do sistema Contains pode retornar algumas correspondências com falsos positivos, de forma que o mecanismo de consulta precisa verificar se cada item carregado corresponde à expressão do filtro. Nesse exemplo, o mecanismo de consulta pode precisar carregar apenas alguns poucos itens adicionais, de forma que o impacto sobre a utilização do índice e a cobrança da RU é mínimo.
No entanto, as consultas com funções de agregação devem depender exclusivamente do índice para usá-lo. Por exemplo, considere a seguinte consulta com um agregado Count:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Como no primeiro exemplo, a função do sistema Contains pode retornar algumas correspondências falsas positivas. No entanto, ao contrário da consulta SELECT *, a consulta Count não pode avaliar a expressão de filtro nos itens carregados para verificar todas as correspondências de índice. A consulta Count deve depender exclusivamente do índice, de forma que, se houver uma possibilidade de que uma expressão de filtro retorne correspondências com falsos positivos, o mecanismo de consulta recorra a uma verificação completa.
As consultas com as seguintes funções de agregação devem depender exclusivamente do índice, portanto, avaliar algumas funções do sistema requer uma verificação completa.
Próximas etapas
Leia mais sobre indexação nos seguintes artigos: