Melhores práticas do Azure Machine Learning para segurança corporativa
Este artigo explica as melhores práticas de segurança para o planejamento ou o gerenciamento de uma implantação segura do Azure Machine Learning. As melhores práticas são provenientes da Microsoft e da experiência dos clientes com o Azure Machine Learning. Cada diretriz explica a prática e a respectiva lógica. O artigo também fornece links para instruções e a documentação de referência.
Arquitetura de segurança de rede recomendada (rede gerenciada)
A arquitetura de segurança de rede de aprendizado de máquina recomendada é uma rede virtual gerenciada. Uma rede virtual gerenciada do Azure Machine Learning protege o espaço de trabalho, os recursos associados do Azure e todos os recursos de computação gerenciados. Ele simplifica a configuração e o gerenciamento da segurança da rede, pré-configurando as saídas necessárias e criando automaticamente recursos gerenciados na rede. Você pode usar pontos de extremidade privados para permitir que os serviços do Azure acessem a rede e, opcionalmente, definir regras de saída para permitir que a rede acesse a Internet.
A rede virtual gerenciada tem dois modos para os quais pode ser configurada:
Permitir saída de internet - Este modo permite a comunicação de saída com recursos localizados na internet, como os repositórios de pacotes públicos PyPi ou Anaconda.

Permitir apenas saída aprovada - Este modo permite apenas a comunicação de saída mínima necessária para o espaço de trabalho funcionar. Esse modo é recomendado para espaços de trabalho que devem ser isolados da Internet. Ou onde o acesso de saída só é permitido a recursos específicos por meio de pontos de extremidade de serviço, tags de serviço ou nomes de domínio totalmente qualificados.

Para obter mais informações, consulte Isolamento de rede virtual gerenciado.
Arquitetura de segurança de rede recomendada (Rede Virtual do Azure)
Se você não puder usar uma rede virtual gerenciada devido aos seus requisitos de negócios, poderá usar uma rede virtual do Azure com as seguintes sub-redes:
- O treinamento contém os recursos de computação usados para o treinamento, como instâncias de computação de machine learning ou clusters de cálculo.
- A pontuação contém os recursos de computação usados para pontuação, como o AKS (Serviço de Kubernetes do Azure).
- O firewall contém o firewall que permite o tráfego na Internet pública, como o Firewall do Azure.
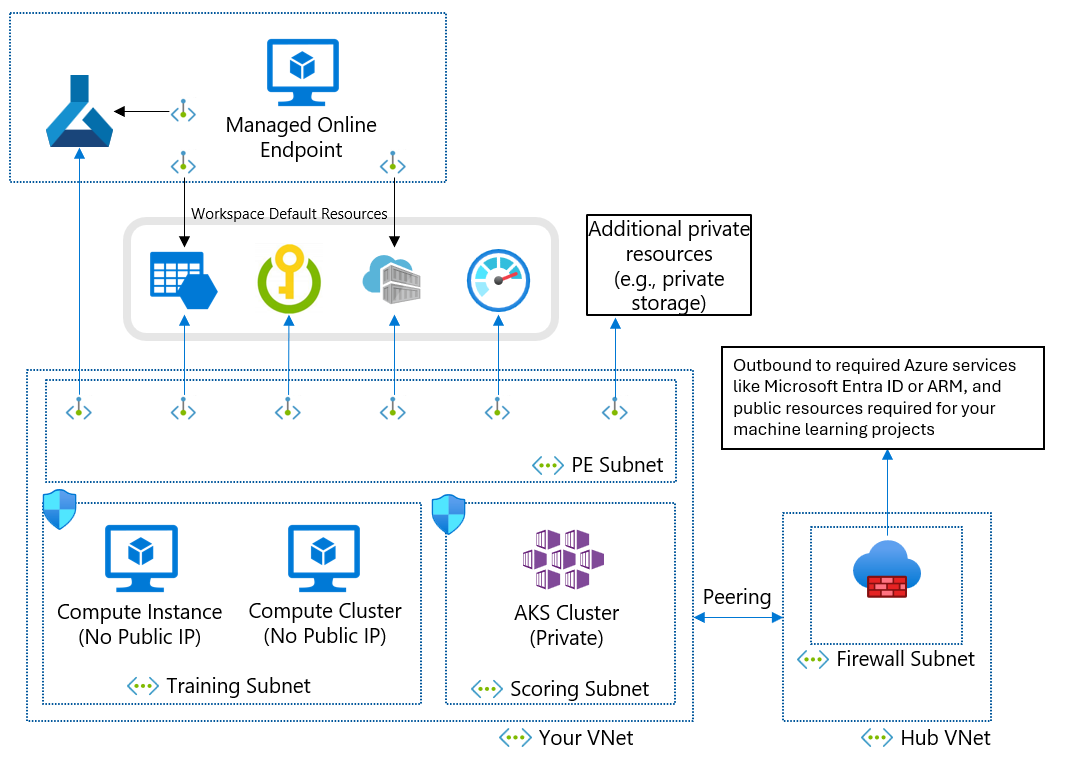
A rede virtual também contém um ponto de extremidade privado para seu espaço de trabalho de aprendizado de máquina e os seguintes serviços dependentes:
