Como modelar dados de grafo com o Azure Cosmos DB for Apache Gremlin
APLICA-SE AO: ![]() Gremlin
Gremlin
Este artigo fornece recomendações para o uso de modelos de dados de grafo. Essas boas práticas são vitais para garantir a escalabilidade e o desempenho de um sistema de banco de dados de grafo à medida que os dados evoluem. Um modelo de dados eficiente é especialmente importante para grafos em grande escala.
Requisitos
O processo descrito neste guia se baseia nas seguintes suposições:
- As entidades no espaço de problema são identificadas. Essas entidades destinam-se a serem consumidas atomicamente para cada solicitação. Em outras palavras, o sistema de banco de dados não foi projetado para recuperar os dados de uma única entidade em várias solicitações de consulta.
- Há uma compreensão dos requisitos de leitura e gravação do sistema de banco de dados. Esses requisitos irão orientar as otimizações necessárias para o modelo de dados de grafo.
- Os princípios do padrão de grafo de propriedade do Apache Tinkerpop são bem compreendidos.
Quando é necessário ter um banco de dados de grafo?
Uma solução de banco de dados de grafo poderá ser idealmente aplicada se as entidades e relações em um domínio de dados apresentarem uma das seguintes características:
- As entidades são altamente conectadas por meio de relações descritivas. A vantagem desse cenário é o fato de que as relações persistem no armazenamento.
- Há relações cíclicas ou entidades autorreferenciadas. Esse padrão costuma constituir um desafio quando você usa bancos de dados relacionais ou de documentos.
- Há relações que evoluem dinamicamente entre as entidades. Esse padrão é especialmente aplicável a dados hierárquicos ou com estrutura de árvore com muitos níveis.
- Há relações muitos para muitos entre as entidades.
- Há requisitos de gravação e leitura nas entidades e nas relações.
Se os critérios acima forem atendidos, uma abordagem de banco de dados de grafo será provavelmente vantajosa no que diz respeito à complexidade da consulta, escalabilidade do modelo de dados e desempenho da consulta.
A próxima etapa é determinar se o grafo será usado para fins analíticos ou transacionais. Se o grafo se destinar a ser usado para cargas de trabalho pesadas de processamento de dados e computação, valerá a pena explorar o conector Spark do Cosmos DB e a biblioteca do GraphX.
Como usar objetos de grafo
O padrão de grafo de propriedades do Apache Tinkerpop define dois tipos de objetos: vértices e bordas.
Confira baixo as boas práticas para as propriedades nos objetos do grafo:
| Objeto | Propriedade | Type | Observações |
|---|---|---|---|
| Vértice | ID | String | Imposto com exclusividade por partição. Se um valor não for fornecido após a inserção, um GUID gerado automaticamente será armazenado. |
| Vértice | Rótulo | String | Essa propriedade é usada para definir o tipo de entidade representado pelo vértice. Se um valor não for fornecido, será usado um valor de vértice padrão. |
| Vértice | Propriedades | Cadeia de caracteres, booliano, numérico | Uma lista de propriedades separadas armazenadas como pares chave-valor em cada vértice. |
| Vértice | Chave de partição | Cadeia de caracteres, booliano, numérico | Essa propriedade define onde o vértice e suas bordas de saída são armazenados. Leia mais sobre o particionamento de grafo. |
| Edge | ID | String | Imposto com exclusividade por partição. Gerado automaticamente por padrão. De modo geral, as bordas não precisam ser recuperadas de forma exclusiva por uma ID. |
| Microsoft Edge | Rótulo | String | Essa propriedade é usada para definir o tipo de relação existente entre dois vértices. |
| Edge | Propriedades | Cadeia de caracteres, booliano, numérico | Uma lista de propriedades separadas armazenadas como pares chave-valor em cada borda. |
Observação
As bordas não requerem um valor de chave de partição, já que seu valor é atribuído automaticamente com base no seu vértice de origem. Saiba mais no artigo Como usar um gráfico particionado no Azure Cosmos DB.
Diretrizes de modelagem de entidade e relação
As diretrizes a seguir irão ajudar você a abordar a modelagem de dados para um banco de dados de grafo do Azure Cosmos DB for Apache Gremlin. Essas diretrizes pressupõem que haja uma definição existente de um domínio de dados e consultas para ele.
Observação
As etapas abaixo são apresentadas na forma de recomendações. Você deve avaliar e testar o modelo final antes de considerá-lo como pronto para a produção. Além disso, as recomendações são específicas para a implementação da API do Gremlin do Azure Cosmos DB.