- Conta do Armazenamento do Azure
- Cofre de Chave do Azure
- Registro de Contêiner do Azure
A comunicação de saída da rede virtual precisa ter a capacidade de acessar os seguintes serviços Microsoft:
- Aprendizado de máquina
- Microsoft Entra ID
- Registro de Contêiner do Azure e registros específicos mantidos pela Microsoft
- Porta da frente do Azure
- Azure Resource Manager
- Armazenamento do Azure
Os clientes remotos se conectam à rede virtual usando o Azure ExpressRoute ou uma conexão VPN (rede virtual privada).
Design da rede virtual e do ponto de extremidade privado
Ao criar uma Rede Virtual do Azure, sub-redes e pontos de extremidade privados, considere os seguintes requisitos:
Em geral, crie sub-redes separadas para treinamento e pontuação e use a sub-rede de treinamento para todos os pontos de extremidade privados.
Para o endereçamento IP, as instâncias de computação precisam ter um IP privado cada uma. Os clusters de cálculo precisam ter um IP privado por nó. Os clusters do AKS precisam ter muitos endereços IP privados, conforme descrito em Planejar o endereçamento IP para o cluster do AKS. Uma sub-rede separada para, pelo menos, o AKS ajuda a impedir o esgotamento de endereços IP.
Os recursos de computação nas sub-redes de treinamento e pontuação devem acessar a conta de armazenamento, o cofre de chaves e o registro de contêiner. Crie pontos de extremidade privados para a conta de armazenamento, o cofre de chaves e o registro de contêiner.
O armazenamento padrão do workspace de machine learning precisa ter dois pontos de extremidade privados: um para o Armazenamento de Blobs do Azure e outro para o Armazenamento de Arquivos do Azure.
Se você usar o estúdio do Aprendizado de Máquina do Azure, os pontos de extremidade privados de espaço de trabalho e armazenamento deverão estar na mesma rede virtual.
Se você tiver vários workspaces, use uma rede virtual para cada workspace a fim de criar um limite de rede explícito entre os workspaces.
Usar endereços IP privados
Os endereços IP privados minimizam a exposição dos recursos do Azure à Internet. O machine learning usa muitos recursos do Azure, e o ponto de extremidade privado do workspace de machine learning não é suficiente para o IP privado de ponta a ponta. A tabela a seguir mostra os principais recursos que o aprendizado de máquina usa e como habilitar o IP privado para os recursos. As instâncias de computação e os clusters de cálculo são os únicos recursos que não têm o recurso de IP privado.
| Recursos | Solução de IP privado | Documentação |
|---|---|---|
| Workspace | Ponto de extremidade privado | Configurar um ponto de extremidade privado para um Workspace do Azure Machine Learning |
| Registro | Ponto de extremidade privado | Isolamento de rede com registros do Azure Machine Learning |
| Recursos associados | ||
| Armazenamento | Ponto de extremidade privado | Proteger as contas de armazenamento do Azure com pontos de extremidade de serviço |
| Key Vault | Ponto de extremidade privado | Cofre de Chaves do Azure Seguro |
| Registro de Contêiner | Ponto de extremidade privado | Habilitar o Registro de Contêiner do Azure |
| Recursos de treinamento | ||
| Instância de computação | IP privado (sem IP público) | Proteger ambientes de treinamento |
| Cluster de computação | IP privado (sem IP público) | Proteger ambientes de treinamento |
| Recursos de hospedagem | ||
| Ponto de extremidade online gerenciado | Ponto de extremidade privado | Isolamento de rede com pontos de extremidade online gerenciados |
| Ponto de extremidade online (Kubernetes) | Ponto de extremidade privado | Pontos de extremidade online seguros do Serviço Kubernetes do Azure |
| Pontos de extremidade em lotes | IP privado (herdado do cluster de computação) | Isolamento de rede em pontos de extremidade em lote |
Controlar o tráfego de entrada e de saída da rede virtual
Use um firewall ou um NSG (grupo de segurança de rede) do Azure para controlar o tráfego de entrada e de saída da rede virtual. Para obter mais informações sobre os requisitos de entrada e de saída, confira Configurar o tráfego de rede de entrada e de saída. Para obter mais informações sobre fluxos de tráfego entre componentes, consulte Fluxo de tráfego de rede em um espaço de trabalho seguro.
Garantir o acesso ao seu workspace
Para garantir que o ponto de extremidade privado possa acessar seu workspace de machine learning, execute as seguintes etapas:
Verifique se você tem acesso à sua rede virtual usando uma conexão VPN, o ExpressRoute ou uma VM (máquina virtual) jumpbox com acesso ao Azure Bastion. O usuário público não pode acessar o workspace de machine learning com o ponto de extremidade privado, pois ele só pode ser acessado na sua rede virtual. Para obter mais informações, confira Proteger seu workspace com redes virtuais.
Verifique se você pode resolver os FQDNs (nomes de domínio totalmente qualificados) do workspace com o endereço IP privado. Se você usar um servidor DNS (Sistema de Nomes de Domínio) próprio ou uma infraestrutura de DNS centralizada, precisará configurar um encaminhador DNS. Para mais informações, confira Como usar seu workspace com um servidor DNS personalizado.
Gerenciamento de acesso ao workspace
Ao definir os controles de gerenciamento de identidades e acesso de machine learning, você pode separar os controles que definem o acesso aos recursos do Azure dos controles que gerenciam o acesso aos ativos de dados. Dependendo do seu caso de uso, considere a possibilidade de usar o gerenciamento de identidades e acesso de autoatendimento, centrado nos dados ou centrado no projeto.
Padrão de autoatendimento
Em um padrão de autoatendimento, os cientistas de dados podem criar e gerenciar workspaces. Esse padrão é mais adequado para situações de prova de conceito que exigem flexibilidade para experimentar diferentes configurações. A desvantagem é que os cientistas de dados precisam ter o conhecimento necessário para provisionar os recursos do Azure. Essa abordagem é menos adequada quando controle rigoroso, uso de recursos, rastreamentos de auditoria e acesso a dados são necessários.
Defina políticas do Azure para definir proteções para o provisionamento e o uso de recursos, como tamanhos de cluster e tipos de VM permitidos.
Crie um grupo de recursos para manter os espaços de trabalho e conceda aos cientistas de dados uma função de Colaborador no grupo de recursos.
Os cientistas de dados já podem criar workspaces e associar os recursos do grupo de recursos por autoatendimento.
Para acessar o armazenamento de dados, crie identidades gerenciadas atribuídas pelo usuário e conceda às identidades funções de acesso de leitura no armazenamento.
Quando os cientistas de dados criam recursos de computação, eles podem atribuir as identidades gerenciadas às instâncias de computação para obter acesso aos dados.
Para ver as melhores práticas, confira Autenticação para análise de escala de dados.
Padrão centrado nos dados
Em um padrão centrado em dados, o espaço de trabalho pertence a um único cientista de dados que pode estar trabalhando em vários projetos. A vantagem dessa abordagem é que o cientista de dados pode reutilizar o código ou os pipelines de treinamento entre projetos. Desde que o workspace seja limitado a um só usuário, o acesso a dados pode ser rastreado de novo a esse usuário durante a auditoria dos logs de armazenamento.