Como modelar vértices e propriedades
A primeira etapa de um modelo de dados de grafo é mapear cada entidade identificada para um objeto de vértice. Um mapeamento individual de todas as entidades em vértices deve ser uma etapa inicial e estar sujeito a alterações.
Uma armadilha comum é mapear propriedades de uma única entidade como vértices separados. Observe o exemplo abaixo, no qual a mesma entidade é representada de duas maneiras diferentes:
Propriedades com base em vértice: nessa abordagem, a entidade usa três vértices separados e duas bordas para descrever suas propriedades. Embora essa abordagem possa reduzir a redundância, ela aumenta a complexidade do modelo. Um aumento na complexidade do modelo pode resultar em latência adicionada, complexidade da consulta e custo de computação. Esse modelo também pode apresentar desafios no particionamento.
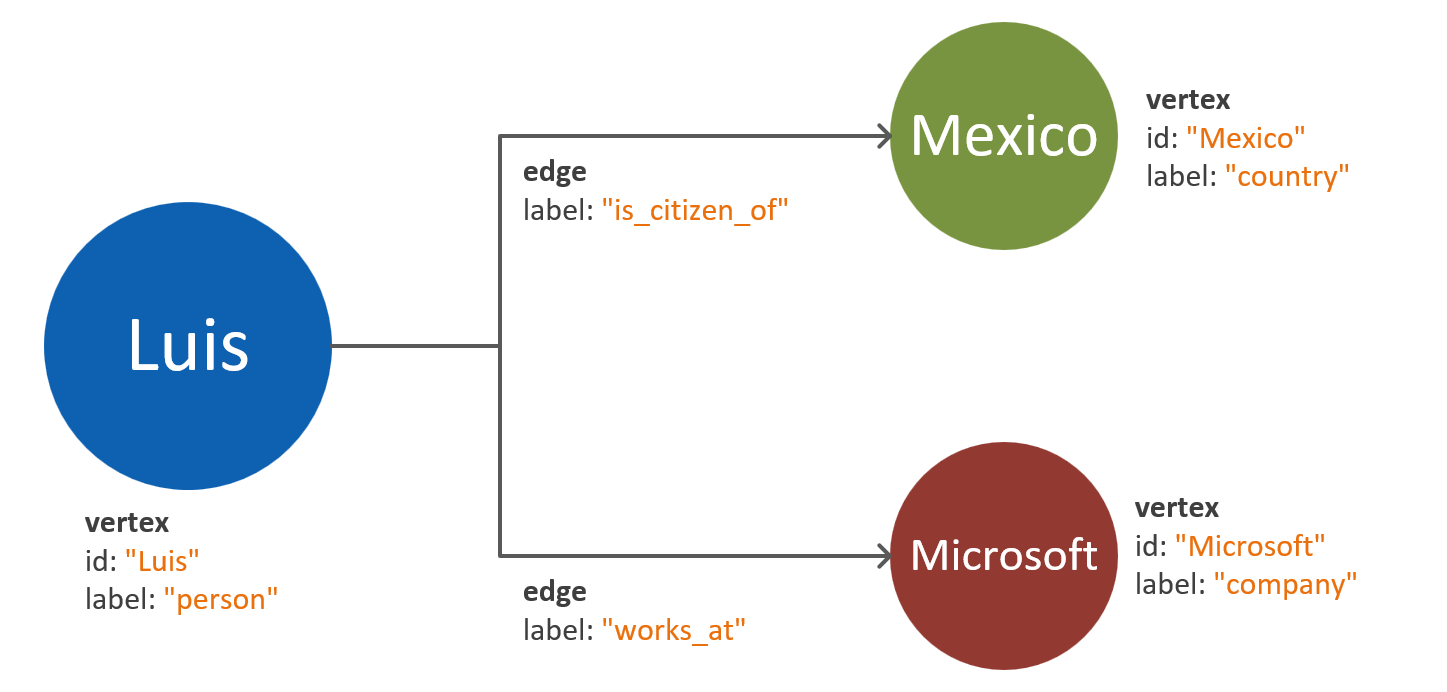
Vértices inseridos na propriedade: essa abordagem usa a lista de pares chave-valor para representar todas as propriedades da entidade dentro de um vértice. Essa abordagem reduz a complexidade do modelo, resultando em consultas mais simples e travessias mais econômicas.

Observação
Os diagramas anteriores mostram um modelo de grafo simplificado que apenas compara duas maneiras de dividir as propriedades de uma entidade.
O padrão vértices inseridos na propriedade geralmente oferece uma abordagem com melhor desempenho e mais escalonável. A abordagem padrão de um novo modelo de dados de grafo deve tender a assumir esse padrão.