A desvantagem é que o acesso a dados não é compartimentado ou restrito por projeto, e qualquer usuário adicionado ao espaço de trabalho pode acessar os mesmos ativos.
Crie o workspace.
Crie recursos de computação com identidades gerenciadas atribuídas pelo sistema habilitadas.
Quando um cientista de dados precisar acessar os dados de determinado projeto, permita o acesso de leitura aos dados à identidade gerenciada de computação.
Conceda à identidade gerenciada de computação acesso a outros recursos necessários, como um registro de contêiner com imagens personalizadas do Docker para treinamento.
Conceda também a função de acesso de leitura de identidade gerenciada do espaço de trabalho nos dados para habilitar a visualização de dados.
Permita acesso ao workspace ao cientista de dados.
O cientista de dados agora pode criar armazenamentos de dados para acessar os dados necessários para projetos e enviar execuções de treinamento que usam os dados.
Opcionalmente, crie um grupo de segurança do Microsoft Entra e conceda-lhe acesso de leitura aos dados e, em seguida, adicione identidades gerenciadas ao grupo de segurança. Essa abordagem reduz o número de atribuições de função diretas em recursos, a fim de evitar atingir o limite de assinatura em atribuições de função.
Padrão centrado no projeto
Um padrão centrado no projeto cria um workspace de machine learning para um projeto específico, e muitos cientistas de dados colaboram no mesmo workspace. O acesso a dados é restrito ao projeto específico, tornando a abordagem adequada para uso de dados confidenciais. Além disso, é simples adicionar ou remover cientistas de dados do projeto.
A desvantagem dessa abordagem é que o compartilhamento de ativos entre projetos pode ser difícil. Também é difícil rastrear o acesso a dados para usuários específicos durante as auditorias.
Criar o workspace
Identifique as instâncias de armazenamento de dados necessárias para o projeto, crie uma identidade gerenciada atribuída pelo usuário e permita acesso de leitura no armazenamento à identidade.
Opcionalmente, permita acesso ao armazenamento de dados à identidade gerenciada do workspace para permitir a visualização de dados. Você pode omitir esse acesso para dados confidenciais não adequados para visualização.
Crie armazenamentos de dados sem credenciais para os recursos de armazenamento.
Crie recursos de computação no workspace e atribua a identidade gerenciada aos recursos de computação.
Conceda à identidade gerenciada de computação acesso a outros recursos necessários, como um registro de contêiner com imagens personalizadas do Docker para treinamento.
Conceda aos cientistas de dados que trabalham no projeto uma função no workspace.
Usando o RBAC (controle de acesso baseado em função) do Azure, você pode impedir os cientistas de dados de criar armazenamentos de dados ou recursos de computação com identidades gerenciadas diferentes. Essa prática impede o acesso a dados não específicos ao projeto.
Opcionalmente, para simplificar o gerenciamento de associação ao projeto, você pode criar um grupo de segurança do Microsoft Entra para membros do projeto e conceder ao grupo acesso ao espaço de trabalho.
Azure Data Lake Storage com passagem de credenciais
Você pode usar a identidade do usuário do Microsoft Entra para acesso ao armazenamento interativo do estúdio de aprendizado de máquina. O Data Lake Storage com o namespace hierárquico habilitado permite uma organização aprimorada dos ativos de dados para armazenamento e colaboração. Com o namespace hierárquico do Data Lake Storage, você pode compartimentalizar o acesso a dados permitindo acesso baseado em ACL (lista de controle de acesso) a pastas e arquivos diferentes a usuários distintos. Por exemplo, você pode permitir acesso aos dados confidenciais a apenas um subconjunto de usuários.
RBAC e funções personalizadas
O RBAC do Azure ajuda você a gerenciar quem tem acesso a recursos de aprendizado de máquina e configurar quem pode executar operações. Por exemplo, o ideal é conceder apenas a usuários específicos a função Administrador do workspace para gerenciar os recursos de computação.
O escopo de acesso pode ser diferente entre ambientes. Em um ambiente de produção, o ideal é limitar a capacidade dos usuários de atualizar pontos de extremidade de inferência. Em vez disso, você pode conceder essa permissão a uma entidade de serviço autorizada.
O machine learning tem várias funções padrão: proprietário, colaborador, leitor e cientista de dados. Você também pode criar funções personalizadas, por exemplo, para criar permissões que reflitam sua estrutura organizacional. Para obter mais informações, consulte Gerenciar acesso a um espaço de trabalho do Azure Machine Learning.
Ao longo do tempo, a composição da sua equipe pode mudar. Se você criar um grupo do Microsoft Entra para cada função de equipe e espaço de trabalho, poderá atribuir uma função RBAC do Azure ao grupo do Microsoft Entra e gerenciar o acesso a recursos e grupos de usuários separadamente.
As entidades de usuário e as entidades de serviço podem fazer parte do mesmo grupo do Microsoft Entra. Por exemplo, ao criar uma identidade gerenciada atribuída pelo usuário que o Azure Data Factory usa para disparar um pipeline de aprendizado de máquina, você pode incluir a identidade gerenciada em um grupo do Microsoft Entra, executor de pipelines de ML.
Gerenciamento central de imagens do Docker
O Azure Machine Learning fornece imagens do Docker que podem ser usadas para treinamento e implantação. No entanto, os requisitos de conformidade da sua empresa podem exigir o uso de imagens de um repositório privado gerenciado por sua empresa. O machine learning apresenta duas maneiras de usar um repositório central:
Usar as imagens de um repositório central como imagens base. O gerenciamento do ambiente de machine learning instala pacotes e cria um ambiente do Python em que o código de treinamento ou de inferência é executado. Com essa abordagem, você pode atualizar as dependências do pacote facilmente sem modificar a imagem base.
Usar as imagens no estado em que se encontram, sem usar o gerenciamento do ambiente de machine learning. Essa abordagem oferece um maior grau de controle, mas também requer que você construa cuidadosamente o ambiente Python como parte da imagem. Você precisa atender a todas as dependências necessárias para executar o código, e quaisquer novas dependências exigem a reconstrução da imagem.
Para obter mais informações, consulte Gerenciar ambientes.
Criptografia de dados
Os dados de machine learning inativos têm duas fontes de dados:
Seu armazenamento tem todos os seus dados, incluindo dados de treinamento e modelo treinado, exceto os metadados. Você é responsável pela criptografia de armazenamento.
O Azure Cosmos DB contém seus metadados, incluindo informações de histórico de execuções, como nome do experimento e data e hora de envio do experimento. Na maioria dos workspaces, o Azure Cosmos DB está na assinatura da Microsoft e criptografado por uma chave gerenciada pela Microsoft.
Se você quiser criptografar seus metadados usando sua própria chave, poderá usar um espaço de trabalho de chave gerenciado pelo cliente. A desvantagem é que você precisa ter o Azure Cosmos DB na sua assinatura e pagar por ele. Para obter mais informações, confira Criptografia de dados com o Azure Machine Learning.
Para obter informações sobre como o Azure Machine Learning criptografa os dados em trânsito, confira Criptografia em trânsito.
Monitoramento
Ao implantar recursos de machine learning, configure controles de log e de auditoria para observabilidade. As motivações para observar os dados podem variar de acordo com quem analisa os dados. Os cenários incluem:
Os profissionais que usam o machine learning ou as equipes de operações desejam monitorar a integridade do pipeline de machine learning. Esses observadores precisam entender problemas na execução programada ou problemas com a qualidade dos dados ou o desempenho esperado do treinamento. Você pode criar painéis do Azure que monitoram dados do Aprendizado de Máquina do Azure ou criar fluxos de trabalho orientados a eventos.
Gerentes de capacidade, profissionais que usam o machine learning ou equipes de operações podem desejar criar um painel para observar a utilização da computação e da cota. Para gerenciar uma implantação com vários workspaces do Azure Machine Learning, considere a criação de um painel central para entender a utilização da cota. As cotas são gerenciadas em uma assinatura e, portanto, a exibição de todo o ambiente é importante para promover a otimização.
As equipes de TI e de operações podem configurar o log de diagnósticos para auditar o acesso a recursos e alterar eventos no workspace.