No entanto, existem situações em que mencionar uma propriedade pode ser vantajoso. Por exemplo, se a propriedade mencionada for atualizada com frequência. Use um vértice separado para representar uma propriedade que é alterada constantemente para minimizar a quantidade de operações de gravação requeridas pela atualização.
Modelos de relação com direções de borda
Depois que os vértices são modelados, as bordas podem ser adicionadas para indicar as relações entre eles. O primeiro aspecto que precisa ser avaliado é a direção da relação.
Os objetos de borda têm uma direção padrão que é seguida por uma travessia ao usar as funções out() ou outE(). O uso dessa direção natural resulta em uma operação eficiente, pois todos os vértices são armazenados com suas bordas de saída.
No entanto, atravessar na direção oposta a uma borda usando a função in() sempre resultará em uma consulta entre partições. Saiba mais sobre o particionamento de grafo. Se uma travessia constante é necessária usando a função in(), recomendamos adicionar bordas em ambos os sentidos.
Você pode determinar a direção da borda usando os predicados .to() ou .from() para a etapa .addE() do Gremlin. Ou usando a biblioteca bulk executor para a API do Gremlin.
Observação
Os objetos de borda têm uma direção por padrão.
Rótulos de relação
O uso de rótulos de relação descritivos pode melhorar a eficiência das operações de resolução de borda. Você pode aplicar esse padrão das seguintes maneiras:
- Use termos não genéricos para rotular uma relação.
- Associe o rótulo do vértice de origem ao rótulo do vértice de destino com o nome da relação.
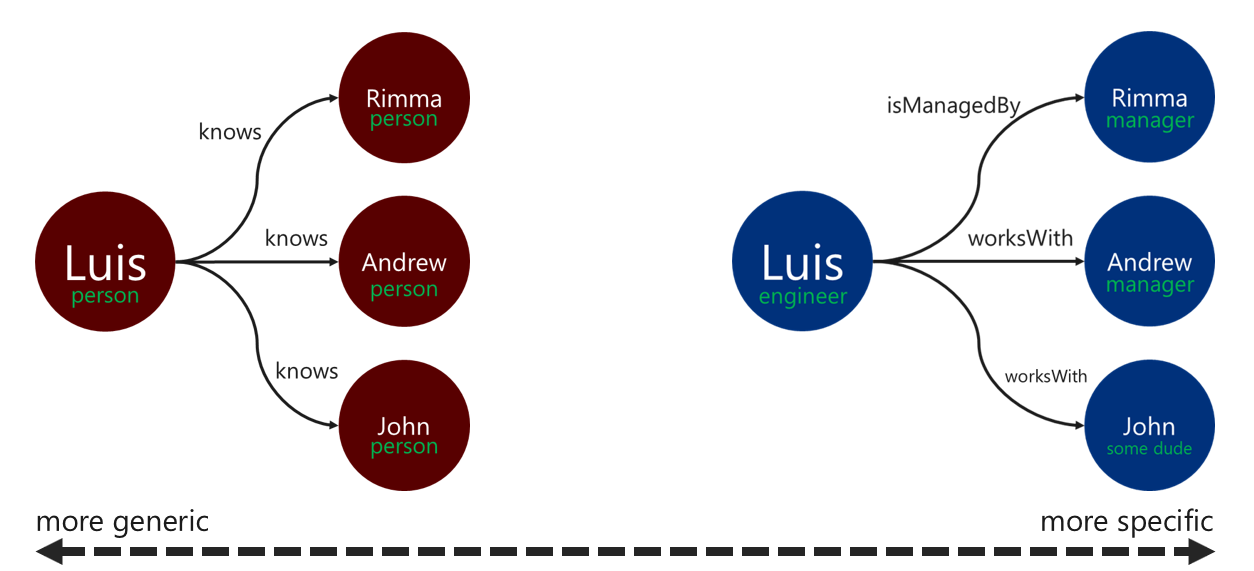
Quanto mais específico for o rótulo que o atravessador usar para filtrar as bordas, melhor. Essa decisão também pode exercer um impacto significativo sobre o custo da consulta. Você pode avaliar o custo da consulta a qualquer momento usando a etapa executionProfile.
Próximas etapas
- Confira a lista de etapas compatíveis do Gremlin.
- Saiba mais sobre o particionamento de banco de dados de grafo para lidar com grafos em grande escala.
- Avalie suas consultas do Gremlin usando a etapa Perfil de Execução.
- Modelo de dados de design de um grafo de terceiros.