Considere a criação de painéis que monitoram a integridade geral da infraestrutura para machine learning e os recursos dependentes, como armazenamento. Por exemplo, combinar métricas de Armazenamento do Azure com dados de execução de pipeline pode ajudá-lo a otimizar a infraestrutura para obter melhor desempenho ou descobrir as causas raiz do problema.
O Azure coleta e armazena automaticamente as métricas e os logs de atividades da plataforma. Você pode encaminhar os dados para outras localizações usando uma configuração de diagnóstico. Configure o log de diagnóstico em um espaço de trabalho centralizado do Log Analytics para observabilidade em várias instâncias de espaço de trabalho. Use o Azure Policy para configurar automaticamente o log para novos workspaces de machine learning nesse workspace central do Log Analytics.
Azure Policy
Você pode impor e auditar o uso de recursos de segurança em workspaces por meio do Azure Policy. As recomendações incluem:
- Impor a criptografia de chave gerenciada personalizada.
- Impor o Link Privado do Azure e pontos de extremidade privados.
- Impor zonas DNS privadas.
- Desabilitar a autenticação não Azure AD, como o SSH (Secure Shell).
Para obter mais informações, confira Definições de políticas internas do Azure Machine Learning.
Use também definições de política personalizadas para controlar a segurança do workspace de maneira flexível.
Clusters de cálculo e instâncias
As considerações e as recomendações a seguir se aplicam a instâncias de machine learning e a clusters de cálculo.
Criptografia de disco
O disco do sistema operacional (SO) de uma instância de computação ou nó de cluster de computação é armazenado no Armazenamento do Azure e criptografado com chaves gerenciadas pela Microsoft. Cada nó também tem um disco temporário local. O disco temporário também é criptografado com chaves gerenciadas pela Microsoft se o espaço de trabalho tiver sido criado com o hbi_workspace = True parâmetro. Para obter mais informações, confira Criptografia de dados com o Azure Machine Learning.
Identidade gerenciada
Os clusters de cálculo dão suporte ao uso de identidades gerenciadas para autenticação nos recursos do Azure. O uso de uma identidade gerenciada para o cluster permite a autenticação em recursos sem expor as credenciais no código. Para saber mais, confira Criar um cluster de cálculo do Azure Machine Learning.
Script de instalação
Você pode usar um script de instalação para automatizar a personalização e a configuração de instâncias de computação na criação. Como administrador, você pode escrever um script de personalização a ser usado ao criar todas as instâncias de computação em um workspace. Você pode usar a Política do Azure para impor o uso do script de instalação para criar cada instância de computação. Para saber mais, confira Criar e gerenciar uma instância de computação do Azure Machine Learning.
Criação em nome de
Se você não quiser que os cientistas de dados provisionem recursos de computação, poderá criar instâncias de computação em seu nome e atribuí-las aos cientistas de dados. Para saber mais, confira Criar e gerenciar uma instância de computação do Azure Machine Learning.
Workspace habilitado para ponto de extremidade privado
Use instâncias de computação com um workspace habilitado para ponto de extremidade privado. A instância de computação rejeita todo o acesso público fora da rede virtual. Essa configuração também impede a filtragem de pacotes.
Suporte ao Azure Policy
Ao usar uma rede virtual do Azure, você pode usar a Política do Azure para garantir que cada cluster ou instância de computação seja criado em uma rede virtual e especificar a rede virtual e a sub-rede padrão. A política não é necessária ao usar uma rede virtual gerenciada, pois os recursos de computação são criados automaticamente na rede virtual gerenciada.
Use também uma política para desabilitar a autenticação não Azure AD, como o SSH.
Próximas etapas
Saiba mais sobre as configurações de segurança de machine learning:
Comece a usar uma implantação baseada em modelo de machine learning:
- Modelos de início rápido do Azure (
microsoft.com) - Análise de escala empresarial e zona de destino de dados de IA
Leia mais artigos sobre as considerações sobre arquitetura para implantar o machine learning:
Saiba como a estrutura da equipe, o ambiente ou as restrições regionais afetam a configuração do workspace.
Veja como gerenciar os custos de computação e o orçamento entre equipes e usuários.
Saiba mais sobre o MLOps (machine learning DevOps), que usa uma combinação de pessoas, processos e tecnologias para fornecer soluções robustas, confiáveis e com machine learning automatizado.